他不确定自己是否正确听见。非常依赖它!但是不要再问了吗?(c)鲍里斯·阿库宁(Boris Akunin)。全世界都是剧院。
在处理上一篇文章中提到的语音助手时,我意识到我不禁要与您共享漂亮的FuzzyWuzzy库。简而言之,多亏了她,可以轻松进行模糊字符串比较。第一步
首先,您需要执行两个步骤:/重要!Python 2.7及更高版本/步骤1.安装。打开命令行并输入:pip install fuzzywuzzy
按Enter键。接下来,以相同的方式安装python-Levenshtein,将字符串匹配速度提高3到10倍。pip install python-Levenshtein
安装完成后,就可以导入该库了。步骤2.导入项目。from fuzzywuzzy import fuzz
from fuzzywuzzy import process
功能性
1.最常见的比较:a = fuzz.ratio(' ', ' ')
print(a)
如果我们更改几个字符,那么输出将得到一个不同的数字。a = fuzz.ratio(' ', ' ')
print(a)
2.部分比较:整行第二行中的这种比较会寻找与初始比较的匹配,例如:a = fuzz.partial_ratio(' ', ' !')
print(a)
要么a = fuzz.partial_ratio(' ', ' , ')
print(a)
但是您应该记住有关寄存器,因为a = fuzz.partial_ratio(' ', ' , ')
print(a)
3.代币比较1)代币排序比率单词相互比较,不分大小写或顺序a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio('1 2 ', '1 2 ')
print(a)
2)令牌集比率此比较与以往不同,如果字符串的重复是单词的重复,则等同于字符串。a = fuzz.token_set_ratio(' ', ' ')
print(a)
4.高级常规比较在许多情况下,更建议使用精确的WRatio,因为它区分大小写和标点符号(不分割字符串)a = fuzz.WRatio(' ', '! !')
print(a)
a = fuzz.WRatio(' ', '!, !')
print(a)
5.使用列表要比较行与列表中的行,请使用处理模块city = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extract("", city, limit=2)
print(a)
如果只需要列表中的第一个,则最好使用extractOnecity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
应用
以上所有方法的使用方式和位置由您决定,但这是我的学期论文中的一个示例:
try:
files = os.listdir('C:\\Users\\hartp\\Desktop\\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\\Users\\hartp\\Desktop\\' + filestart[0])
else:
speak(' ')
except FileNotFoundError:
speak(' ')
让我们看一下代码,了解什么是什么。使用os.listdir命令,我们获得指定路径(在本例中为桌面)末尾所有文件的列表。files = os.listdir('C:\\Users\\hartp\\Desktop\\')
print(files)
接下来是文件列表的行与用户命名的文件名的比较(变量namerec)。我希望您注意到extractOne函数的结果是一个字符串和数字(相似性索引)的元组上一章的例子city = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
.
基于此,我们检查相似性索引filestart [1]> = 80([1],因为元组从0开始编号,如在数组中),如果条件为true,则对名为filestart [0] 的文件运行os.startfile函数。 ]。否则,如果相似性索引小于80或发生找不到文件的错误,我们将通过语音功能通知用户。条条大路通向马坦
对害怕数学的人隐藏, , ().
, .
( , ) — , .
S1 i S2 j
S1=vrhk
S2=rhgr
3 :
- : r → v
- : -r
- : rVhgr
:

0 1? ( — «0»), r , r ( , — «1»). v .
rh h, r ( ), , :
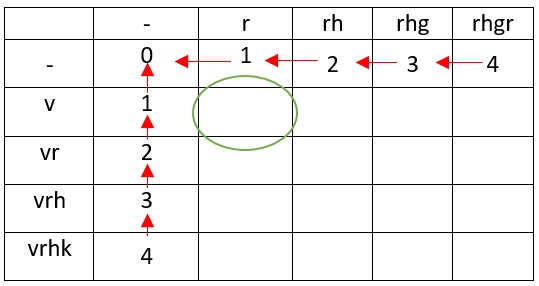
v r ( ).
, — v.
1. ? r , v. r , v, rv. , v v.
v rh
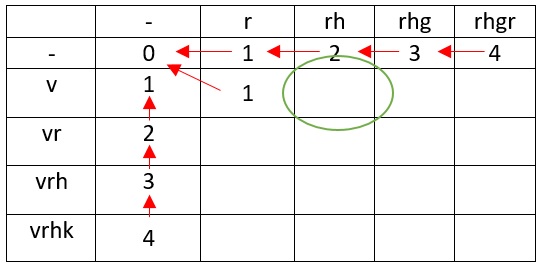
— v h r .
.
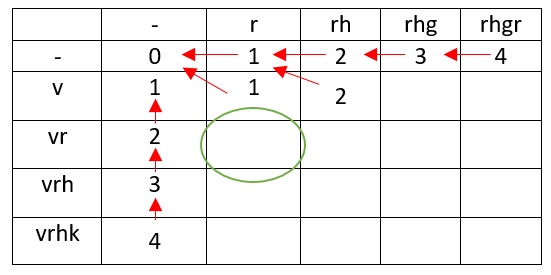
vr r , , , , .
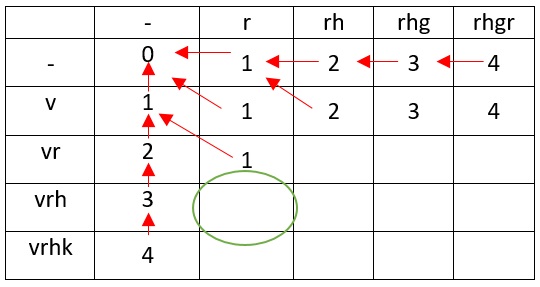
vrh r h ( vr r), 2

vr r vrh rh, , .
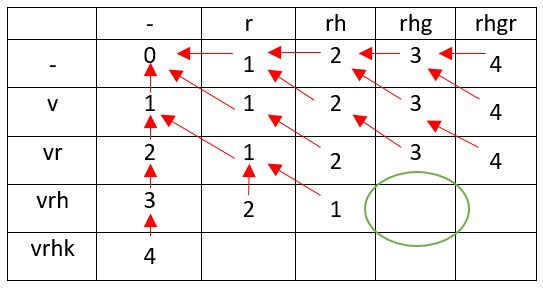
, vrh rhg , , , - ( ).
, , ( ) — vrhk rhgr.
谢谢大家的关注!我希望本文对某人有用。