当Facebook“说谎”时,人们认为这是由于黑客或DDoS攻击所致,但事实并非如此。过去几年中的所有“下降”都是内部变化或故障造成的。为了教会新员工不要以身作则,所有重大事件都被命名为“ Call the Cops”或“ CAPSLOCK”。第一个被命名是因为当有一天社交网络崩溃时,用户打电话给洛杉矶警察并要求修复它,而在Twitter上绝望的警长要求不要为此烦恼。在高速缓存计算机上发生第二次事件期间,网络接口出现故障,但没有上升,并且所有计算机均手动重启。埃琳娜·洛巴诺娃(Elina Lobanova)在过去的四年中,Web Foundation团队一直在Facebook工作。团队成员被称为生产工程师,负责监视整个后端的可靠性和性能,在启动Facebook时将其推出,编写监视和自动化程序,以使自己和他人的生活更加轻松。 在基于Elina关于HighLoad ++ 2019的报告的文章中,我们将展示生产工程师如何监视Facebook后端,他们使用哪些工具,导致严重崩溃以及如何处理它们。我叫Elina,大约5年前,我在Facebook上被称为普通开发人员,这是我第一次遇到真正高负载的系统-这在学院中没有讲到。该公司没有雇用一个团队,而是一个办公室,所以我到达伦敦,选择了一个监视facebook.com工作的团队,并且是生产工程师。
在基于Elina关于HighLoad ++ 2019的报告的文章中,我们将展示生产工程师如何监视Facebook后端,他们使用哪些工具,导致严重崩溃以及如何处理它们。我叫Elina,大约5年前,我在Facebook上被称为普通开发人员,这是我第一次遇到真正高负载的系统-这在学院中没有讲到。该公司没有雇用一个团队,而是一个办公室,所以我到达伦敦,选择了一个监视facebook.com工作的团队,并且是生产工程师。生产工程师
首先,我将告诉您我们在做什么以及为什么我们被称为生产工程师,而不是像Google这样的SRE。2009年
许多公司仍使用的标准模型是“开发人员-测试人员-操作”。它们通常是分开的:它们位于不同的楼层,有时甚至位于不同的国家,并且彼此之间不沟通。在2009年,Facebook已经拥有SRE。在Google,SRE起步较早,他们知道如何实现DevOps,并将其写在《站点可靠性工程》一书中。 在2009年的Facebook上,没有类似的东西。我们被称为SRE,但是我们在世界其他地方与Ops进行了相同的工作:体力劳动,没有自动化,用手部署所有服务,以某种方式进行监视,对所有内容进行调用,一组shell脚本。
在2009年的Facebook上,没有类似的东西。我们被称为SRE,但是我们在世界其他地方与Ops进行了相同的工作:体力劳动,没有自动化,用手部署所有服务,以某种方式进行监视,对所有内容进行调用,一组shell脚本。2010年。SRO和AppOps
所有这些都没有扩展,因为当时的用户数量每年增长3倍,并且服务数量也相应增加。2010年,意志坚定的决定Ops分为两组。第一组是SRO,其中“ O”是“运营”,从事站点的开发,自动化和监视。第二组是AppOps,它们被集成到团队中,每个团队都提供大型服务。AppOps已经接近DevOps的想法。分居了一段时间救了大家。2012年。生产工程师
2012年,AppOps只是简单地重命名了生产工程师。除了名称,什么都没有改变,但是变得更加舒适。正如您所说的,游艇会航行,而我们不想像Ops一样航行。SRO仍然存在,Facebook不断发展,并且很难立即监控所有服务。一个待命的人甚至都不被允许上厕所:他要有人代替他,因为他一直在燃烧。2014.关闭SRO
当局一度将所有人转移到待命中。“每个人”也意味着开发人员:在这里编写您的代码,然后为该代码回答!生产工程师已经被整合到最重要的团队中寻求帮助,而其他人则运气不好。我们从大型团队开始,然后在几年内将Facebook上的所有人转移到了待命者。在开发人员中有一个很大的兴奋:有人退出,有人写了不好的帖子。但是一切都变得平静了,由于不再需要SRO,SRO于2014年关闭。所以我们活到了今天。公司中的“ SRE”一词是臭名昭著的,但我们看起来像Google上的SRE。有区别。- 我们总是建立在团队中。通常,我们没有SRE搜索,就像在Google中一样,它是针对每个搜索服务的。
- 我们不在产品中,而在产品自身管理的基础架构中。
- 我们正在与开发人员一起待命。
- 我们在系统和网络方面有更多的经验,因此我们专注于在服务正常运行时监视和熄灭服务。我们从一开始就预先修复了可能导致崩溃并影响新服务体系结构的错误,从而使它们在生产中可以顺畅地工作。
监控方式
这是最重要的。我们如何做到这一点?像每个人一样:没有黑魔法,在自己的家中。但是,魔鬼会像往常一样详细地告诉您有关它们的信息。在顶上
让我们从底部开始。每个人都知道Linux中的TOP,我们使用ATOP,其中“ A”是“高级”的-系统性能监视器。 ATOP的主要优点是它存储历史记录:您可以对其进行配置以将快照保存到磁盘。我们的ATOP每5秒钟在所有机器上运行一次。这是运行针对facebook.com的PHP后端的示例服务器。我们编写了用于执行PHP代码的虚拟机,称为HHVM(HipHop虚拟机)。根据导出的指标,我们发现几台计算机在一分钟内未处理几乎一个请求。让我们看看为什么在挂起前30秒钟打开ATOP。 可以看出,由于处理器问题,我们将其加载过多。内存也有问题,缓存中只剩下1.5 GB,5秒钟后只有800 MB。
可以看出,由于处理器问题,我们将其加载过多。内存也有问题,缓存中只剩下1.5 GB,5秒钟后只有800 MB。 再过5秒钟后,CPU释放,什么也不执行。ATOP说,看底线,我们写入磁盘,但是呢?原来我们正在写交换。
再过5秒钟后,CPU释放,什么也不执行。ATOP说,看底线,我们写入磁盘,但是呢?原来我们正在写交换。 谁在做这个?从内存0.5 GB中取出并进行交换的进程。取而代之的是两个可疑的Python进程,可以将其视为命令行。
谁在做这个?从内存0.5 GB中取出并进行交换的进程。取而代之的是两个可疑的Python进程,可以将其视为命令行。
ATOP很漂亮,我们不断使用它。
如果您没有它,我强烈建议您使用它。不用担心驱动器,ATOP每5秒每天只吃200-300 MB。Malloc HTTP
对于巴哈马和重大事件,我们起名字。与ATOP相关的一个有趣的错误称为Malloc HTTP。我们使用ATOP和strace首次推出了它。我们到处都使用Thrift作为RPC。在其解析器的早期版本中,有一个惊人的错误,其工作方式如下:到达一条消息,其中前4个字节是数据的大小,然后是数据本身,然后将第一个字节添加到下一条消息中。但是一旦有了其中一个程序而不是转到Thrift服务,我就转到HTTP,并收到响应“ HTTP Bad the Request” :HTTP/1.1 400。使用HTTP并使用malloc HTTP分配字节数之后。Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
没关系,我们已经过量使用了,让我们分配更多的内存!我们使用malloc进行分配,直到我们在此处进行写入和读取为止,它们不会给我们真正的内存。但是它不在那里!如果要分叉,则分叉将返回错误-内存不足。malloc("HTTP")
pid = fork(); // errno = ENOMEM
但是为什么有记忆呢?理解手册之后,我们发现一切都非常简单:当前的过量使用配置是一种神奇的启发式方法,并且内核本身可以决定何时出现和何时不出现:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
对于正常工作的进程,这是正常的,您可以选择最大为TB的malloc,但是对于新进程-否。我们的部分监控与以下事实有关:主流程派生了用于收集数据的小脚本。结果,我们的监视部分出现了故障,因为我们无法再进行分叉。FB303
FB303是我们的基本监控系统。它以1982年的标准低音合成器命名。 原理很简单,因此仍然有效:每个服务都实现Thrift getCounters接口。
原理很简单,因此仍然有效:每个服务都实现Thrift getCounters接口。Service FacebookService {
map<string, i64> getCounters()
}
实际上,他没有实现它,因为已经编写了库,所以一切都在代码increment或中完成set。incrementCounter(string& key);
setCounter(string& key, int64_t value);
结果,每个服务都会在其向Service Discovery注册的端口上导出计数器。下面是一个示例计算机的示例,该计算机生成新闻提要并输出约5.5千对(字符串,数字):内存,生产数据。 每台机器都运行一个二进制过程,该过程遍历所有服务,收集这些计数器并将它们存储在存储中。这就是存储GUI的外观。
每台机器都运行一个二进制过程,该过程遍历所有服务,收集这些计数器并将它们存储在存储中。这就是存储GUI的外观。 与Prometheus和Grafana非常相似,但事实并非如此。 GitHub上的第一个FB303条目是在2009年,而Prometheus则是在2012年。这是对Facebook所有“自己动手做”的解释:我们在开放源代码中没有任何正常现象时就这么做了。例如,搜索计数器的名称。
与Prometheus和Grafana非常相似,但事实并非如此。 GitHub上的第一个FB303条目是在2009年,而Prometheus则是在2012年。这是对Facebook所有“自己动手做”的解释:我们在开放源代码中没有任何正常现象时就这么做了。例如,搜索计数器的名称。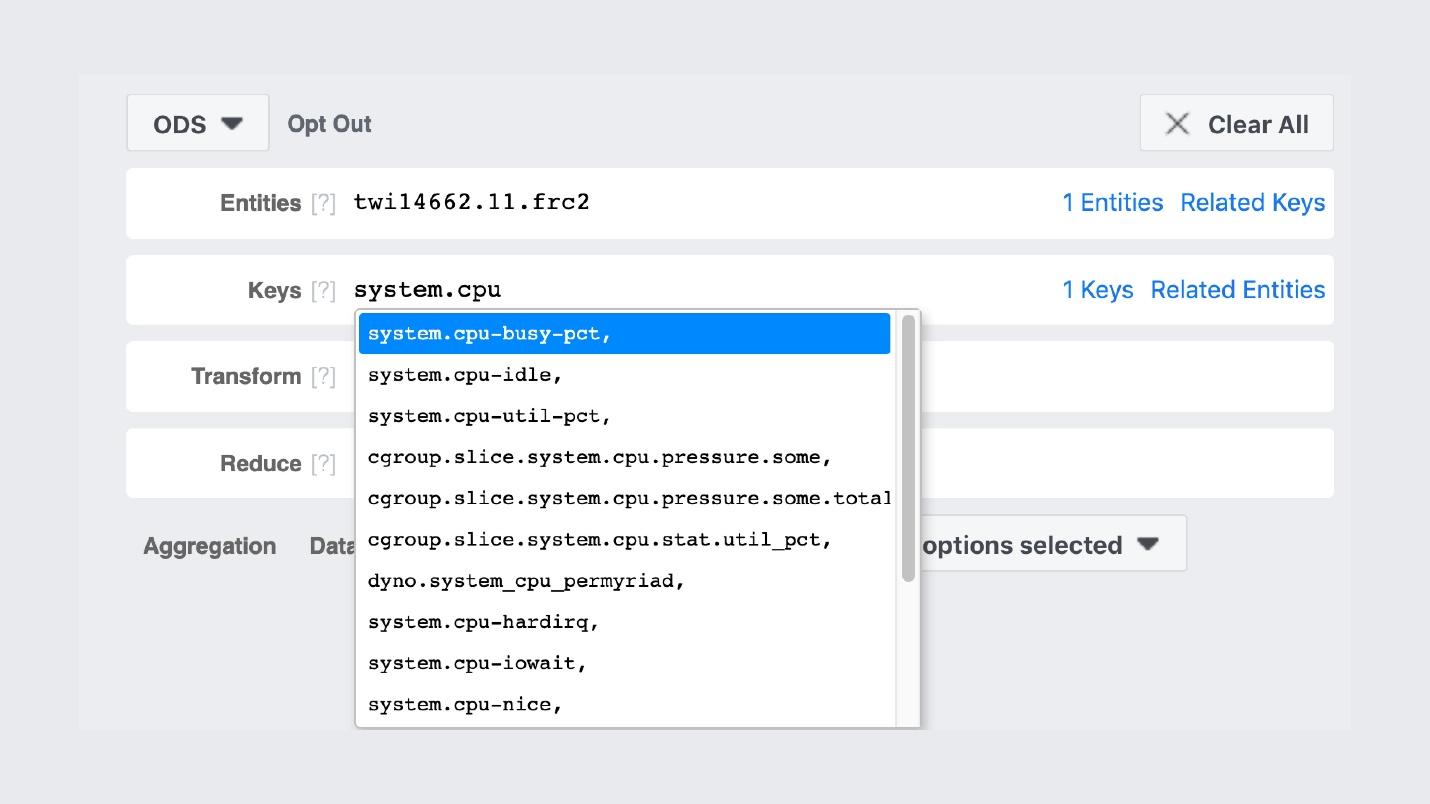 图本身看起来像这样。
图本身看起来像这样。 内部小组的照片,我们在其中张贴了精美的图形。我们的监视堆栈与Prometheus和Grafana之间的重要区别是,我们永远存储数据。我们的监控将对数据进行重新采样,两周后,我们每5分钟获得1分,一年后,每小时获得1分。因此,它们可以存储很多。自动不会在任何地方进行配置。但是,如果我们谈论监视Facebook的功能,那么我将用一个英文单词“ observability”来描述它。
内部小组的照片,我们在其中张贴了精美的图形。我们的监视堆栈与Prometheus和Grafana之间的重要区别是,我们永远存储数据。我们的监控将对数据进行重新采样,两周后,我们每5分钟获得1分,一年后,每小时获得1分。因此,它们可以存储很多。自动不会在任何地方进行配置。但是,如果我们谈论监视Facebook的功能,那么我将用一个英文单词“ observability”来描述它。可观察性
有一个“黑盒子”,有一个“白盒子”,还有一个透明的玻璃“盒子”。这意味着在编写代码时,我们会在日志中而不是选择性地编写所有可能的内容。采样在任何地方都进行了很好的调整,因此用于存储,计数器和其他所有内容的后端运行良好。同时,我们可以在现有柜台上建立仪表板。在研究这些仪表盘的情况下,这不是包含10个图形的终点,而是最初的图形,我们可以从中转到UI并找到所有可能的图形。水肺潜水
这是可观察性思想的高潮。这是我们的ELK堆栈。原理是相同的:我们使用JSON编写时没有特定的方案,然后我们以表格,数据时间序列或10多个可视化选项的形式请求。Scuba记录每秒数百GB的数量。由于不是Elasticsearch,因此所有内容都很快被请求,并且所有内容都存储在功能强大的计算机上。是的,花了很多钱,但是那真是太棒了!例如,在Scuba UI下,其中打开了最受欢迎的表之一,所有Thrift服务的所有客户端都在其中写入日志。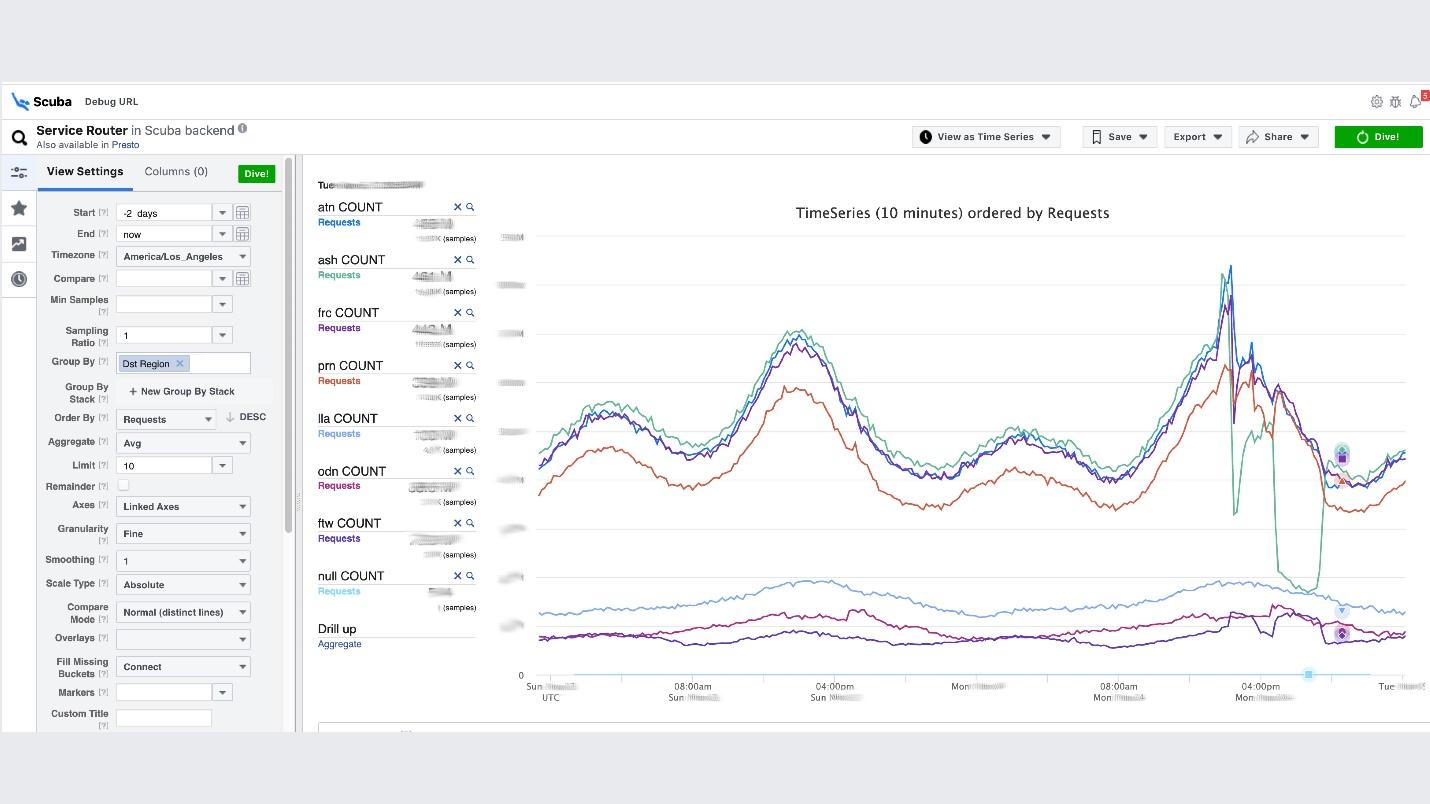 该图表明,最后,服务出现了问题。要找出延迟,请转到计数器列表,选择延迟,汇总,然后单击“潜水”。
该图表明,最后,服务出现了问题。要找出延迟,请转到计数器列表,选择延迟,汇总,然后单击“潜水”。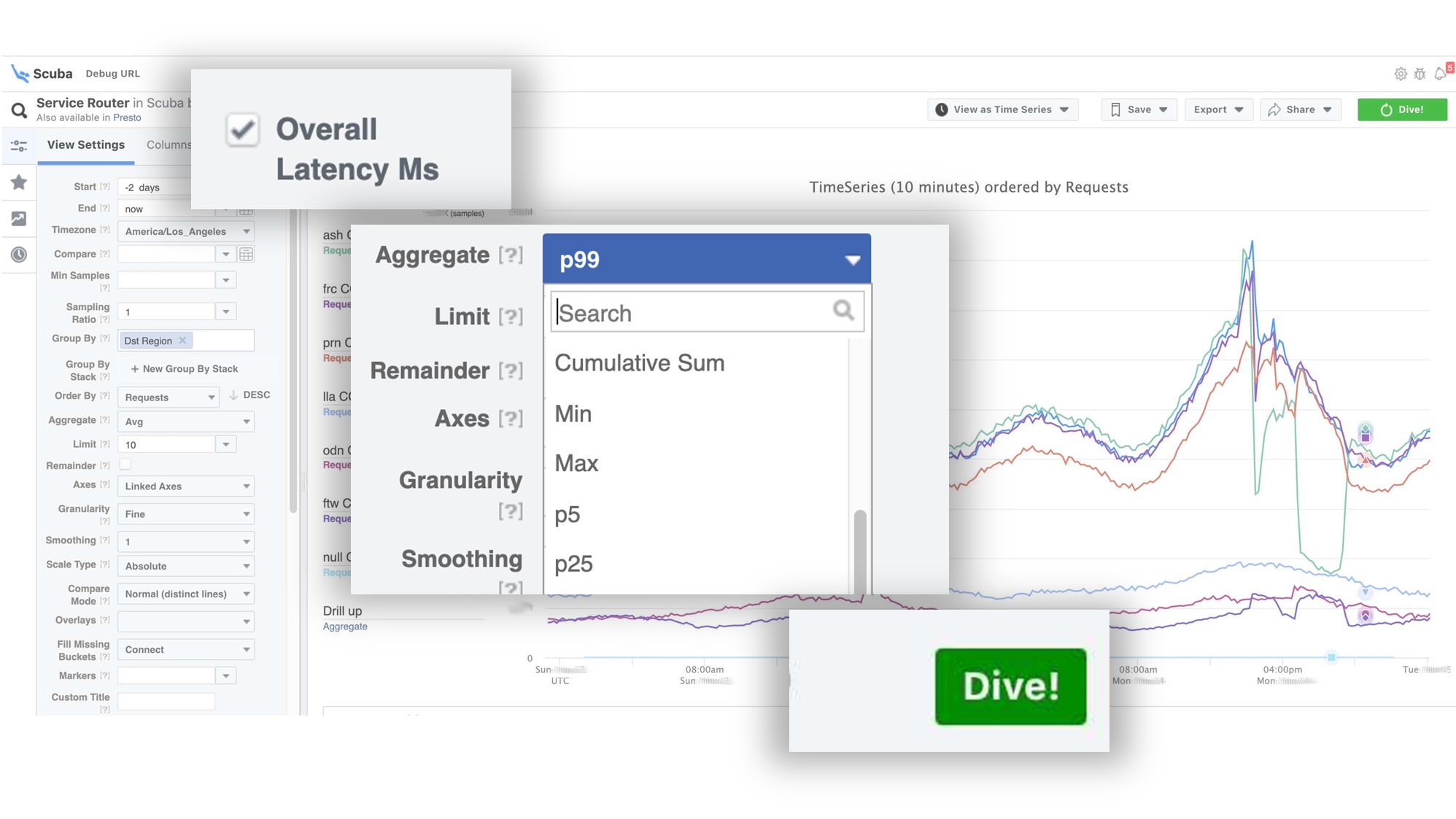 答案在2秒内到来。
答案在2秒内到来。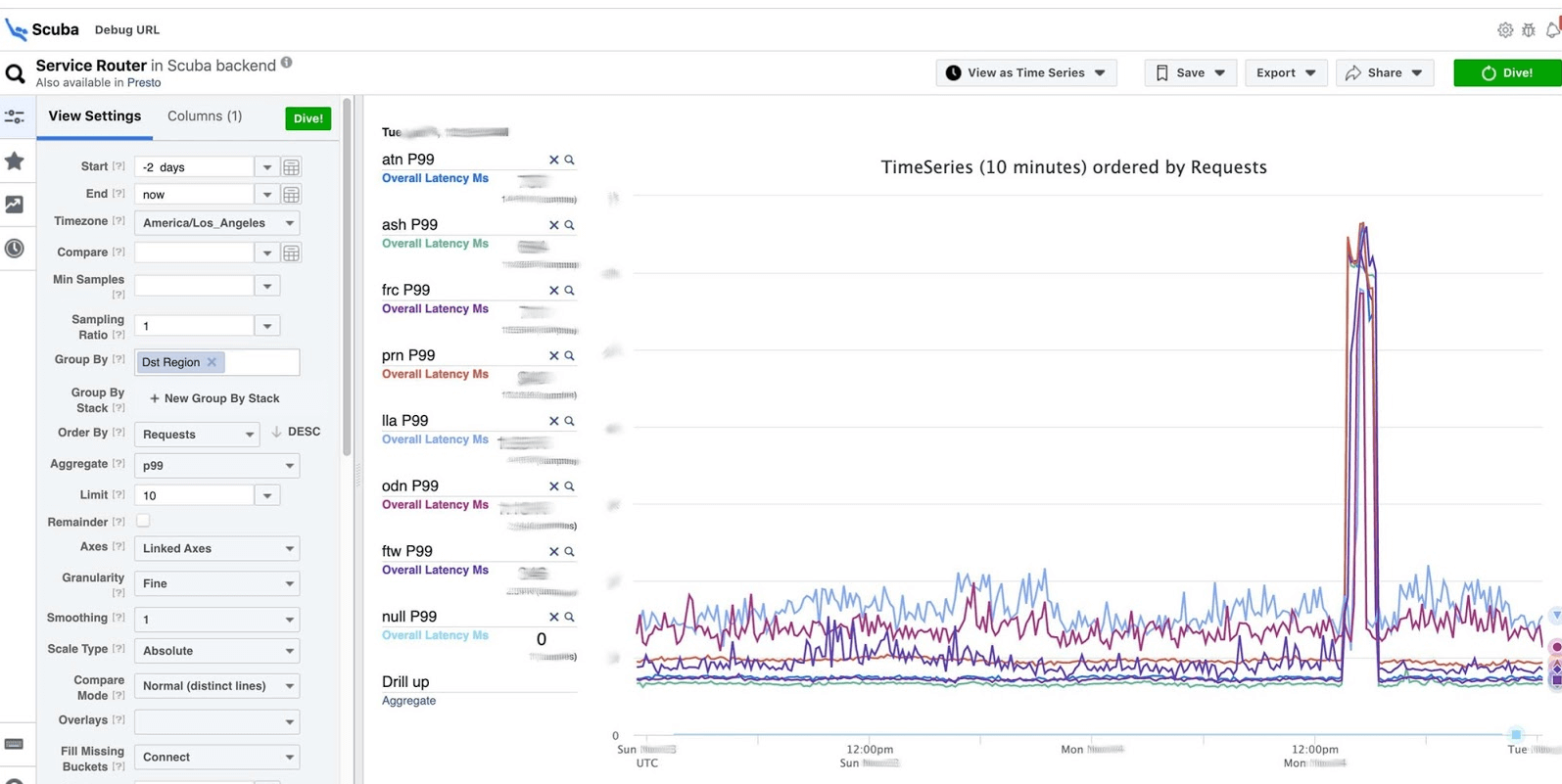 可以看出,在那一刻发生了一些事情,延迟大大增加了。要了解更多信息,可以按不同的参数分组。有数百个这样的表。
可以看出,在那一刻发生了一些事情,延迟大大增加了。要了解更多信息,可以按不同的参数分组。有数百个这样的表。- 该表显示二进制文件,软件包的版本以及在数百万台计算机上消耗的内存量。在每个主机上,每小时制作一次PS,然后将其发送到Scuba。
- 所有dmesg,所有内存转储都发送到其他表。我们每台机器每10分钟运行一次Perf,因此我们知道内核上具有哪些堆栈跟踪以及全局CPU可以加载什么。
PHP调试
Scuba还为我们的核心PHP调试工具提供了后端。成千上万的工程师编写PHP代码,并且您需要以某种方式保存全局存储库,以免发生不良情况。它是如何工作的? PHP还向每个日志写入堆栈跟踪。 Scuba(我们的Elasticsearch)根本无法容纳来自所有计算机的所有日志的堆栈跟踪。在将日志放入Scuba之前,我们将堆栈跟踪转换为哈希,按哈希采样并仅保存它们。堆栈跟踪本身将发送到Memcached。然后,在内部工具中,您可以足够快地从Memcached中提取特定的堆栈跟踪。 通过日志和堆栈跟踪的哈希分组进行可视化。我们使用模式匹配方法调试代码:打开Scuba,查看错误图的外观。
通过日志和堆栈跟踪的哈希分组进行可视化。我们使用模式匹配方法调试代码:打开Scuba,查看错误图的外观。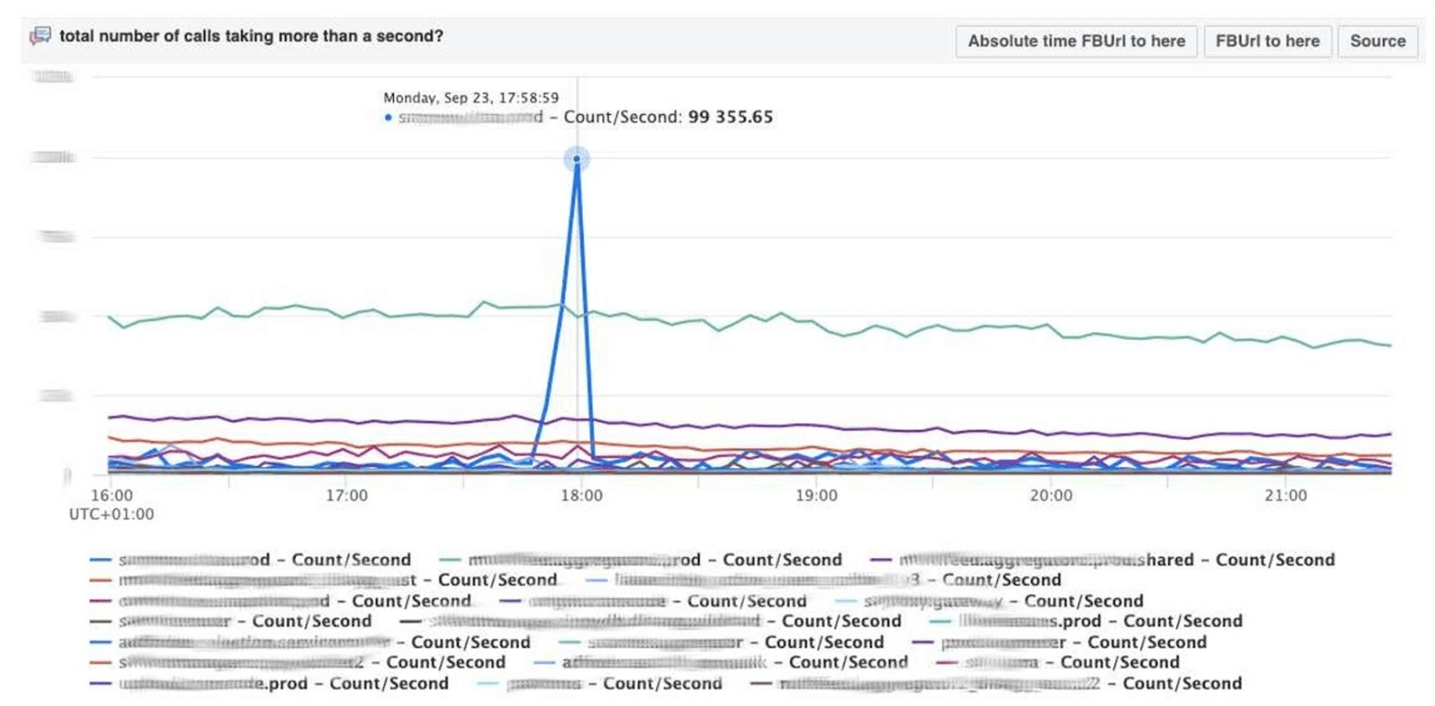 我们转到LogView,错误已按堆栈跟踪分组。
我们转到LogView,错误已按堆栈跟踪分组。 堆栈跟踪是从Memcached加载的,并且已经在上面找到了diff(在PHP存储库中提交),该跟踪大约在同一时间发布,然后回滚。任何人都可以回滚并与我们联系,不需要任何权限。
堆栈跟踪是从Memcached加载的,并且已经在上面找到了diff(在PHP存储库中提交),该跟踪大约在同一时间发布,然后回滚。任何人都可以回滚并与我们联系,不需要任何权限。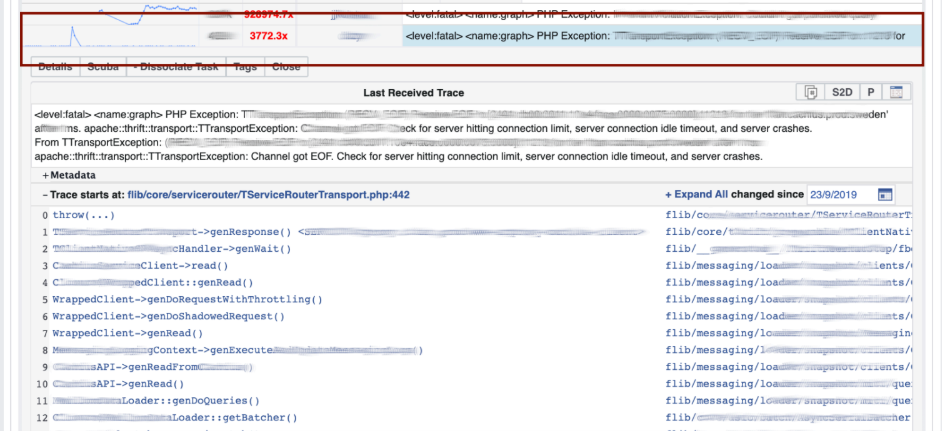
仪表板
我将以仪表板结束监视主题。我们很少-每三个指标中只有两个。仪表板本身很不寻常。我想更多地谈论他。以下是带有一组图形的标准仪表板。不幸的是,对他来说并不是那么简单。事实是,一个图形上的紫色线与另一条图形上的蓝线所对应的服务相同,而另一个图形可以在一天之内,另一个图形可以在一个月内。我们使用基于Cubism的仪表板-开源JS库。它是在Square上编写的,并在Apache许可下发布。它们具有对Graphite和Cube的内置支持。但是它很容易扩展,我们已经做到了。下方的资讯主页以1像素/分钟显示一天。每条线都是一个区域:邻近的数据中心。它们以每秒字节数显示Facebook后端写入的日志数。以下是美国团队的注释,以了解我们已经根据一天中发生的事情修复了什么。在这张图片中寻找相关性很容易。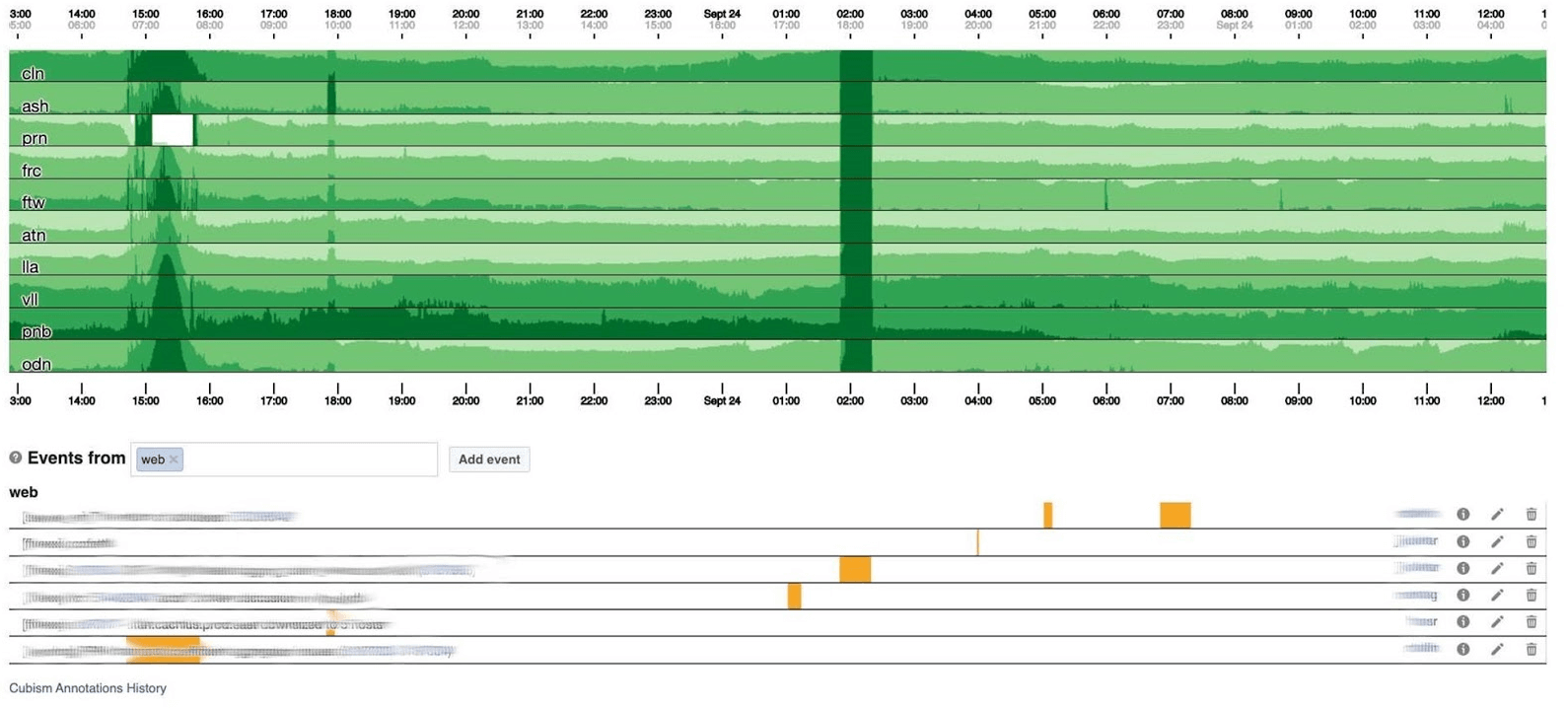 下面是错误的数量500。左侧的内容对于用户而言并不重要,显然他们不喜欢中间的深绿色条纹。
下面是错误的数量500。左侧的内容对于用户而言并不重要,显然他们不喜欢中间的深绿色条纹。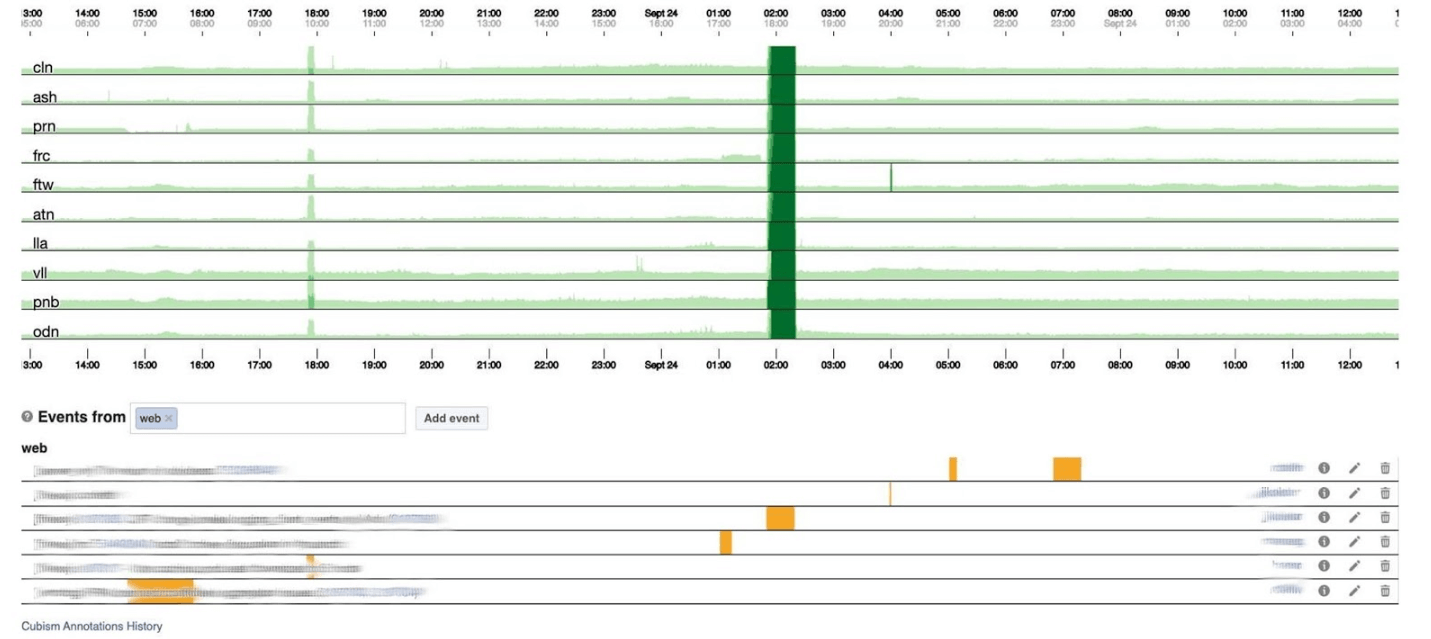 接下来是第99个百分位延迟。同时,如上图所示,可以看出延迟有所降低。要返回错误,无需花费大量时间。
接下来是第99个百分位延迟。同时,如上图所示,可以看出延迟有所降低。要返回错误,无需花费大量时间。
怎么运行的
在120像素高的图形上,所有内容都是可见的。但是其中许多不能放在一个仪表板上,因此我们将其压缩到30。 不幸的是,然后我们得到了某种蟒蛇bo。让我们回过头来看看立体主义如何处理它。他将图表分为四个部分:较高,较暗,然后崩溃。
不幸的是,然后我们得到了某种蟒蛇bo。让我们回过头来看看立体主义如何处理它。他将图表分为四个部分:较高,较暗,然后崩溃。 现在我们拥有与以前相同的时间表,但是所有内容都清晰可见:绿色越深,效果越差。现在更清楚了发生了什么。在左侧,您可以看到波浪的上升,而在中心,它是深绿色的,一切都非常糟糕。
现在我们拥有与以前相同的时间表,但是所有内容都清晰可见:绿色越深,效果越差。现在更清楚了发生了什么。在左侧,您可以看到波浪的上升,而在中心,它是深绿色的,一切都非常糟糕。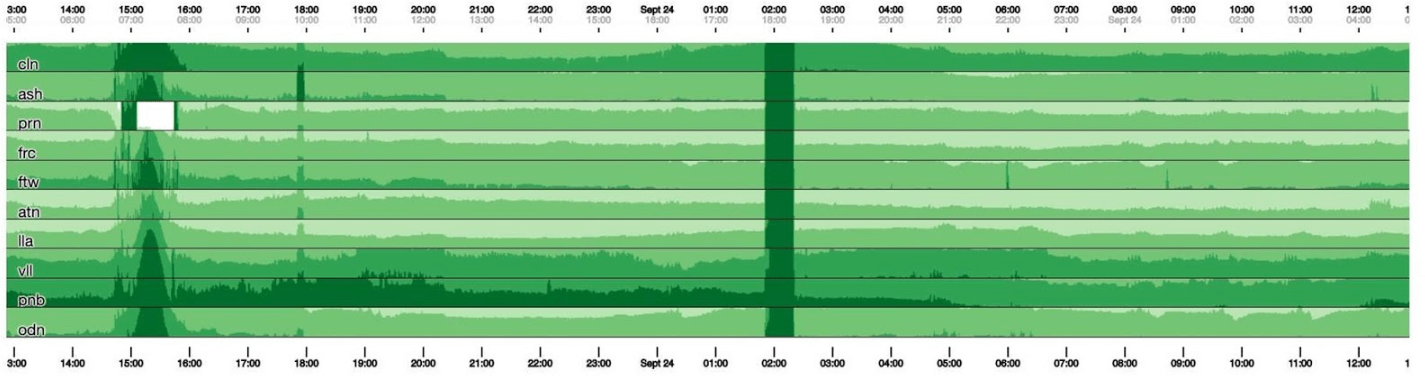 立体主义仅仅是开始。可视化需要它,以便了解现在是否一切都不好。对于每个表,已经有带有详细图形的仪表板。
立体主义仅仅是开始。可视化需要它,以便了解现在是否一切都不好。对于每个表,已经有带有详细图形的仪表板。 监视本身有助于了解系统状态,并在发生故障时做出响应。在Facebook上,每位待命员工都必须能够维修所有东西。如果它燃烧得很亮,那么一切都会打开,尤其是具有系统管理员经验的生产工程师,因为他们知道如何快速解决问题。
监视本身有助于了解系统状态,并在发生故障时做出响应。在Facebook上,每位待命员工都必须能够维修所有东西。如果它燃烧得很亮,那么一切都会打开,尤其是具有系统管理员经验的生产工程师,因为他们知道如何快速解决问题。当Facebook躺下时
有时会发生事件,而Facebook说谎。通常人们认为Facebook是因为DDoS或黑客攻击而撒谎,但是5年来从未发生过。原因一直是我们的工程师。它们不是故意的:系统非常复杂,可能在您不等待的地方发生故障。我们为所有重大事件起名字,以便于提及和告知新来者,以免将来再犯错误。最有趣的名字就是警察的事件。人们打电话给洛杉矶警方,并要求修复Facebook,因为它在说谎。洛杉矶警长非常厌倦,于是在推特上写道:“请不要给我们打电话!”我们对此不负责!” 我参与的最喜欢的事件称为CAPSLOCK。。有趣的是,它表明一切皆有可能。这就是发生的事情。它obychnyyIP地址:
我参与的最喜欢的事件称为CAPSLOCK。。有趣的是,它表明一切皆有可能。这就是发生的事情。它obychnyyIP地址:fd3b:5679:92eb:9ce4::1。Facebook使用Chef来定制操作系统。服务清单将主机配置存储在其数据库中,Chef从服务接收配置文件。服务更改版本后,立即开始以MySQL格式从数据库中读取IP地址并将其放入文件中。现在,新地址以大写形式书写FD3B:5679:92EB:9CE4::1。Shef查看新文件,发现IP地址已“更改”,因为它不是以二进制形式而是以字符串形式进行比较。 IP地址是“新的”,这意味着您需要降低接口并提升接口。在15分钟内,所有数百万辆汽车的界面都出现了故障。看起来还可以,当网络位于某些计算机上时,容量减少了。但是,我们的自定义网卡的网络驱动程序中突然打开了一个错误:启动时,它们需要0.5 GB的顺序物理内存。在缓存计算机上,当我们降低和提升接口时,这些0.5 GB消失了。因此,在高速缓存计算机上,网络接口出现故障,并且没有上升,没有高速缓存,任何操作均无效。我们坐下来,用手重新启动了这些机器。好玩。事件管理器门户
当Facebook“燃烧”时,需要组织“消防队”的工作,最重要的是要了解其燃烧的地方,因为在一家大公司中,它可以在一个地方“闻到燃烧”,但问题将在另一个地方。名为Incident Manager Portal的UI工具可以帮助我们解决这一问题。它是由生产工程师编写的,并且对所有人开放。事情一旦发生,我们就在这里开始一个事件:名称,开头,描述。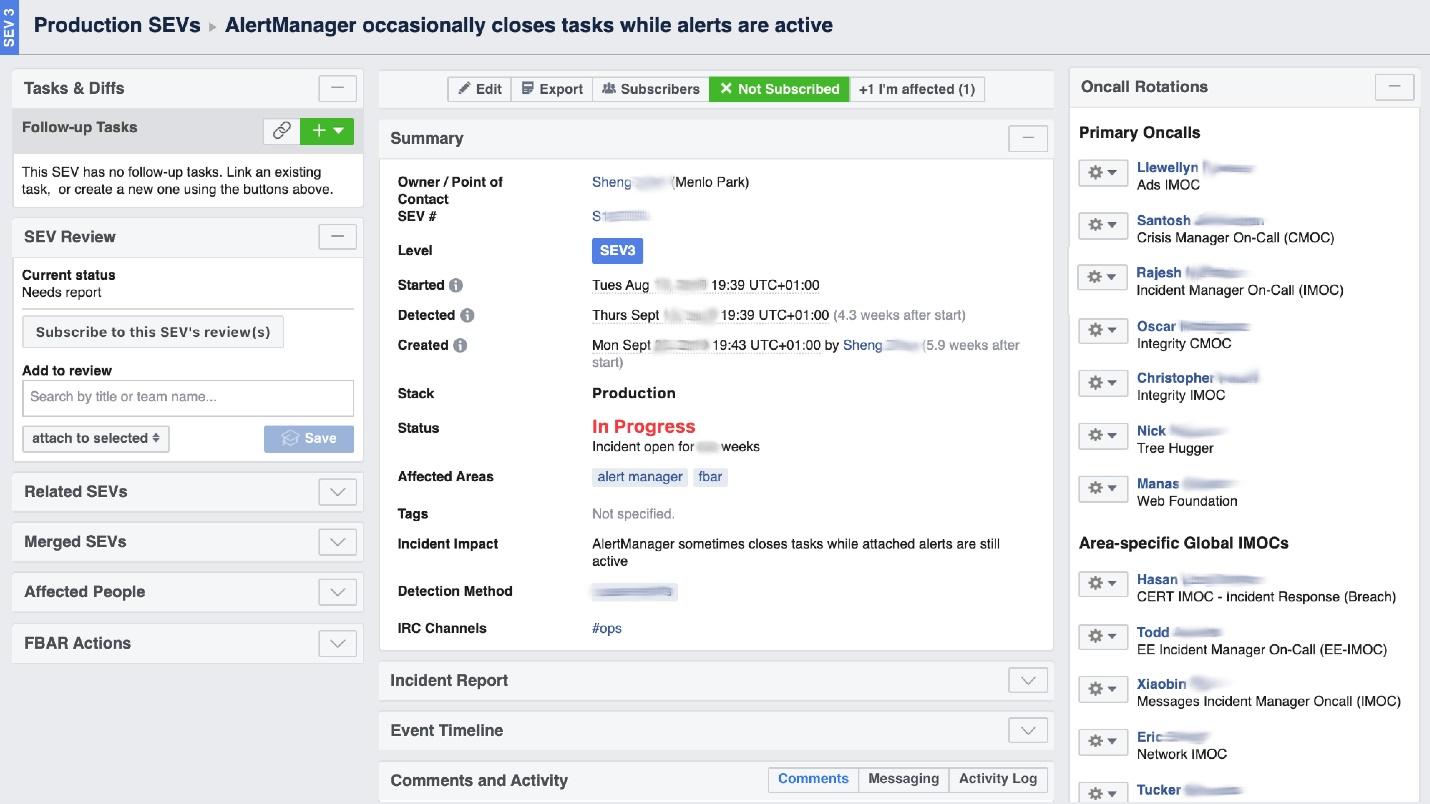 我们有受过专门培训的人员-事件经理待命(IMOC)。这不是一个永久性职位;管理人员会定期更换。万一发生大火,IMOC可以组织和协调人员进行维修,但不必自己修理。一旦发生高危事件,IMOC就会收到SMS,并开始帮助组织一切。在大型系统中,这样的人不能被放弃。
我们有受过专门培训的人员-事件经理待命(IMOC)。这不是一个永久性职位;管理人员会定期更换。万一发生大火,IMOC可以组织和协调人员进行维修,但不必自己修理。一旦发生高危事件,IMOC就会收到SMS,并开始帮助组织一切。在大型系统中,这样的人不能被放弃。预防
Facebook不是那么普遍。在大多数情况下,我们不会扑朔迷离,也不会重新启动缓存计算机,但是我们会预先修复错误,如果可能的话,我们会一次修复每个人。一旦找到并解决了“队列问题”。请求的数量增加了50%,错误增加了100%,因为没有人事先实施节流,尤其是在小型服务中。我们找到了几个服务的示例,并大致定义了一个行为模型。- 在正常负载下,请求到达,处理并返回给客户端。
- 在高负载下,因为所有用于处理请求的线程都忙,所以请求正在队列中等待。延迟在增加,但是到目前为止一切都很好。
- 线在增长,负载在增加。在某个时候,服务器在客户端上执行的所有操作都以响应超时结束,而客户端因错误而退出。此时,服务器的结果可以简单地丢弃。
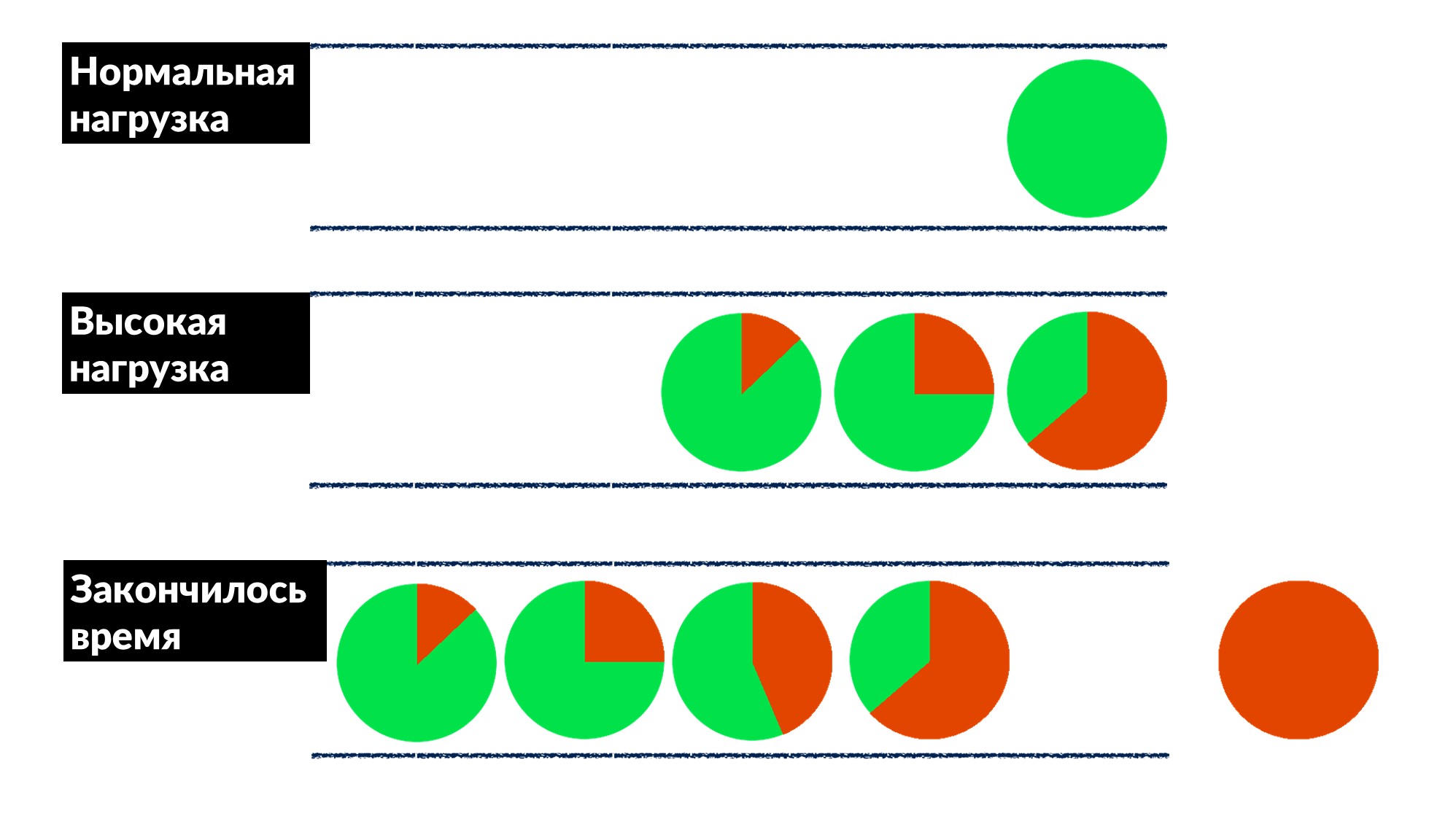 客户端超时以红色突出显示。客户再次重复!事实证明,我们执行的所有请求都被扔进了垃圾箱,并且再也没有人需要它了。如何一次为大家解决这个问题?在队列中引入等待时间限制。如果请求在队列中的数量超出预期,我们会将其丢弃,并且不在服务器上对其进行处理,也不会浪费CPU。我们有一个诚实的游戏:我们丢弃无法处理的所有内容以及可以处理的所有内容。该限制使得在将负载增加到最大负载之上的50%的同时,仍然可以处理66%的请求并仅接收33%的错误。Dispatch框架的开发人员在服务器端实现了这一点,我们的生产工程师将100 ms的超时时间缓慢地解决了所有人的排队情况。因此,所有服务立即获得便宜的基本限制。
客户端超时以红色突出显示。客户再次重复!事实证明,我们执行的所有请求都被扔进了垃圾箱,并且再也没有人需要它了。如何一次为大家解决这个问题?在队列中引入等待时间限制。如果请求在队列中的数量超出预期,我们会将其丢弃,并且不在服务器上对其进行处理,也不会浪费CPU。我们有一个诚实的游戏:我们丢弃无法处理的所有内容以及可以处理的所有内容。该限制使得在将负载增加到最大负载之上的50%的同时,仍然可以处理66%的请求并仅接收33%的错误。Dispatch框架的开发人员在服务器端实现了这一点,我们的生产工程师将100 ms的超时时间缓慢地解决了所有人的排队情况。因此,所有服务立即获得便宜的基本限制。工具类
SRE的意识形态说,如果您有大量的汽车,一堆服务,而与您的双手无关,那么您就需要自动化。因此,有一半的时间我们编写代码和构建工具。- 将立体主义集成到系统中。
- FBAR是一台“主力马”,可以进行修理,因此没有人担心一辆破车。这是FBAR的主要任务,但现在它还有更多任务。
- Coredumper,我们和两位同事一起写的。它监视所有计算机上的核心转储,并将它们与所有主机信息一起放在堆栈跟踪中,包括所有主机信息:位置,如何查找大小。但最重要的是,堆栈跟踪是免费的,无需使用BPF程序启动GDB。
民意调查
我们要做的最后一件事是与人交谈,采访他们。在我们看来,这非常重要。一项有用的民意测验是关于可靠性的。我们在问卷的关键报价中询问已经运行的服务:“系统软件的主要责任必须是继续运行。提供服务应被视为持续运营的有益副作用»
这意味着系统的主要职责是继续工作,并且它提供某种服务是一个额外的好处。大型服务提供商本身理解,调查仅针对中型服务。我们提供了一个调查表,其中我们询问有关架构,SLO,测试的基本知识。- “如果您的系统获得10%的负载会怎样?” 当人们想到:“但是真的呢?” -洞察力出现,甚至许多人统治着他们的系统。以前,他们没有考虑过,但是在提出问题之后,是有原因的。
- “谁是第一个通常注意到您的服务问题的人-您还是您的用户?” 开发人员开始回忆起发生这种情况的时间,并且:“ ...也许您需要添加警报。”
- “您最大的通话痛苦是什么?” 这对于开发人员来说是不寻常的,特别是对于新开发人员而言。他们立即说:“我们有很多警报!让我们清理它们,除去不是的那些。”
- “您的发布频率如何?” 首先,他们记得自己是用手释放它,然后才有自己的自定义部署。
调查表中没有编码;它是标准化的,每六个月更改一次。这是一个两页的文档,我们将在2-3周内帮助您完成填写。然后,我们安排了两个小时的集会,并找到了解决许多难题的方法。这个简单的工具可以很好地与我们合作,并可以为您提供帮助。6-7 Saint HighLoad++, . (, , ).
telegram- . !