3月13日,在欧洲电视网YouTube官方频道上,Little Big乐队的成员名单被公布,它将代表俄罗斯参加比赛。看完剪辑后,我想将我们小组视频与其他参与者的视频统计数据进行比较;观看次数最多的视频,喜欢最多的人,评论最多的人。谷歌搜索完成的统计信息没有任何结果。因此,决定收集必要的统计数据。
文章结构:
打开参与者的播放列表,您可以看到39个视频,实际上有38首歌曲,飓风-Hasta La Vista-塞尔维亚的成分被下载了两次,因此将对其进行统计。为了收集统计信息,我们将使用R。
上载验证码
我们将需要以下软件包:
library(tuber) # API YouTube,
library(dplyr) #
library(ggplot2) #
首先,请转到Google开发者控制台,然后在api“ YouTube数据API v3”上创建OAuth密钥。收到密钥后,从R登录。
yt_oauth(" ", " ")
现在我们可以收集统计信息:
#
list_videos <- get_playlist_items(filter = c(playlist_id = "PLmWYEDTNOGUL69D2wj9m2onBKV2s3uT5Y"))
# , get_stats
stats_videos <- lapply(as.character(list_videos$contentDetails.videoId), get_stats) %>%
bind_rows()
stats_videos <- stats_videos %>%
mutate_at(vars(-id), as.integer)
# , get_video_details
description_videos <- lapply(as.character(list_videos$contentDetails.videoId), get_video_details)
description_videos <- lapply(description_videos, function(x) {
list(
id = x[["items"]][[1]][["id"]],
name_video = x[["items"]][[1]][["snippet"]][["title"]]
)
}) %>%
bind_rows()
.. — — [ ] — Official Music Video — Eurovision 2020, , . .
#
description_videos$name_video <- description_videos$name_video %>%
gsub("[^[:alnum:][:blank:]?&/\\-]", '', .) %>%
gsub("( .*)|( - Offic.*)", '', .)
#
df <- description_videos %>%
left_join(stats_videos, by = 'id') %>%
rowwise() %>%
mutate( #
proc_like = round(likeCount / (likeCount + dislikeCount), 2)
) %>%
ungroup()
# Hurricane - Hasta La Vista - Serbia ,
df <- df %>%
group_by(name_video) %>%
summarise(
id = first(id),
viewCount = sum(viewCount),
likeCount = sum(likeCount),
dislikeCount = sum(dislikeCount),
commentCount = sum(commentCount),
proc_like = round(likeCount / (likeCount + dislikeCount), 2)
)
df$color <- ifelse(df$name_video == 'Little Big - Uno - Russia','red','gray')
. .
# -
ggplot(df, aes(x = reorder(name_video, viewCount), y = viewCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "- ") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::number_format(big.mark = " "))
#
ggplot(df, aes(x = reorder(name_video, proc_like), y = proc_like, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = " ") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))
# -
ggplot(df, aes(x = reorder(name_video, commentCount), y = commentCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "- ") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::number_format(big.mark = " "))
#
ggplot(df, aes(x = reorder(name_video, commentCount/viewCount), y = commentCount/viewCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = " ") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.25))
, Little Big 1 , .
. Little Big , . - .
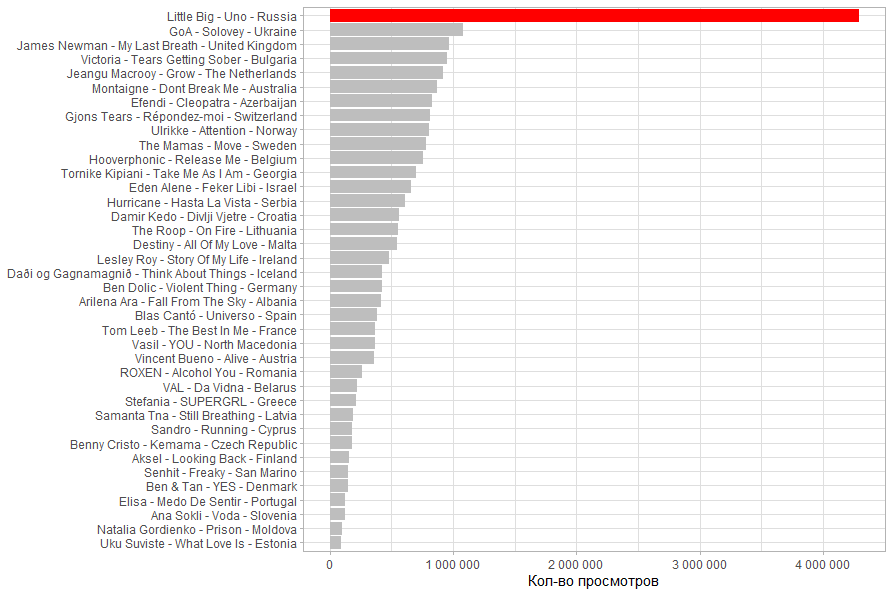
, . . .

.
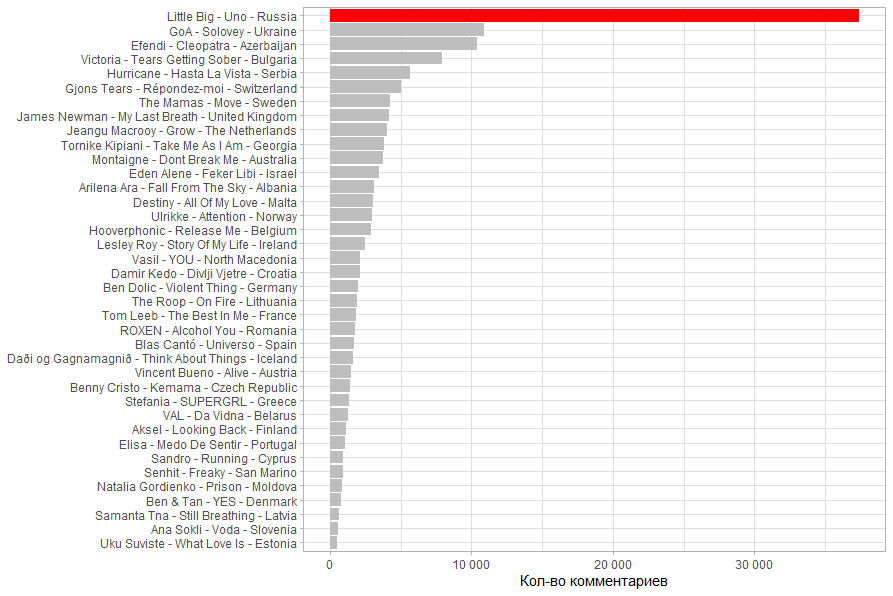
( / ). . .
13.03.2020 18:00 , , , .
UPD: 14.03.2020 20:30
. . Little Big , .

, . Little Big ,

.

( / ). 2 , , , . .

14.03.2020 20:30 , , , , . .
:
helg1978 . .
library(rvest)
library(tidyr)
#
hdoc <- read_html('https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population')
tnode <- html_node(hdoc, xpath = '/html/body/div[3]/div[3]/div[4]/div/table')
df_population <- html_table(tnode)
df_population <- df_population %>% filter(`Country (or dependent territory)` != 'World')
df_population$Population <- as.integer(gsub(',','',df_population$Population,fixed = T))
df_population$`Country (or dependent territory)` <- gsub('\\[.*\\]','', df_population$`Country (or dependent territory)`)
df_population <- df_population %>%
select(
`Country (or dependent territory)`,
Population
) %>%
rename(Country = `Country (or dependent territory)`)
#
df2 <- df %>%
separate(name_video, c('compozitor', 'name_track', 'Country'), ' - ', remove = F) %>%
mutate(Country = ifelse(Country == 'The Netherlands', 'Netherlands', Country)) %>%
left_join(df_population, by = 'Country')
#
cor(df2$viewCount,df2$Population)
ggplot(df2, aes(x = Population, y = viewCount)) +
geom_point() +
theme_light() +
geom_smooth(method = 'lm') +
labs(x = ", ", y = "- ") +
scale_y_continuous(labels = scales::number_format(big.mark = " ")) +
scale_x_continuous(labels = scales::number_format(big.mark = " "))
# ,
cor(df2[df2$Country != 'Russia',]$viewCount,df2[df2$Country != 'Russia',]$Population)
ggplot(df2 %>% filter(Country != 'Russia') , aes(x = Population, y = viewCount)) +
geom_point() +
theme_light() +
geom_smooth(method = 'lm') +
labs(x = ", ", y = "- ") +
scale_y_continuous(labels = scales::number_format(big.mark = " ")) +
scale_x_continuous(labels = scales::number_format(big.mark = " "))
# ,
cor(df2$viewCount,df2$Population, method = "spearman")
ggplot(df2 , aes(x = rank(Population), y = rank(viewCount))) +
geom_point() +
theme_light() +
geom_smooth(method = 'lm') +
labs(x = ", ( 1 40)", y = "- ( 1 40)") +
guides(fill = F)
#
ggplot(df2, aes(x = reorder(name_video, viewCount/Population), y = viewCount/Population, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = " ") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.25))
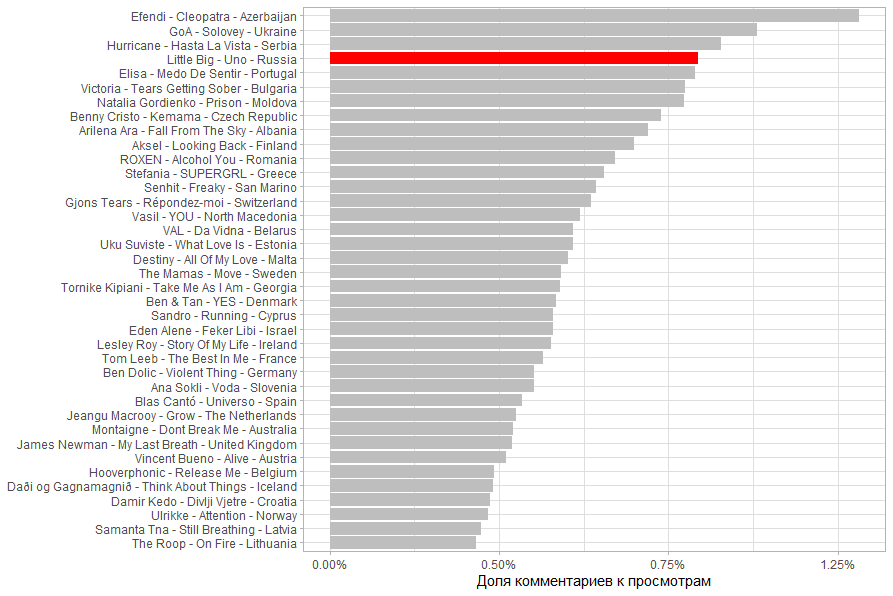
, , 50 . 71%.

. 71% 15%. .

( ), , (. . 40%).

作为参考,我计算了该国人口的观点份额。事实证明,对于特别小的国家而言,其他国家/地区对他们的关注程度更高。特别是马耳他,圣马力诺和冰岛。

完整的github代码