大家好。2月26日,在OTUS中的“ MS SQL Server Developer”课程中的新班级上了课程。在这方面,我想与您分享有关窗口功能的出版物。顺便说一句,在接下来的一周,您仍然可以加入;-)组。
窗口功能在我们的实践中已经很完善,但是很少有人知道RANGE和ROWS框架是如何工作的。也许这就是为什么它们不那么常见的原因。本文的目的是提供使用示例,以便您绝对不会出现“谁是谁”的问题。和“如何应用?”。问题“为什么?” 该文章将保持不变。让我们看一下什么是框架以及如何使用OVER()子句中的ORDER By实现类似的效果。为了演示,我们将使用一个简单的表,以便您无需使用编译器即可计算示例。通常,我强烈建议您-查看并考虑执行的结果,然后再检查一下自己-这样您会在感知窗口函数时发现白点,当您阅读完成的结果时可能不会很明显。表Create table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
让我们从一个简单的时刻开始-带和不带排序的SUM函数的区别SELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;
 让我们看一下第一个不起眼的耙子,您认为有多少开发人员在阅读代码时认为cum和cum_uniq是相同的?想一点吗?也许是这样,但是因为在这里它是显而易见的,并且在阅读应用程序中的代码时是如此明显,甚至排序字段的非唯一性也不那么明显。现在打开我们美妙的窗户。窗口,或者说框架是ROWS和RANGE的两种类型,首先要了解ROWS。帧限制选项:
让我们看一下第一个不起眼的耙子,您认为有多少开发人员在阅读代码时认为cum和cum_uniq是相同的?想一点吗?也许是这样,但是因为在这里它是显而易见的,并且在阅读应用程序中的代码时是如此明显,甚至排序字段的非唯一性也不那么明显。现在打开我们美妙的窗户。窗口,或者说框架是ROWS和RANGE的两种类型,首先要了解ROWS。帧限制选项:- 当前行/范围之前的所有内容以及当前行的实际值在未
绑定的前缀之间和在未
绑定的前缀之间和当前行之间
- 当前行/范围及其后的所有内容在当前行
和无边界跟随之间 - 之前和之后的指定有多少行,包括(不支持RANGE)
之间的N个前后N按照
CURRENT ROW和n之间继
N之间前后CURRENT ROW
但是,让我们看看实际的框架。如您所见,我们在当前行和所有以前的行中都打开了“窗口”,如您所见,这与ASC排序是一致的SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;
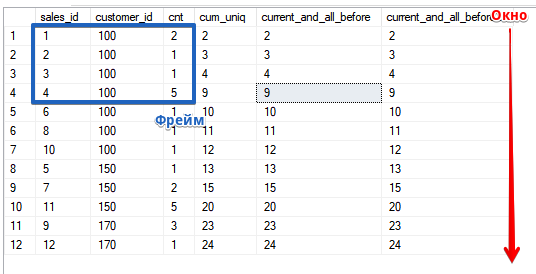 我想提醒您,窗口(在OVER()子句中)的排序顺序与查询本身的排序顺序无关,在此示例中,如果您决定检查计算并了解函数的工作原理,则可以简化计算
我想提醒您,窗口(在OVER()子句中)的排序顺序与查询本身的排序顺序无关,在此示例中,如果您决定检查计算并了解函数的工作原理,则可以简化计算SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;
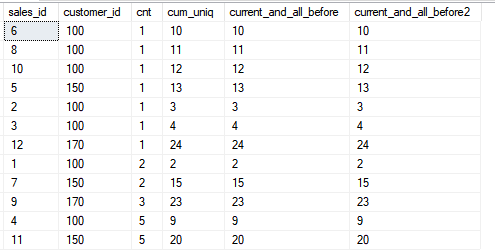 现在,当我们包含所有后续行时,让我们看一下框架的功能。
现在,当我们包含所有后续行时,让我们看一下框架的功能。SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
 如您在此处看到的,如果使用反向排序,则对于聚合函数也可以获得相同的结果-但是ROWS稍微稳定一点,因为如果您的排序字段不是唯一的,则可以以相同的值形式得到惊喜。最后,当我们指定应包含在框架中的特定行数时,该选项将不再能被分类模仿
如您在此处看到的,如果使用反向排序,则对于聚合函数也可以获得相同的结果-但是ROWS稍微稳定一点,因为如果您的排序字段不是唯一的,则可以以相同的值形式得到惊喜。最后,当我们指定应包含在框架中的特定行数时,该选项将不再能被分类模仿SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;
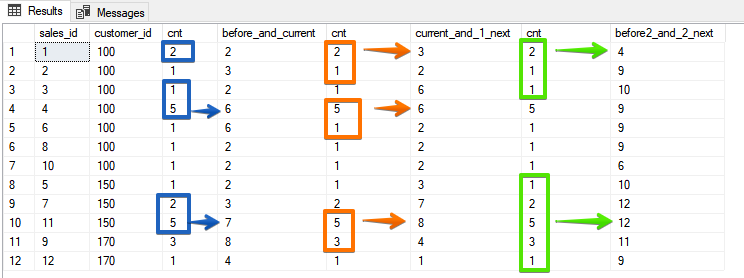 在此选项中,您已经明确指出了范围内的哪些行,我认为,从结果中最明显。
在此选项中,您已经明确指出了范围内的哪些行,我认为,从结果中最明显。ROWS和RANGE之间的区别
区别在于ROWS在行上运行,RANGE在范围上运行。是的,这从名称上是显而易见的,但在实践中解释不多?让我们看一下图片(文章底部的源代码)。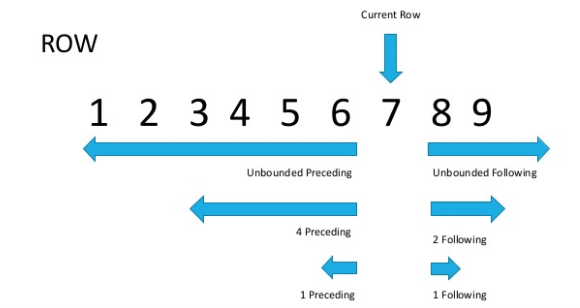
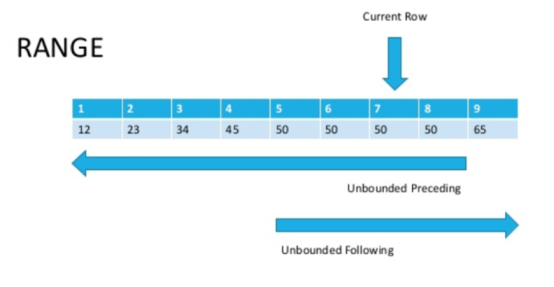 现在,如果仔细看,很明显,具有相同sort参数值的行称为范围。如上所述,ROWS被限制为字符串,而RANGE捕获您在ORDER BY窗口函数中指定的匹配值的整个范围。
现在,如果仔细看,很明显,具有相同sort参数值的行称为范围。如上所述,ROWS被限制为字符串,而RANGE捕获您在ORDER BY窗口函数中指定的匹配值的整个范围。SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;
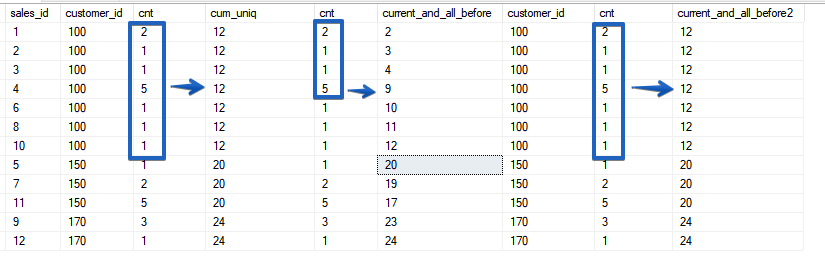 ROWS-即使排序不是唯一的,也始终使用特定的行进行操作,但是RANGE只是将时间段与范围与排序字段的匹配值组合在一起。从这个意义上讲,该功能与SUM()函数的行为非常相似,并且按非唯一字段进行排序。让我们来看另一个例子。
ROWS-即使排序不是唯一的,也始终使用特定的行进行操作,但是RANGE只是将时间段与范围与排序字段的匹配值组合在一起。从这个意义上讲,该功能与SUM()函数的行为非常相似,并且按非唯一字段进行排序。让我们来看另一个例子。SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;
 已经有2个字段,范围由两个字段都具有匹配值的范围确定。选项是当我们在计算中包括当前字段的所有后续行时(在SUM函数的情况下,该行与可以使用反向排序获得的值相符):
已经有2个字段,范围由两个字段都具有匹配值的范围确定。选项是当我们在计算中包括当前字段的所有后续行时(在SUM函数的情况下,该行与可以使用反向排序获得的值相符):SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;
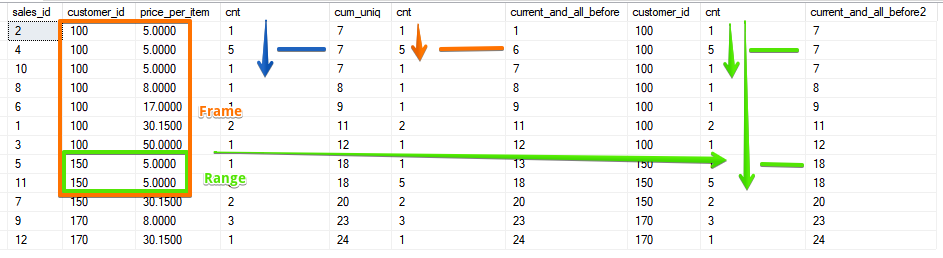 如您所见,RANGE再次捕获了匹配对的整个范围。尽管ROWS和RANGE的功能并非每次都是新的,但有关如何使用它的问题仍然存在。我希望本文能加深对ROWS和RANGE有何不同的理解,现在您将不会怀疑在哪种情况下需要该框架。插图源RANGE关于差异和ROWSWindow函数的介绍对于SQL Server 2016,Mark Tabladillo赶上了课程
如您所见,RANGE再次捕获了匹配对的整个范围。尽管ROWS和RANGE的功能并非每次都是新的,但有关如何使用它的问题仍然存在。我希望本文能加深对ROWS和RANGE有何不同的理解,现在您将不会怀疑在哪种情况下需要该框架。插图源RANGE关于差异和ROWSWindow函数的介绍对于SQL Server 2016,Mark Tabladillo赶上了课程