在OTUS 的机器学习课程开始之前,准备了本文的翻译。
任务
在本指南中,我们使用比特币与美元数据集。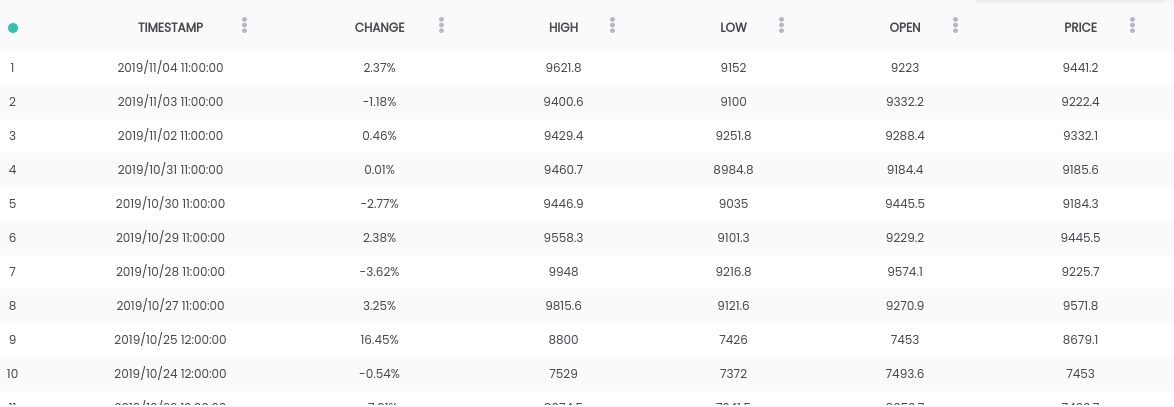 上面的数据集包含每日价格摘要,其中CHANGE列是价格相对于前一天价格(PRICE)对新价格(OPEN)的百分比变化。目标:为了简化任务,我们将集中于预测第二天价格是上涨(CHANGE> 0)还是下跌(CHANGE <0)。(因此我们可以潜在地使用``现实生活中的预测'')。要求
上面的数据集包含每日价格摘要,其中CHANGE列是价格相对于前一天价格(PRICE)对新价格(OPEN)的百分比变化。目标:为了简化任务,我们将集中于预测第二天价格是上涨(CHANGE> 0)还是下跌(CHANGE <0)。(因此我们可以潜在地使用``现实生活中的预测'')。要求- 必须在系统上安装Python 2.6+或3.1+
- 安装pandas,sklearn和openblender(使用pip)
$ pip install pandas OpenBlender scikit-learn
步骤1.获取比特币数据
首先,让我们导入必要的库:import OpenBlender
import pandas as pd
import json
现在,通过OpenBlender API提取数据。首先,让我们定义参数(在我们的例子中,这只是比特币数据集的ID ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
注意:您需要在openblender.io上创建一个帐户(免费)并添加令牌(您可以在“帐户”标签中找到该令牌):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
现在,让我们将数据放入Dataframe'df '中:
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
并查看它们: 注意:值可能会有所不同,因为数据集每天都会更新!
注意:值可能会有所不同,因为数据集每天都会更新!步骤2.数据准备
首先,我们需要创建一个预测目标,即“ CHANGE ”是增加还是减少。为此,将'success_thr_over':0添加到目标阈值参数:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
如果我们再次从API中提取数据:df = pullObservationsToDF(parameters)
df.head()
 属性“ CHANGE”已由新属性“ change_over_0”替换,如果“ CHANGE”为正,则变为1,否则为0。这将是机器学习的目标。如果我们要预测“明天”的观测,我们将无法使用明天的信息,因此我们加一个延迟时间。
属性“ CHANGE”已由新属性“ change_over_0”替换,如果“ CHANGE”为正,则变为1,否则为0。这将是机器学习的目标。如果我们要预测“明天”的观测,我们将无法使用明天的信息,因此我们加一个延迟时间。parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 这只是将“ change_over_0”与前一天(期间)的数据对齐,并将其名称更改为“ TARGET_change_over_0”。让我们看一下依赖关系:
这只是将“ change_over_0”与前一天(期间)的数据对齐,并将其名称更改为“ TARGET_change_over_0”。让我们看一下依赖关系:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 它们是线性独立的,不太可能有用。
它们是线性独立的,不太可能有用。步骤3.获取商业新闻数据
在OpenBlender中搜索依赖项之后,我发现了Fox商业新闻数据集,该数据集将有助于为目标生成良好的预测。 我们需要找到一种方法,通过计算新闻摘要中单词和单词组的重复次数,并将``标题''列的值转换为数字特征,并将它们与我们的比特币数据集进行及时比较。这比听起来容易。首先,您需要为新闻的“标题”属性创建一个TextVectorizer:
我们需要找到一种方法,通过计算新闻摘要中单词和单词组的重复次数,并将``标题''列的值转换为数字特征,并将它们与我们的比特币数据集进行及时比较。这比听起来容易。首先,您需要为新闻的“标题”属性创建一个TextVectorizer:action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
我们将创建一个矢量化程序,以数字形式将所有符号作为标记词获得。上面,我们指出了以下几点:- 名称:我们称其为“ Fox Business TextVectorizer”;
- anchor:数据集的ID和我们将需要用作源的特征的名称(在我们的情况下,仅是'title'列);
- ngram_range:用于标记化的一组单词的最小和最大长度;
- 语言:英语
- remove_stop_words:从源中删除停用词;
- min_count_limit:应该视为标记的最小重复次数(单次出现很少有用)。
现在运行:res = OpenBlender.call(action, vectorizer_parameters)
res
回答:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
创建了TextVectorizer,根据我们的配置生成了4270个n-gram。稍后,我们将需要生成的ID:5dc1a404951629331f6359dd步骤4.与比特币数据集兼容的新闻摘要
现在我们需要及时比较新闻摘要和比特币汇率数据。通常,这意味着您需要使用时间戳作为键来组合两组数据。让我们将合并的数据添加到原始数据提取选项中:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
上面,我们指出了以下几点:- id_blend:我们的textVectorizer的ID;
- blend_type:'text_ts',以便Python理解它是文本和时间戳的混合;
- 限制:“预测性”,因此将来的新闻不会与所有观察“混合”,而只能与在指定时间之前发布的那些“混合”。
- blend_class:'closest_observation',因此只有最接近的观测值才被“混合”;
- 规格:用于传输观测值的最大可能经过时间,在这种情况下为12小时(3600 * 12)。这意味着将根据最近12个小时的新闻预测对比特币价格的每次观察。
最后,我们只是按日期添加过滤器“date_filter”日期,开始于8月20日,因为这是当福克斯新闻开始收集数据,并“drop_non_numeric”,使我们得到的只有数:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
注意:我将11月4日表示为'end_date',因为这是我编写此代码的日期,因此您可以更改日期。让我们再次获取数据:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57,2115) 现在,我们有2000多个带有标记和57个观察值的符号。
现在,我们有2000多个带有标记和57个观察值的符号。步骤5.将ML应用于预测目标
现在,最后,我们有了一个干净的数据集,它看起来完全符合我们的需要,并且具有目标和关联数值数据的时间偏移。让我们看一下与“ Target_change_over_0”的最高相关性: 现在,我们有了一些相关属性。让我们按时间顺序将数据集分为训练和测试,以便我们可以在早期观察中训练模型,在以后进行观察。
现在,我们有了一些相关属性。让我们按时间顺序将数据集分为训练和测试,以便我们可以在早期观察中训练模型,在以后进行观察。X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 我们有40个观察值用于训练,而17个则用于测试。现在我们导入必要的库:
我们有40个观察值用于训练,而17个则用于测试。现在我们导入必要的库:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
现在,让我们使用随机森林(RandomForest)进行预测:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
为了更容易理解,我们将预测和y_test放入数据框:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
我们真正的'y_test'是二进制的,但是我们的预测是float类型的,因此我们将它们四舍五入,假设如果它们大于0.5,则意味着价格上涨,如果小于0.5,则意味着下跌。threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
现在,为了更好地理解结果,我们获得了AUC,误差矩阵和准确性指标:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 使用0.65 AUC,可以得到正确预测的64.7%。
使用0.65 AUC,可以得到正确预测的64.7%。- 我们预计会下降9倍,而价格也会下降(右);
- 我们预测会下降5倍,并且价格(不正确地)上涨;
- 我们预计会增加1次,但价格下降幅度却不正确);
- 我们预测价格会上涨2倍,且价格会上涨(真实)。
了解有关该课程的更多信息。