注意佩雷夫。:在本文中,Banzai Cloud共享了一个使用其特殊实用程序的示例,以促进Kubernetes中Kafka的操作。这些说明说明了如何确定最佳的基础结构大小并配置Kafka本身以实现所需的吞吐量。 Apache Kafka是一个分布式流媒体平台,用于创建可靠,可伸缩和高性能的实时流媒体系统。 Kubernetes可以扩展其令人印象深刻的功能。为此,我们开发了 Kafka开源运算符和一个名为 Supertubes的工具。它们使您可以在Kubernetes中运行Kafka并使用其各种功能,例如微调代理的配置,基于带有重新平衡的指标进行扩展,机架感知(硬件资源的意识),“软” (优雅)滚动更新等。
Apache Kafka是一个分布式流媒体平台,用于创建可靠,可伸缩和高性能的实时流媒体系统。 Kubernetes可以扩展其令人印象深刻的功能。为此,我们开发了 Kafka开源运算符和一个名为 Supertubes的工具。它们使您可以在Kubernetes中运行Kafka并使用其各种功能,例如微调代理的配置,基于带有重新平衡的指标进行扩展,机架感知(硬件资源的意识),“软” (优雅)滚动更新等。在您的集群中尝试Supertubes:
curl https://getsupertubes.sh | sh supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
或参考文档。您还可以阅读有关Kafka的某些功能,这些功能在Supertubes和Kafka运算符的帮助下是自动化的。我们已经在博客中写过关于它们的信息:
当您决定在Kubernetes中部署Kafka集群时,可能会遇到确定基础架构的最佳大小以及需要微调Kafka配置以满足带宽需求的问题。每个代理的最大性能取决于其核心基础结构组件的性能,例如内存,处理器,磁盘速度,网络带宽等。理想情况下,代理的配置应使基础结构的所有元素都得到最大程度的利用。但是,在现实生活中,此设置非常复杂。用户更有可能将代理配置为最大化使用一个或两个组件(磁盘,内存或处理器)。通常,当代理程序的配置允许您“使用全部”最慢的组件时,该代理程序将显示出最佳性能。这样我们就可以大致了解一个经纪人可以处理的负载。从理论上讲,我们还可以估计在给定负载下工作所需的代理数量。但是,实际上,存在许多不同级别的配置选项,以至于很难(如果不是不可能)评估某种配置的潜在性能。换句话说,从某些给定的性能开始计划配置是非常困难的。对于Supertubes用户,我们通常采用以下方法:从某种配置(基础架构+设置)开始,然后测量其性能,调整代理设置并再次重复该过程。直到充分利用最慢的基础结构组件的潜力为止。这样,我们对集群需要处理多少负载的代理有一个更清晰的了解(代理的数量还取决于其他因素,例如确保稳定性的消息副本的最小数量,分区领导者的数量等)。另外,我们了解到需要哪种基础架构组件垂直扩展。本文将讨论我们采取的步骤,以从初始配置中最慢的组件中“榨取一切”,并测量Kafka集群的吞吐量。高度弹性的配置至少需要三个工作代理(min.insync.replicas=3)分为三个不同的辅助功能区。为了配置,扩展和监视Kubernetes基础架构,我们使用了自己的混合云容器管理平台Pipeline。它支持内部部署(裸机,VMware)和五种类型的云(阿里巴巴,AWS,Azure,谷歌,甲骨文)及其任意组合。关于Kafka集群的基础架构和配置的思考
对于以下示例,我们选择AWS作为云服务提供商,并选择EKS作为Kubernetes发行版。可以使用经CNCF认证的Banzai Cloud的Kubernetes发行版PKE来实现类似的配置。磁碟
亚马逊提供各种类型的EBS卷。SSD是gp2和io1的基础,但是,为了确保高吞吐量,gp2会消耗累积的贷款(I / O积分),因此我们首选io1类型,它提供稳定的高吞吐量。实例类型
Kafka的性能高度依赖于操作系统的页面缓存,因此我们需要具有足够内存以供代理(JVM)和页面缓存使用的实例。实例c5.2xlarge是一个不错的开始,因为它具有16 GB的内存,并且已针对使用EBS进行了优化。其缺点是每24小时最多只能提供30分钟的最高性能。如果您的工作负载需要较长时间才能达到最佳性能,请查看其他类型的实例。我们就是这样做的,在c5.4xlarge处停止。它提供的最大吞吐量为593.75 Mb / s。。EBS io1卷的最大吞吐量高于c5.4xlarge实例的吞吐量,因此,最慢的基础结构元素可能是此类实例的I / O吞吐量(这也应由我们的负载测试结果证实)。网络
与VM实例和磁盘的性能相比,网络带宽应相当大,否则网络将成为瓶颈。在我们的案例中,c5.4xlarge网络接口支持的速度高达10 Gb / s,这明显高于VM的I / O实例的带宽。经纪人部署
应该将代理部署(在Kubernetes中计划)到专用节点,以避免与其他进程争夺处理器,内存,网络和磁盘资源。Java版本
逻辑选择是Java 11,因为从JVM正确确定运行代理的容器可用的处理器和内存的意义上说,它与Docker兼容。知道处理器限制很重要,因此JVM在内部透明地设置了GC线程和JIT编译器线程的数量。我们banzaicloud/kafka:2.13-2.4.0在Java 11中使用了包含Kafka 2.4.0(Scala 2.13)的Kafka映像。如果您想了解有关Kubernetes上Java / JVM的更多信息,请查看我们的以下出版物:
经纪人内存设置
设置代理的内存有两个关键方面:JVM和Kubernetes pod的设置。为pod设置的内存限制必须大于最大堆大小,以便JVM在其自身的内存中以及Java活跃的Kafka使用的操作系统页面高速缓存中具有足够的空间。在我们的测试中,我们使用参数运行Kafka代理-Xmx4G -Xms2G,并且pod的内存限制为10 Gi。请注意,可以根据容器的内存限制,使用-XX:MaxRAMPercentage和来自动获取JVM的内存设置-X:MinRAMPercentage。经纪人处理器设置
一般来说,可以通过增加Kafka使用的线程数来提高并发性,从而提高生产率。可用于Kafka的处理器越多越好。在我们的测试中,我们从6个处理器的限制开始,然后逐渐(迭代)将其数量增加到15个。此外,我们num.network.threads=12在代理设置中进行设置,以增加从网络接收并发送数据的流的数量。立即发现追随者经纪人不能足够快地接收副本,他们提高num.replica.fetchers到4以提高追随者经纪人复制领导者邮件的速度。负载生成工具
确保在Kafka集群(正在运行基准测试)达到其最大负载之前,所选负载生成器的电势不会耗尽。换句话说,有必要对负载生成工具的功能进行初步评估,并为其选择具有足够数量的处理器和内存的实例类型。在这种情况下,我们的工具将产生比Kafka集群可消化的负载更多的负载。经过多次实验,我们选择了c5.4xlarge的三个副本,每个副本中都启动了生成器。标杆管理
性能评估是一个反复的过程,包括以下步骤:- 基础架构设置(EKS集群,Kafka集群,负载生成工具以及Prometheus和Grafana);
- 在一定时期内产生负载,以过滤收集的性能指标中的随机偏差;
- 根据观察到的性能指标微调代理的基础结构和配置;
- 重复此过程,直到达到所需的Kafka群集带宽水平。同时,它应该稳定地重现并显示最小的带宽变化。
下一节描述了基准测试群集中执行的步骤。工具类
以下工具用于快速部署基本配置,负载生成和性能评估:
EKS集群
准备一个带有专用c5.4xlarge工作节点的EKS群集,该工作节点位于各个可用区中,用于带有Kafka代理的Pod,以及用于负载生成器和监视基础结构的专用节点。banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
当EKS群集运行时,启用其集成的监视服务 -它将Prometheus和Grafana部署到群集。Kafka系统组件
使用supertubes CLI在EKS中安装Kafka系统组件(Zookeeper,kafka-operator):supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
卡夫卡集群
默认情况下,EKS使用gp2 EBS 卷,因此您需要基于io1卷为Kafka集群创建一个单独的存储类:kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF
为代理设置参数,min.insync.replicas=3并在三个不同的可用区域中的节点上部署代理pod:supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600
主题
我们同时启动了负载生成器的三个实例。他们每个人都写自己的主题,也就是说,我们只需要三个主题:supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
对于每个主题,复制因子均为3-高可用性生产系统的最小建议值。负载生成工具
我们启动了负载生成器的三个实例(每个实例在一个单独的主题中编写)。对于负载生成器的Pod,您需要注册节点相似性,以便仅在为其分配的节点上计划它们:apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
需要注意的几点:- 负载生成器会生成512字节的消息,并以500条消息的批次将其发布到Kafka。
-required-acks=all , Kafka. , , , , . (consumers) , , , .- 20 worker' (
-workers=20). worker 5 producer', worker' Kafka. 100 producer', Kafka.
集群监控
在对Kafka集群进行压力测试期间,我们还监控了其运行状况,以确保没有pod重启,不同步的副本以及最大的吞吐量,同时波动最小:测量结果
3个代理,消息大小-512字节
通过将分区均匀地分布在三个代理上,我们设法实现了约500 Mb / s(每秒约99万条消息)的性能:

 JVM虚拟机的内存消耗未超过2 GB:
JVM虚拟机的内存消耗未超过2 GB:

 磁盘带宽达到了最大I / O带宽代理工作的所有三个实例上的节点:
磁盘带宽达到了最大I / O带宽代理工作的所有三个实例上的节点: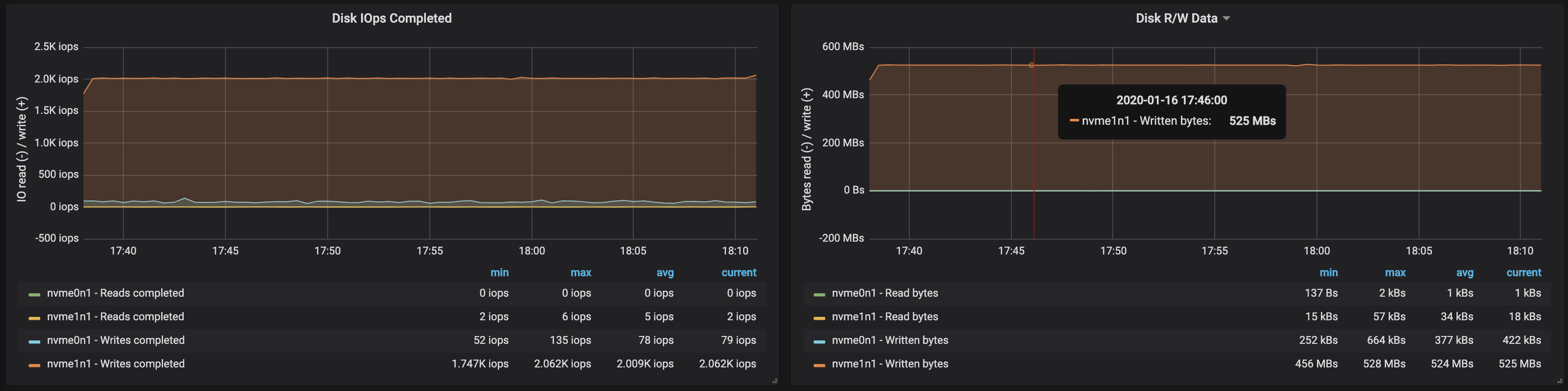

 从节点的内存使用情况数据来看,系统缓冲和缓存大约需要10-15 GB:
从节点的内存使用情况数据来看,系统缓冲和缓存大约需要10-15 GB:


3个代理,消息大小-100字节
随着消息大小的减少,吞吐量将减少约15-20%:处理每条消息所花费的时间会受到影响。此外,处理器负载几乎翻了一番。

 由于代理节点仍具有未使用的内核,因此可以通过更改Kafka的配置来提高性能。这不是一件容易的事,因此,要提高吞吐量,最好使用较大的消息。
由于代理节点仍具有未使用的内核,因此可以通过更改Kafka的配置来提高性能。这不是一件容易的事,因此,要提高吞吐量,最好使用较大的消息。4个代理,消息大小-512字节
您只需添加新的代理并保持分区的平衡即可轻松提高Kafka集群的性能(这可确保代理之间的负载平均分配)。在我们的情况下,添加代理后,群集吞吐量增加到〜580 Mb / s(每秒约110万条消息)。事实证明,增长幅度小于预期:这主要是由于分区的不平衡(并非所有经纪人都在机会高峰期工作)。


 JVM计算机的内存消耗保持在2 GB以下:
JVM计算机的内存消耗保持在2 GB以下:


 分区不平衡影响了具有驱动器的代理的操作:
分区不平衡影响了具有驱动器的代理的操作:



发现
上面介绍的迭代方法可以扩展为涵盖更复杂的场景,包括数百个使用者,重新分区,滚动更新,pod重新启动等。所有这些使我们能够评估Kafka集群在各种条件下的功能极限,确定其工作瓶颈并找到应对方法。我们开发了Supertubes,可以快速,轻松地部署集群,对其进行配置,添加/删除代理和主题,响应警报,并确保Kafka在整个Kubernetes中都能正常工作。我们的目标是帮助专注于主要任务(“生成”和“使用” Kafka消息),并将Supertubes和Kafka的所有辛苦工作提供给操作员。如果您对Banzai Cloud技术和开源项目感兴趣,请在GitHub,LinkedIn或Twitter上订阅该公司。译者的PS
另请参阅我们的博客: