我们在Sberbank的团队正在开发会话数据服务,该服务可组织分布式应用程序之间单个Java会话上下文的互换。我们的服务迫切需要非常快速的Java对象序列化,因为这是我们关键任务的一部分。最初,它们浮现在我们的脑海:Google协议缓冲区,Apache Thrift,Apache Avro,CBOR这些库的前三个要求对对象进行序列化以描述其数据模式。CBOR非常低级,它只能序列化标量值及其集合。我们需要的是一个Java序列化库,该库“没有问太多问题”,并且不强制将可序列化对象“手动分类为原子”。我们想序列化任意Java对象,而实际上不了解它们,因此我们希望尽快进行。因此,我们组织了一场争夺Java序列化问题的可用开源解决方案的竞赛。
竞争者
在竞赛中,我们选择了最受欢迎的Java序列化库(主要使用二进制格式)以及在其他 Java序列化审核中运行良好的库。开始了!种族
速度是评估即兴比赛参与者Java序列化库的主要标准。为了客观地评估哪个序列化库更快,我们从系统日志中获取真实数据,并从它们中组合合成会话数据,这些数据的长度从0到1 MB 不等。数据格式为字符串和字节数组。注意:展望未来,应该说赢家和输家已经出现在0到10 KB的可序列化对象的大小上。对象大小进一步增加到1 MB并没有改变比赛的结果。
在这方面,为了更好地说明,以下Java序列化器性能的图表受到10 KB对象大小的限制。
, :: , IBM JRE One Nio ( 13 14). sun.reflect.MagicAccessorImpl private final ( ) , . , IBM JRE sun.reflect.MagicAccessorImpl, , runtime .
(, Serialization-FAQ, One Nio ), fork , sun.reflect.MagicAccessorImpl . sun.reflect.MagicAccessorImpl fork- sun.misc.Unsafe .
另外,在我们的分支中,对字符串的序列化进行了优化-使用IBM JRE时,字符串的序列化开始速度提高了30-40%。
因此,在本出版物中,One Nio库的所有结果都是通过我们自己的叉子获得的,而不是在原始库中获得的。
串行化/反序列化速度的直接测量是使用Java Microbenchmark Harness(JMH)进行的,该工具来自OpenJDK,用于构建和运行基准测试。对于每次测量(图形上的一个点),使用5秒钟“预热” JVM,另外5秒钟用于时间测量本身,然后取平均值。UPD:没有一些细节的JMH基准代码public class SerializationPerformanceBenchmark {
@State( Scope.Benchmark )
public static class Parameters {
@Param( {
"Java standard",
"Jackson default",
"Jackson system",
"JacksonSmile default",
"JacksonSmile system",
"Bson4Jackson default",
"Bson4Jackson system",
"Bson MongoDb",
"Kryo default",
"Kryo unsafe",
"FST default",
"FST unsafe",
"One-Nio default",
"One-Nio for persist"
} )
public String serializer;
public Serializer serializerInstance;
@Param( { "0", "100", "200", "300", /*... */ "1000000" } )
public int sizeOfDto;
public Object dtoInstance;
public byte[] serializedDto;
@Setup( Level.Trial )
public void setup() throws IOException {
serializerInstance = Serializers.getMap().get( serializer );
dtoInstance = DtoFactory.createWorkflowDto( sizeOfDto );
serializedDto = serializerInstance.serialize( dtoInstance );
}
@TearDown( Level.Trial )
public void tearDown() {
serializerInstance = null;
dtoInstance = null;
serializedDto = null;
}
}
@Benchmark
public byte[] serialization( Parameters parameters ) throws IOException {
return parameters.serializerInstance.serialize(
parameters.dtoInstance );
}
@Benchmark
public Object unserialization( Parameters parameters ) throws IOException, ClassNotFoundException {
return parameters.serializerInstance.deserialize(
parameters.serializedDto,
parameters.dtoInstance.getClass() );
}
}
这是发生的事情:
首先,我们注意到,将其他元数据添加到序列化结果中的库选项比相同库的默认配置要慢(请参阅“使用类型”和“用于持久”配置)。
通常,无论配置如何,根据序列化的结果淘汰的Jackson JSON和Bson4Jackson都会成为局外人。
此外,基于反序列化结果,Java Standard退出了竞争,因为对于任何大小的可序列化数据,反序列化都比竞争对手慢得多。
仔细看看其余的参与者:
根据序列化的结果,FST库充满信心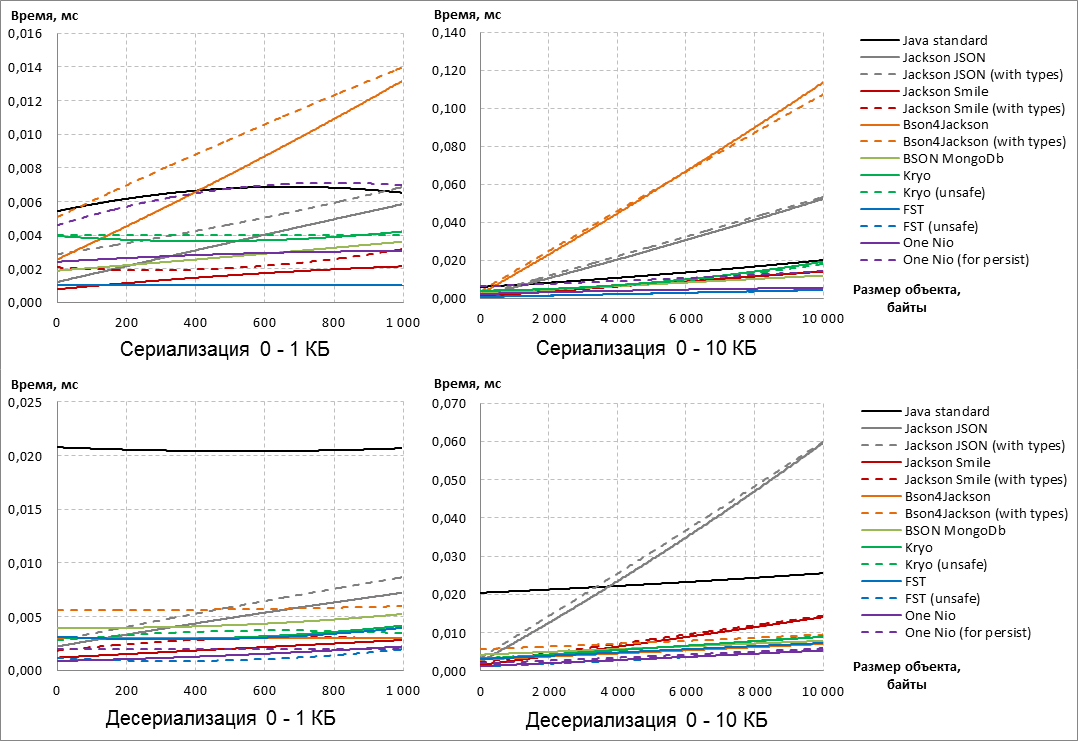
 并且随着对象尺寸的增加,One Nio会 “ 踩她的脚跟” 。请注意,对于One Nio, “ forpersist”选项比序列化速度的默认配置慢得多。如果您查看反序列化,我们会发现One Nio能够随着数据量的增加而超过FST。相反,在后者中,非标准配置“不安全”执行反序列化的速度要快得多。为了将所有要点放在AND上,让我们看一下序列化和反序列化的总结果:
很明显,有两个明确的领导者:FST(不安全)和One Nio。
如果在小物体上FST(不安全)
并且随着对象尺寸的增加,One Nio会 “ 踩她的脚跟” 。请注意,对于One Nio, “ forpersist”选项比序列化速度的默认配置慢得多。如果您查看反序列化,我们会发现One Nio能够随着数据量的增加而超过FST。相反,在后者中,非标准配置“不安全”执行反序列化的速度要快得多。为了将所有要点放在AND上,让我们看一下序列化和反序列化的总结果:
很明显,有两个明确的领导者:FST(不安全)和One Nio。
如果在小物体上FST(不安全)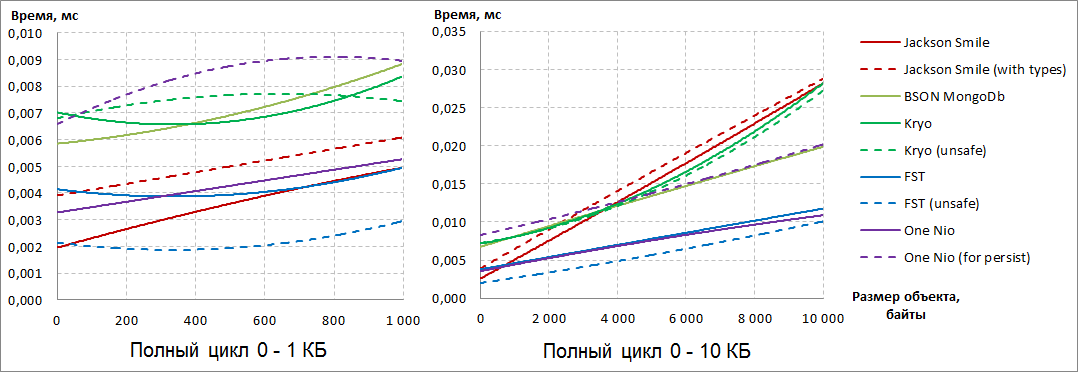 自信地领导,然后随着可序列化对象大小的增加,他开始认输,并最终落后于One Nio。BSON MongoDb自信地将可序列化对象的大小增加到第三位,尽管它领先领先者将近两倍。
自信地领导,然后随着可序列化对象大小的增加,他开始认输,并最终落后于One Nio。BSON MongoDb自信地将可序列化对象的大小增加到第三位,尽管它领先领先者将近两倍。称量
序列化结果的大小是评估Java序列化库的第二个最重要的标准。从某种意义上说,序列化/反序列化的速度取决于结果的大小:形成和处理紧凑的结果要比批量结果更快。为了“加权”序列化的结果,使用了所有相同的Java对象,它们是从系统日志(字符串和字节数组)中获取的真实数据组成的。此外,序列化结果的重要属性还在于压缩后压缩的程度(例如,将其保存在数据库或其他存储中)。在我们的比赛中,我们使用了Deflate压缩算法,它是ZIP和gzip的基础。“称量”的结果如下: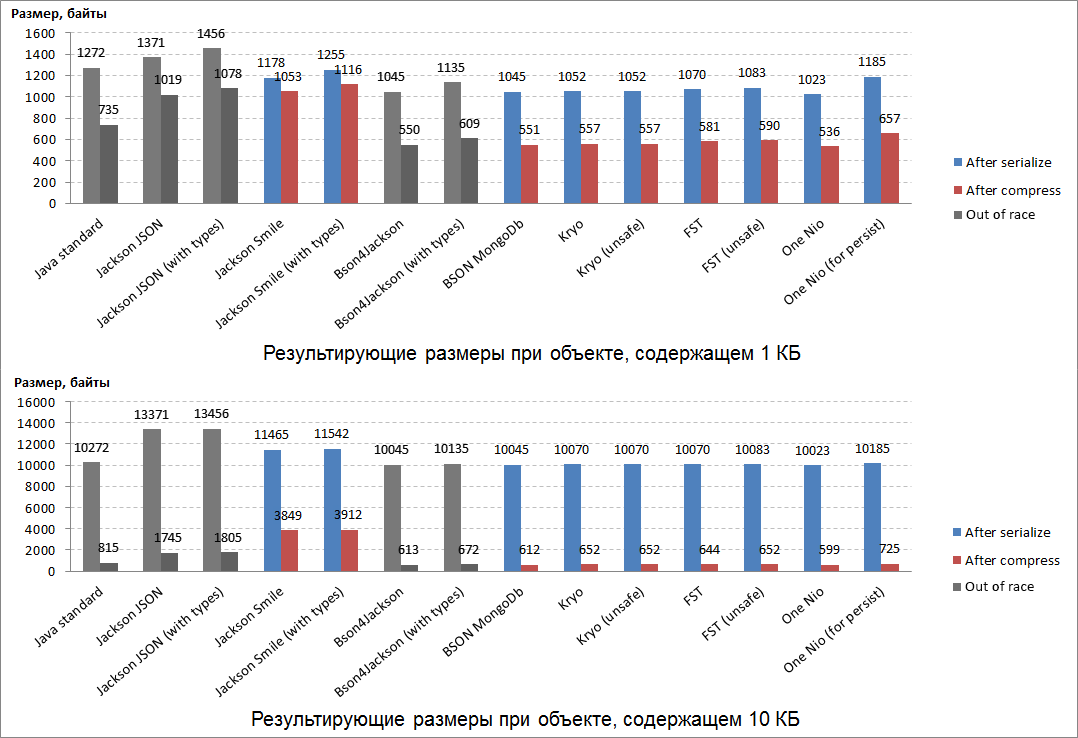 可以预期,最紧凑的结果是该赛事的其中一位领先者之一:One Nio。紧凑度排名第二的是BSON MongoDb (在比赛中排名第三)。就紧凑性而言,排在第三位的Kryo库“逃脱了” ,该库以前未能在比赛中证明自己。这三个“ weighing”前导的序列化结果也得到了完美压缩(几乎两个)。事实证明,它是最不可压缩的:JSON的二进制等效项是Smile和JSON本身。一个奇怪的事实-序列化过程中“权衡”的所有赢家都将相同数量的服务数据添加到小型和大型可序列化对象中。
可以预期,最紧凑的结果是该赛事的其中一位领先者之一:One Nio。紧凑度排名第二的是BSON MongoDb (在比赛中排名第三)。就紧凑性而言,排在第三位的Kryo库“逃脱了” ,该库以前未能在比赛中证明自己。这三个“ weighing”前导的序列化结果也得到了完美压缩(几乎两个)。事实证明,它是最不可压缩的:JSON的二进制等效项是Smile和JSON本身。一个奇怪的事实-序列化过程中“权衡”的所有赢家都将相同数量的服务数据添加到小型和大型可序列化对象中。灵活性
在做出负责任的选择获奖者决定之前,我们决定彻底检查每个序列化器的灵活性及其可用性。为此,我们编制了20条评估参加比赛的序列化器的标准,以使“没有一只鼠标滑过”我们的眼睛。
带说明的脚注1 LinkedHashMap.
2 — , — .
3 — , — .
4 sun.reflect.MagicAccessorImpl — : boxing/unboxing, BigInteger/BigDecimal/String. MagicAccessorImpl ( ' fork One Nio) — .
5 ArrayList.
6 ArrayList HashSet .
7 HashMap.
8 — , , /Map-, ( HashMap).
9 -.
10 One Nio — , ' fork- — .
11 .
UPD:根据第13条标准,One Nio(表示坚持)获得了另一分(第19条)。这种细致的“申请人审查”也许是我们“播报”中最耗时的阶段。但是随后这些比较结果很好地打开了使用序列化库的便利。因此,您可以将这些结果用作参考。意识到真是遗憾,但我们的领导人根据比赛和称量的结果 -FST(不安全)和 One Nio-事实证明在灵活性方面是局外人...但是,我们对一个奇怪的事实感兴趣:在持久性方面的配置(不是最快的,也不是最紧凑的)中的一个Nio在灵活性方面得分最高-19/20。灵活地进行默认(快速而紧凑)One Nio配置工作的机会看起来也很有吸引力-并且有一种方法。一开始,当我们向参与者介绍比赛时,据说序列化结果中包含的One Nio(表示持久性)详细说明了有关可序列化Java对象类的元信息。(*)。使用此元信息进行反序列化,One Nio库确切地知道序列化时可序列化对象的类是什么样。基于此知识,One Nio反序列化算法是如此灵活,以至于它提供了序列化所带来的最大兼容性byte[]。事实证明,可以为指定的类分别获取元信息(*),将其序列化 byte[] 并发送到将反序列化该类的Java对象的一侧:逐步执行代码...
one.nio.serial.Serializer<SomeDto> dtoSerializerWithMeta = Repository.get( SomeDto.class );
byte[] dtoMeta = serializeByDefaultOneNioAlgorithm( dtoSerializerWithMeta );
// №1: dtoMeta №2
one.nio.serial.Serializer<SomeDto> dtoSerializerWithMeta = deserializeByOneNio( dtoMeta );
Repository.provideSerializer( dtoSerializerWithMeta );
byte[] bytes1 = serializeByDefaultOneNioAlgorithm( object1 );
byte[] bytes2 = serializeByDefaultOneNioAlgorithm( object2 );
...
SomeDto object1 = deserializeByOneNio( bytes1 );
SomeDto object2 = deserializeByOneNio( bytes2 );
...
如果执行此显式过程以在分布式服务之间交换有关类的元信息,则这些服务将能够使用默认的(快速而紧凑的)One Nio配置相互发送序列化的Java对象。毕竟,在服务运行时,它们两侧的类的版本保持不变,这意味着在每次交互过程中都无需在每个序列化结果中“来回拖动”常量元信息。因此,在开始时做了一些更多的操作,然后您可以同时使用One Nio的速度和紧凑性以及One Nio的灵活性(表示持久性)。确实需要什么!因此,为了以序列化的形式在分布式服务之间传输Java对象(这就是我们组织这次竞赛的目的) 一个Nio是灵活性的赢家 (19/20)。在较早在赛车和称重方面出类拔萃的Java序列化程序中,展示了不错的灵活性:- BSON MongoDb (14.5 / 20),
- 克里奥(13/20)。
基座
回顾一下过去的Java序列化竞赛的结果:- 在比赛中,评分的前两行分别由FST(不安全)和One Nio划分,BSON MongoDb排名第三,
- 一个Nio击败了称重区,然后是BSON MongoDb和Kryo,
- 在灵活性方面,仅出于我们在分布式应用程序之间交换会话上下文的任务,One Nio再次获得了第一名 ,而BSON MongoDb和Kryo表现出色。
因此,就所获得的结果的整体而言,我们获得的基座如下:- 一个Nio
在主要比赛中(种族)与FST(不安全)并列第一,但在衡量和测试灵活性方面却大大压倒了竞争对手。 - FST(不安全)
也是一个非常快速的Java序列化库,但是,它缺少序列化导致的字节数组的直接和向后兼容性。 - BSON MongoDB + Kryo
2 3- Java-, . 2- , . Collection Map, BSON MongoDB custom- / (Externalizable ..).
在Sberbank的会话数据服务中,我们使用了One Nio库,该库在我们的竞争中赢得了第一名。使用该库,Java会话上下文数据被序列化并在应用程序之间传输。由于此修订,会话传输的速度提高了数倍。负载测试表明,在接近Sberbank Online用户实际行为的情况下,仅由于这一改进,就可获得高达40%的加速。这样的结果意味着减少了系统对用户动作的响应时间,从而增加了客户的满意度。在下一篇文章中,我将尝试在实践中演示One Nio的附加加速从使用类派生的sun.reflect.MagicAccessorImpl。不幸的是,IBM JRE不支持该类的最重要属性,这意味着One Nio在此JRE版本上的全部潜力尚未显现。未完待续。