几个月前,我们宣布了explain.tensor.ru,这是一个用于解析和可视化 PostgreSQL 查询计划的公共服务。在过去的时间里,您已经使用了6000多次,但是其中一些便捷的功能可能会被忽略-这些是结构上的提示,看起来像这样: 聆听它们,您的请求将“变得顺滑如丝”。 :)但是,严重的是,很多情况下使请求变慢且在资源上 “繁琐”的情况很典型,并且可以通过计划的结构和数据来识别。在这种情况下,每个开发人员都不必仅仅依靠他们的经验就自己寻找优化选项-我们可以告诉他这里发生了什么,可能是什么原因以及如何解决该问题。我们做到了。
聆听它们,您的请求将“变得顺滑如丝”。 :)但是,严重的是,很多情况下使请求变慢且在资源上 “繁琐”的情况很典型,并且可以通过计划的结构和数据来识别。在这种情况下,每个开发人员都不必仅仅依靠他们的经验就自己寻找优化选项-我们可以告诉他这里发生了什么,可能是什么原因以及如何解决该问题。我们做到了。 让我们仔细看看这些案例-如何确定案例以及提出哪些建议。为了更好地理解该主题,您可以先听我关于PGConf.Russia 2020的报告中的相应内容,然后再继续详细分析每个示例:
让我们仔细看看这些案例-如何确定案例以及提出哪些建议。为了更好地理解该主题,您可以先听我关于PGConf.Russia 2020的报告中的相应内容,然后再继续详细分析每个示例:#1:索引“排序不足”
什么时候出现
显示客户“ LLC Bell”的最后一张发票。如何识别
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
推荐建议
使用用于对字段进行排序的索引。例:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
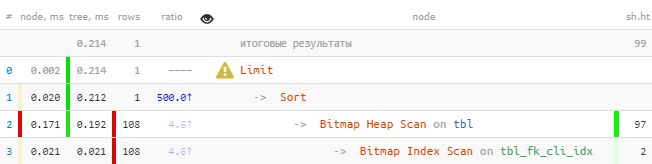 [请看explorer.tensor.ru]您会立即注意到,索引减去了100多个条目,然后对它们进行了排序,只剩下一个。我们修复:
[请看explorer.tensor.ru]您会立即注意到,索引减去了100多个条目,然后对它们进行了排序,只剩下一个。我们修复:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [看explain.tensor.ru]即使在这样原始的样本上,速度也快8.5倍,读数减少33倍。您对每个值拥有的“事实”越多,效果就越明显
[看explain.tensor.ru]即使在这样原始的样本上,速度也快8.5倍,读数减少33倍。您对每个值拥有的“事实”越多,效果就越明显fk。我注意到,对于没有进行fk排序pk也没有排序的其他查询,这样的索引将作为“前缀”使用,而不会比以前的索引更糟糕(有关更多信息,请参见我的文章,查找低效索引)。特别是,它将为该字段中的显式外键提供常规支持。#2:索引交集(BitmapAnd)
什么时候出现
显示客户有限责任公司Kolokolchik代表NAO Buttercup签订的所有合同。如何识别
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
推荐建议
为两个源中的字段
创建一个复合索引,或者从第二个字段中扩展一个现有字段。例:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [看explain.tensor.ru]正确:
[看explain.tensor.ru]正确:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [请看explorer.tensor.ru]这里的收益较少,因为位图堆扫描本身非常有效。但是仍然快7倍,读数少2.5倍。
[请看explorer.tensor.ru]这里的收益较少,因为位图堆扫描本身非常有效。但是仍然快7倍,读数少2.5倍。#3:索引池(BitmapOr)
什么时候出现
显示前20个最旧的“自有”或未分配的应用程序及其优先级。如何识别
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
推荐建议
使用UNION [ALL]组合条件的每个OR块的子查询。例:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [看explain.tensor.ru]正确:
[看explain.tensor.ru]正确:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
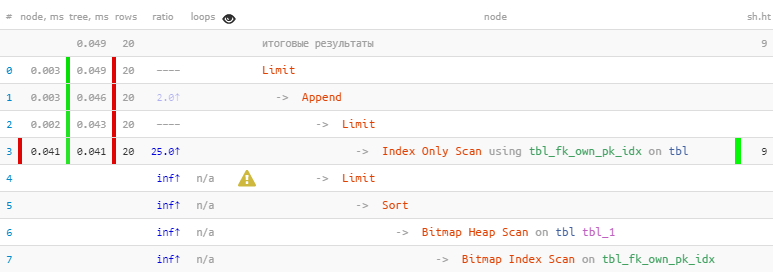 [请看explorer.tensor.ru]我们利用了以下事实:第一个块中立即收到了所有20条必要的记录,因此,第二个记录的位图堆扫描更为“昂贵”,甚至没有执行-结果是,速度比以前快22倍。读数减少44倍!
[请看explorer.tensor.ru]我们利用了以下事实:第一个块中立即收到了所有20条必要的记录,因此,第二个记录的位图堆扫描更为“昂贵”,甚至没有执行-结果是,速度比以前快22倍。读数减少44倍!可以在PostgreSQL反模式文章中找到有关使用特定示例的这种优化方法的更详细的故事:有害的JOIN和OR和PostgreSQL反模式:关于按名称迭代优化搜索的故事,或“在那里进行优化”。SQL HowTo文章中考虑了通过多个键(而不只是const / NULL对)进行
的有序选择的通用版本:我们直接在查询中编写while循环,即“基本三向”。
#4:阅读很多不必要的东西
什么时候出现
通常,如果您想“固定另一个过滤器”到现有请求中,就会出现这种情况。“您没有,但带有珍珠纽扣吗?” 电影《钻石手》
例如,修改上面的任务,显示前20个最古老的“关键”应用程序进行处理,无论其用途如何。如何识别
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
推荐建议
使用WHERE子句
创建[更多]自定义索引,或在索引中包含其他字段。如果您的任务的过滤条件为``静态''-也就是说,将来不涉及扩展值列表-最好使用WHERE索引。不同的布尔/枚举状态非常适合此类别。
如果过滤条件可以采用不同的值,则最好使用这些字段扩展索引-就像上面的BitmapAnd一样。
例:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [看explain.tensor.ru]正确:
[看explain.tensor.ru]正确:CREATE INDEX ON tbl(pk)
WHERE critical;
 [请看explorer.tensor.ru]如您所见,过滤已从计划中完全消失,请求速度提高了5倍。
[请看explorer.tensor.ru]如您所见,过滤已从计划中完全消失,请求速度提高了5倍。#5:稀疏表
什么时候出现
当表上记录的大量更新/删除导致大量“死”记录的情况时,各种尝试使自己的处理任务排队。如何识别
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
推荐建议
手动手动执行VACUUM [FULL]或通过微调其参数(包括针对特定表的参数)来实现自动频繁的真空测试。在大多数情况下,这些问题是由从业务逻辑进行调用时结构不良的查询引起的,例如PostgreSQL反模式中讨论的那些:与“死角”作战。
但是您需要了解,即使VACUUM FULL可能也不一定总是有帮助。在这种情况下,您应该熟悉DBA文章中的算法:VACUUM通过时,我们将手动清理表。
#6:从索引中间读取
什么时候出现
看来他们阅读不多,而且全部都是按索引阅读的,并且他们没有过滤其他任何内容-但无论如何,阅读的页面明显多于我们想要的。如何识别
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
推荐建议
仔细查看所使用索引的结构和在请求中指定的键字段-很可能未指定部分索引。最有可能的是,您将不得不创建一个相似的索引,但是没有前缀字段,或者学习如何遍历它们的值。例:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [看explorer.tensor.ru]即使按索引看,一切似乎都还不错,但出于某种原因却令人怀疑-对于20条读取的记录,我不得不减去4页数据,每条记录32KB-这不是大胆吗?是的,该索引的名称具有暗示性。
我们修复:
[看explorer.tensor.ru]即使按索引看,一切似乎都还不错,但出于某种原因却令人怀疑-对于20条读取的记录,我不得不减去4页数据,每条记录32KB-这不是大胆吗?是的,该索引的名称具有暗示性。
我们修复:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
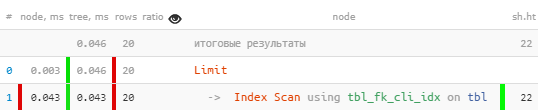 [看一下explain.tensor.ru]突然- 快10倍,少读4倍!
[看一下explain.tensor.ru]突然- 快10倍,少读4倍!在DBA文章:查找无用索引中可以看到索引使用效率低下的其他示例。
#7:CTE×CTE
什么时候出现
在查询中,我们键入了来自不同表的“胖” CTE,然后决定在它们之间进行操作JOIN。该情况与v12以下的版本或的要求有关WITH MATERIALIZED。如何识别
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
推荐建议
仔细分析请求- 此处是否需要CTE?如果全部相同,则根据PostgreSQL Antipatterns中描述的模型在hstore / json中应用“撕裂” :用沉重的JOIN击中字典。#8:交换到磁盘(临时写入)
什么时候出现
大量记录的一次性处理(排序或唯一化)不适合为此分配的内存。如何识别
-> *
&& temp written > 0
推荐建议
如果操作使用的内存量没有大大超过work_mem参数的设置值,则值得对其进行调整。您可以立即在每个人的配置中,但是您可以通过SET [LOCAL]进行特定的请求/事务。例:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [看explain.tensor.ru]正确:
[看explain.tensor.ru]正确:SET work_mem = '128MB';
 [请看explorer.tensor.ru]出于显而易见的原因,如果仅使用内存而不是磁盘,则请求的执行速度将大大提高。同时,HDD的部分负载也被删除。但是您需要了解,分配大量内存始终也不起作用-这对每个人来说都是不够的。
[请看explorer.tensor.ru]出于显而易见的原因,如果仅使用内存而不是磁盘,则请求的执行速度将大大提高。同时,HDD的部分负载也被删除。但是您需要了解,分配大量内存始终也不起作用-这对每个人来说都是不够的。#9:不相关的统计
什么时候出现
他们立刻大量地注入了数据库,但是并没有设法把他们赶走ANALYZE。如何识别
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
推荐建议
做同样的事情ANALYZE。PostgreSQL Antipatterns中对此情况进行了更详细的描述:统计信息充斥着所有的内容。
#10:“出了点问题”
什么时候出现
预期竞争请求会施加锁定,或者没有足够的CPU /管理程序硬件资源。如何识别
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
推荐建议
使用外部系统监视服务器的锁或异常资源消耗。关于用于数百台服务器的此过程的组织版本,我们已经在这里和这里讨论过。