 大家好!从事性能测试。我真的很想在Grafana中设置监控并享受指标。在负载工具中存储指标的标准是InfluxDB。在InfluxDB中,您可以通过以下常用工具保存指标:通过使用性能测试工具及其指标,我为Grafana和InfluxDB的捆绑包积累了一些编程秘诀。我建议考虑一个有趣的问题,该问题存在于具有两个或多个标签的度量标准中。我认为这并不少见。在一般情况下,任务听起来像是:计算一个组的总指标,该组又分为子组。
大家好!从事性能测试。我真的很想在Grafana中设置监控并享受指标。在负载工具中存储指标的标准是InfluxDB。在InfluxDB中,您可以通过以下常用工具保存指标:通过使用性能测试工具及其指标,我为Grafana和InfluxDB的捆绑包积累了一些编程秘诀。我建议考虑一个有趣的问题,该问题存在于具有两个或多个标签的度量标准中。我认为这并不少见。在一般情况下,任务听起来像是:计算一个组的总指标,该组又分为子组。共有三个选项:
- 只是按类型标签分组的金额
- 格拉法纳路。我们使用一堆价值观
- 子查询的最高总和
一切如何开始
使用Jolokia,Telegraf,InfluxDB和Grafana配置的JVM MBean监视。他还可视化了内存池上的指标-HEAP及更高版本中的每个内存池分配了多少内存。从前一天的13:00到当天的晚上的01:00(12小时)的JVM内存池和垃圾收集器活动的图表。在这里,您可以看到内存池分为两组:HEAP和NON_HEAP。大约在17:00进行了垃圾回收,之后内存池的大小减小了:
为了收集内存池的指标,我在telegraf配置文件中指定了以下设置:telegraf.conf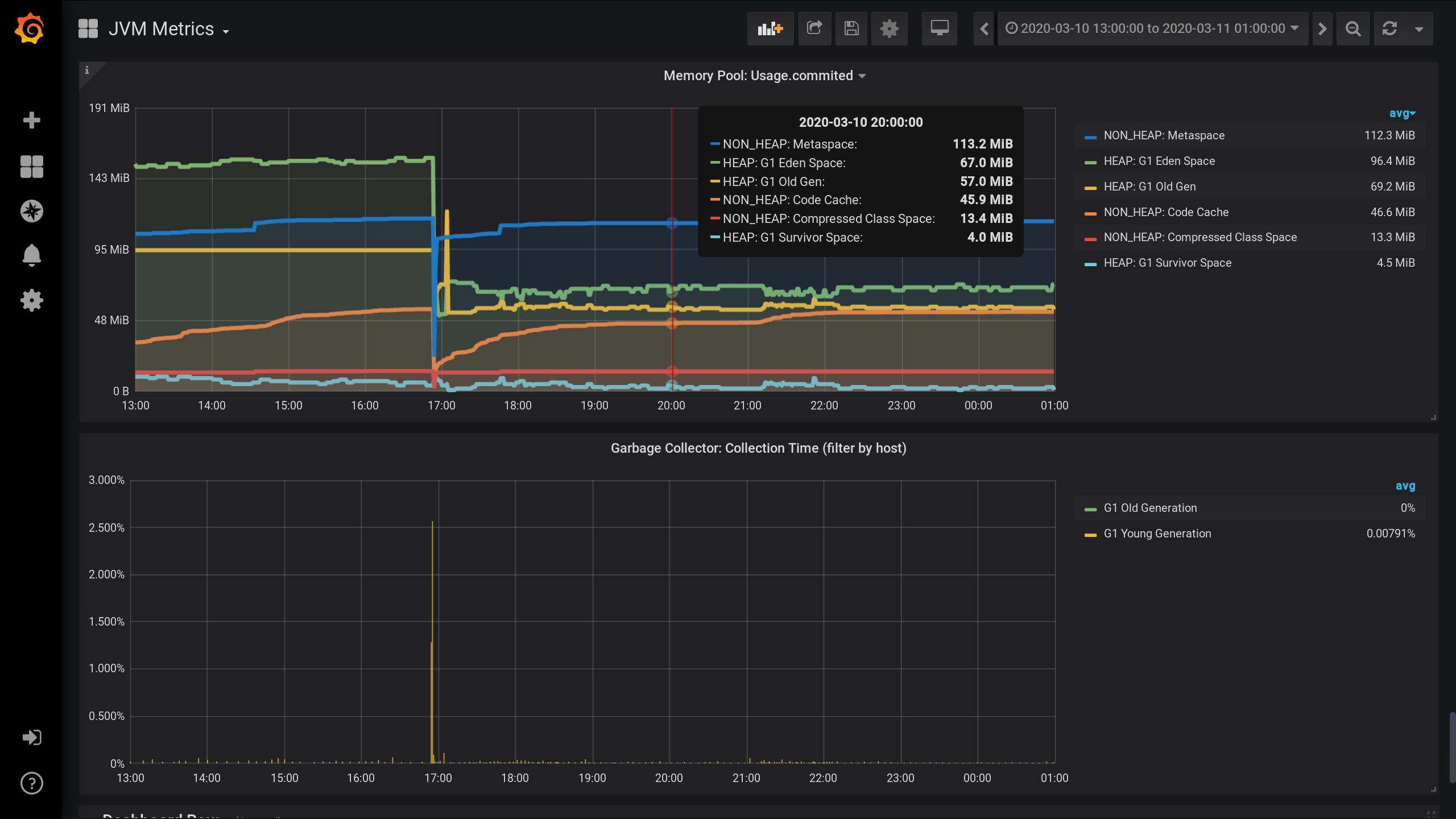
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
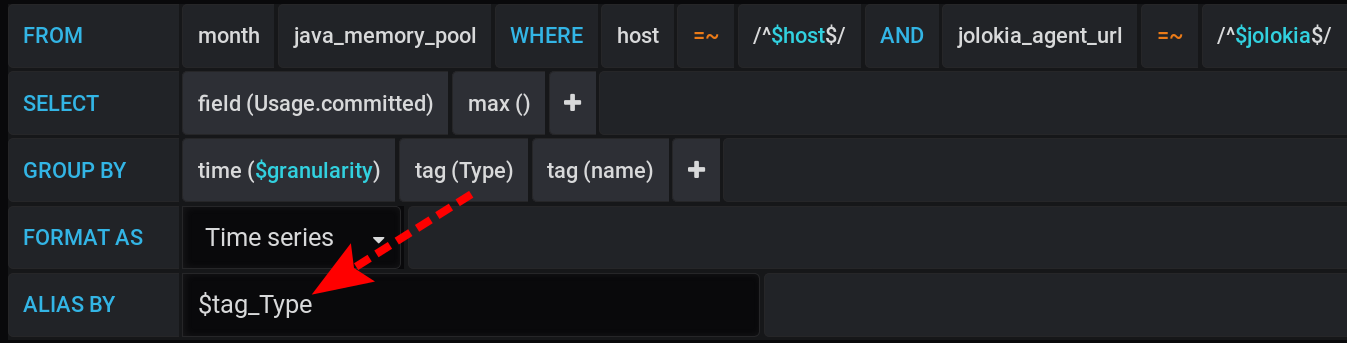
然后在Grafana中,我向InfluxDB发出了一个请求,要求在Usage.Committed步骤中以一个步长$granularity(1m)在图表中显示最大度量值,并按两个标签Type(HEAP或NON_HEAP)和name(元空间,G1 Old Gen等)分组:
相同的请求在文本形式中,考虑到所有Grafana变量(注意使用来转义变量值-这对于查询正确工作很重要):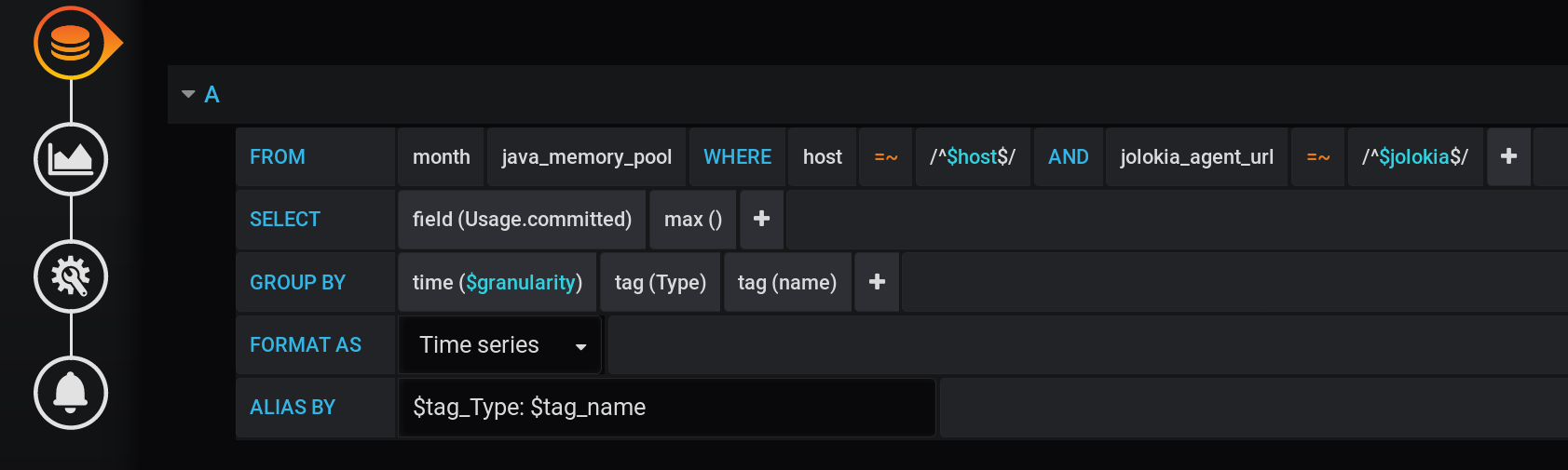
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
考虑到Grafana变量的特定值,以文本形式进行的相同查询:SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
按时间分组GROUP BY time($granularity)或GROUP BY time(1m)用于减少图表上的点数。对于12小时的时间段和1分钟的分组步骤,我们得到:12 x 60 = 720次或721点(最后一个点的值为null)。请记住,在时间间隔(12小时)和分组步骤(1分钟)中,721是在当前设置下响应InfluxDB的请求的预期点数。
NON_HEAP
内存池:在20 :00,Metaspace(蓝色)在内存消耗方面处于领先地位。根据HEAP:G1老一代(黄色),当地时间17:03出现小幅激增。并且在20:00时,所有NON_HEAP池总计剩下172.5 MiB(113.2 + 45.9 + 13.4),而HEAP池则剩下128 MiB(67 + 57 + 4)。
请记住20:00的值:NON_HEAP池172.5 MiB和HEAP池128 MiB。未来我们将专注于这些价值观。
在Type:name的上下文中,我们轻松获得了指标值。在仅名称标签的上下文中,度量值也很容易获得,因为所有内存池的名称都是唯一的,并且仅按名称保留结果分组就足够了。问题仍然存在:如何获得为所有HEAP池和所有NON_HEAP池分配的总大小?
1.仅按类型标签分组的金额
1.1。按标签分组的总和
可能想到的第一个解决方案是通过Type标签对值进行分组并计算每组中值的总和。这样的查询将如下所示:
以Type标记和所有Grafana变量分组的总和计算请求的文本表示形式: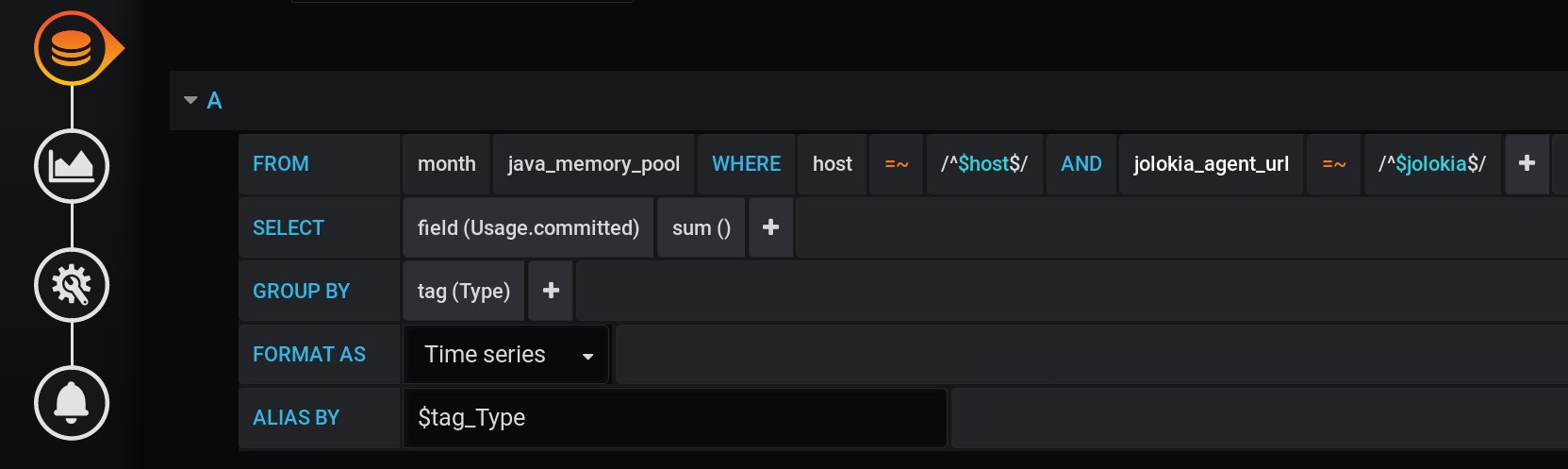
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
这是一个有效的查询,但它只会返回两点:和将仅通过具有两个值(HEAP和NON_HEAP)的Type标签进行分组计算。我们什至看不到时间表。将有两个独立的点,它们的值之和很大(超过3 TiB):
这样的和不合适,需要细分为时间间隔。
1.2。每分钟按标签分组的数量
在原始查询中,我们通过自定义$粒度间隔对指标进行分组。现在让我们按自定义间隔进行分组。该查询将被补充GROUP BY time($granularity):
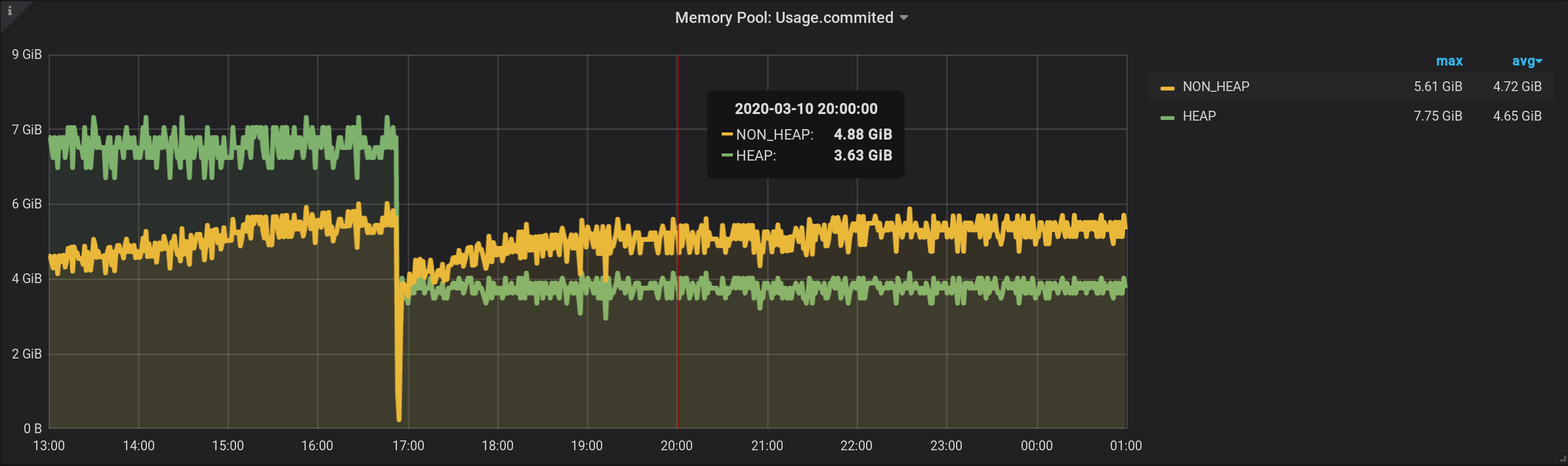
我们得到的是虚高的值,而不是NON_HEAP的172.5 MiB,我们看到的是4.88 GiB:
由于指标每2秒发送一次到InfluxDB(请参阅上面的telegraf.conf),所以一分钟内的读数总和不会给出该数量此刻,以及三十个这样的金额之和。我们也不能将
结果除以常数30。由于$粒度是一个参数,因此可以将其设置为1分钟和10分钟。并且金额的值将改变。
1.3。标签每秒分组
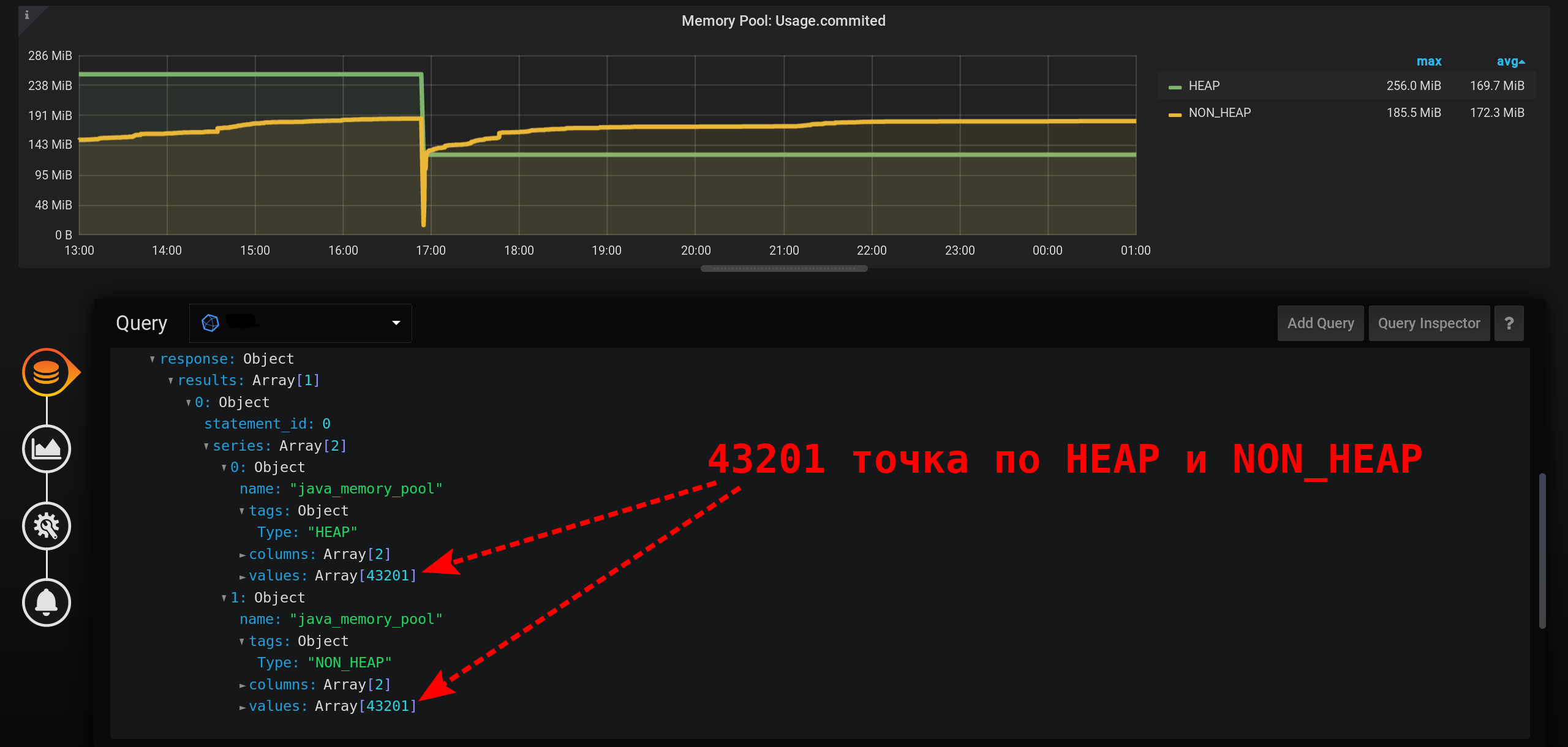
为了正确获取当前度量标准收集强度(2秒)的度量标准值,您需要计算不超过度量标准收集强度的固定间隔的量。让我们尝试以秒为单位显示统计信息。添加到GROUP BY分组中time(1s):
如此小的粒度,我们在12小时的时间间隔(12小时* 60分钟* 60秒= 43,200个间隔,每行43,201点,最后一行为空)中获得了
大量的点:43,201点在图表的每一行中。有很多点,InfluxDB将长时间形成响应,Grafana将花费更长的响应时间,然后浏览器将在很长一段时间内绘制大量的点。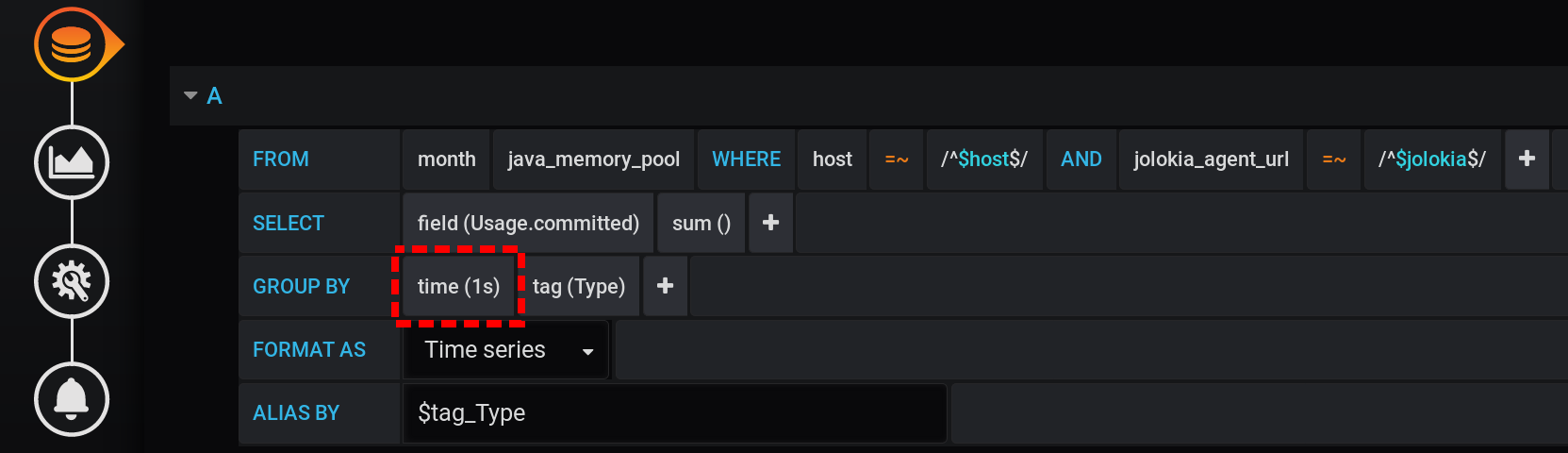
 而且不是每秒钟都有点:指标每2秒收集一次,并按每秒分组,这意味着每秒钟的点将为空。要查看平滑线,请配置非空值的连接。否则,我们将看不到这些图形:
以前,Grafana使得浏览器在绘制大量点时挂起。现在,Grafana版本可以绘制数万个点:浏览器仅跳过其中的一些点,使用稀疏的数据绘制图形。但是该图被平滑了。高点显示为平均高点。
而且不是每秒钟都有点:指标每2秒收集一次,并按每秒分组,这意味着每秒钟的点将为空。要查看平滑线,请配置非空值的连接。否则,我们将看不到这些图形:
以前,Grafana使得浏览器在绘制大量点时挂起。现在,Grafana版本可以绘制数万个点:浏览器仅跳过其中的一些点,使用稀疏的数据绘制图形。但是该图被平滑了。高点显示为平均高点。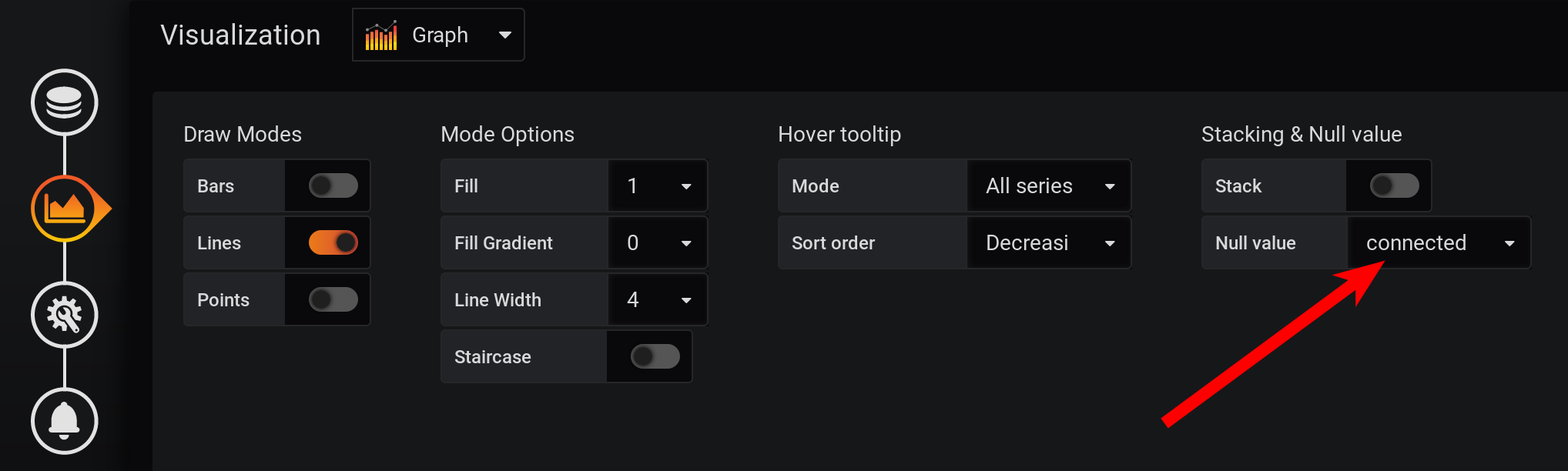 结果,有一个图形,它被正确显示,正确计算了20:00时的度量,正确计算了图表图例中的度量。但是图形是平滑的:1秒的精度在其上看不到爆发。尤其是从图表中消失了17:03时的HEAP激增,HEAP图表非常平滑:
性能的负数将在更长的时间间隔内清楚地体现出来。如果您尝试在一个月(720小时)内而不是在12小时内构建图形,那么所有内容都将以这么小的粒度(1秒)冻结,这将导致太多点。在没有峰值的情况下存在一个负数,这是一个悖论- 由于获取指标的准确性很高,因此显示的准确性也很差。
结果,有一个图形,它被正确显示,正确计算了20:00时的度量,正确计算了图表图例中的度量。但是图形是平滑的:1秒的精度在其上看不到爆发。尤其是从图表中消失了17:03时的HEAP激增,HEAP图表非常平滑:
性能的负数将在更长的时间间隔内清楚地体现出来。如果您尝试在一个月(720小时)内而不是在12小时内构建图形,那么所有内容都将以这么小的粒度(1秒)冻结,这将导致太多点。在没有峰值的情况下存在一个负数,这是一个悖论- 由于获取指标的准确性很高,因此显示的准确性也很差。
2.格拉法纳路。我们使用一堆价值观
使用InfluxDB和Grafana查询设计器无法创建简单而高效的解决方案。我们将仅尝试使用Grafana工具来汇总原始图表中显示的指标。是的,这是可能的!2.1。仅使悬停工具提示/累积值:累积
我们将保持选择指标的要求不变,与“如何开始”部分中的要求相同:
指标将按Type和name分组。但是我们只会在图形的名称中显示Type标签:
并且在可视化设置中,我们将按Grafana堆栈对指标进行分组:
首先,将两个标签的分隔添加到两个不同的堆栈A和B中,以使它们的值不相交: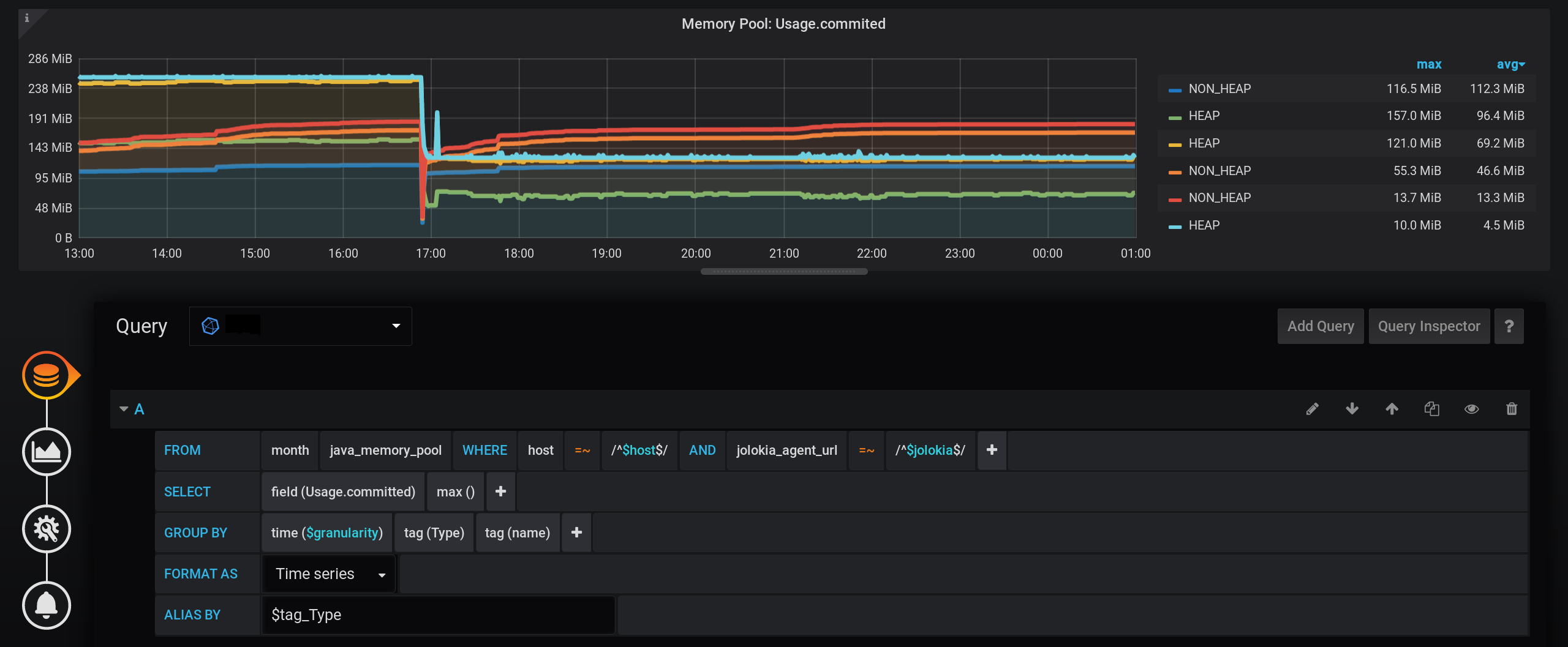
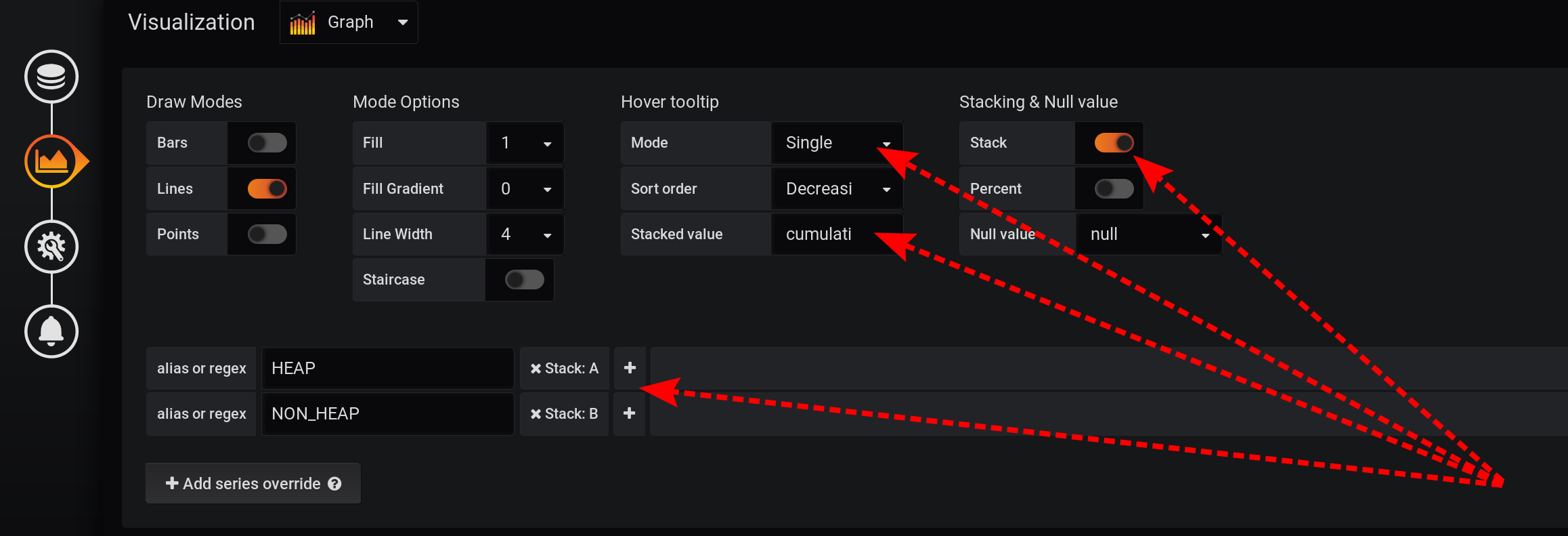
- 添加系列覆盖 / HEAP / 堆栈:A
- 添加系列覆盖 / NON_HEAP / 堆栈:B
然后配置指标的可视化以在带有图形的工具提示中显示总价值:- 堆叠与空值 / 堆叠:开
- 悬停工具提示 / 累计值:累计
- 悬停工具提示 / 模式:单
由于Grafana的不同功能,您需要按该顺序执行操作。如果您更改操作顺序或将某些字段保留为默认设置,则某些操作将无效:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
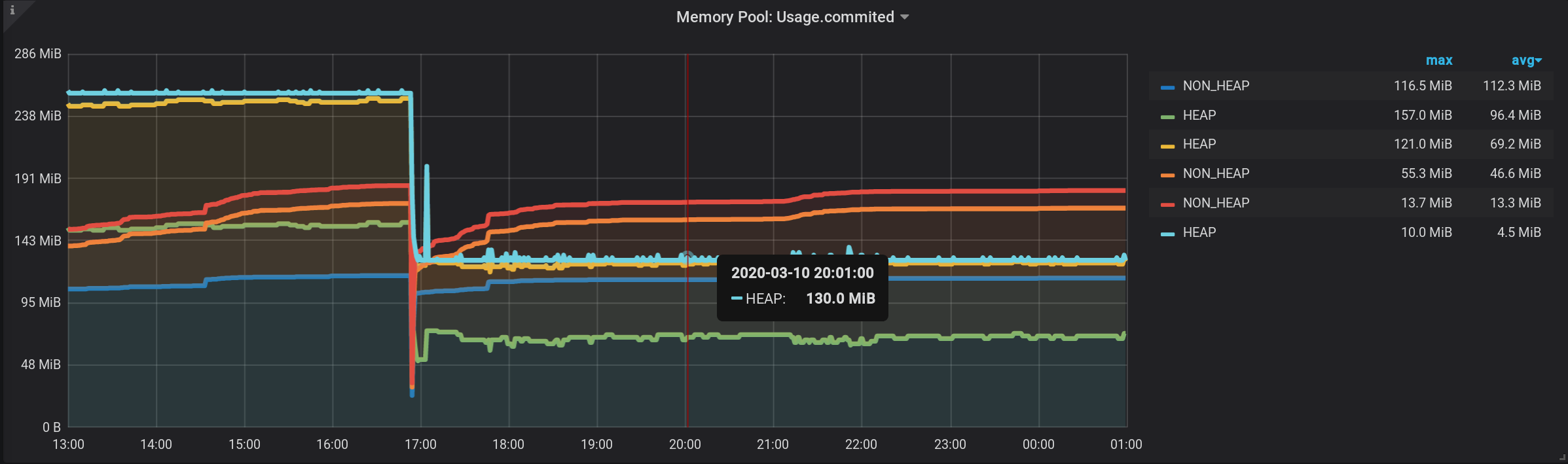
现在,我们看到了很多线条,例如我们自己。但!如果将鼠标悬停在最上面的NON_HEAP上,工具提示将显示所有NON_HEAP的值之和。该金额被认为是正确的,Grafana已经表示:
并且,如果将鼠标悬停在名称为HEAP的最上方图表上,我们将通过HEAP查看该金额。图形显示正确。甚至可以看到17:03 的HEAP激增:
正式地,任务已完成。
但是有缺点-显示了很多额外的图表。您需要将光标移到它们的最上方。并且在图例中,不是累积的,而是显示单个值,因此图例变得无用。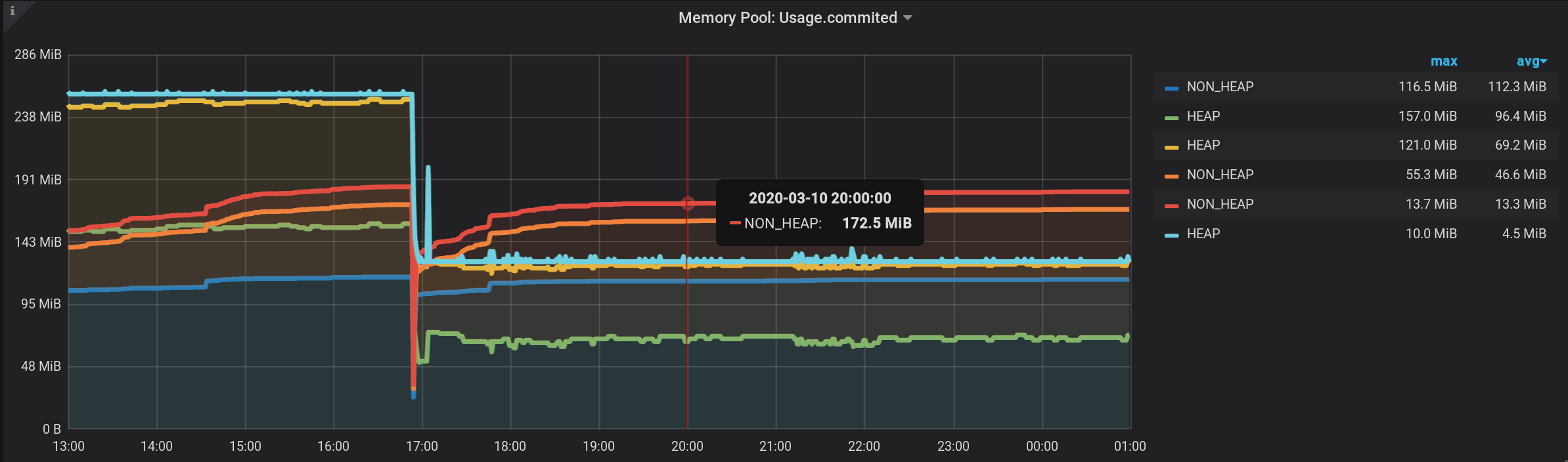
2.2。累加值:累积且隐藏中间行
让我们修复先前解决方案的第一个缺点:确保不显示多余的图表。为了这:- 将具有不同名称和值0的新指标添加到结果中。
- 将新的指标添加到堆栈A和堆栈B到堆栈顶部。
- 从显示隐藏-的原线HEAP和NON_HEAP。
我们在主要请求之后添加两个新值:请求B接收值为0和名称为[NON_HEAP]的序列,请求C接收值为0和名称为[HEAP]的序列。要获得0,我们取每个时间组中“ Usage.committed”字段的第一个值,然后减去它:first(“ Usage.committed”)-first(“ Usage.committed”) -我们得到一个稳定的0。图形的名称在不丢失含义的情况下进行了更改由于方括号:[NON_HEAP]和[HEAP]:[HEAP]和HEAP合并到堆栈A中,并且还隐藏了所有HEAP。[NON_HEAP]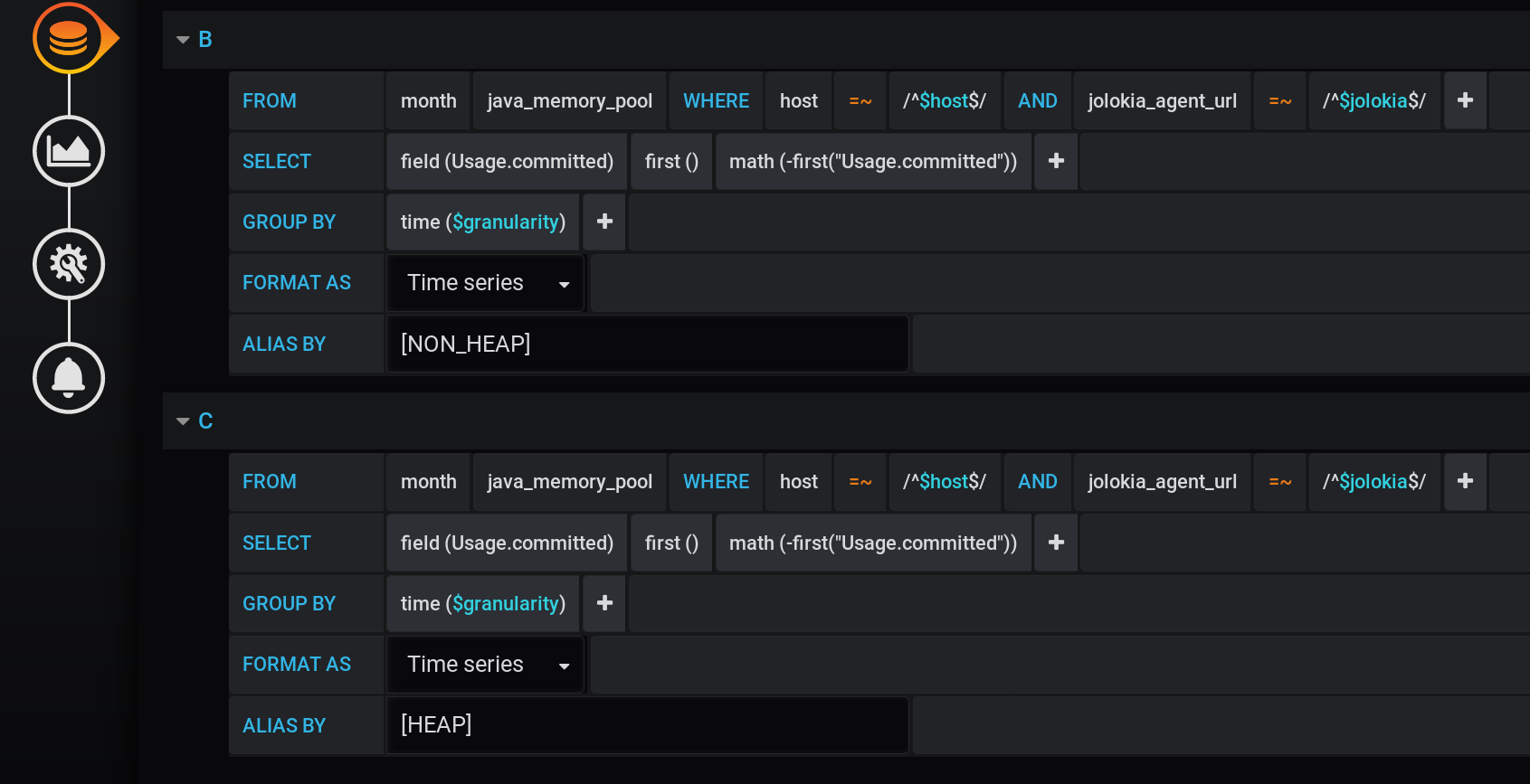 并在堆栈B中合并NON_HEAP并隐藏NON_HEAP:将鼠标悬停在图表上时,通过工具提示中的[NON_HEAP] 获取
正确的金额:将鼠标悬停在图表上时,通过工具提示中
的[HEAP]获取正确的金额。甚至所有的突发事件都是可见的:
而且时间表很快就形成了。但是图例始终显示为0,图例已变得无用。
一切顺利!真正的绕过是通过Grafana堆栈。因此,该文章被添加到“ 异常编程”类别中。
并在堆栈B中合并NON_HEAP并隐藏NON_HEAP:将鼠标悬停在图表上时,通过工具提示中的[NON_HEAP] 获取
正确的金额:将鼠标悬停在图表上时,通过工具提示中
的[HEAP]获取正确的金额。甚至所有的突发事件都是可见的:
而且时间表很快就形成了。但是图例始终显示为0,图例已变得无用。
一切顺利!真正的绕过是通过Grafana堆栈。因此,该文章被添加到“ 异常编程”类别中。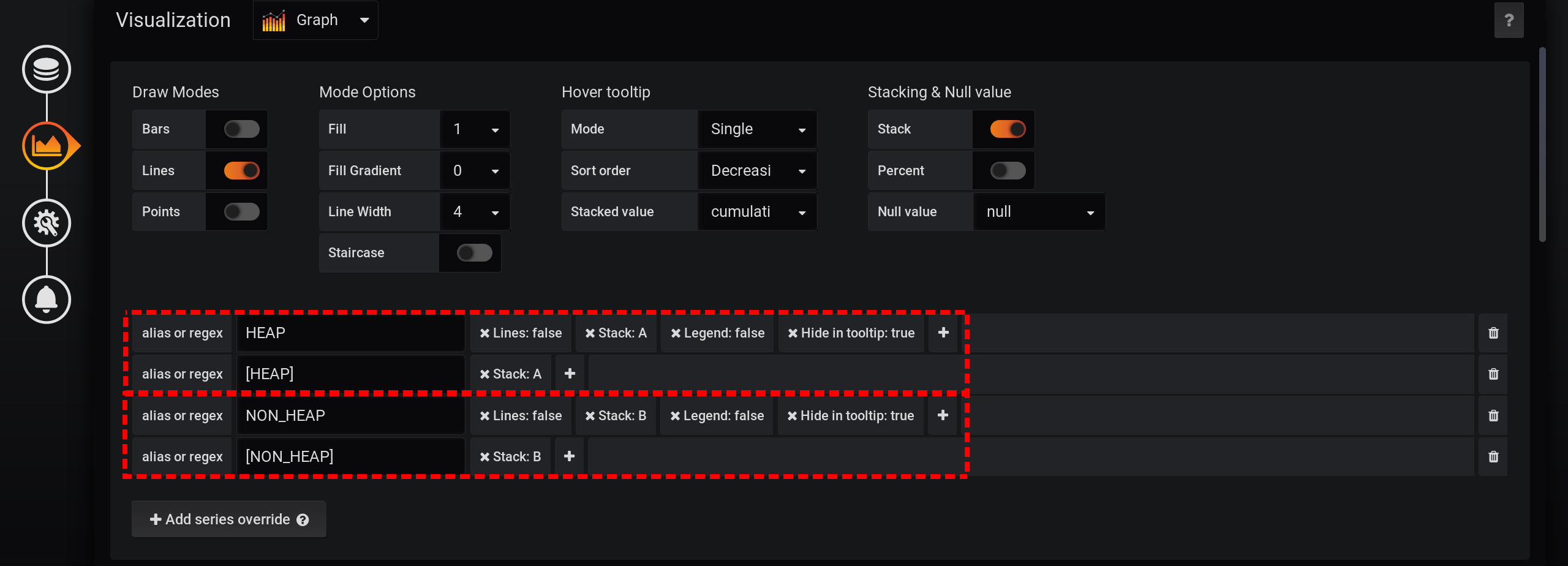


3.子查询的最高和
由于我们已经使用了一系列Grafana和InfluxDB走上了异常编程的道路,让我们继续。让我们让InfluxDB返回少量点并显示图例。3.1最大值的累积和的增量之和
让我们深入研究InfluxDB的可能性。以前,我经常通过提取累计金额的导数来提供帮助,因此,我们现在尝试应用此方法。让我们切换到手动编辑请求的模式:
让我们发出这样的请求:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
这里以时间为单位获取指标中的最大值,并从引用开始的那一刻起将这些值的总和按Type和name标签分组。结果,在每时每刻都会有所有类型的所有指示的总和(HEAP或NON_HEAP),并以池名称分隔,但与版本1.2的情况不同,不会相加30个值,但最大只能是一个。而且,如果在最后一步中采用这种累加总和的non_negative_difference增量,则将在时间间隔开始时获得按Type和name标签分组的所有数据池的总和值。现在,仅按标签获取金额类型(不按名称分组),您需要使用类似的分组参数进行顶级请求,但不按名称进行分组。由于进行了如此复杂的查询,我们得到了所有类型的总和。完美的时间表。最大值的总和是正确计算的。存在具有正确值(非零)的图例。在工具提示中,您可以显示所有指标,而不仅仅是“单一”。甚至显示了HEAP突发:
一件事-事实证明请求很困难:最大值的累积总和的增量随分组级别的变化而增加。
3.2分组级别发生变化的最高和
您能做些比3.1版更简单的事情吗?潘多拉盒子已经打开,我们切换到手动查询编辑模式。有人怀疑从累积量中获得增量会导致零影响-一种消灭另一种。摆脱non_negative_difference(cumulative_sum(...))。简化请求。我们只剩下最大值的总和,而分组级别降低了:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
这是一个快速简单的查询,按分钟分组时,在12小时内每个系列仅返回721点:12(小时)* 60(分钟)= 720个间隔,721个点(最后一个空白)。请注意,时间过滤器已重复。它在子查询和分组请求中:
如果没有$ timeFilter,则在外部分组请求中,返回的点数在12小时内不会是721,而是更多。由于子查询分组是从 ... 到时间间隔执行的,而没有过滤器的外部请求的分组将是从 ... 现在的时间间隔。并且如果在Grafana不被选择的时间间隔过去的X小时(不使得给 = 现在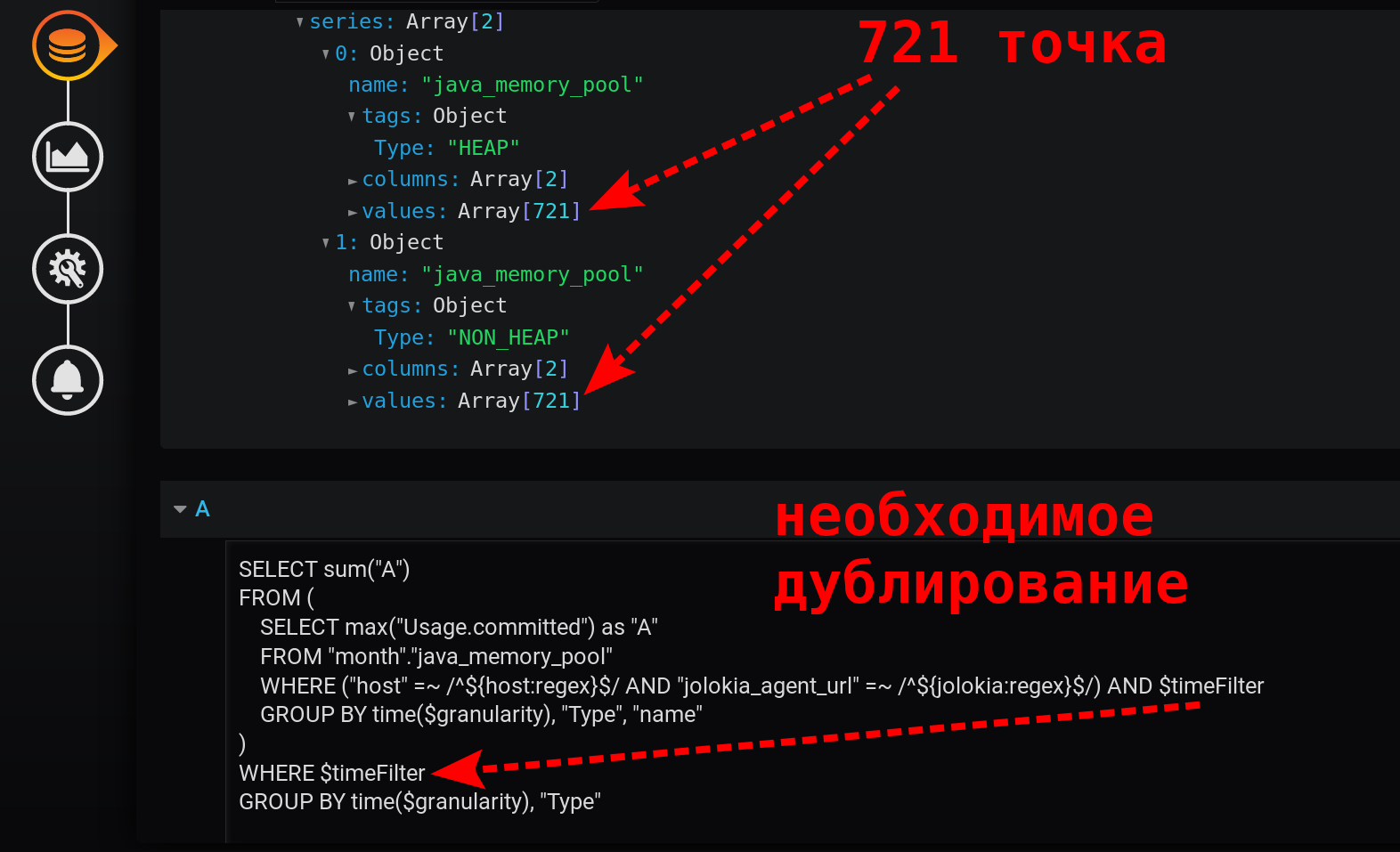 ),但在从过去(到 < 现在)的间隔内,将出现选择末尾具有空值的空点。结果图简单,快速,正确。具有显示摘要指标的图例。带有工具提示,可同时显示多行。并且还显示所有突发值:
结果达到了!
),但在从过去(到 < 现在)的间隔内,将出现选择末尾具有空值的空点。结果图简单,快速,正确。具有显示摘要指标的图例。带有工具提示,可同时显示多行。并且还显示所有突发值:
结果达到了!参考(代替参考)
本文中使用的工具的分布:有关本文中使用的工具功能的文档:性能测试工程师需要众所周知Grafana和InfluxDB
的结合。在此捆绑软件中,许多简单的任务非常有趣,它们不能总是通过常规编程方法来解决。有时,可能需要具有Grafana功能和InfluxDB查询语言的精妙之处的异常编程技能。在本文中,考虑了对按一个标签分组但有多个标签的度量进行汇总的实现的四个步骤。任务很有趣。并且有许多这样的任务。我正在准备一份有关Grafana和InfluxDB编程技巧的报告。我将定期发布有关此主题的材料。同时,对于您对当前文章的疑问,我将感到满意。