最近,我不得不处理从Office文档(docx,xlsx,rtf,doc,xls,odt和ods)获取文本的需求。由于要求以xml格式显示文本且无垃圾且结构最便于进一步解析,因此使任务变得复杂。
由于使用Interop的笨重,在许多方面都有冗余,并且还需要在服务器上安装MS Office,因此立即放弃使用Interop的决定。结果,找到了解决方案并在内部项目上实施。但是,由于缺少任何通用的手册,搜索变得如此复杂且琐碎,我决定在业余时间写一个库来解决指定的任务,并创建一种编写指令,以便开发人员阅读她至少能够从表面上理解这个问题。
在对找到的解决方案进行描述之前,我建议您熟悉我的研究得出的一些结论:
- 对于.Net平台,尚没有适用于所有列出格式的现成解决方案,这将迫使我们在某些地方使我们的解决方案成为现实。
- 不要试图找到有关在网络上使用Microsoft OpenXML的好手册:要处理该库,您将不得不红眼,抽烟StackOverflow并使用调试器。
- 是的,我仍然设法驯服龙。
我必须立即说,该库尚未准备好,但是它正在被积极编写(在空闲时间允许的范围内)。假设将针对每种格式编写单独的帖子,并与它们的出版物并行发布,同时将更新github上的存储库,并可以从中获取源代码。
使用xlsx和docx
.xlsx
, , , docx xlsx zip-, xml. , : zip . , : \xl\worksheets.
excel , , - , :

, , , ( <f>) ( <v>). , shared sharedStrings.xml, \xl.
: .
, -, IConvertable:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
namespace ConverterToXml.Converters
{
interface IConvertable
{
string Convert(Stream stream);
string ConvertByFile(String path);
}
}
, : string Convert(Stream stream) ( , - ), string ConvertByFile(String path) .
XlsxToXml, IConvertable Nuget DocumentFormat.OpenXml ( , 2.10.0).
string SpreadsheetProcess(Stream memStream), string Convert(Stream stream).
public string Convert(Stream memStream)
{
return SpreadsheetProcess(memStream);
}
, *string SpreadsheetProcess(Stream memStream)*:
string SpreadsheetProcess(Stream memStream)
{
using (SpreadsheetDocument doc = SpreadsheetDocument.Open(memStream, false))
{
memStream.Position = 0;
StringBuilder sb = new StringBuilder(1000);
sb.Append("<?xml version=\"1.0\"?><documents><document>");
SharedStringTable sharedStringTable = doc.WorkbookPart.SharedStringTablePart.SharedStringTable;
int sheetIndex = 0;
foreach (WorksheetPart worksheetPart in doc.WorkbookPart.WorksheetParts)
{
WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);
sheetIndex++;
}
sb.Append(@"</document></documents>");
return sb.ToString();
}
}
, string SpreadsheetProcess(Stream memStream) :
using excel . xlsx DocumentFormat.OpenXml SpreadsheetDocument.
StringBuilder sb ( 1000 . StringBuilder , . , , .
shared ( ). , SpreadsheetDocument :
SharedStringTable sharedStringTable = doc.WorkbookPart.SharedStringTablePart.SharedStringTable.
,
foreach (WorksheetPart worksheetPart in doc.WorkbookPart.WorksheetParts)
{
WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);
sheetIndex++;
}
WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);:
private void WorkSheetProcess(StringBuilder sb, SharedStringTable sharedStringTable, WorksheetPart worksheetPart, SpreadsheetDocument doc,
int sheetIndex)
{
string sheetName = doc.WorkbookPart.Workbook.Descendants<Sheet>().ElementAt(sheetIndex).Name.ToString();
sb.Append($"<sheet name=\"{sheetName}\">");
foreach (SheetData sheetData in worksheetPart.Worksheet.Elements<SheetData>())
{
if (sheetData.HasChildren)
{
foreach (Row row in sheetData.Elements<Row>())
{
RowProcess(row, sb, sharedStringTable);
}
}
}
sb.Append($"</sheet>");
}
, :
string sheetName = doc.WorkbookPart.Workbook.Descendants<Sheet>().ElementAt(sheetIndex).Name.ToString();
, , . , . , , shift+F9( ), doc( )->WorkbookPart->Workbook Descendants(), Sheet. , ( ). :
foreach , . sheetData - , , RowProcess:
foreach (SheetData sheetData in worksheetPart.Worksheet.Elements<SheetData>())
{
if (sheetData.HasChildren)
{
foreach (Row row in sheetData.Elements<Row>())
{
RowProcess(row, sb, sharedStringTable);
}
}
}
void RowProcess(Row row, StringBuilder sb, SharedStringTable sharedStringTable) :
void RowProcess(Row row, StringBuilder sb, SharedStringTable sharedStringTable)
{
sb.Append("<row>");
foreach (Cell cell in row.Elements<Cell>())
{
string cellValue = string.Empty;
sb.Append("<cell>");
if (cell.CellFormula != null)
{
cellValue = cell.CellValue.InnerText;
sb.Append(cellValue);
sb.Append("</cell>");
continue;
}
cellValue = cell.InnerText;
if (cell.DataType != null && cell.DataType == CellValues.SharedString)
{
sb.Append(sharedStringTable.ElementAt(Int32.Parse(cellValue)).InnerText);
}
else
{
sb.Append(cellValue);
}
sb.Append("</cell>");
}
sb.Append("</row>");
}
foreach (Cell cell in row.Elements<Cell>()) :
if (cell.CellFormula != null)
{
cellValue = cell.CellValue.InnerText;
sb.Append(cellValue);
sb.Append("</cell>");
continue;
}
, , (cellValue = cell.CellValue.InnerText;) .
, , shared: , :
if (cell.DataType != null && cell.DataType == CellValues.SharedString)
{
sb.Append(sharedStringTable.ElementAt(Int32.Parse(cellValue)).InnerText);
}
, .
.docx
, word excel-.
, , , , , , . , , .., , , , - , , .
, . zip . . word document. , , , , . , : - .
, w:t, w:r, w:p. , docx, . : , w:numPr, (w:ilvl) id , (w:numId).
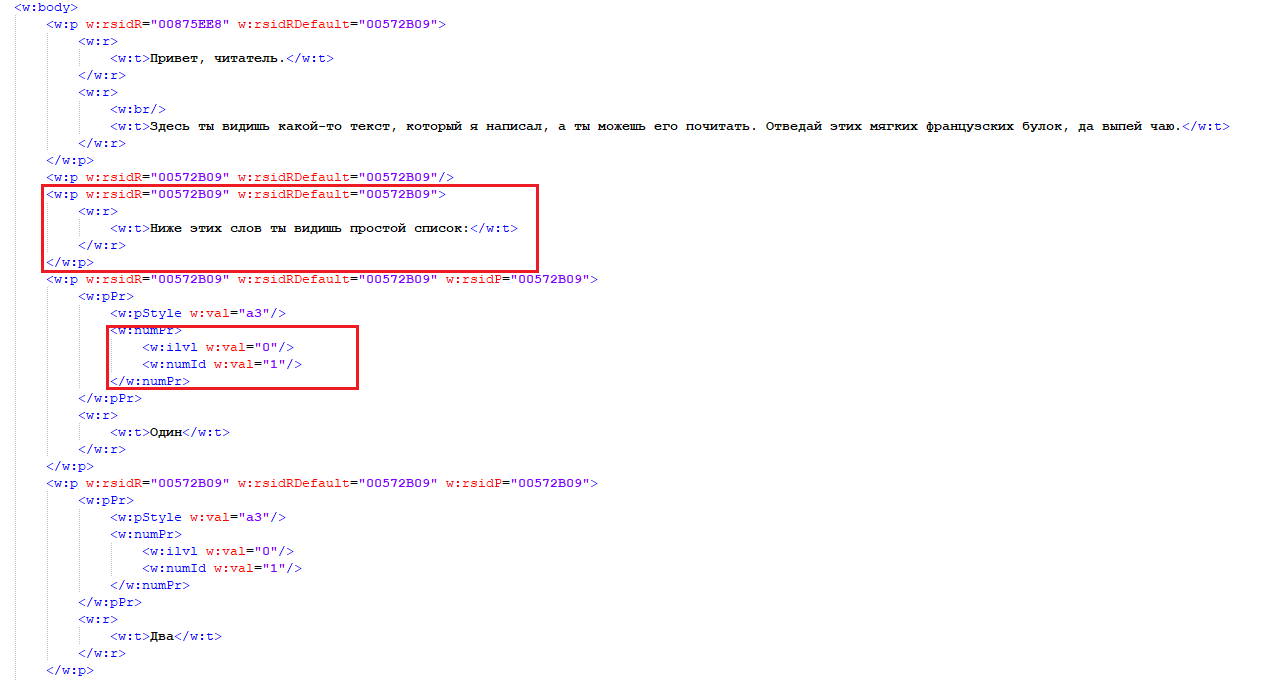
, , , , ( , ), , id , , .
, , :

, . w:tr () w:tc().

在开始编码之前,我要注意一个非常重要的细微差别(是的,例如关于Petka和Vasily Ivanovich的笑话)。解析列表时,尤其是嵌套列表时,如果列表项被某种形式的文本,图像或其他任何插入分隔开,则可能会出现这种情况。然后问题来了,我们什么时候放列表的结束标记?我的建议是ing着拐杖和骑自行车,这要归结为添加字典,字典的键将是列表的ID,并且值将对应于段落的ID(是的,事实证明文档中的每个段落都有其自己的唯一ID),这也是列表中的最后一个ID。也许这写起来很困难,但是我认为当您看一下实现时,它会变得更加清晰:public string Convert(Stream memStream)
{
Dictionary<int, string> listEl = new Dictionary<int, string>();
string xml = string.Empty;
memStream.Position = 0;
using (WordprocessingDocument doc = WordprocessingDocument.Open(memStream, false))
{
StringBuilder sb = new StringBuilder(1000);
sb.Append("<?xml version=\"1.0\"?><documents><document>");
Body docBody = doc.MainDocumentPart.Document.Body;
CreateDictList(listEl, docBody);
foreach (var element in docBody.ChildElements)
{
string type = element.GetType().ToString();
try
{
switch (type)
{
case "DocumentFormat.OpenXml.Wordprocessing.Paragraph":
if (element.GetFirstChild<ParagraphProperties>() != null)
{
if (element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val != CurrentListID)
{
CurrentListID = element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val;
sb.Append($"<li id=\"{CurrentListID}\">");
InList = true;
ListParagraph(sb, (Paragraph)element);
}
else
{
ListParagraph(sb, (Paragraph)element);
}
if (listEl.ContainsValue(((Paragraph)element).ParagraphId.Value))
{
sb.Append($"</li id=\"{element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val}\">");
}
continue;
}
else
{
SimpleParagraph(sb, (Paragraph)element);
continue;
}
case "DocumentFormat.OpenXml.Wordprocessing.Table":
Table(sb, (Table)element);
continue;
}
}
catch (Exception e)
{
continue;
}
}
sb.Append(@"</document></documents>");
xml = sb.ToString();
}
return xml;
}
Dictionary<int, string> listEl = new Dictionary<int, string>(); — .
using (WordprocessingDocument doc = WordprocessingDocument.Open(memStream, false)) — doc WordprocessingDocument, word, ( , OpenXML) .
StringBuilder sb = new StringBuilder(1000); — xml.
Body docBody = doc.MainDocumentPart.Document.Body; — ,
CreateDictList(listEl, docBody);, foreach , :
void CreateDictList(Dictionary<int, string> listEl, Body docBody)
{
foreach(var el in docBody.ChildElements)
{
if(el.GetFirstChild<ParagraphProperties>() != null)
{
int key = el.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val;
listEl[key] = ((DocumentFormat.OpenXml.Wordprocessing.Paragraph)el).ParagraphId.Value;
}
}
}
GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val; — ( https://docs.microsoft.com/ru-ru/office/open-xml/open-xml-sdk ), . , , , )
, , foreach . : . , , . , (, ) , . , . :
string type = element.GetType().ToString();
try
{
switch (type)
{
case "DocumentFormat.OpenXml.Wordprocessing.Paragraph":
if (element.GetFirstChild<ParagraphProperties>() != null)
{
if (element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val != CurrentListID)
{
CurrentListID = element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val;
sb.Append($"<li id=\"{CurrentListID}\">");
InList = true;
ListParagraph(sb, (Paragraph)element);
}
else
{
ListParagraph(sb, (Paragraph)element);
}
if (listEl.ContainsValue(((Paragraph)element).ParagraphId.Value))
{
sb.Append($"</li id=\"{element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val}\">");
}
continue;
}
else
{
SimpleParagraph(sb, (Paragraph)element);
continue;
}
case "DocumentFormat.OpenXml.Wordprocessing.Table":
Table(sb, (Table)element);
continue;
}
}
try-catch , - , switch-case ( , , ). , - , .
, ListParagraph(sb, (Paragraph)element); :
void ListParagraph(StringBuilder sb, Paragraph p)
{
var level = p.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingLevelReference>().Val;
var id = p.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val;
sb.Append($"<ul id=\"{id}\" level=\"{level}\"><p>{p.InnerText}</p></ul id=\"{id}\" level=\"{level}\">");
}
<ul>, id .
, , SimpleParagraph(sb, (Paragraph)element);:
void SimpleParagraph(StringBuilder sb, Paragraph p)
{
sb.Append($"<p>{p.InnerText}</p>");
}
, <p>
该表以以下方法处理Table(sb, (Table)element);:
void Table(StringBuilder sb, Table table)
{
sb.Append("<table>");
foreach (var row in table.Elements<TableRow>())
{
sb.Append("<row>");
foreach (var cell in row.Elements<TableCell>())
{
sb.Append($"<cell>{cell.InnerText}</cell>");
}
sb.Append("</row>");
}
sb.Append("</table>");}
这样的元素的处理非常琐碎:我们读取行,将它们分成单元格,从单元格中获取值,将它们包装在标签中<cell>,然后包装到标签中<row>并将其全部放入内部<table>。
基于此,我建议考虑针对docx和xlsx格式的文档解决的任务。
可以在资源库中的链接处查看源代码
rtf转换文章