我很早就知道“我曾经被拥有”(HIBP)网站。没错,直到最近,他还从未去过那里。我总是有两个密码。其中一个被反复用于垃圾邮件和在陌生站点上的几个帐户。但是我不得不拒绝它,因为邮件被黑了。老实说,我感谢黑客,因为此事件使我查看了密码-使用和存储密码的方式。当然,我更改了所有密码被泄露的帐户的密码。然后我想知道泄漏的密码是否在HIBP数据库中。我不想在网站上输入密码,所以我下载了数据库(pwned-passwords-sha1-ordered-by-count-v5)该基地是非常令人印象深刻。这是一个22.8 GB的文本文件,带有一组SHA-1哈希,每行带有一个计数器,该哈希中的密码在泄漏中发生了多少次。我找出了破解密码的SHA-1,并试图找到它。内容
[G]代表
我们有一个文本文件,每行中都有一个哈希。最好的去处也许是grep。grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txt我的密码在列表中排名第一,频率超过1500次,因此确实很糟糕。因此,搜索结果几乎立即返回。但是,并非所有人的密码都很弱。我想检查查找最坏情况的情况需要多长时间-文件中的最后一个哈希:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txt结果:33,35s user 23,39s system 41% cpu 2:15,35 total这很可悲。毕竟,由于我的邮件被黑了,所以我想检查数据库中所有旧密码和新密码的存在。但是两分钟的grep根本无法让您轻松地做到这一点。当然,我可以编写脚本,运行该脚本并进行散步,但这不是一个选择。我想找到一个更好的解决方案并学习一些东西。特里结构
第一个想法是使用特里数据结构。该结构似乎是存储SHA-1哈希的理想选择。字母很小,因此节点也很小,结果文件也一样。也许它甚至适合RAM?密钥搜索应该非常快。所以我实现了这种结构。然后,他使用源数据库的前1,000,000个哈希值来构建结果文件,并检查所有内容是否都在创建的文件中。是的,我可以在文件中找到所有内容,因此结构运行良好。问题是不同的。生成的文件的大小为2283686592B(2.2 GB)。这个不好。让我们数一下,看看会发生什么。节点是16个32位值的简单结构。值是具有指定SHA-1哈希符号的以下节点的``指针''。因此,一个节点占用16 * 4字节= 64字节。好像有点?但是如果考虑一下,一个节点代表哈希中的一个字符。因此,在最坏的情况下,SHA-1哈希将占用40 * 64字节= 2560字节。例如,这仅占用40个字节的散列的文本表示,这会更糟。特里结构具有重用节点的优点。如果您有两个单词aaaand abb,那么将重用前几个字符的节点,因为这些字符是相同的- a。让我们回到我们的问题。让我们计算一下在结果文件中存储了多少个节点:file_size / node_size = 2283686592 / 64 = 35682603现在,我们来看看在最坏情况下从一百万个哈希值中将创建多少个节点:1000000 * 40 = 40000000因此,特里结构只重用了40000000 - 35682603 = 4317397节点,这是最坏情况下的10.8%。使用此类指示符,整个HIBP数据库的结果文件将占用1421513361920字节(1.02 TB)。我什至没有足够的硬盘来检查密钥搜索的速度。那天,我发现trie结构不适合相对随机的数据。让我们寻找另一个解决方案。二进制搜索
SHA-1哈希具有两个不错的功能:它们可以相互比较,并且大小都相同。因此,我们可以处理原始的HIBP数据库并根据排序的SHA-1值创建文件。但是,如何对22 GB的文件进行排序?题。为什么对源文件进行排序?HIBP返回一个文件,该文件的字符串已经按哈希排序。
回答。我只是没有考虑过。那时我还不了解排序的文件。排序
对RAM中的所有哈希进行排序不是一种选择;我没有太多的RAM。解决方案是这样的:- 将大文件拆分为较小的文件,以适合RAM。
- 从小文件下载数据,在RAM中排序并写回文件。
- 将所有小的分类文件合并为一个大文件。
对于较大的排序文件,您可以使用二进制搜索来搜索我们的哈希。硬盘访问很重要。让我们计算一下二进制搜索需要多少个匹配:log2(555278657) = 29.0486367039即30个匹配。还不错在第一阶段,可以执行优化。将文本哈希转换为二进制数据。这样会将结果数据的大小减少一半:从22 GB减少到11 GB。精细。为什么要合并?
那时,我意识到您可以做得更聪明。如果您不将小文件合并为一个大文件,而是对RAM中排序的小文件进行二进制搜索怎么办?问题是如何找到要在其中查找密钥的所需文件。解决方案非常简单。新的方法:- 创建名称为“ 00” ...“ FF”的256个文件。
- 从大文件读取哈希时,将以“ 00 ..”开头的哈希写入到名为“ 00”的文件,将以“ 01 ..”开头的哈希写入到文件“ 01”,依此类推。
- 从小文件下载数据,在RAM中排序并写回文件。
一切都非常简单。此外,还会出现另一个优化选项。如果哈希存储在文件“ 00”中,则我们知道它以“ 00”开头。如果哈希存储在文件“ F2”中,则它以“ F2”开头。因此,在将散列写入小文件时,我们可以省略每个散列的第一个字节!这是所有数据的5%。总共节省555 MB。并行性
分离成较小的文件为优化提供了另一个机会。文件彼此独立,因此我们可以并行对其进行排序。我们记得您所有的处理器都希望同时出汗;)不要自私的混蛋
当我实现上述解决方案时,我意识到其他人可能也有类似的问题。可能还有许多其他人也下载并搜索了HIBP数据库。所以我决定分享我的工作。在此之前,我再次修改了方法,发现了一些要在将代码和工具发布到Github之前解决的问题。首先,作为最终用户,我不想使用创建带有奇怪名称的许多奇怪文件的工具,不清楚其中存储了什么内容,等等。那么,可以通过组合文件“ 00” ..“ FF”来解决此问题。一个大文件。不幸的是,拥有一个大文件进行排序提出了一个新问题。如果我想在此文件中插入哈希怎么办?只是一个哈希。这只有20个字节。哦,哈希以“ 000000000 ..”开头。好的。让我们通过移动11 GB的其他哈希来释放它的空间...您了解问题所在。在文件中间插入数据并不是最快的操作。这种方法的另一个缺点是您需要再次存储第一个字节-它是555 MB的数据。最后但并非最不重要的一点是,对硬盘驱动器上存储的数据进行二进制搜索要比访问RAM慢得多。我的意思是,这是30个磁盘读取与0个磁盘读取。B3
再次。我们拥有的和我们想要实现的。我们有11 GB的二进制值。所有值都是可比较的并且具有相同的大小。我们要查找存储的数据中是否存在特定的键,并且还想更改数据库。这样一切都可以快速进行。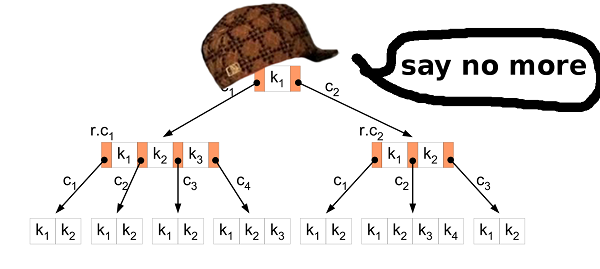 B树?对B树允许您在搜索,修改等操作时最小化对磁盘的访问。它具有更多的功能,但是我们需要这两项。
B树?对B树允许您在搜索,修改等操作时最小化对磁盘的访问。它具有更多的功能,但是我们需要这两项。插入排序
第一步是将数据从HIBP源文件转换为B树。这意味着您需要依次提取所有哈希并将它们插入结构中。通常的插入算法适用于此。但就我们而言,您可以做得更好。众所周知,将大量原始数据插入B树中。明智的人们为此发明了比通常的刀片更好的方法。首先,您需要对数据进行排序。可以按照上述步骤进行操作(将文件拆分为较小的文件,然后在RAM中排序)。然后将数据插入树中。在通常的算法中,如果找到要插入值的叶节点并将其填充,则创建一个新节点(在右侧)并在左右两个节点之间均匀分配值(外加一个值到父节点)但这并不重要)。简而言之,左侧节点中的值始终小于右侧节点中的值。事实是,当您插入排序后的数据时,您知道较小的值将不再插入树中,因此不会有更多的值流向左侧节点。左节点始终保持一半为空。而且,如果插入足够的值,您可能会发现右节点已满,因此需要将值的一半移到新的右节点。与前面的情况一样,拆分节点仍然为空。等等…结果,在所有插入之后,您将得到一棵树,其中几乎所有节点都是一半为空。这不是对空间的非常有效的利用。我们可以做得更好。是否分开?
在插入排序的数据的情况下,您可以对插入算法进行一些小的修改。如果要粘贴值的节点已满,请不要破坏它。只需创建一个新的空节点并将该值粘贴到父节点即可。然后,当您插入以下值(大于前一个值)时,将它们插入到一个新的空节点中。为了保留B树的属性,在所有插入之后,有必要对树的每一层(根除外)中最右边的节点进行排序,并将该极端节点及其左邻居的值平均划分。这样您就可以得到最小的树。HIBP树属性
设计B树时,需要选择其顺序。它显示一个节点上可以存储多少个值以及该节点可以有多少个子代。通过操纵此参数,我们可以操纵树的高度,节点的二进制大小等。在HIBP中,我们具有555278657哈希。假设我们想要一棵高度为三的树(因此,我们只需要三个读取操作即可检查哈希是否存在)。我们需要找到一个M使得logM(555278657) < 3。我选择了1024。这不是最小的可能值,但是它可以插入更多的散列并保留树的高度。输出文件
HIBP源文件的大小为22.8 GB。带有B树的输出文件为12.4 GB。在我的机器(Intel Core i7-6700、3.4 GHz,16 GB RAM),硬盘(不是SSD)上创建它大约需要11分钟。基准测试
B树选项显示了很好的结果:| | 时间[μs] | %|
| -----------------:| ------------:| ------------:| |
| okon | 49 | 100 |
| grep'^ hash'| 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++逐行| 135'720'201 | 276'980'002 |
okon-库和CLI
正如我所说,我想与世界分享我的作品。我实现了一个库和命令行界面来处理HIBP数据库并快速搜索哈希。搜索是如此之快,以至于例如可以将其集成到密码管理器中,并在每次按键时向用户提供反馈。有许多可能的用途。该库具有C接口,因此几乎可以在任何地方使用。 CLI是一个CLI。您可以简单地构建和运行(:代码在我的存储库中。免责声明:okon尚未提供用于将值插入到创建的B树中的接口。它只能处理HIBP文件,创建B树并在其中搜索。这些功能运行良好,因此我决定共享代码并继续使用insert和其他可能的功能。链接与讨论
谢谢阅读
(: