几个月前,我的个人资料中发布了有关在JVM上加载类的详细信息。演讲之后,我的同事们提出了一个很好的问题:Spring使用什么机制来解析配置,以及如何从上下文中加载类?
 在经过数小时的Spring源代码调试之后,我的同事实验性地得出了非常简单和可以理解的事实。
在经过数小时的Spring源代码调试之后,我的同事实验性地得出了非常简单和可以理解的事实。一点理论
立即确定ApplicationContext是提供应用程序配置信息的Spring应用程序中的主要接口。在直接进行演示之前,
我们将看一下创建ApplicationContext所涉及的步骤: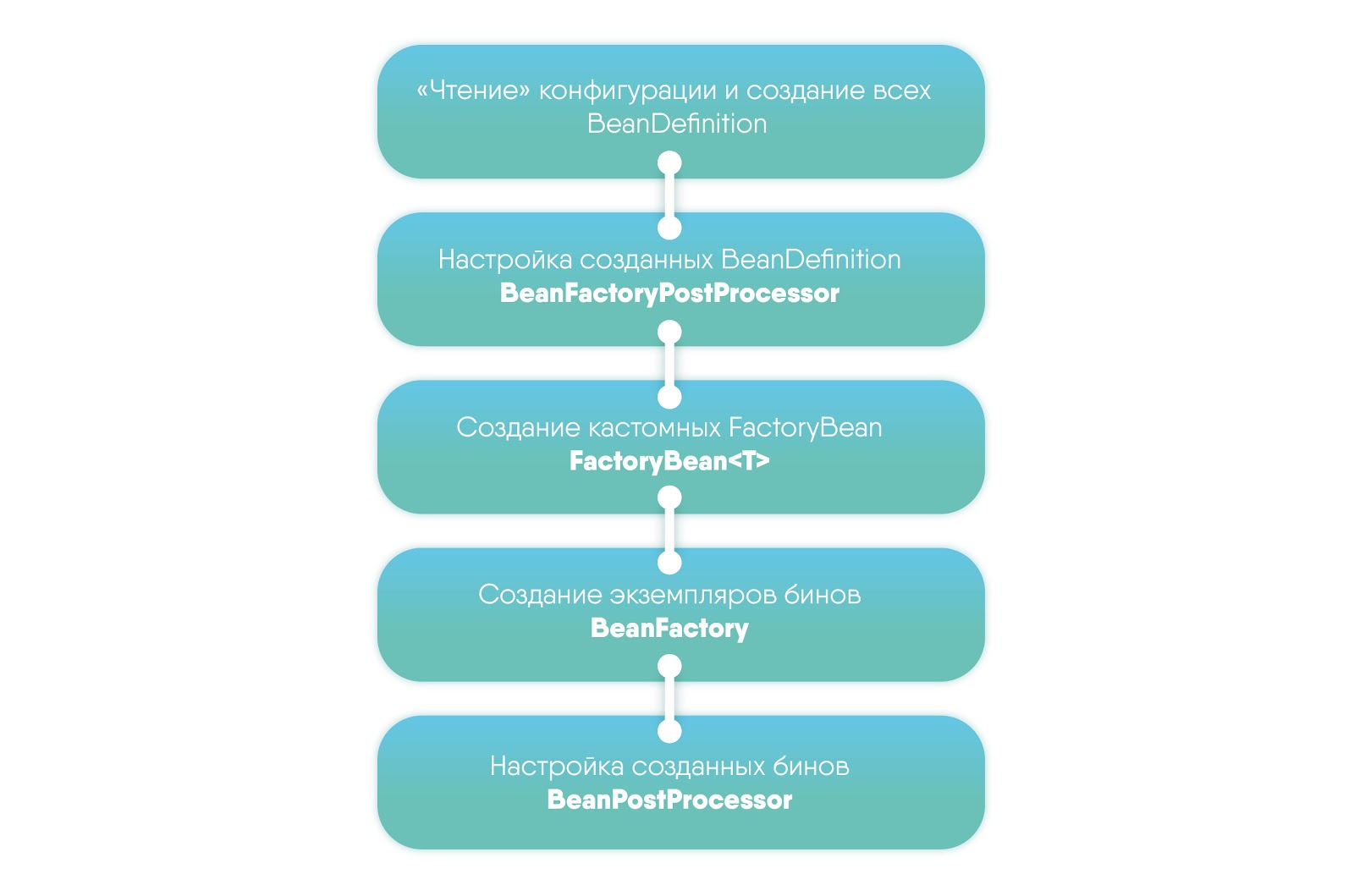 在本文中,我们将分析第一步,因为我们对读取配置和创建BeanDefinition感兴趣。BeanDefinition是一个接口,用于描述bean,其属性,构造函数参数和其他元信息。关于bean本身的配置,Spring有4种配置方法:
在本文中,我们将分析第一步,因为我们对读取配置和创建BeanDefinition感兴趣。BeanDefinition是一个接口,用于描述bean,其属性,构造函数参数和其他元信息。关于bean本身的配置,Spring有4种配置方法:- Xml配置 -ClassPathXmlApplicationContext(“ context.xml”);
- Groovy配置 -GenericGroovyApplicationContext(“ context.groovy”);
- 通过注释进行配置,该注释指示要扫描的软件包 -AnnotationConfigApplicationContext(“ package.name”);
- JavaConfig-通过注释进行配置,该注释指示用@Configuration标记的类(或类数组)-AnnotationConfigApplicationContext(JavaConfig.class)。
XML配置
我们以一个简单的项目为基础:public class SpringContextTest{
private static String classFilter = "film.";
public static void main(String[] args){
printLoadedClasses(classFilter);
在这里,您应该解释一些方法和使用的方法:- printLoadedClasses(字符串...过滤器) -该方法将作为参数传递的包中的加载器和加载的JVM类的名称打印到控制台。此外,还有关于所有已加载类的数量的信息。
- doSomething(对象o)是一种完成原始工作的方法,但不允许在编译期间的优化过程中排除提到的类。
我们连接到Spring项目(在下文中,Spring 4充当测试主题):11 public class SpringContextTest{
12 private static String calssFilter = "film.";
13
14 public static void main(String[] args){
15
16 printLoadedClasses(classFilter);
17
第25行是通过Xml配置声明和初始化ApplicationContext 。配置xml文件如下:<beans xmlns = "http://www.spingframework.org/schema/beans" xmlns:xsi = "http..."
<bean id = "villain" class = "film.Villain" lazy-init= "true">
<property name = "name" value = "Vasily"/>
</bean>
</beans>
在配置Bean时,我们指定一个确实存在的类。请注意指定的属性lazy-init =“ true”:在这种情况下,仅在从上下文中请求bin后才创建bin。我们看一下Spring在引发上下文时如何使用配置文件中声明的类来清除这种情况:public class SpringContextTest {
private static String classFilter = "film.";
public static void main(String[] args) {
printLoadedClasses(classFilter);
让我们检查Xml配置的详细信息:-读取配置文件的类是XmlBeanDefinitionReader,它实现了BeanDefinitionReader接口;- 输入处的XmlBeanDefinitionReader接收InputStream并通过DefaultDocumentLoader加载Document:Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
-之后,将处理此文档的每个元素,如果它是bin,则将基于填充的数据(id,名称,类,别名,初始化方法,destroy方法等)创建BeanDefinition:} else if (delegate.nodeNameEquals(ele, "bean")) {
this.processBeanDefinition(ele, delegate);
-每个BeanDefinition都放置在一个Map中,该Map存储在DefaultListableBeanFactory类中:this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
在代码中,Map如下所示:
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<String, BeanDefinition>(64);
现在,在同一配置文件中,用film.BadVillain类添加另一个bean声明:<beans xmlns = "http://www.spingframework.org/schema/beans" xmlns:xsi = "http..."
<bean id = "goodVillain" class = "film.Villain" lazy-init= "true">
<property name = "name" value = "Good Vasily"/>
</bean>
<bean id = "badVillain" class = "film.BadVillain" lazy-init= "true">
<property name = "name" value = "Bad Vasily"/>
</bean>
我们将看到如果您打印已创建的BeanDefenitionNames和已加载的类的列表,会发生什么情况:ApplicationContext context = new ClassPathXmlApplicationContext(
configLocation: "applicationContext.xml");
System.out.println(Arrays.asList(context.getBeanDefinitionNames()));
printLoadedClasses(calssFilter);
尽管配置文件中指定的film.BadVillain类不存在,但Spring可以正常工作:ApplicationContext context = new ClassPathXmlApplicationContext(
configLocation: "applicationContext.xml");
System.out.println(Arrays.asList(context.getBeanDefinitionNames()));
printLoadedClasses(calssFilter);
所述BeanDefenitionNames列表包含2个元素;也就是说,在我们的文件中配置的那两个BeanDefinition已创建。两个垃圾箱的配置基本相同。但是,在加载现有类的同时,没有出现问题。从中我们可以得出结论,也有人尝试加载不存在的类,但是失败的尝试并没有破坏任何东西。让我们尝试通过它们的名称获取bean本身:ApplicationContext context = new ClassPathXmlApplicationContext(
configLocation: "applicationContext.xml");
System.out.println(Arrays.asList(context.getBeanDefinitionNames()));
System.out.println(context.getBean( name: "goodVillain"));
System.out.println(context.getBean( name: "badVillain"));
我们得到以下信息: 如果在第一种情况下收到有效的bean,则在第二种情况下到达异常。注意堆栈跟踪:延迟加载类。所有类装入器都经过爬网,以尝试在先前装入的装入器中找到它们正在寻找的类。在找不到所需的类之后,通过调用Utils.forName方法,尝试按名称查找不存在的类,这导致自然错误。引发上下文时,仅加载一个类,而尝试加载不存在的文件并不会导致错误。为什么会发生?那是因为我们注册了lazy-init:true并禁止Spring创建bean的实例,在该实例中生成先前接收到的异常。如果从配置中删除此属性或更改其值lazy-init:false,则上述错误也将崩溃,但不会忽略该应用程序。在我们的例子中,上下文已初始化,但是我们无法创建bean的实例,因为 找不到指定的类。
如果在第一种情况下收到有效的bean,则在第二种情况下到达异常。注意堆栈跟踪:延迟加载类。所有类装入器都经过爬网,以尝试在先前装入的装入器中找到它们正在寻找的类。在找不到所需的类之后,通过调用Utils.forName方法,尝试按名称查找不存在的类,这导致自然错误。引发上下文时,仅加载一个类,而尝试加载不存在的文件并不会导致错误。为什么会发生?那是因为我们注册了lazy-init:true并禁止Spring创建bean的实例,在该实例中生成先前接收到的异常。如果从配置中删除此属性或更改其值lazy-init:false,则上述错误也将崩溃,但不会忽略该应用程序。在我们的例子中,上下文已初始化,但是我们无法创建bean的实例,因为 找不到指定的类。Groovy配置
使用Groovy文件配置上下文时,您需要生成GenericGroovyApplicationContext,它接收带有上下文配置作为输入的字符串。在这种情况下,GroovyBeanDefinitionReader类用于读取context 。此配置与Xml基本相同,仅对Groovy文件有效。另外,GroovyApplicationContext与Xml文件配合使用也很好。一个简单的Groovy配置文件的示例:beans {
goodOperator(film.Operator){bean - >
bean.lazyInit = 'true' >
name = 'Good Oleg'
}
badOperator(film.BadOperator){bean - >
bean.lazyInit = 'true' >
name = 'Bad Oleg' / >
}
}
我们尝试做与Xml相同的操作: 错误立即崩溃:Groovy与Xml一样,创建BeanDefenitions,但是在这种情况下,后处理器立即给出错误。
错误立即崩溃:Groovy与Xml一样,创建BeanDefenitions,但是在这种情况下,后处理器立即给出错误。通过注释进行配置,该注释指示要扫描的软件包或JavaConfig
此配置与前两个不同。通过注释进行配置使用2个选项:JavaConfig和基于类的注释。此处使用相同的上下文:AnnotationConfigApplicationContext(“包” /JavaConfig.class)。它的工作取决于传递给构造函数的内容。在AnnotationConfigApplicationContext的上下文中,有2个私有字段:- 私有的最终AnnotatedBeanDefinitionReader阅读器(与JavaConfig一起使用);
- 私有的最终ClassPathBeanDefinitionScanner扫描(扫描数据包)。
AnnotatedBeanDefinitionReader
的独特之处在于它可以在多个阶段中工作:- 注册所有@Configuration文件以进行进一步解析;
- 注册一个特殊的BeanFactoryPostProcesso r,即BeanDefinitionRegistryPostProcessor,它使用ConfigurationClassParser类解析JavaConfig并创建一个BeanDefinition。
考虑一个简单的例子:@Configuration
public class JavaConfig {
@Bean
@Lazy
public MainCharacter mainCharacter(){
MainCharacter mainCharacter = new MainCharacter();
mainCharacter.name = "Patric";
return mainCharacter;
}
}
public static void main(String[] args) {
ApplicationContext javaConfigContext =
new AnnotationConfigApplicationContext(JavaConfig.class);
for (String str : javaConfigContext.getBeanDefinitionNames()){
System.out.println(str);
}
printLoadedClasses(classFilter);
我们使用最简单的bin创建一个配置文件。我们看一下将要加载的内容: 如果在Xml和Groovy的情况下,加载了与声明的数量一样多的BeanDefinition,那么在这种情况下,在引发上下文的过程中,将同时加载声明的BeanDefinition和其他BeanDefinition。在通过JavaConfig实现的情况下,所有类都会立即加载,包括JavaConfig本身的类,因为它本身是bean。另一个要点:在Xml和Groovy配置的情况下,上传了343个文件,这里出现了631个其他文件,更加“繁重”。ClassPathBeanDefinitionScanner的工作步骤:
如果在Xml和Groovy的情况下,加载了与声明的数量一样多的BeanDefinition,那么在这种情况下,在引发上下文的过程中,将同时加载声明的BeanDefinition和其他BeanDefinition。在通过JavaConfig实现的情况下,所有类都会立即加载,包括JavaConfig本身的类,因为它本身是bean。另一个要点:在Xml和Groovy配置的情况下,上传了343个文件,这里出现了631个其他文件,更加“繁重”。ClassPathBeanDefinitionScanner的工作步骤:- 指定的软件包确定要扫描的文件列表。所有文件都属于目录;
- , InputStream org.springframework.asm.ClassReader.class;
- 3- , org.springframework.core.type.filter.AnnotationTypeFilter. Spring , Component , Component;
- , BeanDefinition.
Xml和Groovy的使用注释的所有“魔术”都恰好位于springframework.asm包的ClassReader.class类中。该阅读器的特殊性在于它可以使用字节码。也就是说,阅读器从字节码中获取一个InputStream,对其进行扫描并在其中查找注释。
考虑一个简单的例子的扫描仪。
创建您自己的注释以搜索相应的类:import org.springframework.stereotype.Component
import java.lang.annotation.*;
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface MyBeanLoader{
String value() default "";
我们创建2个类:一个带有标准Component注释,第二个带有自定义注释:@Component
public class MainCharacter {
public static int num = 1;
@Value("Silence")
public String name;
public MainCharacter() { }
MyBeanLoader("makerFilm")
@Lazy
public class FilmMaker {
public static int staticInt = 1;
@Value("Silence")
public String filmName;
public FilmMaker(){}
结果,我们为这些类和成功加载的类获取了生成的BeanDefinition。ApplicationContext annotationConfigContext =
new AnnotationConfigApplicationContext(...basePackages: "film");
for (String str : annotationConfigContext.getBeanDefinitionNames()){
System.out.println(str);
}
printLoadedClasses(classFilter);

结论
综上所述,所提出的问题可以回答如下:- Spring ?
, . BeanDefinition, : , BeanDefinition’ . BeanDefinition, .. - Spring ?
Java: , , , .
PS我希望在这篇文章中我能够“揭开秘密的面纱”,并详细说明如何在第一阶段形成弹性背景。事实证明,并非所有事物都如此“恐怖”。但这只是大型框架的一小部分,这意味着未来还有很多新的有趣的事物。