当又一个丰硕的一年结束时,我想回顾一下,盘点一下,并展示在这段时间内我们能做些什么。#DeepPavlov库已经有两年的历史了,很高兴我们的社区每天都在增长。在图书馆工作的一年中,我们实现了:是什么帮助实现了这样的结果?为什么DeepPavlov是构建对话式AI的最佳开源?我们将在文章中讲述。
#DeepPavlov瞄准结果
最近,对话系统已经成为人机交互的标准。聊天机器人几乎用于所有行业,从而简化了人与计算机之间的交互。它们无缝集成到网站,消息传递平台和设备中。如今,许多公司更喜欢将日常任务委托给可以同时处理多个用户请求的交互式系统,从而节省了人工成本。但是,公司通常不知道在开发满足其业务需求的机器人时应该从哪里开始。从历史上看,聊天机器人可以分为两大类:基于规则和基于数据。第一种类型依赖于预定义的命令和模板。这些命令中的每一个都应该由聊天机器人开发人员使用正则表达式和文本数据分析编写。相比之下,数据驱动的聊天机器人依赖于对数据进行了预训练的机器学习模型。开源库-DeepPavlov提供用于构建交互式系统的免费且易于使用的解决方案。 DeepPavlov带有一些经过预训练的组件,以解决与自然语言处理(NLP)相关的问题。DeepPavlov解决的问题包括:文本分类,拼写错误,命名实体的识别,知识库中问题的答案等。您可以通过运行以下命令在一行中安装DeepPavlov:pip install -q deeppavlov
*该框架允许您训练和测试模型,以及自定义其超参数。该库支持Linux和Windows平台。您可以在库的演示版本中尝试使用此模型和其他模型。当前,通过使用基于BERT的模型,已在许多任务中实现了现代化的结果。DeepPavlov团队将BERT集成到以下三个任务中:文本分类,识别命名实体以及问题的答案。结果,我们在所有这些任务上都进行了重大改进。1. BERT DeepPavlov模型
用于文本分类的
BERT例如,基于BERT DeepPavlov的文本分类模型用于解决检测侮辱的问题。该模型包括预测是否将公开讨论中发表的评论视为对参与者之一的冒犯。对于这种情况,仅在两个类别中进行分类:侮辱和不侮辱。任何经过预训练的模型都可以用于通过命令行界面(CLI)和Python进行输出。在使用模型之前,请确保使用以下命令安装了所有必需的软件包:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
用于命名实体识别的BERT
除了文本分类模型外,DeepPavlov还包括用于命名实体识别(NER)的基于BERT的模型。这是NLP中最常见的任务之一,也是我们库中使用最多的模型。同时,NER具有许多业务应用程序。例如,模型可以从简历中提取重要信息,以促进人力资源专家的工作。另外,NER可用于识别客户请求中的相关实体,例如产品规格,公司名称或公司分支机构信息。DeepPavlov团队使用英语的OntoNotes软件包对NER模型进行了培训,该软件包具有19种标记类型,包括PER(人员),LOC(位置),ORG(组织)以及许多其他标记。要与之交互,必须使用以下命令进行安装:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
用于回答问题的BERT问题的
上下文答案是在给定上下文(例如,Wikipedia中的一段)中找到问题答案的任务,其中每个问题的答案都是上下文段。例如,下面的上下文,问题和答案三元组构成了回答问题的正确三元组。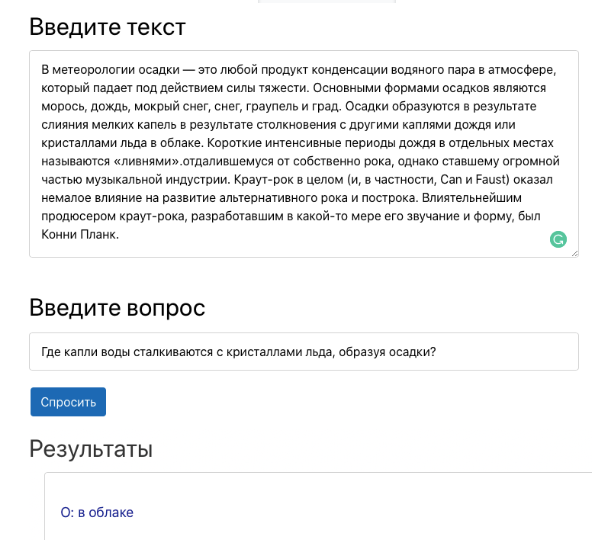 在演示中演示问答系统的工作。问题解答系统可以使企业中的许多流程自动化。例如,这可以帮助雇主根据公司内部文件获得答案。此外,该模型将有助于测试学生在学习过程中理解课文的能力。然而,近来,基于上下文回答问题的任务引起了科学家的极大关注。该领域的关键转折点之一是发布了斯坦福问题答案集(SQuAD)。SQuAD数据集导致解决问题系统的方法无数。DeepPavlov BERT模型是最成功的模型之一。它超越了所有其他方面,目前正在产生与人类特征相近的结果。要将基于BERT的质量检查模型与DeepPavlov一起使用,您必须:
在演示中演示问答系统的工作。问题解答系统可以使企业中的许多流程自动化。例如,这可以帮助雇主根据公司内部文件获得答案。此外,该模型将有助于测试学生在学习过程中理解课文的能力。然而,近来,基于上下文回答问题的任务引起了科学家的极大关注。该领域的关键转折点之一是发布了斯坦福问题答案集(SQuAD)。SQuAD数据集导致解决问题系统的方法无数。DeepPavlov BERT模型是最成功的模型之一。它超越了所有其他方面,目前正在产生与人类特征相近的结果。要将基于BERT的质量检查模型与DeepPavlov一起使用,您必须:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
可以在文档中找到更多模型。如果您需要使用库组件的教程,请在我们的官方博客中查找它们。2. DeepPavlov Agent-用于创建多任务聊天机器人的平台
如今,有几种开发交互式代理的方法。在开发会话代理程序时,模块化体系结构主要用于展开脚本的重点对话。但是,用户通常需要将聚焦的对话与其他功能结合在一起,例如回答问题或搜索信息,以及保持对话。因此,理想的对话代理是一个个人助理,可以组合不同类型的代理,并根据其使用的任务在其功能和角色之间进行切换。同时,代理必须累积有关其本质的信息,并针对特定用户调整其算法。另一方面,它应该能够与外部服务集成。例如,对外部数据库进行查询,从那里获取信息,进行处理,突出显示重要信息,并将其传输给用户。为了解决此问题,2019年10月,发布了DeepPavlov Agent 1.0的第一版,该平台是用于创建多任务聊天机器人的平台。该代理可帮助生产聊天机器人的开发人员在一个管道中组织多个NLP模型。在文档中阅读有关平台和功能的更多信息。3. DeepPavlov NLP SaaS的实施
为了简化DeepPavlov中经过预训练的NLP模型的工作,于2019年9月推出了SaaS服务。DeepPavlov Cloud允许您分析文本以及将文档存储在云中。要使用模型,您需要在我们的服务中注册并在您个人帐户的“令牌”部分中获得令牌。目前,该服务支持几种俄语预训练的NLP模型,并且正在测试系统。4.参加DSCT8或有针对性的对话系统
使用诸如Amazon Alexa和Google Assistant之类的虚拟助手为开发应用程序打开了机会,这些应用程序使我们能够简化许多日常任务的实现,例如订购出租车,在餐厅订餐等,为了解决此类问题,我们使用了重点对话系统。对话状态跟踪(DST)是此类对话系统中的关键组成部分。 DST负责将人类语言中的语音转换为语言的语义表示,尤其是提取与用户目标相对应的意图和广告位/值对。在团队参与DSTC8期间开发了GOLOMB模型(基于GOaL的基于多任务BERT的对话状态跟踪器)-一种基于目标的基于BERT的多任务模型以跟踪对话的状态。为了预测对话状态,该模型解决了几个分类问题以及查找子字符串的任务。很快,该模型将出现在DeepPavlov库中。同时,您可以在此处阅读全文。 海报在美国纽约AAAI-20会议上的介绍。
海报在美国纽约AAAI-20会议上的介绍。
5.参加Alexa奖Socialbot大奖赛
DeepPavlov团队由莫斯科物理技术学院的学生和研究生组成,被选中参加Alexa奖Socialbot Grand Challenge 3,这是一项致力于开发对话式AI技术的国际竞赛。竞赛的目的是创建一个可以在相关主题上与人们自由交流的机器人。在375个申请中,Alexa奖委员会选择了10个决赛入围者,其中包括我们的团队-DREAM。目前,该队已进入比赛的四分之一决赛,并正在努力争取进入半决赛。您可以在官方页面上关注新闻并为我们加油,并且不要忘记订阅Twitter。 团队组成梦之队。
团队组成梦之队。
6.参加TF挑战赛
如前所述,DeepPavlov附带了一些由TensorFlow和Keras支持的预训练组件。今年,DeepPavlov团队获得了使用TensorFlow库的最佳机器学习项目的Google Powered by TF Challenge竞赛。在600多个竞赛参与者中,Google选择了五个最佳项目,其中一个是DeepPavlov库。该项目已在TensorFlow官方博客上介绍。值得注意的是,TensorFlow的灵活性使我们能够创建可以想到的任何神经网络架构。特别是,我们使用TensorFlow与基于BERT的模型进行无缝集成。
7.社区发展
我们项目的全球目标是使对话人工智能领域的开发人员和研究人员能够使用最先进的工具来创建下一代交互系统,并成为AI领域具有国际意义的平台,以交流经验和教授最先进的技术。为此,DeepPavlov员工为参与计算机科学的学生和员工提供免费的学期培训课程。其中一门课程是“自然语言处理中的深度学习”课程,其中包括研讨会和讲习班。这些课程包括以下主题:建立对话系统,评估具有响应能力的对话系统的方法,对话系统的各种框架,由于对话政策的优化而估算酬金的方法,用户请求的类型,对呼叫中心呼叫建模的考虑。 2020年,我们启动了新的招聘计划,已有900名学生和员工免费接受培训。您可以在我们的网站上关注本课程和其他课程的新闻和背景。如果您错过了课程,但想了解更多信息,请访问我们的youtube频道,您随时可以在记录中找到它们。如今,DeepPavlov库提供了AI就绪的用于处理文本的组件,该组件在全球92个国家中使用。到2020年2月,该库的下载量已达到100,000万,并且安装动态正在发展。此外,俄罗斯已有30多家公司实施并成功使用了基于DeepPavlov的解决方案。这表明这种解决方案在世界范围内非常流行。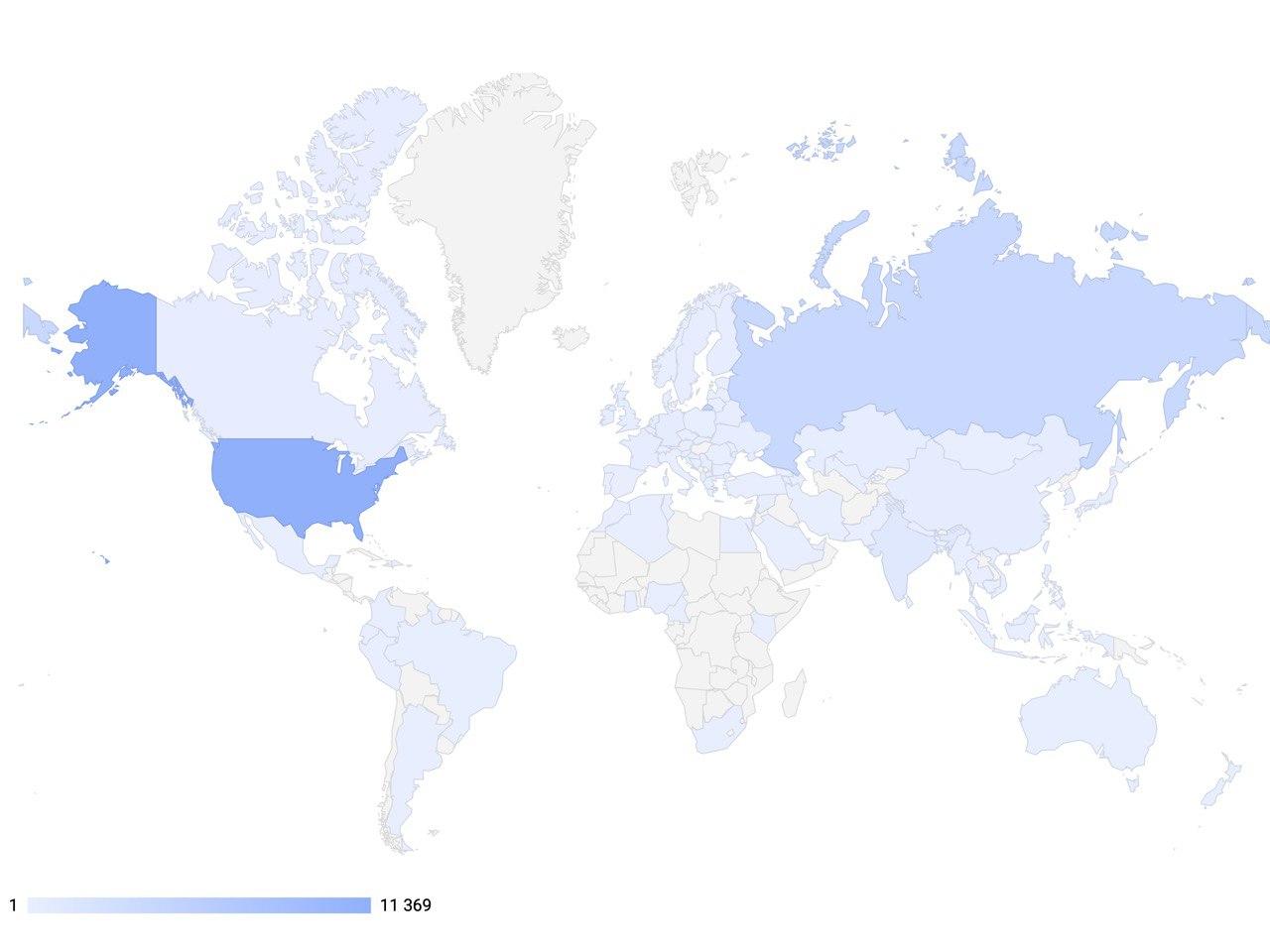
下一步是什么?
我们很高兴与您分享我们的成功,因此我们为社区准备了一个活动。我们希望分享来自实际生产项目的经验和知识,以了解如何创建最佳的AI助手。加入2月28日DeepPavlov开放库用户和开发人员会议,讨论人工智能及其应用,并与社区其他成员见面。该活动将于2月25日至28 日作为AI周的一部分举行。我们正在等待使用DeepPavlov或想了解我们技术的每个人。有关演讲者和该计划的所有信息都可以在网站上找到,参加活动需要注册。加入:DeepPavlov 2年
人工智能行业将继续发展,我们相信DeepPavlov将成为每个开发人员都会用来理解自然语言的先进技术。明年,我们将努力使我们的社区增加一倍,增加开源工具,并改善机器学习研究。并且不要忘记DeepPavlov有一个论坛 -提出有关库和模型的问题。感谢您的关注!