Pandas无需介绍:今天,它已成为使用Python分析数据的主要工具。我是一名数据分析专家,尽管每天我都会使用熊猫,但我对这个库功能的多样性从未感到惊讶。在本文中,我想谈谈我最近学习并可以有效使用的五个鲜为人知的熊猫函数。对于初学者:Pandas是用于Python中数据分析的高性能工具包,具有简单便捷的数据结构。该名称来自“面板数据”的概念,这是一个计量经济学术语,是指有关同一主题在不同时间段内的观测数据。在这里,您可以从文章中下载带有示例的 Jupyter Notebook。1.日期范围[日期范围]
从外部API或数据库请求数据时,通常需要指定日期范围。熊猫不会给我们带来麻烦。就这些情况而言,有data_range函数,该函数返回按天,月,年等增加的日期数组。假设我们需要按日期设置日期范围:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 我们将把生成的从
我们将把生成的从date_range转换为成对的日期“ from”和“ to”,可以将其转换为相应的函数。for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2.与源指标合并[与指标合并]
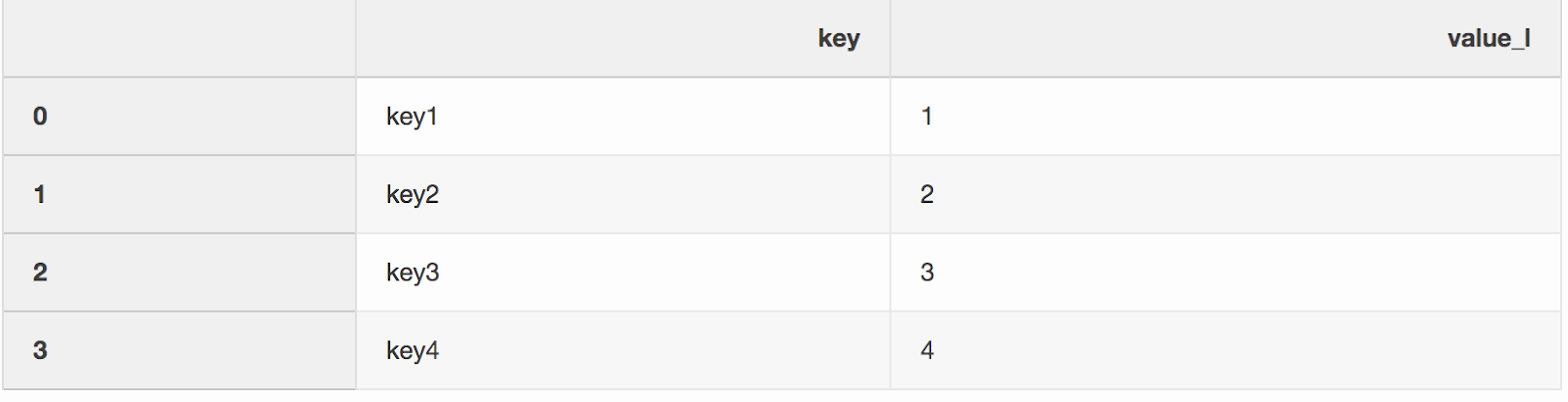
奇怪的是,合并两个数据集就是将两个数据集合并为一个数据集的过程,该数据集的行基于公共列或属性进行映射。我以某种方式错过的合并功能的两个参数之一是indicator。“指示器” _merge在DataFrame中添加一列,以显示行来自左,右,或两个DataFrame的位置。_merge当使用大型数据集来验证合并正确时,列可能非常有用。left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
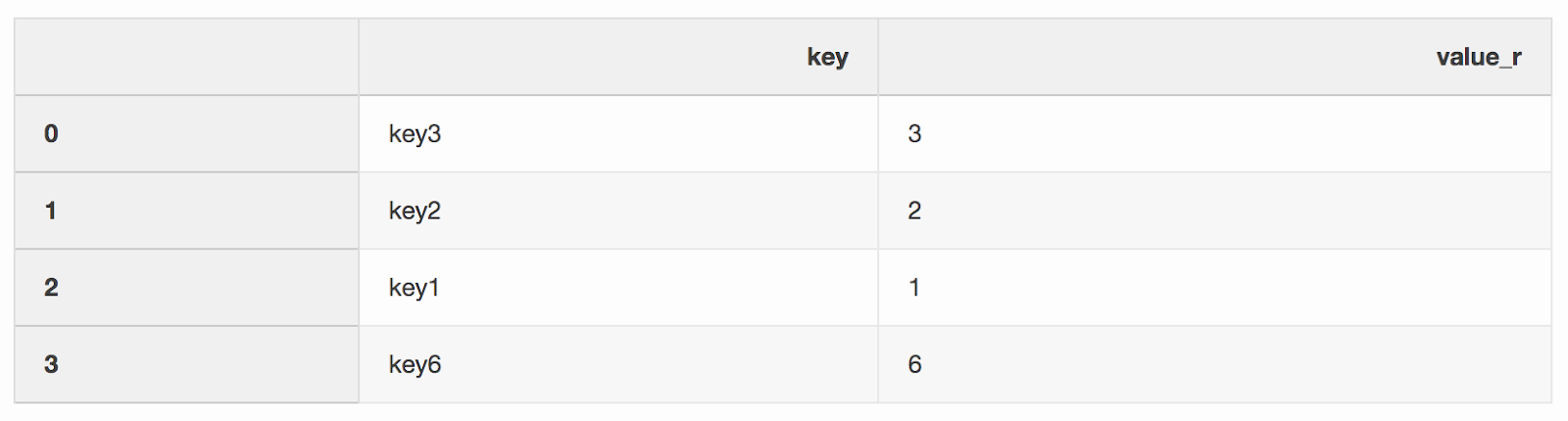
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
df_merge = left.merge(right, on='key', how='left', indicator=True)
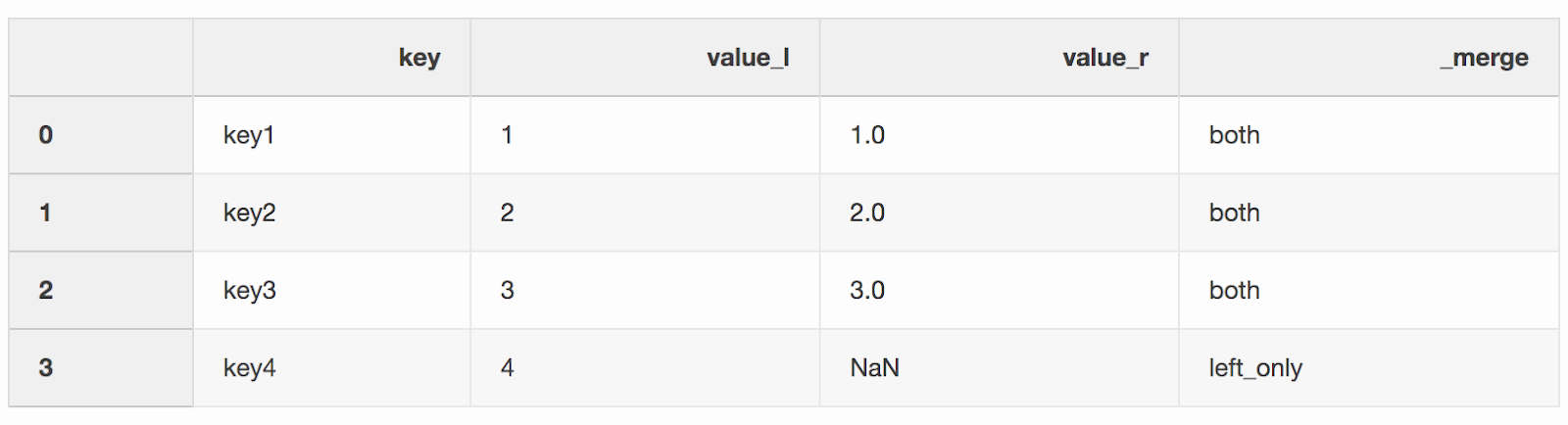 该列
该列_merge可用于检查是否从两个DataFrame中获取了正确的行数。df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3.按最接近的值合并[最近合并]
在处理诸如加密货币和证券之类的财务数据时,可能有必要将报价(价格变化)与交易进行比较。假设我们想将每笔交易与报价相结合,该报价在交易前几毫秒便已更新。Pandas具有一项功能merge_asof,因此可以通过最接近的键值组合DataFrame(timestamp在我们的示例中)。带有报价和交易的数据集取自pandas示例。DataFrame quotes(“报价”)包含不同股票的价格变化。通常,报价多于交易。quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
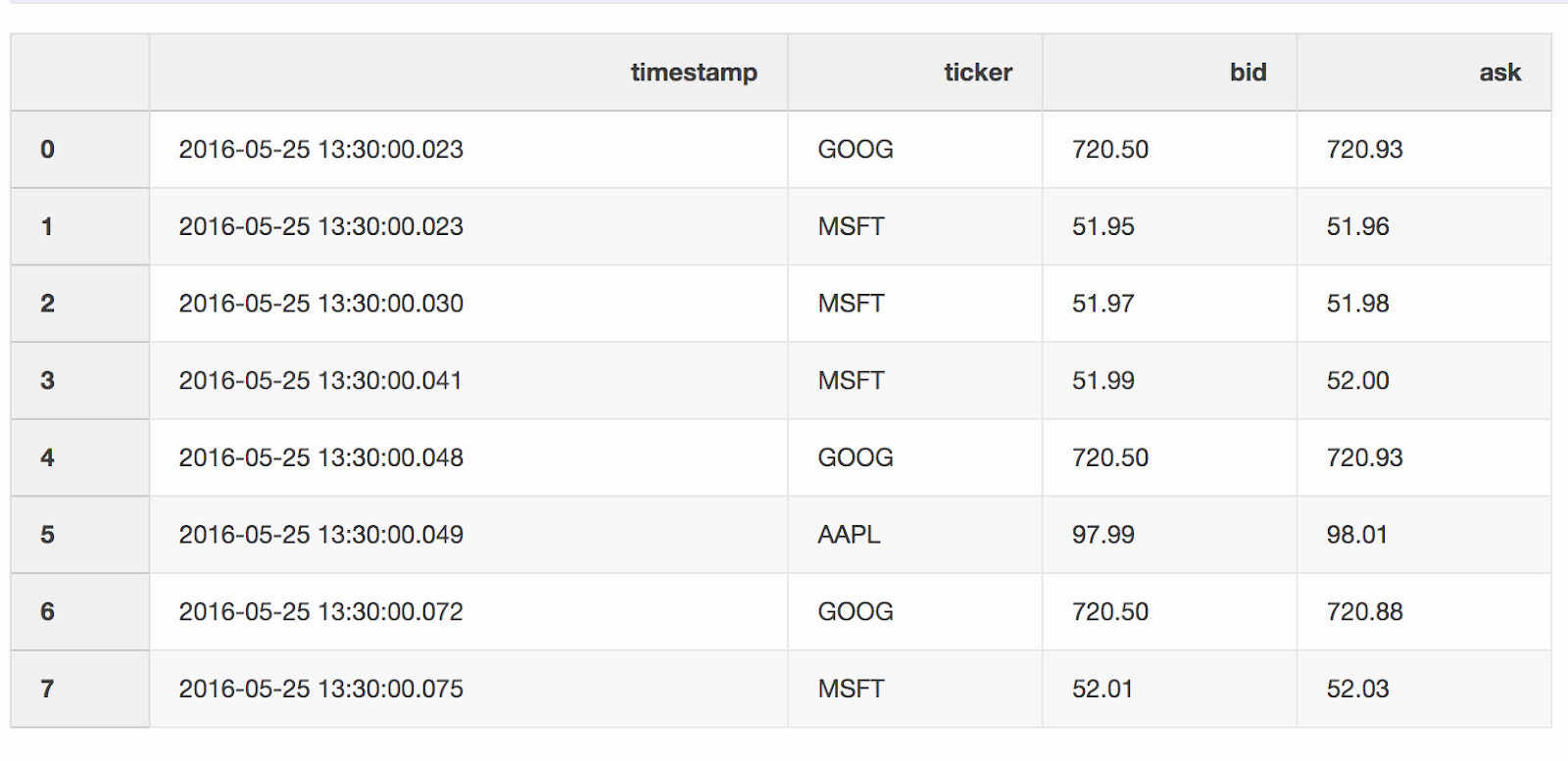 DataFrame
DataFrame trades包含不同股票的交易。trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
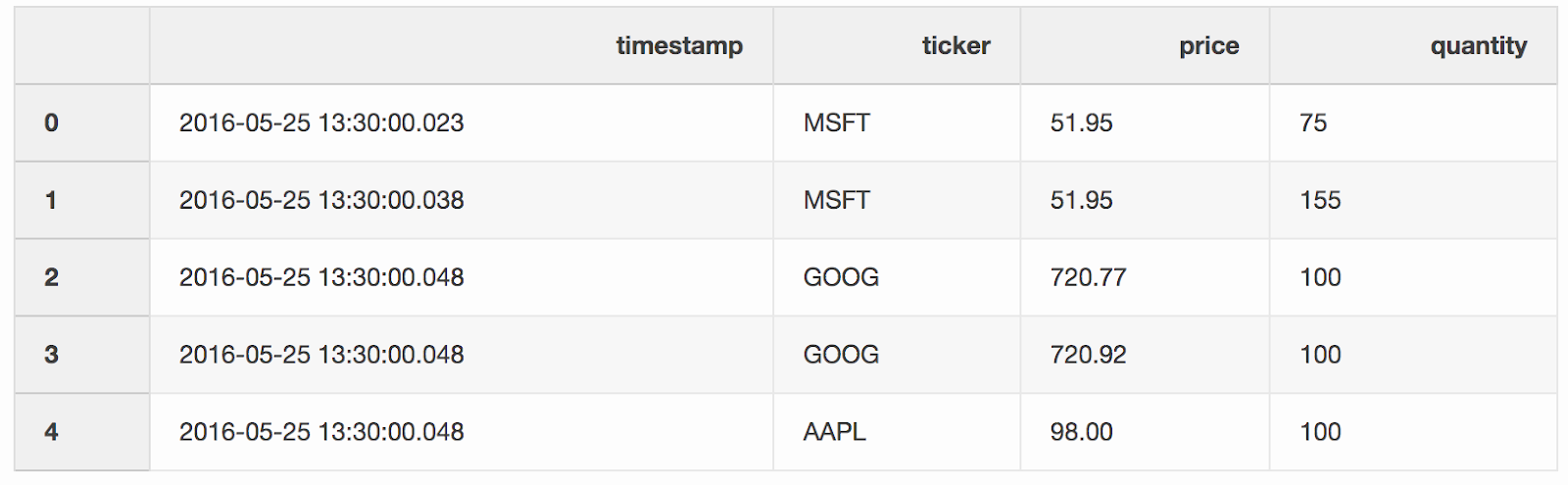 如果
如果timestamp最后报价可能比交易时间短10毫秒,我们将按报价单(报价工具,例如股票)合并交易和报价。如果报价在交易之前出现的时间超过10毫秒,则此报价的出价(买方准备支付的价格)和要价(卖方准备出售的价格)将是null(此示例中的APL报价器)。pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4.创建一个Excel报告
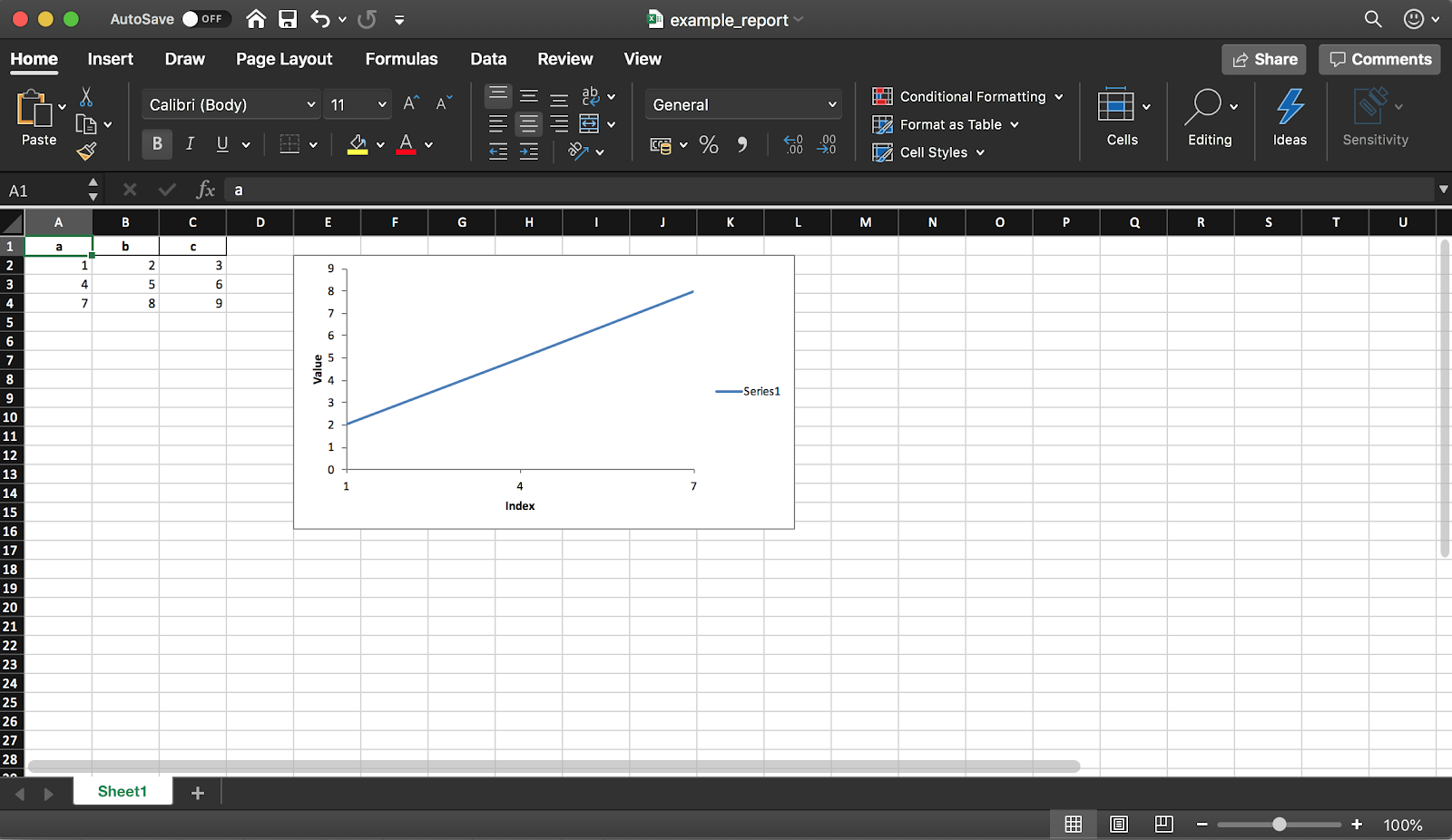 熊猫(带有XlsxWriter库)使您可以从DataFrame创建Excel报告。这为您节省了大量时间-无需再将DataFrame导出为CSV并将手动格式化为Excel。也可以使用各种图表等。
熊猫(带有XlsxWriter库)使您可以从DataFrame创建Excel报告。这为您节省了大量时间-无需再将DataFrame导出为CSV并将手动格式化为Excel。也可以使用各种图表等。df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
下面的代码段创建了Excel格式的表格。取消注释该行以将其保存到文件writer.save()。report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
如前所述,您还可以使用库将图表添加到报告中。您需要设置图表的类型(在我们的示例中为线性)及其数据范围(数据范围应在Excel表中)。
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5.节省磁盘空间
大量数据分析项目上的工作通常会以来自各种实验的大量已处理数据的形式留下痕迹。笔记本电脑上的SSD很快就会装满。Pandas允许您在压缩数据的同时将数据保存到磁盘,然后从压缩格式中再次读取数据。创建一个带有随机数的大型DataFrame。df = pd.DataFrame(pd.np.random.randn(50000,300))
 如果将其另存为CSV,则文件在硬盘驱动器上将占用近300 MB。
如果将其另存为CSV,则文件在硬盘驱动器上将占用近300 MB。df.to_csv('random_data.csv', index=False)
一个参数compression='gzip'将文件大小减小到136 MB。df.to_csv('random_data.gz', compression='gzip', index=False)
压缩文件的读取方式与常规文件相同,因此我们不会丢失任何功能。df = pd.read_csv('random_data.gz')
结论
这些小技巧提高了我每天与熊猫一起工作的效率。我希望您从本文中学到了一些有用的功能,这些功能也将帮助您提高工作效率。您最喜欢的熊猫技巧是什么?