最近,应用程序中的字符识别任务并不是特别困难-您可以使用许多现成的OCR库,其中许多已经完善。但尽管如此,有时可能会出现一项任务,需要开发您自己的识别算法,而无需使用第三方“复杂的” OCR库。
这正是我工作期间出现的任务,最好不要使用现成的库,这有几个原因:封闭的项目,经过进一步的认证,对代码行数和连接库的大小有一定的限制,此外,由于您必须在主题领域内有足够的认识,特定字符集。
识别算法很简单,当然,它并不是最准确,快速和有效的,但是可以很好地应对它的小任务。
假设我们以结构化形式的文档扫描图像形式输入。这些文档在左上角有一个特殊的单字符代码。我们的任务是识别该符号,然后执行一些操作,例如,根据给定的规则对源文档进行分类。

算法图如下:
 由于我们预先知道符号的位置,因此切入特定区域并不困难。为了消除符号边缘的所有“不规则性”,我们将图像转换为单色(黑白)。
由于我们预先知道符号的位置,因此切入特定区域并不困难。为了消除符号边缘的所有“不规则性”,我们将图像转换为单色(黑白)。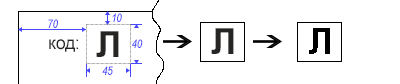
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
接下来,您需要将生成的片段“逐个像素”转换为二进制字符串,例如,其中“ *”对应于黑色像素,而空格则转换为白色的字符串。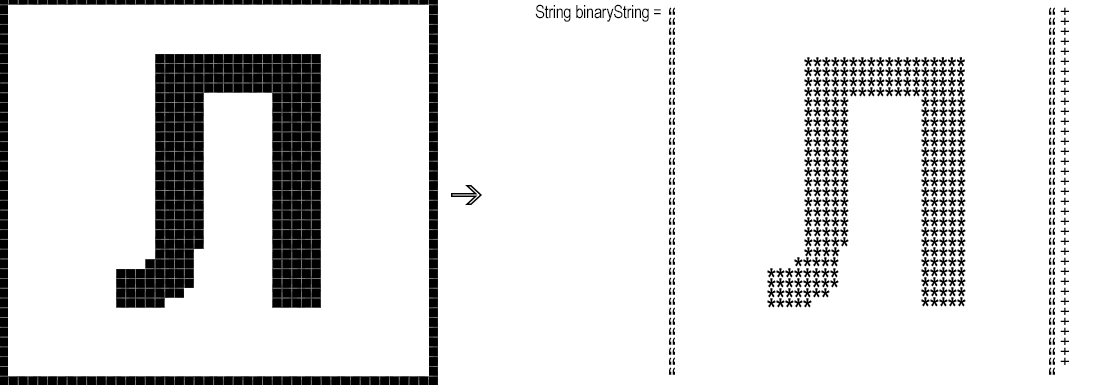
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
接下来,您需要找到接收到的字符串和预先准备的参考字符串之间的最小Levenshtein距离(实际上,您可以采用任何字符串比较方法)。int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
查找Levenshtein距离的功能是根据标准算法的一种方法:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
结果findSymbol将是我们公认的字符。可以优化该算法以提高性能,并补充各种检查以提高识别效率。许多指标取决于要解决的问题的特定主题区域(字符数,字体的种类,图像质量等)。实际上,发现该方法可以定性地应对字符``相似性''等有问题的问题,例如``L''<-> “ P”,“ 5” <->“ S”,“ O” <->“ 0”。因为,例如,即使存在一些“不规则性”,二进制字符串“ L”和“ P”之间的距离将始终大于识别的“ L”和参考字符串“ L”之间的距离。通常,如果您需要解决类似的问题(例如,识别扑克牌),并且对神经元的使用和其他现成的解决方案有很多限制,则可以安全地采用和修改此方法。