 嗨,我叫Andrey Schukin,我帮助大公司将服务和系统迁移到CROC Cloud。最近,我们与Southbridge的同事(在Slerm培训中心开设了Kubernetes课程)一起为客户举办了网络研讨会。我决定从Pavel Selivanov的精彩演讲中学习资料,并为刚开始使用云资源调配工具但不知道从哪里开始的人们写一篇文章。因此,我将讨论在CROC Cloud的培训和生产中使用的技术堆栈。让我们谈谈基础架构管理的现代方法,一堆Packer,Terraform和Ansible组件,以及我们将用来安装的Kubeadm工具。剪切下将包含大量文本和配置。有很多资料,所以我添加了帖子导航。我们还准备了一个小型存储库,用于存放培训部署所需的一切。不要给鸡起名字,因为烤蛋糕比炸蛋糕更健康,我们启动烤箱。PackerTerraform-作为代码的基础结构启动Terraform集群结构KubernetesKubeadm存储库,包含所有文件
嗨,我叫Andrey Schukin,我帮助大公司将服务和系统迁移到CROC Cloud。最近,我们与Southbridge的同事(在Slerm培训中心开设了Kubernetes课程)一起为客户举办了网络研讨会。我决定从Pavel Selivanov的精彩演讲中学习资料,并为刚开始使用云资源调配工具但不知道从哪里开始的人们写一篇文章。因此,我将讨论在CROC Cloud的培训和生产中使用的技术堆栈。让我们谈谈基础架构管理的现代方法,一堆Packer,Terraform和Ansible组件,以及我们将用来安装的Kubeadm工具。剪切下将包含大量文本和配置。有很多资料,所以我添加了帖子导航。我们还准备了一个小型存储库,用于存放培训部署所需的一切。不要给鸡起名字,因为烤蛋糕比炸蛋糕更健康,我们启动烤箱。PackerTerraform-作为代码的基础结构启动Terraform集群结构KubernetesKubeadm存储库,包含所有文件不要给鸡起名字
 基础架构管理有许多不同的概念。其中之一被称为“宠物大战”。牛,即“反对牲畜的宠物”。这个概念描述了两种相反的基础架构方法。想象一下,我们有一只喜欢的狗。我们照顾她,把他带到兽医那里,梳理皮毛,总的来说,这是我们在许多其他狗中所独有的。在另一种情况下,我们有一个鸡舍。我们还照顾鸡,饲料,热量,并努力创造最舒适的环境。然而,对于我们来说,鸡是一种面目全非的资源,它可以完成产卵的功能,并且充其量我们将它们指定为“总是会粘水泥的黑色粉末”。如果鸡肉停止产卵或断爪,那么很可能会简单地为我们提供美味的午餐肉汤。实际上,我们并不关心单个鸡的命运,而是整个鸡舍作为一条生产线。在IT中,一旦出现了可降低工程师入门门槛的工具,并使其能够以全自动模式部署和维护复杂集群,便开始采用类似的方法。以前,我们只对少数服务器进行了监视,手动调整和以各种可能的方式进行维护。在监视过程中,来自Cthulhu,Aylith和Dagon服务器的日志闪烁了。传统。然后虚拟化牢固地进入了我们的生活,Lovecraft和《星际迷航》的作品名称被更实用的“ vlg-vlt-vault01.company.ru”取代。服务器很多,但是我们还是手动或多或少地提高了服务的质量,必要时消除了每台计算机上的问题。现在,维护基础结构的方法与编程完全一致。我们添加了另一个抽象级别,并且不再为单个节点烦恼。每个虚拟机都有一个匿名索引而不是名称,并且在出现问题的情况下,虚拟机只会杀死工作快照并从工作快照中删除。有一些工具可让您实施此方法。在我们的例子中,第一个工具是CROC Cloud,第二个是Terraform。
基础架构管理有许多不同的概念。其中之一被称为“宠物大战”。牛,即“反对牲畜的宠物”。这个概念描述了两种相反的基础架构方法。想象一下,我们有一只喜欢的狗。我们照顾她,把他带到兽医那里,梳理皮毛,总的来说,这是我们在许多其他狗中所独有的。在另一种情况下,我们有一个鸡舍。我们还照顾鸡,饲料,热量,并努力创造最舒适的环境。然而,对于我们来说,鸡是一种面目全非的资源,它可以完成产卵的功能,并且充其量我们将它们指定为“总是会粘水泥的黑色粉末”。如果鸡肉停止产卵或断爪,那么很可能会简单地为我们提供美味的午餐肉汤。实际上,我们并不关心单个鸡的命运,而是整个鸡舍作为一条生产线。在IT中,一旦出现了可降低工程师入门门槛的工具,并使其能够以全自动模式部署和维护复杂集群,便开始采用类似的方法。以前,我们只对少数服务器进行了监视,手动调整和以各种可能的方式进行维护。在监视过程中,来自Cthulhu,Aylith和Dagon服务器的日志闪烁了。传统。然后虚拟化牢固地进入了我们的生活,Lovecraft和《星际迷航》的作品名称被更实用的“ vlg-vlt-vault01.company.ru”取代。服务器很多,但是我们还是手动或多或少地提高了服务的质量,必要时消除了每台计算机上的问题。现在,维护基础结构的方法与编程完全一致。我们添加了另一个抽象级别,并且不再为单个节点烦恼。每个虚拟机都有一个匿名索引而不是名称,并且在出现问题的情况下,虚拟机只会杀死工作快照并从工作快照中删除。有一些工具可让您实施此方法。在我们的例子中,第一个工具是CROC Cloud,第二个是Terraform。烤蛋糕比油炸更健康
 在基础架构管理中,两种方法之间存在对比。烤,即“炒反对烤”。Fried方法意味着您拥有原始的OS映像,例如CentOS7。然后,在部署OS之后,我们使用配置管理系统以使系统进入目标状态。例如,使用Ansible,Chef,Puppet或SaltStack。一切正常,尤其是在服务器数量不多的情况下。当需要大规模部署时,我们将面临性能问题。在推出许多新软件包的过程中,数百台服务器同步开始吞噬网络资源,CPU,RAM和IOPS。此外,此过程可能会延迟相当长的时间。简而言之,该电路绝对是可操作的,但从最大限度地减少事故期间的停机时间的角度来看,它并不是那么有趣。Baked方法意味着您已经准备好了“ baked” OS映像,在该映像上您已经安装了所有必需的软件包,配置了配置以及所有其他内容。在输出中,我们有一个抽象的快照模板,针对某些功能的性能进行了优化。从此类烘焙的映像部署基础架构所花费的时间大大减少,并将停机时间降至最低。多层Docker映像中使用了非常相似的意识形态,其中没有人不必要地伸手。钉好容器-捡起一个新的。
在基础架构管理中,两种方法之间存在对比。烤,即“炒反对烤”。Fried方法意味着您拥有原始的OS映像,例如CentOS7。然后,在部署OS之后,我们使用配置管理系统以使系统进入目标状态。例如,使用Ansible,Chef,Puppet或SaltStack。一切正常,尤其是在服务器数量不多的情况下。当需要大规模部署时,我们将面临性能问题。在推出许多新软件包的过程中,数百台服务器同步开始吞噬网络资源,CPU,RAM和IOPS。此外,此过程可能会延迟相当长的时间。简而言之,该电路绝对是可操作的,但从最大限度地减少事故期间的停机时间的角度来看,它并不是那么有趣。Baked方法意味着您已经准备好了“ baked” OS映像,在该映像上您已经安装了所有必需的软件包,配置了配置以及所有其他内容。在输出中,我们有一个抽象的快照模板,针对某些功能的性能进行了优化。从此类烘焙的映像部署基础架构所花费的时间大大减少,并将停机时间降至最低。多层Docker映像中使用了非常相似的意识形态,其中没有人不必要地伸手。钉好容器-捡起一个新的。我们启动烤箱。封隔器
 在我们的基础架构中,我们使用了几种Hashicorp产品,其中有些被证明是非常成功的。让我们开始使用Packer工具准备和烘焙图像的魔术。Packer使用JSON模板,即包含描述需要作为“烘焙”虚拟机(VM)获得的内容的模板文件。创建模板后,文件将传输到Packer,并配置了在云中创建服务器的必要权限。Packer允许您在KVM,VirtualBox,Vagrant,AWS,GCP,阿里云,OpenStack等本地提升VM。在CROC Cloud中与Packer一起使用很方便,因为它实现了AWS接口,即为该接口编写的所有工具。 AWS,与CROC云一起使用。设置必要的模板后,Packer在云中引发VM CROC,等待其启动,然后“提供者”进入工作-Provisioner:必须完成映像准备的实用程序。在本例中,这是Ansible,尽管Packer可以与其他选项一起使用。VM准备就绪后,Packer会创建其映像并将其放置在CROC Cloud中,以便可以从同一映像启动其他VM。
在我们的基础架构中,我们使用了几种Hashicorp产品,其中有些被证明是非常成功的。让我们开始使用Packer工具准备和烘焙图像的魔术。Packer使用JSON模板,即包含描述需要作为“烘焙”虚拟机(VM)获得的内容的模板文件。创建模板后,文件将传输到Packer,并配置了在云中创建服务器的必要权限。Packer允许您在KVM,VirtualBox,Vagrant,AWS,GCP,阿里云,OpenStack等本地提升VM。在CROC Cloud中与Packer一起使用很方便,因为它实现了AWS接口,即为该接口编写的所有工具。 AWS,与CROC云一起使用。设置必要的模板后,Packer在云中引发VM CROC,等待其启动,然后“提供者”进入工作-Provisioner:必须完成映像准备的实用程序。在本例中,这是Ansible,尽管Packer可以与其他选项一起使用。VM准备就绪后,Packer会创建其映像并将其放置在CROC Cloud中,以便可以从同一映像启动其他VM。Base.json结构
在文件的开头,有一个部分声明了变量:扰流板"variables" : {
"source_ami_name": "{{env SOURCE_AMI_NAME}}",
"ami_name": "{{env AMI_NAME}}",
"instance_type": "{{env INSTANCE_TYPE}}",
"kubernetes_version": "{{env KUBERNETES_VERSION}}",
"docker_version": "{{env DOCKER_VERSION}}",
"subnet_id": "",
"availability_zone": "",
},
这些变量的主要集合将在settings.json文件中进行设置。当启动Packer并构建新映像时,那些经常更改的变量更易于从控制台进行设置。以下是“构建器”部分:扰流板"builders" : [
{
"type": "amazon-ebs",
"region": "croc",
"skip_region_validation": true,
"custom_endpoint_ec2": "https://api.cloud.croc.ru",
"source_ami": "",
"source_ami_filter": {
"filters": {
"name": "{{user `source_ami_name`}}"
"state": "available",
"virtualization-type": "kvm-virtio"
},
...
在此介绍目标云和VM启动方法。请注意,在这种情况下,声明了amazon-ebs类型,但是对于Packer与CROC Cloud的操作,将在custom_endpoint_ec2中设置相应的地址。我们的基础架构具有一个几乎与Amazon Web Services完全兼容的API,因此,如果您已经为此平台进行了现成的开发,那么在大多数情况下,您仅需要指定一个自定义API入口点- 在我们的示例中为api.cloud.croc.ru。值得一提的是source_ami_filter部分。在此设置VM的初始映像,在其中进行必要的更改。但是,Packer对此图像要求使用AMI,即其随机标识符。由于此标识符事先很少知道,并且每次更新都会更改,因此源AMI的设置不是设置为特定值,而是设置为变量source_ami_filter。在这种情况下,过滤器的确定参数是图像的名称。此名称是通过settings.json文件在变量中设置的。接下来,定义VM设置:指定实例的类型,处理器,内存大小,分配的空间等:扰流板"instance_type": "{{user `instance_type`}}",
"launch_block_device_mappings": [
{
"device_name": "disk1",
"volume_type": "io1",
"volume_size": "8",
"iops": "1000",
"delete_on_termination": "true"
}
],
base.json中的以下是连接到此VM的参数:扰流板"availability_zone": "{{user `availability_zone`}}",
"subnet_id": "{{user `subnet_id`}}",
"associate_public_ip_address": true,
"ssh_username": "ec2-user",
"ami_name": "{{user `ami_name`}}"
在此处注意subnet_id参数很重要。必须手动设置它,因为如果未在CROC Cloud中指定VM子网,则无法创建。需要预先准备的另一个参数是associate_public_ip_address。您需要选择一个白色IP地址,因为在创建VM Packer之后,将开始通过Ansible应用必要的设置。同时,Ansible通过SSH连接到VM,这需要白色IP地址或VPN。最后一部分是预配器:扰流板"provisioners": [
{
"type": "ansible",
"playbook_file": "playbook.yml",
"extra_arguments": [
"--extra-vars",
"kubernetes_version={{user `kubernetes_version`}}",
"--extra-vars",
"docker_version={{user `docker_version`}}"
]
}
]
这些是提供程序,即Packer用于配置服务器的实用程序。在这种情况下,将使用ansible类型提供程序。以下是playbook_file参数,该参数定义Ansible角色以及将在其上应用指定角色的主机。下面介绍了其他选项extra_arguments,这些选项在启动Ansible时会传输Kubernetes和Docker的版本。CROC云准备
 除了我们的配置文件,我们还需要从云控制面板的侧面执行一些操作,以便所有魔术都能正常工作。我们需要选择一个白色IP并创建一个工作子网,在部署时将使用该子网。
除了我们的配置文件,我们还需要从云控制面板的侧面执行一些操作,以便所有魔术都能正常工作。我们需要选择一个白色IP并创建一个工作子网,在部署时将使用该子网。- 单击突出显示地址。Packer会自行找到所需的白色IP地址。
- 单击创建子网,然后指定一个子网和掩码。
- 复制子网ID。
- 将此值插入Packer启动命令的subnet_id参数。
 然后运行Packer。他找到原始的VM映像,将其部署在CROC Cloud中,并在其上执行Ansible角色。可以在CROC Cloud的“实例”部分中看到新的VM。
然后运行Packer。他找到原始的VM映像,将其部署在CROC Cloud中,并在其上执行Ansible角色。可以在CROC Cloud的“实例”部分中看到新的VM。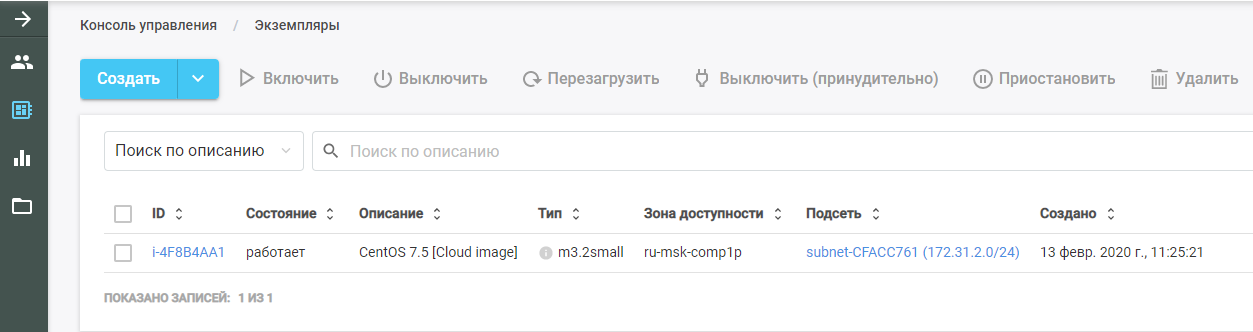
 完成工作后,Packer从云中删除VM,并在其位置保留一个现成的映像,可以在“模板”部分中找到该映像。整个Kubernetes基础架构将根据该映像创建。
完成工作后,Packer从云中删除VM,并在其位置保留一个现成的映像,可以在“模板”部分中找到该映像。整个Kubernetes基础架构将根据该映像创建。Ansible
如前所述,playbook参数在Ansible提供程序的参数中传递。playbook.yml文件本身如下所示:- hosts: all
become: true
roles:
| - base
该文件传输到Ansible,在所有主机上都必须履行base的角色。如果还有其他角色,则可以将它们作为列表添加到同一文件中。基本角色使您可以通过单个命令获得现成的集群。main.yml文件显示了此角色的确切作用:- 将Docker存储库添加到系统模板。
- 将Kubernetes存储库添加到系统模板。
- 安装必要的软件包。
- 创建用于配置Docker守护程序的目录。
- 根据daemon.json.j2配置文件配置机器。
- 加载br_netfilter内核。
- 包括br_netfilter的必要选项。
- 包括Docker和Kubelet组件。
- 在VM中运行Docker。
- 运行一个命令,该命令下载Kubernetes正常工作所需的Docker映像。
在这种情况下,已安装的软件包在vars目录的main.yml文件中设置。在我们的案例中,我们安装了docker-ce软件包以及Kubernetes正常工作所需的三个软件包:kubelet,kubeadm和kubectl。Terraform-基础架构即代码
 Terraform是HashiCorp提供的非常有用的工具,用于进行云编排。它具有自己的特定HCL语言,该语言通常在公司的其他产品中使用,例如,在HashiCorp Vault和Consul中。基本原理类似于所有配置管理系统。您只需以所需格式指示目标状态,然后系统会计算如何实现此目标的算法。另一件事是,与同一个Ansible(在复杂的剧本上充当黑匣子)不同,Terraform可以以便于分析的形式发布未来行动计划。在计划复杂的基础架构更改时,这一点很重要。在计划了必要的操作之后,运行terraform apply命令,Terraform将部署文件中描述的基础结构。像Packer一样,此工具支持AWS,GCP,阿里云,Azure,OpenStack,VMware等。
Terraform是HashiCorp提供的非常有用的工具,用于进行云编排。它具有自己的特定HCL语言,该语言通常在公司的其他产品中使用,例如,在HashiCorp Vault和Consul中。基本原理类似于所有配置管理系统。您只需以所需格式指示目标状态,然后系统会计算如何实现此目标的算法。另一件事是,与同一个Ansible(在复杂的剧本上充当黑匣子)不同,Terraform可以以便于分析的形式发布未来行动计划。在计划复杂的基础架构更改时,这一点很重要。在计划了必要的操作之后,运行terraform apply命令,Terraform将部署文件中描述的基础结构。像Packer一样,此工具支持AWS,GCP,阿里云,Azure,OpenStack,VMware等。我们描述这个项目
Terraform目录包含一组扩展名为.tf的文件。这些文件描述了我们将使用的基础架构的组件。将项目分为功能模块。这种结构使控制版本控制和从现成的方便块中组装每个项目变得更加容易。对于我们的选择,以下结构是合适的:- 主文件
- 网络
- security_groups.tf
- 大师
- master.tpl
Main.tf文件结构
让我们从main.tf文件开始,在其中配置对云的访问。特别是,宣布了一些参数,这些参数将Terraform配置为与CROC Cloud一起使用:provider "aws" {
endpoints {
ec2 = "https://api.cloud.croc.ru"
}
此外,该文件还描述了Terraform必须独立创建私钥并将其公共部分上传到所有服务器。私钥本身在Terraform的末尾发布:resource "tls_private_key" "ssh" {
algorithm = "RSA"
}
resource "aws_key_pair" "kube" {
key_name = "terraform"
public_key = "${tls_private_key.ssh.public_key_openssh}"
}
output "ssh" {
value = "${tls_private_key.ssh.private_key_pem}"
}
network.tf文件的结构
此文件描述了启动虚拟机所需的网络组件:扰流板data "aws_availability_zones" "az" {
state = "available"
}
resource "aws_vpc" "kube" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_eip" "master" {
count = "1"
vpc = true
}
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.kube.id}"
count = "${length(data.aws_availability_zones.az.names)}"
cidr_block = "${var.private_subnet_cidr_list[count.index]}"
availability_zone = "${data.aws_availability_zones.az.names[count.index]}"
}
Terraform使用两种类型的组件:在这种情况下,data参数指示Terraform应该接收处于可用状态的指定云的可用性区域。第一个参数资源描述虚拟私有云的创建,第二个参数描述弹性IP地址的创建。对于Kubernetes集群,我们通过Terraform订购该IP地址。此外,在每个可访问区域中,当CROC具有两个云服务时,将创建其自己的子网。声明aws_subnet类型的资源,并将生成的aws_vpc的ID作为此参数的一部分传递。但是,由于该资源的ID仍然未知,因此我们指定aws_vpc.kube.id参数,该参数引用创建的资源并替换ID字段中的值。由于创建的子网的数量由云可用区的数量决定,并且此数量可以随时间变化,因此可以通过长度变量(data.aws_availability_zones.az.names)设置此参数,即通过data参数接收的访问区列表的长度。最后两个参数是cidr_block(分配的子网)和在其中创建该子网的可用性区域。最后一个参数也是通过一个变量设置的,该变量根据[count.index]声明的循环索引从数据列表中获取一个值。Security_groups.tf文件结构
安全组是一种用于云的防火墙,它不能在VM本身内部创建,而可以由云创建。在这种情况下,防火墙描述了两个规则。第一条规则创建一个称为kube的安全组。需要此安全组以允许来自Kubernetes节点的所有传出流量,从而允许节点自由访问Internet。还允许从节点本身的子网到Kubernetes节点的入站流量。因此,Kubernetes节点可以在彼此之间不受限制地工作。第二条规则创建ssh安全组。它允许从任何IP地址到Kubernetes集群VM的端口22的SSH连接:扰流板resource "aws_security_group" "kube" {
vpc_id = "${aws_vpc.kube.id}"
name = "kubernetes"
# Allow all outbound
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
# Allow all internal
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["${var.vpc_cidr}"]
}
}
resource "aws_security_group" "ssh" {
vpc_id = "${aws_vpc.kube.id}"
name = "ssh"
# Allow all inbound
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
主节点。Master.tf的文件结构
master.tf文件描述了几个模板和实例的创建。特别是,正在创建一个Kubernetes主实例。ami变量设置VM的源映像的AMI。下面介绍VM的类型以及在其中创建子网的子网。定义子网时,将再次使用一个循环在每个可用性区域中创建VM。接下来,声明使用的安全组和在main.tf文件中指定的密钥。user_data字段包含一组cloud-init脚本的执行,其结果将在VM中实现:扰流板resource "aws_instance" "master" {
count = "1"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
disable_api_termination = false
instance_initiated_shutdown_behavior = "terminate"
source_dest_check = false
subnet_id = "${aws_subnet.private.*.id[count.index % length(data.aws_availability_zones.az.names)]}"
associate_public_ip_address = true
vpc_security_group_ids = [
"${aws_security_group.ssh.id}",
"${aws_security_group.kube.id}",
]
key_name = "${aws_key_pair.kube.key_name}"
user_data = "${data.template_cloudinit_config.master.rendered}"
monitoring = "true"
}
主节点。云初始化
Cloud-init是Canonical正在开发的工具。它允许您在启动VM之后在云基础架构中自动执行某些命令集。Terraform具有使用模板与其集成的机制。由于无法“烘焙” VM中的所有必需内容,因此启动后,根据其类型,它必须加入Kubernetes集群或初始化Kubernetes集群。在名为master.tpl的cloud-init文件模板中,执行了几个操作。1.记录Kubeadm的配置文件:#cloud-config
write_files:
- path: etc/kubernetes/kubeadm.conf
owner: root:root
content:
...
2.执行一组命令:- 向导的IP地址被写入生成的配置文件中;
- 用kubeadm init命令初始化Kubernetes集群中的master;
- 在Kubernetes集群中,使用kubectl apply命令安装了Calico覆盖网络。
runcmd:
- sed -i "s/CONTROL_PLANE_IP/$(curl http://169.254.169.254/latest/meta-data-local-ipv4)/g" /etc/kubernetes/kubeadm.conf
- kubeadm init --config /etc/kubernetes/kubeadm.conf
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
启动虚拟机后执行命令后,将从一个主节点获得一个可用的Kubernetes集群。其余节点将加入此主节点。普通节点。节点
node.tf文件类似于master.tf文件。资源也在这里创建,在这种情况下称为节点。唯一的区别是,主节点是在单个实例中创建的,而创建的工作节点的数量是通过nodes_count变量设置的:resource "aws_instance" "node" {
count = "${var.nodes_count}"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
用于工作节点的cloud-init文件仅执行一个命令-kubeadm join。该命令使用我们发送的授权令牌将完成的机器连接到Kubernetes集群。启动Terraform
启动时,Terraform使用以下模块:这些模块必须安装在本地计算机上:terraform init terraform/
与该命令一起,指出了所有必需文件所在的目录。初始化时,Terraform将下载所有指定的模块,然后您需要执行terraform plan命令:terraform plan -var-file terraform/vars/dev.tfvars terraform/
请注意,除了包含Terraform文件的目录外,还指示var文件,其中包含Terraform文件中使用的变量的值。vars目录可以包含多个.tfvars文件,这使您可以使用一组Terraform文件来管理不同类型的基础结构。dev.tfvars文件本身包含以下重要变量:- Kubernetes_version(Kubernetes的可安装版本);
- Kubernetes_ami(Packer创建的AMI映像)。
设置变量的必要值后,运行terraform plan命令,之后Terraform将显示实现Terraform文件中描述的状态所需的动作列表。在检查了此列表之后,应用建议的更改:terraform apply -auto-approve -var-file terraform/vars/dev.tfvars terraform/从terraform plan命令中,它的区别在于存在密钥-自动批准,从而无需确认所做的更改。您可以省略此键,但是随后需要手动确认每个操作。Kubernetes集群结构
 Kubernetes集群由执行管理功能的主节点和运行集群中安装的应用程序的工作节点组成。主节点上安装了四个组件,以确保此系统的运行:
Kubernetes集群由执行管理功能的主节点和运行集群中安装的应用程序的工作节点组成。主节点上安装了四个组件,以确保此系统的运行:- ETCD,即Kubernetes数据库
- API服务器,通过它我们在Kubernetes中存储信息并从中获取信息;
- 财务经理
- 排程器
在工作节点上安装了两个附加组件:- Kube-proxy(负责在Kubernetes集群中生成网络规则);
- Kubelet(负责将命令发送到Docker守护程序以在Kubernetes集群中运行应用程序)。
在节点之间,Calico网络插件可以工作。集群工作流程图
, Kubernetes replicaset.
- API-, ETCD. .
- API- .
- Controller-manager API- , «», .
- Scheduler . ETCD API-.
- Kubelet API- Docker .
- Docker .
- Kubelet API- , .
, Kubernetes , . , , YAML-. , , API-. .
库贝姆
 值得一提的最后一个要素是库贝阿姆。部署新的Kubernetes集群始终是一个艰苦的过程。在每个阶段,都有人为因素导致错误的风险,并且许多任务非常日常且冗长。例如,在节点之间浇注用于TLS加密的证书,并使它们保持最新。这是用于基本模板自动化的实用工具。Kubeadm的窍门是它已被正式认证可与Kubernetes一起使用。它允许您:
值得一提的最后一个要素是库贝阿姆。部署新的Kubernetes集群始终是一个艰苦的过程。在每个阶段,都有人为因素导致错误的风险,并且许多任务非常日常且冗长。例如,在节点之间浇注用于TLS加密的证书,并使它们保持最新。这是用于基本模板自动化的实用工具。Kubeadm的窍门是它已被正式认证可与Kubernetes一起使用。它允许您:- 安装,配置和运行所有主要的群集组件
- 管理证书,包括旋转证书并写出新证书;
- 管理集群组件版本(升级和降级)。
同时,Kubeadm不是完整的Kubernetes集群管理系统,而是一种构建块,可让您在运行Kubeadm实用程序的节点上配置Kubernetes。这意味着需要一个编排系统,该系统将运行所有必需的VM,对其进行配置并在所有节点上运行Kubeadm。出于这些目的,使用Terraform。包含所有文件的存储库
在这里,我们将所有文件和配置放在一个位置,以便为您提供更多便利。如果您手头没有私有云,但是您想亲自进行所有这些步骤并在实践中测试部署,请通过cloud@croc.ru与我们联系。我们将为您提供测试的演示版本,并就所有问题提供建议。很快将有一个新的Slurm,您可以在其中创建自己的集群。CROC促销代码有10%的折扣。对于已经使用Kubernetes的人,有一门高级课程。折扣是一样的。同事,Habraparser破坏了代码的标记。请从上面的链接获取来自GitHub的源代码。