本文提出了作者结合模糊数学和分形理论的规定开发的模糊归纳方法,介绍了模糊集的递归度的概念,将集的不完全递归作为分数维来描述主题域。作为所提出的方法的范围和以模糊集为基础创建的知识模型,考虑了信息系统生命周期的管理,包括使用和测试软件的方案的开发。
关联
在设计,开发,实施和运行信息系统的过程中,有必要对从外部收集或在软件生命周期的每个阶段出现的数据,信息和信息进行累积和系统化。这为设计工作和决策提供了必要的信息和方法支持,在不确定性很高的情况下和结构不良的环境中尤其有用。此类资源的积累和系统化形成的知识库不仅应该是项目团队在创建信息系统的过程中获得的有用经验的来源,而且应该是为实现项目任务而进行的新愿景,方法和算法建模的最简单方法。换一种说法,这样的知识库既是知识资本的库,又是知识管理工具的库[3,10]。
知识库作为工具的效率,有用性和质量与其维护的资源强度和知识提取的有效性相关。数据库中知识的收集和修复越简单,越快,查询结果越相关,工具本身就越好,越可靠[1,2]。然而,适用于数据库管理系统的离散方法和结构化工具(包括关系数据库关系的规范化)不允许描述或建模语义成分,解释,区间和连续语义集[4、7、10]。为此,我们需要一种方法论方法来概括有限本体的特定情况,并使知识模型更接近信息系统主题领域描述的连续性。
这种方法可以是模糊数学理论和分形维数概念的组合[3,6]。根据Gödel不完全性原则(在信息系统中,推理不完全性原则,从该系统得出的知识是一致的),在限制条件下,根据连续性的标准(描述的离散化步骤的大小)优化知识的描述,进行顺序模糊化(减少模糊性),我们得到了一个正式的描述,该描述完全连贯地反映了一系列知识,您可以用它执行信息过程的任何操作-收集,存储,处理和传输[5、8、9]。
模糊集递归定义
令X为模拟系统某些特性的值的集合:
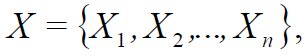 (1)
(1)
n = [N ≥ 3] – (, (0; 1) – (; )).
X = B, B = {a,b,c,...,z} – , X.
 , ( ) , X, :
, ( ) , X, :
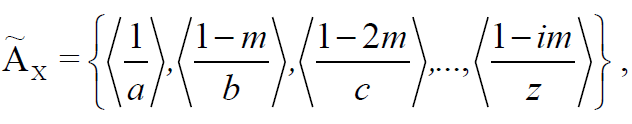 (2)
(2)
m – , i N – .
, () , , :
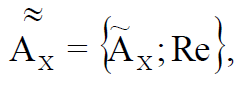 (3)
(3)
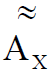 – , , X, , ; Re – .
– , , X, , ; Re – .
, 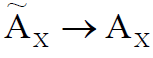 ( ) .
( ) .
Re = 1 2- , ( ), X [1, 2]:
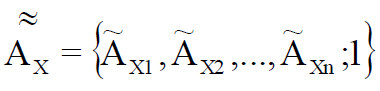 (4)
(4)
– , , – ( ) . – ( – ) [3, 9].
Re :
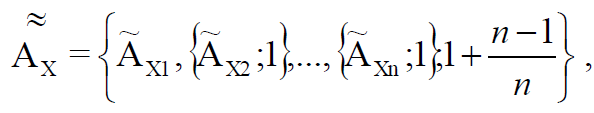 (5)
(5)
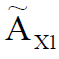 – X1,
– X1, 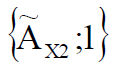 – X2 . .
– X2 . .
, – .
, , , . , , , .
, , .
: ( ), ( ), ( ).
X – , X :
 (6)
(6)
X1 – , X2 – , X3 – ,
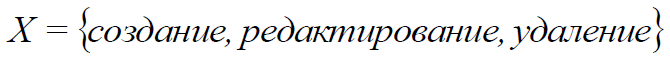 (7)
(7)
, ( – ), ( ), .
, X ( ), .
, () « » :
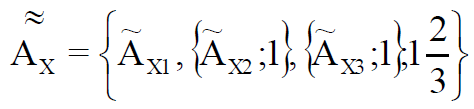 (8)
(8)
1,6(6) .
, ( , . use-case), ( , . test-case).
, , .
:
 (9)
(9)
– X;
 – X, a ( ) 1;
– X, a ( ) 1;
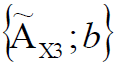 – X, b ( ) 1.
– X, b ( ) 1.
, ( ) , / .
Ux X , , ( -) , / , , :
 (10)
(10)
n – X.
Tx X . , , :
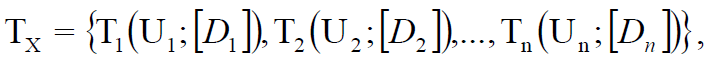 (11)
(11)
[D] – , n – X.
, . , .
, .
, « », , . , , .
« » , , .
- .., .., .., « ». .: – , 2014. – 88 .
- .., .., .., « ». .: – , 2014. – 122 .
- .., «: ». : , 2011. – 296 .
- ., « » / « ». .: «», 1974. – . 5 – 49.
- ., « ». .: , 2016. – 320 .
- .., « » / «», №54 (2/2008), http://www.delphis.ru/journal/article/fraktalnaya-matematika-i-priroda-peremen.
- ., « ». .: , 2002. – 656 .
- « : », . .., .. : - . . . -, 2003. – 24 .
- .., « ». .: -, 2017. – 622 .
- Zimmerman H. J. «Fuzzy Set Theory – and its Applications», 4th edition. Springer Seience + Business Media, New York, 2001. – 514 p.