在学习数据科学时,我决定为自己编写一份数据分析中使用的基本技术的摘要。它反映了方法的名称,简要描述了本质,并提供了用于快速应用的Python代码。我当时正在为自己准备一份纲要,但我认为这可能对某人有用,例如在面试之前,比赛中或开始新项目时。专为通常熟悉所有这些方法但需要在内存中刷新它们的读者设计。下条切。- 朴素贝叶斯分类器。用于计算将观察分类为一类或另一类的概率的公式:
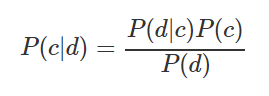
例如,您需要计算在天气晴朗的情况下进行体育比赛的概率。下表显示了源数据和计算: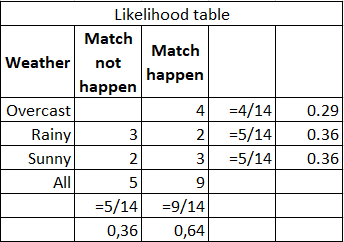
您可以通过公式(3/9)*(9/14)/(5/14)= 60%进行计算,或者仅根据常识3 /(2 + 3)= 60%进行计算。优点 -易于解释结果,适用于大样本和多类别分类。弱点 -并不总是满足特征独立的假设;特征应构成完整的事件组。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
gnb = GaussianNB()
y_pred = gnb.fit(X_train, y_train).predict(X_test)
print("Number of mislabeled points out of a total %d points : %d"
% (X_test.shape[0], (y_test != y_pred).sum()))
- 最近邻居的方法。根据与其他观测值的相似程度对每个观测值进行分类。该算法是非参数性的(对数据没有限制,例如,数据分布的功能),并且使用了惰性训练(未使用预训练的模型,在分类过程中使用了所有可用数据)。
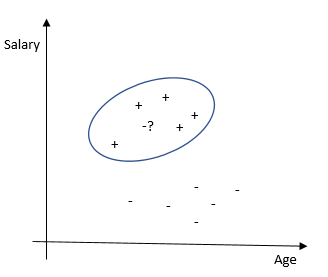
优点 -易于解释结果,非常适合具有少量解释变量的任务。缺点 -与其他方法相比,准确性较低。它需要具有大量解释变量和大量样本的强大计算能力。
from sklearn.neighbors import KNeighborsClassifier
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(X, y)
print(neigh.predict([[1.1]]))
print(neigh.predict_proba([[0.9]]))
- 支持向量法(SVM)。每个数据对象都表示为p维空间中的向量(点)。任务是用超平面分离点。即,可以找到这样的超平面,使得从其到最近点的距离最大。可能会有许多抢手的超平面;因此,可以认为,最大化类之间的距离有助于更可靠的分类。
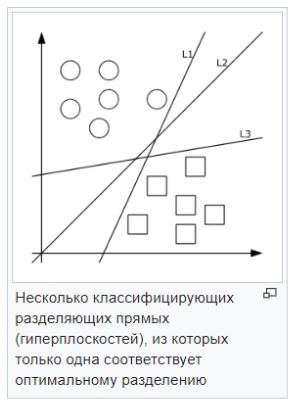
— . , , . . — , , , , . .
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
clf.predict([[2., 2.]])
- 决策树。根据特定条件以树结构的形式将数据划分为子样本。从数学上讲,将划分为几类,直到找到所有尽可能精确地确定该类的条件,即每个类中都没有其他类的代表。实际上,使用的特征和层数量有限,并且始终有两个分支。
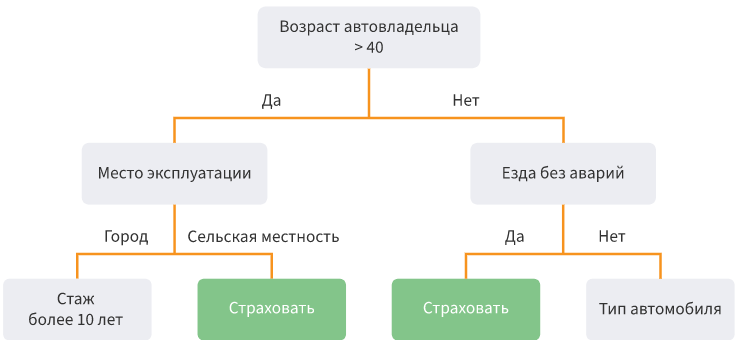
优势 -可以模拟复杂的过程并轻松解释它们。多类分类是可能的。缺点 -如果制作了许多层,则很容易重新训练模型。排放会影响精度;解决这些问题的方法是修整较低的水平。
from sklearn.datasets import load_iris
from sklearn import tree
X, y = load_iris(return_X_y=True)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
tree.plot_tree(clf.fit(iris.data, iris.target))
- / . . — . (random patching) . oob-.
: , , , , , . , . — , . , ( 100 000), — .
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X, y)
print(clf.feature_importances_)
print(clf.predict([[0, 0, 0, 0]]))
- . ( hinge loss function). .
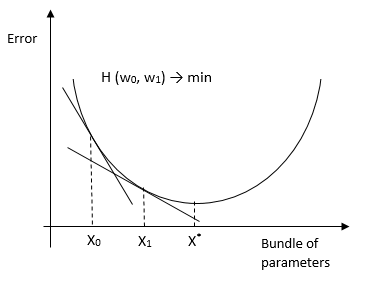
还有一个随机梯度下降的版本,用于大样本。其本质是,它不考虑整个样本的导数,而是考虑每个观察(在线学习)(或小批量观察组)的导数并更改权重。结果,他达到了与传统HS相同的最佳效果。有将HS用于OLS,logit,tobit和其他方法(证据)的方法。优点:分类和预测的准确性高,适用于多分类。弱点 -对模型参数的敏感性。
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=5)
clf.fit(X, y)
clf.predict([[2., 2.]])
clf.coef_
clf.intercept_
- . . , . , , .
: , , , . — .
import numpy as np
import matplotlib.pyplot as plt
from sklearn import ensemble
from sklearn import datasets
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
params = {'n_estimators': 500, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'}
clf = ensemble.GradientBoostingRegressor(**params)
clf.fit(X_train, y_train)
mse = mean_squared_error(y_test, clf.predict(X_test))
print("MSE: %.4f" % mse)
- /logit. 0 1, (log likelihood). — Y w.

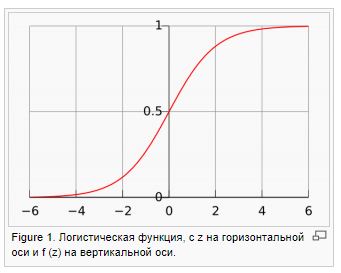
: , . — , .
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
clf = LogisticRegression(random_state=0).fit(X, y)
clf.predict(X[:2, :])
clf.predict_proba(X[:2, :])
clf.score(X, y)
-Probit. , , , .
import statsmodels
result_3 = statsmodels.discrete.
discrete_model.Probit(labf_part, ind_var_probit )
print(result_3.summary())
-Tobit. , .
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
import pandas as pd
from tobit import *
tr = TobitModel()
tr = tr.fit(x, y, cens, verbose=False)
tr.coef_
- , , . , , , . .