在Kubernetes中实现CI / CD的典型条件是:应用程序必须能够在停止之前停止接受新的客户端请求,最重要的是,成功完成现有请求。 符合此条件可使您在部署期间实现零停机时间。但是,即使使用非常流行的捆绑软件(例如NGINX和PHP-FPM),您也可能会遇到困难,这将导致每次部署中出现大量错误...
符合此条件可使您在部署期间实现零停机时间。但是,即使使用非常流行的捆绑软件(例如NGINX和PHP-FPM),您也可能会遇到困难,这将导致每次部署中出现大量错误...理论。豆荚如何生活
我们已经发表这篇文章中关于荚生命周期的细节。在本主题的上下文中,我们对以下内容感兴趣:当pod进入Termination状态时,不再向其发送新请求(将pod 从服务的端点列表中删除)。因此,对于我们而言,为了避免在部署过程中出现停机,足以解决应用程序正确停止的问题。还应记住,默认情况下宽限期为30秒:此后,吊舱将终止,应用程序应设法在此期间之前处理所有请求。注意:尽管运行超过5-10秒的任何请求都已经有问题,并且正常关机将不再对他有帮助...为了更好地了解pod完成其工作会发生什么,只需研究以下方案即可: A1,B1-进行更改子
A1,B1-进行更改子
A2的状态:发送SIGTERM
B2-从端点删除Pod
B3-获取更改(端点列表已更改)
B4-更新iptables规则注意:删除端点Pod和发送SIGTERM不会顺序发生,而是并行发生。并且由于Ingress不会立即收到更新的端点列表,因此来自客户端的新请求将发送到Pod,这会在Pod终止期间导致500个错误(我们翻译了关于这个问题的更详细的资料)。您需要通过以下方式解决此问题:- 发送Connection的标题:关闭响应(如果它涉及HTTP应用程序)。
- 如果无法对代码进行更改,那么本文将介绍一种解决方案,该解决方案将允许您处理请求,直到宽限期结束为止。
理论。NGINX和PHP-FPM如何结束进程
Nginx的
让我们从NGINX开始,因为一切都差不多。沉浸在该理论中,我们了解到NGINX具有一个主流程和多个“工作者”-这些是处理客户请求的子流程。提供了一个方便的功能:使用该命令以nginx -s <SIGNAL>快速关闭方式或正常关闭方式终止进程。显然,我们对后一种选择很感兴趣。然后一切都变得很简单:您需要向preStop挂钩添加命令,该命令将发送有关正常关机的信号。这可以在Deployment的容器块中完成: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
现在,在pod在NGINX容器日志中完成其工作的时刻,我们将看到以下内容:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
这将意味着我们需要的:NGINX等待查询完成,然后终止该过程。但是,下面将讨论一个常见问题,因此,即使有命令,该nginx -s quit过程也无法正确完成。至此,我们已经完成了NGINX的工作:至少您可以从日志中了解到一切正常。PHP-FPM呢?如何处理正常关机?让我们做对。PHP-FPM
对于PHP-FPM,信息少一些。如果您专注于PHP-FPM 的官方手册,那么它将告诉您收到了以下POSIX信号:SIGINT,SIGTERM-快速关机;SIGQUIT -正常关机(我们需要什么)。
不需要此问题中的其余信号,因此,将省略对其的分析。为了正确完成该过程,您将需要编写以下preStop挂钩: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
乍一看,这是在两个容器中正常关闭所需要的全部。但是,任务比看起来要复杂。接下来,我们检查了两种情况,其中正常关机不起作用,并且在部署期间导致项目短期无法访问。实践。正常关机的可能问题
Nginx的
首先,记住以下内容很有用:除了执行命令外,nginx -s quit还应注意另一步骤。无论如何,当NGINX而不是SIGQUIT信号发送SIGTERM时,我们遇到了一个问题,由于该请求未能正确完成。例如,在这里可以找到类似的情况。不幸的是,我们无法确定出现此行为的具体原因:有人怀疑NGINX版本,但没有得到证实。症状是,在NGINX容器的日志中,观察到消息“连接5中剩下的打开的套接字#10”,此后容器停止了。我们可以观察到这样的问题,例如,通过所需的Ingress答案: 部署时的状态码指示器在这种情况下,我们只能从Ingress本身获得503错误代码:由于它不再可用,它无法访问NGINX容器。如果您使用NGINX查看容器的日志,则它们包含以下内容:
部署时的状态码指示器在这种情况下,我们只能从Ingress本身获得503错误代码:由于它不再可用,它无法访问NGINX容器。如果您使用NGINX查看容器的日志,则它们包含以下内容:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
更改停止信号后,容器将开始正确停止:这已通过不再观察到503错误这一事实得到确认。如果遇到类似的问题,弄清楚在容器中使用了哪个停止信号以及preStop挂钩的外观如何是有意义的。原因可能恰恰在于此。PHP-FPM等
简单描述了PHP-FPM的问题:它不等待子进程完成,而是终止子进程,因此在部署和其他操作过程中会出现502个错误。自2005年以来,在bugs.php.net上已经出现了几条描述此问题的错误消息(例如,here和here)。但是您可能不会在日志中看到任何内容:PHP-FPM将宣布其过程完成,而不会出现任何错误或第三方通知。值得澄清的是,问题本身或多或少地取决于应用程序本身,例如在监视中可能不会出现。如果仍然遇到它,那么想到一个简单的解决方法:添加带有以下内容的preStop挂钩:sleep(30)。它将允许您完成之前的所有请求(由于Pod 已处于“ 终止”状态,因此我们不接受新请求),并且30秒钟后,pod本身将以信号结束SIGTERM。事实证明,lifecycle对于容器,它将如下所示: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
但是,由于30秒的指示,sleep我们将大大延长部署时间,因为每个吊舱将终止至少 30秒,这很糟糕。该怎么办?让我们转向负责直接执行应用程序的一方。在我们的例子中,这是PHP-FPM,默认情况下它不监视其子进程的执行:主进程立即终止。可以使用伪指令更改此行为,该伪指令process_control_timeout指定子进程等待主机发出的信号的时间限制。如果将该值设置为20秒,则它将覆盖容器中运行的大多数请求,完成请求后,主进程将停止。有了这些知识,我们将回到我们的最后一个问题。如前所述,Kubernetes并不是一个整体的平台:它的各个组件之间的交互需要一些时间。当我们考虑Ingress和其他相关组件的工作时尤其如此,因为由于部署时的这种延迟,很容易爆发500个错误。例如,在向上游发送请求的阶段可能会发生错误,但是组件之间交互的“时滞”相当短-不到一秒钟。因此,结合已经提到的指令process_control_timeout,以下构造可用于lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
在这种情况下,我们补偿了团队的延迟,sleep并且没有显着增加部署时间:30秒与一个之间有明显的区别吗?..本质上process_control_timeout,它承担着“主要工作” ,但lifecycle在出现滞后时仅用作“安全网”。一般而言,所描述的行为和相应的解决方法不仅涉及PHP-FPM。使用其他语言/框架时,可能会以一种或另一种方式出现类似情况。如果您无法通过其他方式修复正常关机(例如,重写代码以使应用程序正确处理终止信号),则可以使用上述方法。它可能不是最漂亮的,但是可以工作。实践。负载测试以验证Pod性能
负载测试是检查容器工作方式的一种方法,因为此过程使您在用户访问站点时更接近真实的战斗条件。您可以使用Yandex.Tank来测试以上建议:它完全可以满足我们的所有需求。以下是通过Grafana和Yandex.Tank本身的图表进行清晰测试的技巧和窍门-我们经验的示例。这里最重要的是检查阶段的变化。。添加新修复程序后,运行测试,并查看结果是否与以前的启动相比有所更改。否则,将很难确定无效的解决方案,并且将来您只能造成危害(例如,增加部署时间)。另一个警告-查看容器终止期间的日志。是否在此处记录了正常关机信息?访问其他资源(例如,相邻的PHP-FPM容器)时,日志中是否存在任何错误?应用程序本身的错误(例如上述NGINX的情况)?我希望本文的介绍性信息将有助于更好地了解容器在终止期间会发生什么情况。因此,第一次测试运行是在没有lifecycle应用程序服务器附加指令的情况下进行的(process_control_timeout在PHP-FPM中)。该测试的目的是确定错误的大概数量(以及是否完全存在)。同样,从其他信息中,应该知道每个炉床的平均展开时间约为5-10秒(完全就绪)。结果如下: 在Yandex.Tank信息面板上看到502错误的飞溅,该错误在部署时发生,平均持续长达5秒钟。大概这终止了对旧Pod的现有请求。之后,出现了503个错误,这是由于NGINX容器已停止而导致的,该容器也由于后端而断开连接(因此Ingress无法与其连接)。让我们看看如何
在Yandex.Tank信息面板上看到502错误的飞溅,该错误在部署时发生,平均持续长达5秒钟。大概这终止了对旧Pod的现有请求。之后,出现了503个错误,这是由于NGINX容器已停止而导致的,该容器也由于后端而断开连接(因此Ingress无法与其连接)。让我们看看如何process_control_timeoutPHP-FPM中的代码将帮助我们等待子进程的完成,即 解决此类错误。使用此指令重复部署: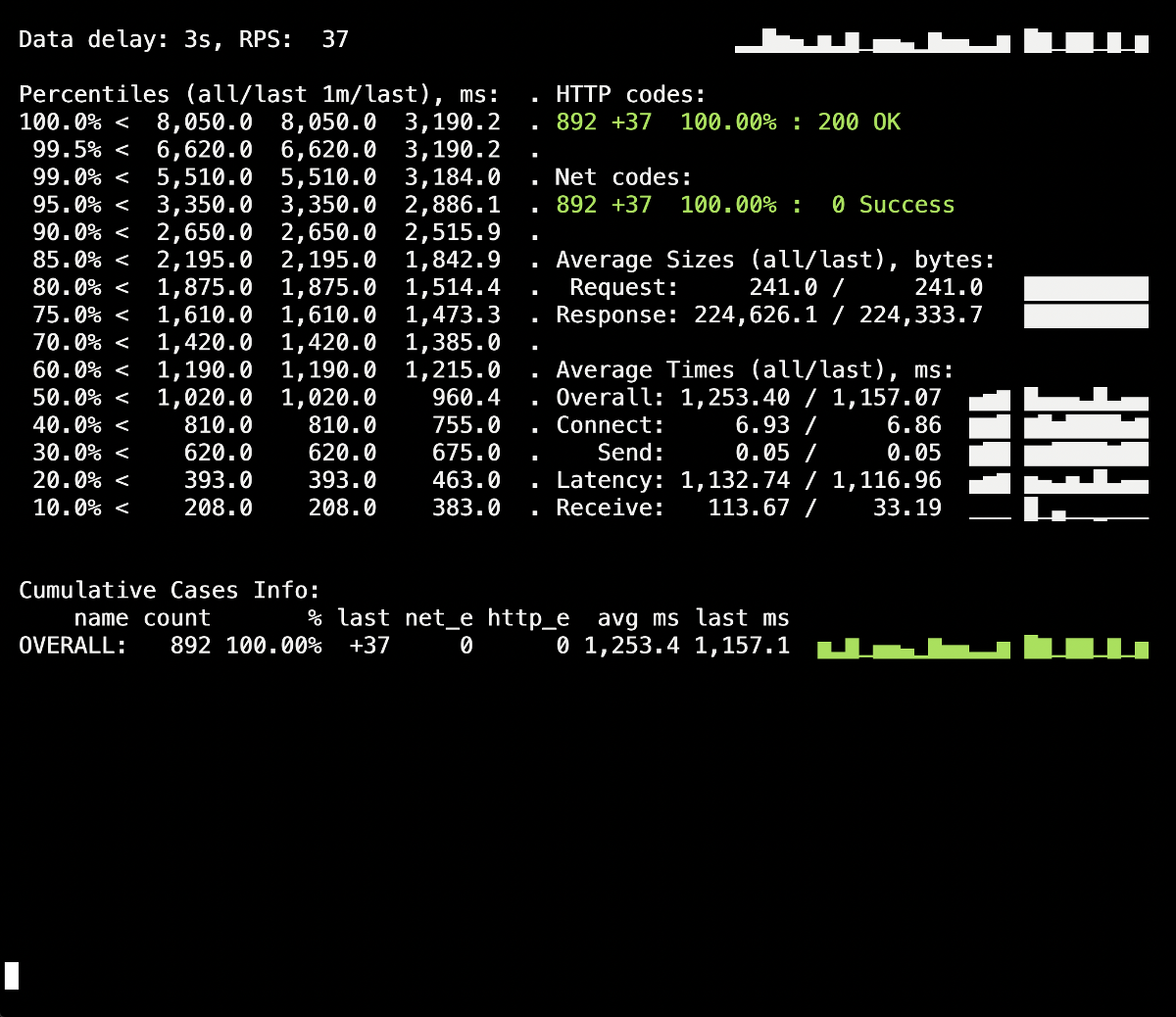 500s部署期间没有更多错误!部署成功,正常关机即可。但是,值得记住使用Ingress容器的那一刻,因为时滞会导致一小部分错误。为了避免它们,仍然需要添加构造
500s部署期间没有更多错误!部署成功,正常关机即可。但是,值得记住使用Ingress容器的那一刻,因为时滞会导致一小部分错误。为了避免它们,仍然需要添加构造sleep并重复部署。但是,在我们的特定情况下,看不到任何更改(再次没有错误)。结论
为了正确完成该过程,我们期望应用程序具有以下行为:- 等待几秒钟,然后停止接受新连接。
- 等待所有请求完成并关闭所有不执行请求的保持连接。
- 完成您的过程。
但是,并非所有应用程序都可以这种方式工作。解决Kubernetes现实中的问题的一种方法是:- 添加将等待几秒钟的停止前挂钩
- 研究后端的配置文件以获取相关参数。
NGINX的示例使我们能够理解,即使是最初必须正确处理信号才能完成的应用程序也可能无法做到这一点,因此在应用程序部署期间检查500个错误至关重要。它还使您可以更广泛地看待问题,而不必专注于单独的容器或容器,而可以看待整个基础架构。Yandex.Tank可以与任何监视系统一起用作测试工具(在我们的示例中,来自Grafana的数据以Prometheus形式的后端进行了测试)。在基准测试可能产生的重负载下,正常关机的问题显而易见,监视功能有助于在测试期间或测试后更详细地分析情况。回应对文章的反馈:值得一提的是,这里针对NGINX Ingress阐述了问题和解决方案。对于其他情况,也许有其他解决方案,我们可能会在以下周期材料中考虑。聚苯乙烯
K8s提示和技巧周期中的其他内容: