全国各地销售办事处的成千上万经理每天在我们的CRM系统中 记录成千上万的联系 -与潜在客户进行交流或已经与我们合作的事实。对于此客户,您必须首先找到,并且最好尽快找到。这种情况最经常发生在名字上。因此,毫不奇怪,再次在负载最重的数据库之一(我们自己的公司VLSI帐户)上分析“繁重”请求时,我发现“最顶部”是按名称快速搜索公司名片的请求。此外,进一步的调查显示了一个有趣的例子,即优化然后降低性能 几支团队在随后的改进中提出了要求,每个团队的行为完全出于善意。0:用户想要什么
[ 来自此处的 KDPV ]用户说“快速”按名称搜索时通常是什么意思?几乎从来没有发现过对这种类型的子字符串进行“诚实”的搜索... LIKE '%%'-因为这样做不仅得到and ,甚至获得结果。
用户暗示在家庭一级您可以在标题中单词的开头为他提供搜索,并显示与输入内容更相关的内容。并几乎可以立即完成 -使用线间输入。''' '''' '1:限制任务
更重要的是,一个人不会专门输入,' '因此您必须搜索每个单词的前缀。不,相对于故意“错过”前一个单词,用户响应最后一个单词的快速提示要容易得多-看看任何搜索引擎的工作原理。通常,正确制定任务要求是解决方案的一半以上。有时,仔细分析用例会严重影响结果。抽象开发者做什么?1.0:外部搜索引擎
哦,搜索很困难,我根本什么都不想做-让我们把它交给开发人员吧!让他们向我们部署一个相对于数据库的外部搜索引擎:Sphinx,ElasticSearch,...在同步和更改速度方面,这是一个尽管可行但很耗时的选择。但在我们的情况下不是,因为仅在每个客户的帐户数据框架内进行搜索。而且数据具有很大的可变性-如果经理现在已经插入了卡' ',则5-10秒后,他已经可以记住自己忘记在那儿指明电子邮件并想查找并更正它。因此,让我们“直接在数据库中搜索”。幸运的是,PostgreSQL允许我们执行此操作,而不仅仅是一个选项-我们将考虑它们。1.1:“诚实”子字符串
我们坚持使用“子字符串”一词。但是正是通过子字符串(甚至是正则表达式!)进行索引搜索的时候,还有一个出色的pg_trgm模块!只有这样,才有必要正确排序。为了简化模型,让我们尝试一下:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
我们在其中填写780万条真实组织和索引的记录:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
让我们寻找行间搜索的前10个条目:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
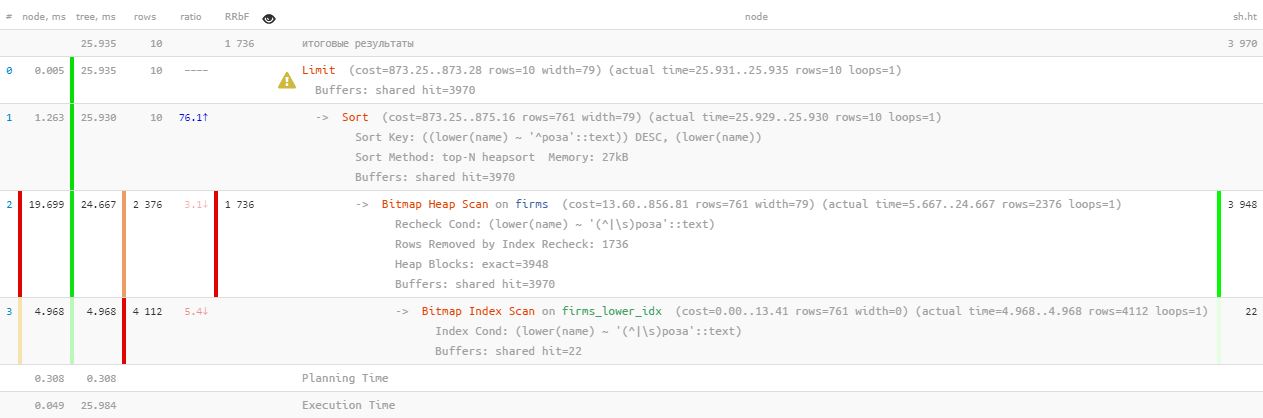 [看看explain.tensor.ru]好吧,这是... 26 毫秒,31MB的读取数据和超过1.7K过滤的记录-可供10个人使用。开销太高了,是否有可能变得更有效率?
[看看explain.tensor.ru]好吧,这是... 26 毫秒,31MB的读取数据和超过1.7K过滤的记录-可供10个人使用。开销太高了,是否有可能变得更有效率?1.2:文字搜索?是FTS!
确实,PostgreSQL提供了一种非常强大的全文搜索(全文搜索)机制,其中包括前缀搜索的可能性。一个很好的选择,甚至不需要安装扩展!我们试试吧:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [请看explorer.tensor.ru]在这里,查询执行的并行化对我们有所帮助,将时间减少了一半至11ms。是的,而且我们不得不读取1.5倍的数据,只有20MB。而且,这里越小越好,因为我们减去的数量越大,缓存未命中的机会就越高,并且从磁盘读取的每个额外数据页都可能成为请求的“刹车”。
[请看explorer.tensor.ru]在这里,查询执行的并行化对我们有所帮助,将时间减少了一半至11ms。是的,而且我们不得不读取1.5倍的数据,只有20MB。而且,这里越小越好,因为我们减去的数量越大,缓存未命中的机会就越高,并且从磁盘读取的每个额外数据页都可能成为请求的“刹车”。1.3:还喜欢吗?
先前的请求对每个人都有利,但是只有每天拉出十万次,才会运行2 TB的读取数据。充其量-从内存中获取,但是如果您不走运,则从磁盘获取。因此,让我们尝试使其更小。回想一下,用户希望首先看到“以...开头”。因此,这纯粹是带有!的前缀搜索text_pattern_ops。并且只有当我们“不够”最多10条所需记录时,我们才必须使用FTS搜索来读取它们:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
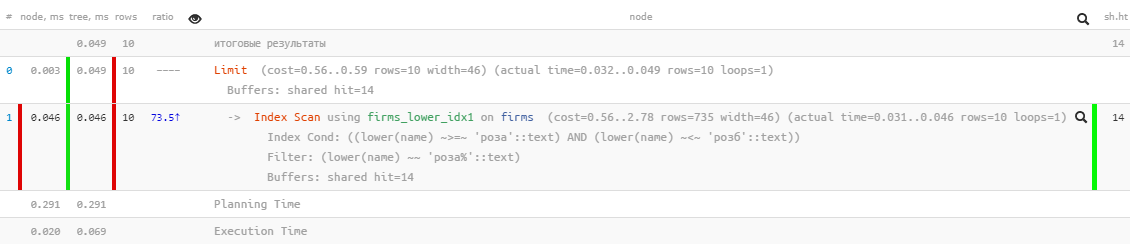 [查看explain.tensor.ru ]出色的性能-仅0.05ms,读取的大小超过100KB!只有我们忘记了按名称排序,这样用户才不会迷失于结果中:
[查看explain.tensor.ru ]出色的性能-仅0.05ms,读取的大小超过100KB!只有我们忘记了按名称排序,这样用户才不会迷失于结果中:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
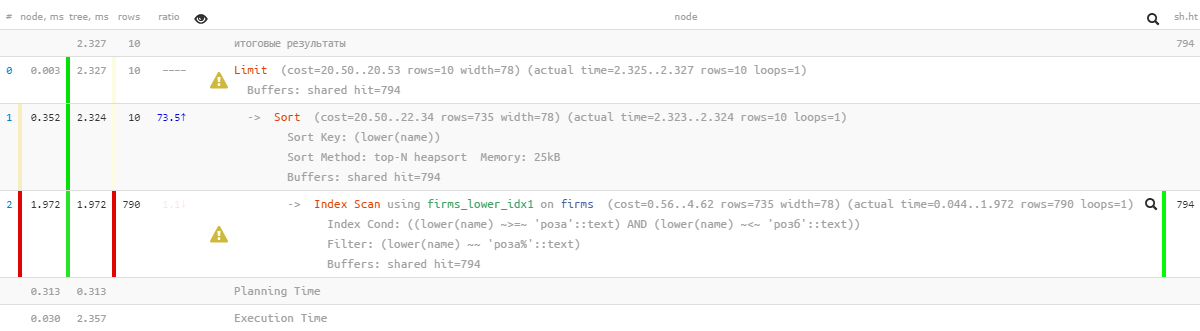 [看explorer.tensor.ru]哦,事情不再那么漂亮了-似乎有一个索引,但是排序却比它快了……当然,它比以前的版本有效很多倍,但是...
[看explorer.tensor.ru]哦,事情不再那么漂亮了-似乎有一个索引,但是排序却比它快了……当然,它比以前的版本有效很多倍,但是...1.4:“使用文件修改”
但是有一个索引可以让您按范围进行搜索,并且使用sorting是正常的- 正常的btree!CREATE INDEX ON firms(lower(name));
只需要一个请求就可以“手动组装”:SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [查看explain.tensor.ru]太好了–排序工作和资源消耗都保持“微观”,比“纯” FTS效率高数千倍!它仍然可以在单个请求中收集:
[查看explain.tensor.ru]太好了–排序工作和资源消耗都保持“微观”,比“纯” FTS效率高数千倍!它仍然可以在单个请求中收集:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
我注意到,只有在第一个子查询返回LIMIT的行数少于 last 期望的行数时,才执行第二个子查询。我已经写过关于这种查询优化方法的文章。因此,是的,我们现在同时在表上有btree和gin,但是从统计上来看,只有不到10%的请求到达了第二个块。就是说,由于这项任务的众所周知的典型限制,我们能够将服务器总资源消耗减少近一千倍!1.5 *:省去文件
上面LIKE我们被禁止使用错误的排序。但是可以通过指定USING语句将其“设置在真实路径上”:默认是隐含的ASC。另外,您可以在句子中指定特定排序运算符的名称USING。排序运算符必须是小于或大于某个B树运算符族的成员。ASC通常相当于USING <和DESC一般等价物USING >。
在我们的例子中,“少”是~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [看explain.tensor.ru]
[看explain.tensor.ru]2:如何“发出请求”
现在,我们将请求保留为“坚持”半年或一年,并且令人惊讶的是,我们再次发现它处于“顶部”,该指标表明每日总“抽出” 5.5TB的内存(共享命中的缓冲区),即甚至超过了原来的水平。
不,当然,我们的业务在增长,工作量也在增加,但幅度并没有太大!所以这里有些脏-让我们弄清楚。2.1:分页的诞生
在某个时候,另一个开发团队希望能够通过快速下标搜索“跳入”注册表,并获得相同但扩展的结果。还有没有页面导航的注册表?让我们拧紧它!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
现在,开发人员可以不费力地显示带有“ type-page”加载的搜索结果注册表。当然,实际上,对于每个下一页数据,都将读取越来越多的数据(在以前的所有时间中,我们都将其丢弃,再加上所需的“尾部”)-也就是说,这是明确的反模式。并且从下一个迭代开始,从存储在界面中的键开始搜索会更正确,但是大约是另一次。2.2:想要异国情调
在某个时候,开发人员希望使用来自另一个表的数据来使结果选择多样化,为此,先前的整个请求都发送给了CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
甚至如此-不错,因为子查询仅针对10条返回的记录进行计算(如果不是)...2.3:DISTINCT毫无意义且无情
在这种演变过程中的某个地方,第二个子查询失去NOT LIKE了条件。很明显,此后我UNION ALL开始两次返回一些记录 -首先在该行的开头找到,然后再次返回-在该行的第一个单词的开头。在限制中,第二个子查询的所有记录都可以与第一个子查询的记录重合。开发人员做什么而不是寻找原因?..没问题!- 原始样本大小的两倍
- 放置DISTINCT,以便我们仅获得每一行的单个实例
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
也就是说,很明显,最后的结果是完全相同的,但是“跳到”第二个CTE子查询的机会变得更高了,没有这个,显然阅读更多。但这不是最可悲的事情。由于开发人员要求我不选择DISTINCT特定记录,而是立即选择记录的所有字段,因此sub_query字段-子查询的结果-自动到达该位置。现在,为了执行DISTINCT,数据库必须执行的不是10个子查询,而是全部<2 * N> + 10!2.4:合作高于一切!
因此,开发人员幸免于难-他们没有打扰,因为在注册表中,他们被``修补''到了重要的N值,而接收每个下一个``页面''的速度却一直在减慢。直到另一个部门的开发人员来到他们那里,并且不想使用这种便捷的方法进行迭代搜索 -也就是说,我们从某个样本中抽取了一块,通过附加条件过滤,得出结果,然后再下一块(在我们的情况下是通过增加N),依此类推,直到填满整个屏幕为止。通常,在捕获的样本中N的值几乎达到17K,并且在短短24小时内至少有4K的请求是在``链中''执行的。他们中的最后一个已经大胆扫描每次迭代1GB内存 ...