预期数据工程师课程的开始,我们准备了一些小而有趣的材料的翻译。
在本文中,我将讨论Parquet如何将大型数据集压缩为较小的占用空间的文件,以及如何使用并发(多线程)实现远远超过I / O流带宽的带宽。Apache Parquet:最适合低熵数据
从Apache Parquet 格式的规范中可以了解到,它包含几个编码级别,可以显着减小文件大小,其中包括:- 使用字典进行编码(压缩)(类似于熊猫。表示数据的分类方式,但是概念本身不同);
- 压缩数据页(Snappy,Gzip,LZO或Brotli);
- 执行长度(对于null-字典的指针和索引)和整数位打包的编码;
为了向您展示这是如何工作的,让我们看一个数据集:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
几乎所有的Parquet实现都使用默认字典进行压缩。因此,编码数据如下:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
字典中的索引还通过重复编码算法进行压缩:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
按照返回路径,您可以轻松地恢复原始的字符串数组。在上一篇文章中,我创建了一个以这种方式很好压缩的数据集。使用时pyarrow,我们可以使用字典(默认情况下已启用)启用和禁用编码,以了解这将如何影响文件大小:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
pandas.DataFrame包含Snappy压缩和使用字典压缩的
占用1 GB(1024 MB)的数据集仅需1.436 MB,即,甚至可以将其写入软盘。如果不使用字典进行压缩,则它将占用44.4 MB。使用PyArrow在Parquet-cpp中并发读取
在C ++中的Apache Parquet的实现-parquet -cpp中,我们在PyArrow中将其提供给Python使用,其中添加了并行读取列的功能。要尝试此功能,请从conda - forge安装PyArrow :conda install pyarrow -c conda-forge
现在,当读取Parquet文件时,可以使用参数nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
对于低熵的数据,解压缩和解码与处理器紧密相关。由于C ++为我们完成了所有工作,因此GIL并行性没有问题,并且可以显着提高速度。通过在四核笔记本电脑(至强E3-1505M,NVMe SSD)上的pandas DataFrame中读取1 GB 数据集,可以了解我的能力: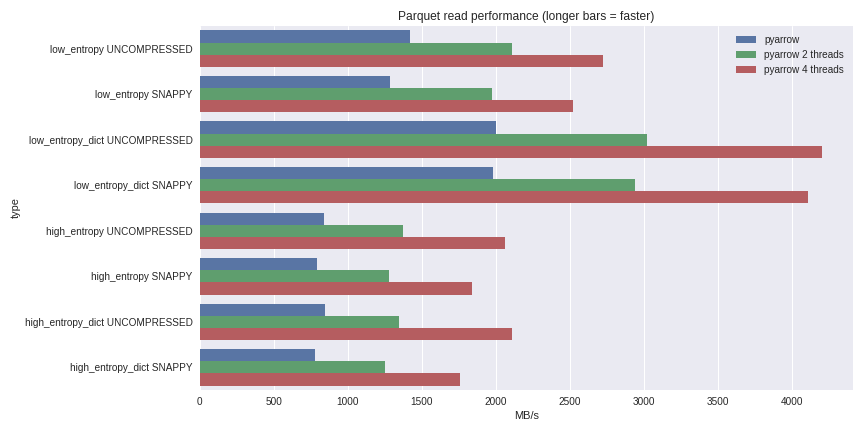 您可以在此处查看完整的基准测试方案。对于使用字典的压缩情况和不使用字典的情况,我都在此处包括了性能。对于低熵的数据,尽管事实上所有文件都很小(使用字典时约为1.5 MB,使用字典时约为45 MB),但使用字典进行压缩会显着影响性能。借助4个线程,熊猫的读取性能提高到4 GB / s。这比Feather格式或我所知道的任何其他格式快得多。
您可以在此处查看完整的基准测试方案。对于使用字典的压缩情况和不使用字典的情况,我都在此处包括了性能。对于低熵的数据,尽管事实上所有文件都很小(使用字典时约为1.5 MB,使用字典时约为45 MB),但使用字典进行压缩会显着影响性能。借助4个线程,熊猫的读取性能提高到4 GB / s。这比Feather格式或我所知道的任何其他格式快得多。结论
随着1.0版本parquet-cpp(C ++中的Apache Parquet)的发布,您可以亲眼看到Python用户现在可以使用的提高的I / O性能。由于所有基本机制都是用C ++实现的,因此使用其他语言(例如R),您可以为Apache Arrow(列数据结构)和parquet-cpp创建接口。Python绑定是核心libarrow和libparquet C ++库的轻量级外壳。就这样。如果您想进一步了解我们的课程,请注册一个开放日,该日将在今天举行!