什么是数据结构?简而言之,数据结构是一个容器,其中数据以特定的布局(格式或在内存中的组织方式)存储。这种“布局”使数据结构在某些操作中有效,而在另一些操作中无效。您的目标是了解数据结构,以便可以选择最适合所讨论问题的数据结构。为什么我们需要数据结构?因为数据结构用于以有组织的方式存储数据,并且由于数据是计算机科学中最重要的元素,所以数据结构的真正价值显而易见。无论您解决什么问题,都必须以一种或另一种方式处理数据-无论是员工的工资,股票价格,购物清单还是简单的电话簿。根据不同的方案,数据应以特定格式存储。我们有几种数据结构,涵盖了以不同格式存储数据的需求。常用的数据结构让我们首先列出最常用的数据结构,然后逐一查看它们:- 数组-数组
- 堆栈-堆栈
- 队列-队列
- 链接列表-相关列表
- 树木-树木
- 图-图
- 尝试(它们本质上是树,但是单独命名它们仍然很不错)。- 优先
- 哈希表-哈希表
数组-数组数组是最简单,使用最广泛的数据结构。其他数据结构(例如堆栈和队列)是从数组派生的。这是包含元素(1、2、3和4)的大小为4的简单数组的图像。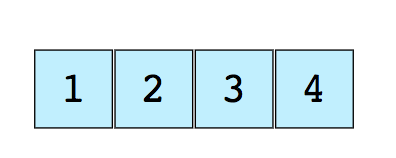 每个数据项都被分配一个称为索引的正数值,该索引对应于该项在数组中的位置。大多数语言将数组的起始索引定义为0.以下是两种类型的数组:
每个数据项都被分配一个称为索引的正数值,该索引对应于该项在数组中的位置。大多数语言将数组的起始索引定义为0.以下是两种类型的数组:- 一维数组(如上所示)
- 多维数组(数组内部的数组)多维数组
数组的基本操作Insert-
在指定的索引处插入元素Delete(Delete)-删除在指定索引处的元素Size-获取数组中元素的总数自学习:1查找数组的第二个最小元素。2.数组中的第一个非重复整数。3.合并两个排序的数组。4.对数组中的正值和负值重新排序。堆栈我们都熟悉著名的选项“撤消(取消)”,该选项几乎出现在每个应用程序中。有没有想过这是如何工作的?该机制的本质是将工作的先前状态(受一定数量的限制)保存在内存中,以使最后一个动作首先出现。仅数组不能做到这一点。那就是堆栈派上用场的地方!堆栈的一个真实示例是一堆垂直排列的书。要在中间某处放置一本书,您需要删除所有放在其顶部的书。这是LIFO(后进先出)方法的工作方式。这是包含三个数据元素(1、2和3)的堆栈的图像,其中3在顶部,将首先删除: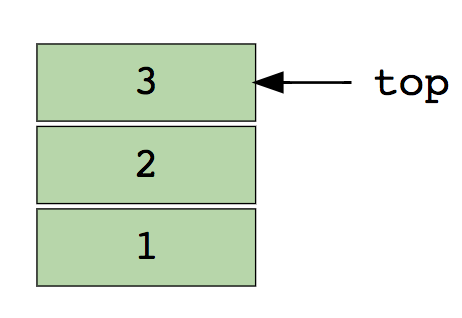 堆栈的基本操作:推-在其他元素之上插入元素。拉(弹出)-从堆栈中移除后返回顶部元素。空吗(IsEmpty)-如果堆栈为空,则返回true(true)。顶部(顶部)-返回顶部元素,而不从堆栈中删除。对于独立研究:1.使用堆栈评估后缀表达式。2.在堆栈上对值进行排序。3.检查表达式中的平衡括号。队列就像堆栈一样,队列是另一个线性数据结构,其中的项按顺序存储。堆栈和队列之间的唯一显着区别是,Queue使用了一种方法,而不是使用LIFO方法FIFO,先进先出的缩写。一个真实的路线示例:许多人在售票处等车。如果有新人到达,他将从头开始而不是从一开始就加入队伍,而站在前面的人将是第一个收到车票的人,因此将离开队伍。这是包含四个数据元素(1、2、3和4)的队列的图像,其中1在顶部,并且将首先被删除:
堆栈的基本操作:推-在其他元素之上插入元素。拉(弹出)-从堆栈中移除后返回顶部元素。空吗(IsEmpty)-如果堆栈为空,则返回true(true)。顶部(顶部)-返回顶部元素,而不从堆栈中删除。对于独立研究:1.使用堆栈评估后缀表达式。2.在堆栈上对值进行排序。3.检查表达式中的平衡括号。队列就像堆栈一样,队列是另一个线性数据结构,其中的项按顺序存储。堆栈和队列之间的唯一显着区别是,Queue使用了一种方法,而不是使用LIFO方法FIFO,先进先出的缩写。一个真实的路线示例:许多人在售票处等车。如果有新人到达,他将从头开始而不是从一开始就加入队伍,而站在前面的人将是第一个收到车票的人,因此将离开队伍。这是包含四个数据元素(1、2、3和4)的队列的图像,其中1在顶部,并且将首先被删除: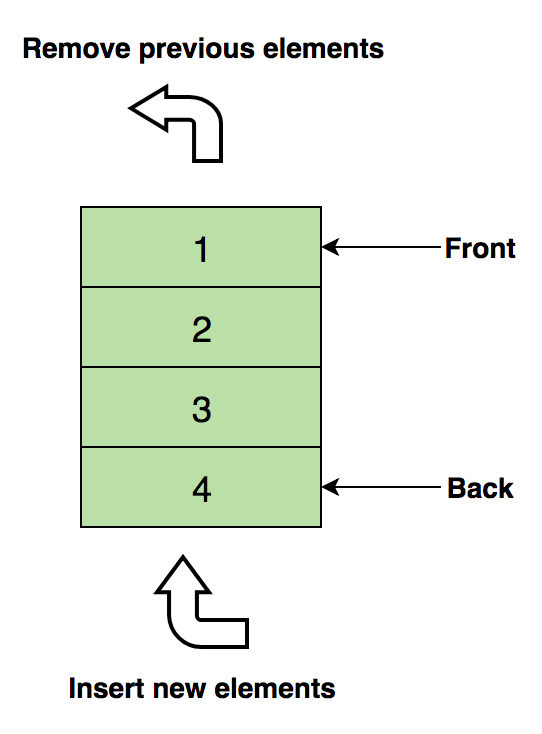 队列的基本操作:入队-在队列的末尾插入一个元素。出队-从队列的开头删除项目。空吗(IsEmpty)-如果队列为空,则返回true(true)。顶部(顶部)-返回队列的第一个元素。对于独立学习:1.使用队列实现堆栈。2.队列的前k个元素相反。3.使用队列生成从1到n的二进制数。链表链表是另一个重要的线性数据结构,乍一看可能看起来与数组相似,但是在内存分配,内部结构以及基本插入和删除操作的执行方式上有所不同。链表就像一个节点链,其中每个节点都包含诸如数据之类的信息,以及指向链中下一个节点的指针。有一个标头指针指向链接列表的第一个元素,如果列表为空,则仅指向零或不指向任何内容。链接列表用于实现文件系统,哈希表和邻接列表。这是链表的内部结构的直观表示:
队列的基本操作:入队-在队列的末尾插入一个元素。出队-从队列的开头删除项目。空吗(IsEmpty)-如果队列为空,则返回true(true)。顶部(顶部)-返回队列的第一个元素。对于独立学习:1.使用队列实现堆栈。2.队列的前k个元素相反。3.使用队列生成从1到n的二进制数。链表链表是另一个重要的线性数据结构,乍一看可能看起来与数组相似,但是在内存分配,内部结构以及基本插入和删除操作的执行方式上有所不同。链表就像一个节点链,其中每个节点都包含诸如数据之类的信息,以及指向链中下一个节点的指针。有一个标头指针指向链接列表的第一个元素,如果列表为空,则仅指向零或不指向任何内容。链接列表用于实现文件系统,哈希表和邻接列表。这是链表的内部结构的直观表示: 以下是链表的类型:链表的基本操作InsertAtEnd- 在链表的末尾插入一个项目。InsertB Start(InsertAtHead)-在链接列表的开头插入一个项目。删除-从链接列表中删除该项目。DeleteBeginning(DeleteAtHead)-删除链接列表的第一个元素。搜索-从链接列表中返回找到的项目。空吗(IsEmpty)-如果链接列表为空,则返回true(true)。对于独立学习:1.翻转链接列表(反向,反向,向后显示)。2.在链表中定义一个循环。3.从链接列表的末尾返回第N个节点。4.从链接列表中删除重复项。图图是以网络形式相互连接的节点的集合。节点也称为顶点。该对(x,y)称为边,它表示顶点x与顶点y连接。一条边可以包含重量/成本,显示从顶部x移到y所需的成本。
以下是链表的类型:链表的基本操作InsertAtEnd- 在链表的末尾插入一个项目。InsertB Start(InsertAtHead)-在链接列表的开头插入一个项目。删除-从链接列表中删除该项目。DeleteBeginning(DeleteAtHead)-删除链接列表的第一个元素。搜索-从链接列表中返回找到的项目。空吗(IsEmpty)-如果链接列表为空,则返回true(true)。对于独立学习:1.翻转链接列表(反向,反向,向后显示)。2.在链表中定义一个循环。3.从链接列表的末尾返回第N个节点。4.从链接列表中删除重复项。图图是以网络形式相互连接的节点的集合。节点也称为顶点。该对(x,y)称为边,它表示顶点x与顶点y连接。一条边可以包含重量/成本,显示从顶部x移到y所需的成本。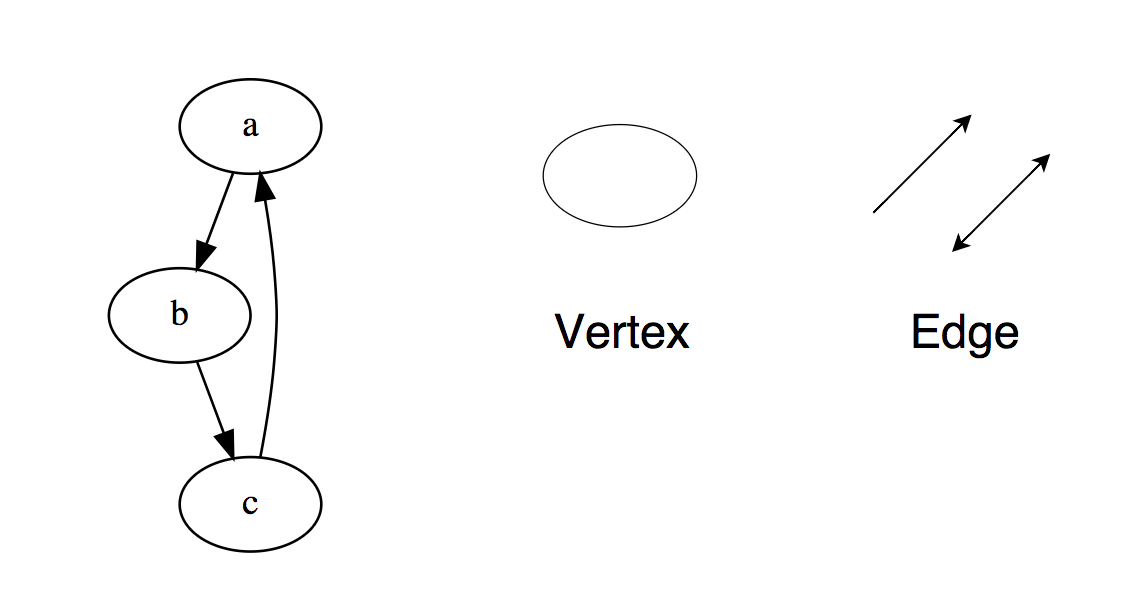 图形类型:在编程语言中,图形以两种形式表示:以下是连续的邻接表(无向图)的示例。
图形类型:在编程语言中,图形以两种形式表示:以下是连续的邻接表(无向图)的示例。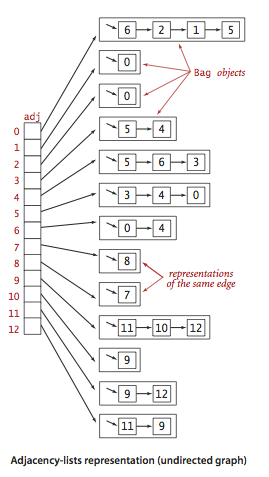 沿图移动算法的已知示例:对于独立研究:1.广度和深度的实现首次搜索2.检查图是否为树。3.计算图中的边数。4.查找峰之间的最短路径。树树是由顶点(节点)和连接它们的边组成的分层数据结构。树看起来像图,但是将树与图区分开的关键是树中不能存在循环。树是一幅残缺的图。树广泛用于人工智能和复杂算法中,为问题解决算法提供了有效的存储机制。这是一棵简单树的图像,以及树数据结构中使用的基本术语:
沿图移动算法的已知示例:对于独立研究:1.广度和深度的实现首次搜索2.检查图是否为树。3.计算图中的边数。4.查找峰之间的最短路径。树树是由顶点(节点)和连接它们的边组成的分层数据结构。树看起来像图,但是将树与图区分开的关键是树中不能存在循环。树是一幅残缺的图。树广泛用于人工智能和复杂算法中,为问题解决算法提供了有效的存储机制。这是一棵简单树的图像,以及树数据结构中使用的基本术语: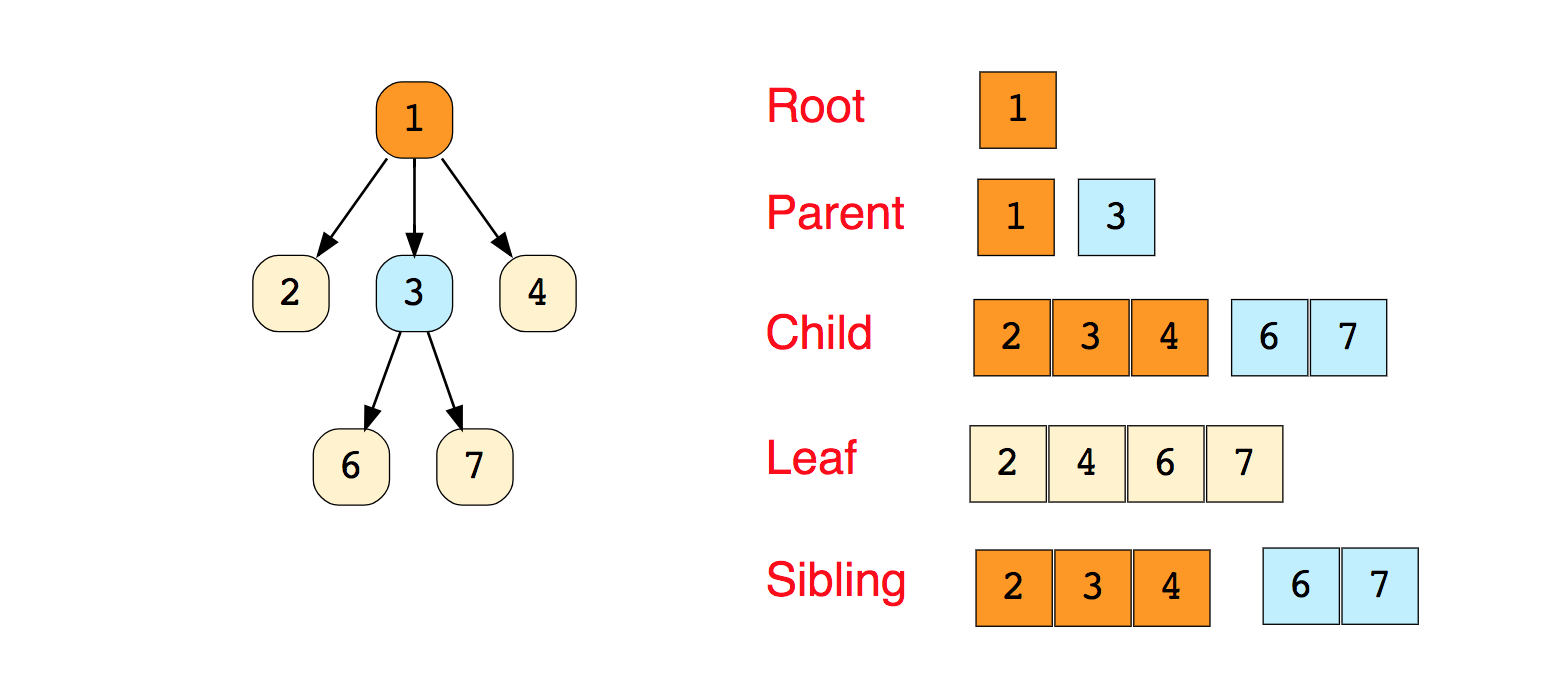 有树类型:
有树类型:- N-
- (Balanced Tree)
- (Binary Tree)
- (Binary Search Tree)
- AVL
- - (Red Black Tree)
- 2–3
综上所述,二叉树和二叉搜索树是最常用的树。对于独立研究:1.找到二叉树的高度。2.在二进制搜索树中找到第k个最大值。3.在距根“ k”的距离处找到节点。4.在二叉树中找到给定节点的祖先。实际示例:1. Facebook:当两个顶点之间有边时,每个用户都是一个顶点,两个人是朋友。推荐给朋友的建议也是基于图论计算的。2. Google Maps:不同的位置由峰表示,道路由边表示,图论用于查找两个峰之间的最短路径。3.交通网络:山峰是道路与肋骨的交汇处-这些是交汇处之间的路段。4.表示分子结构,其中顶点是分子,而边缘是分子之间的键。5. 图形中的离散信令过程。(和有一个很好的文章在这里也和这一个在同一时间)6.经验观察表明,大多数基因受少数其他基因(通常少于十个)的调控。因此,可以将遗传网络视为稀疏图,即其中一个节点连接到其他几个节点的图。如果有向(无环)图或无向图被概率饱和,则结果分别是概率导向的图形模型和概率无向图形模型。7. Mayer集群波动性函数展开的理论热力学中的气体(Z)需要计算两个,三个,四个条件,依此类推。有一种系统的方法可以与图表组合执行此操作,这有助于找出图表之间的连接方式。当您想要总结这些图的子集时,了解图论会很有用。8.贴图着色:著名的四色定理指出,您始终可以正确地对贴图区域进行着色,这样就不会使用不超过四种不同的颜色为两个相邻区域分配相同的颜色。在此模型中,带有颜色的区域是节点,而相邻区域是图的边缘。9.拥有三座小屋的任务是众所周知的数学难题。它可以表述为:飞机(或球体)上的三个小屋,每个小屋必须与天然气,水和电力公司连接。使用平面图可以解决该问题。10.搜索图的中心:对于每个顶点,找到到最远顶点的最短路径的长度。图的中心是该值最小的顶点。这对于定居点的建筑规划很重要,在定居点中应将医院,消防部门或警察局设置在最远的地方。对于像我这样的C#爱好者,这里有C#图形代码示例的链接。对于最高级的库,可在此处使用 C ++实现图形。对于AI和天网的爱好者,请在这里here脚。序列(Trie)序列,也称为带前缀的树(Prefix Trees),是一种树状数据结构,足以解决与字符串相关的问题。它们提供快速搜索,主要用于在字典中搜索单词,在搜索引擎中搜索自动句子,甚至用于IP路由。这是“ top”,“ thus”和“ their”这三个词如何按优先级存储的说明: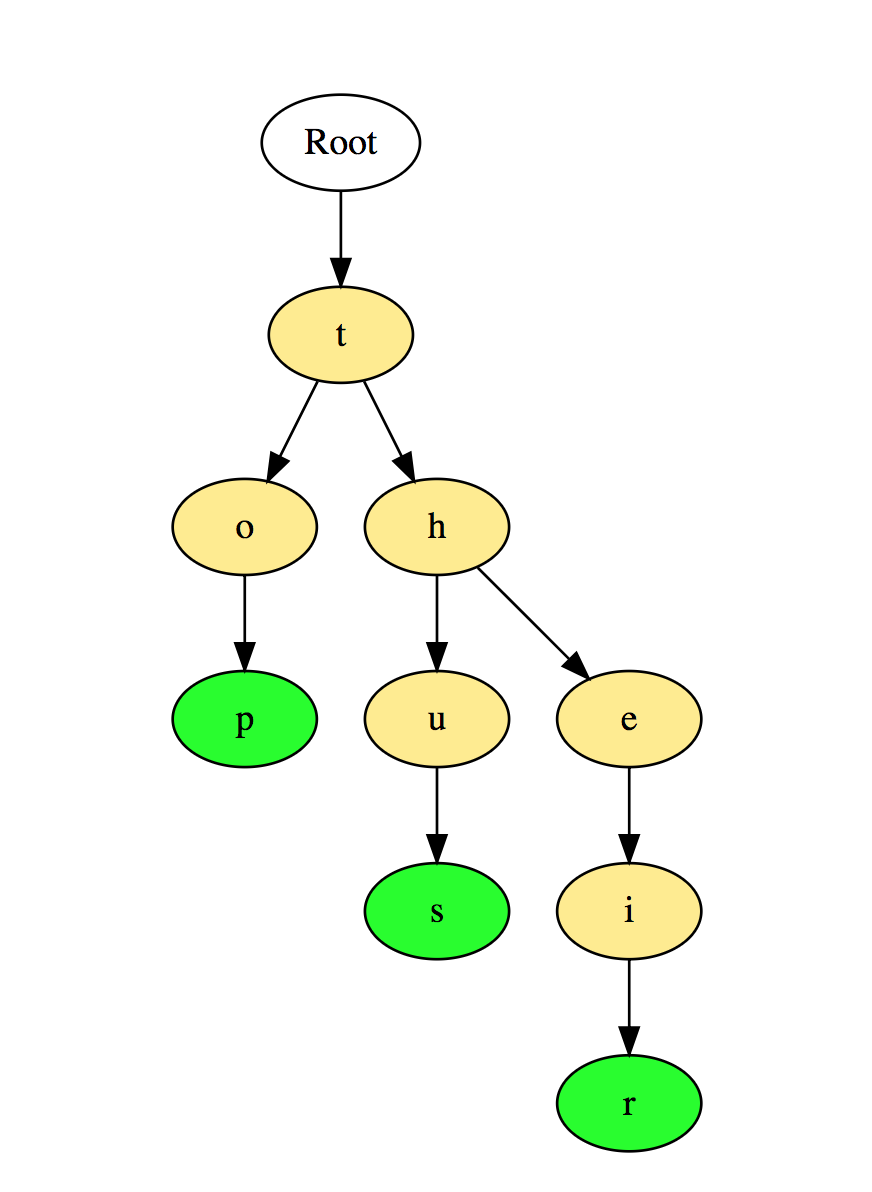 单词从上到下存储,其中绿色节点“ p”,“ s”和“ r”指向“ top”,“因此,分别是“和”。对于独立学习:1.计算优先级中的单词总数。2.打印存储在优先级中的所有单词。3.使用优先级对数组元素进行排序。4.使用队列从字典中生成单词。5.创建T9词典。实际的使用示例:1.输入单词时从字典中选择或完成。2.在电话或电话词典中搜索联系人。哈希表散列是用于唯一标识对象并通过一些预先计算的唯一索引(称为“键”)存储每个对象的过程。因此,对象以键值对的形式存储,此类元素的集合称为字典。可以使用此键找到每个对象。有不同的基于哈希的数据结构,但是哈希表是最常用的数据结构。当需要使用键访问元素时,可以使用哈希表,并且可以确定键的有用值。哈希表通常使用数组来实现。哈希数据结构的性能取决于以下三个因素:这是散列如何显示在数组中的说明。使用哈希函数计算该数组的索引。
单词从上到下存储,其中绿色节点“ p”,“ s”和“ r”指向“ top”,“因此,分别是“和”。对于独立学习:1.计算优先级中的单词总数。2.打印存储在优先级中的所有单词。3.使用优先级对数组元素进行排序。4.使用队列从字典中生成单词。5.创建T9词典。实际的使用示例:1.输入单词时从字典中选择或完成。2.在电话或电话词典中搜索联系人。哈希表散列是用于唯一标识对象并通过一些预先计算的唯一索引(称为“键”)存储每个对象的过程。因此,对象以键值对的形式存储,此类元素的集合称为字典。可以使用此键找到每个对象。有不同的基于哈希的数据结构,但是哈希表是最常用的数据结构。当需要使用键访问元素时,可以使用哈希表,并且可以确定键的有用值。哈希表通常使用数组来实现。哈希数据结构的性能取决于以下三个因素:这是散列如何显示在数组中的说明。使用哈希函数计算该数组的索引。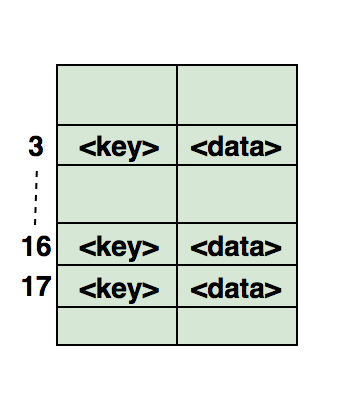 对于独立研究:1.在阵列中找到对称对。2.遵循完整的行驶路径。3.查找该数组是否是另一个数组的子集。4.检查给定的数组是否不相交。以下是.Net中的哈希表使用示例代码
对于独立研究:1.在阵列中找到对称对。2.遵循完整的行驶路径。3.查找该数组是否是另一个数组的子集。4.检查给定的数组是否不相交。以下是.Net中的哈希表使用示例代码static void Main(string[] args)
{
Hashtable ht = new Hashtable
{
{ "001", "Zara Ali" },
{ "002", "Abida Rehman" },
{ "003", "Joe Holzner" },
{ "004", "Mausam Benazir Nur" },
{ "005", "M. Amlan" },
{ "006", "M. Arif" },
{ "007", "Ritesh Saikia" }
};
if (ht.ContainsValue("Nuha Ali"))
{
Console.WriteLine(" !");
}
else
{
ht.Add("008", "Nuha Ali");
}
ICollection key = ht.Keys;
foreach (string k in key)
{
Console.WriteLine(k + ": " + ht[k]);
}
Console.ReadKey();
}
实际示例:1.游戏“生活”。在其中,哈希是每个活细胞的一组坐标。2. Google搜索引擎的原始版本可以将所有现有单词映射到出现它们的一组URL中。在这种情况下,哈希表使用了两次:第一次将单词映射到URL集,第二次保存每个URL集。3.在实现多路树结构/算法时,哈希表可用于快速访问内部节点的任何子元素。4.编写用于下棋的程序时,跟踪先前评估过的位置非常重要,这样您可以在需要时再次回来。5.任何编程语言都需要将变量名映射到其在内存中的地址。实际上,在像Javascript和Perl这样的脚本语言中,字段可以动态地添加到对象中,这意味着对象本身就像哈希映射一样。