在本文中,我将讨论一些简单的技巧,这些技巧在处理不适合本地计算机但仍然太小而不能称为大数据的数据时很有用。按照英语的类比(大但不大),我们称此数据为厚数据。我们正在谈论的单位大小和数十GB。[免责声明]如果您喜欢SQL,那么下面编写的所有内容都可能使您产生强烈的,很可能是负面的情绪,在荷兰,特斯拉有49262辆特斯拉,其中427辆是出租车,最好不要再读[/免责声明]。 起点是轮毂上的一篇文章,其中描述了一个有趣的数据集-在荷兰注册的车辆的完整列表,1400万行,从卡车牵引车到时速超过25 km / h的电动自行车,应有尽有。该套件很有趣,需要7 GB,您可以将其下载到负责组织的网站上。试图驱动大熊猫中的数据进行过滤和清理的尝试以惨败告终(我警告过SQL轻骑兵的绅士们!)。熊猫因桌面8 GB的内存不足而跌落。稍加流血,如果您回想起熊猫可以读取中等大小的csv文件,就可以解决问题。行中的片段大小由chunksize参数确定。为了说明这项工作,我们将编写一个简单的函数来发出请求,并确定总共有多少辆特斯拉汽车,以及其中有多少比例在出租车上工作。没有片段读取的技巧,这样的请求首先会耗尽所有内存,然后遭受很长一段时间,最后斜坡下降。通过片段读取,我们的函数将如下所示:
起点是轮毂上的一篇文章,其中描述了一个有趣的数据集-在荷兰注册的车辆的完整列表,1400万行,从卡车牵引车到时速超过25 km / h的电动自行车,应有尽有。该套件很有趣,需要7 GB,您可以将其下载到负责组织的网站上。试图驱动大熊猫中的数据进行过滤和清理的尝试以惨败告终(我警告过SQL轻骑兵的绅士们!)。熊猫因桌面8 GB的内存不足而跌落。稍加流血,如果您回想起熊猫可以读取中等大小的csv文件,就可以解决问题。行中的片段大小由chunksize参数确定。为了说明这项工作,我们将编写一个简单的函数来发出请求,并确定总共有多少辆特斯拉汽车,以及其中有多少比例在出租车上工作。没有片段读取的技巧,这样的请求首先会耗尽所有内存,然后遭受很长一段时间,最后斜坡下降。通过片段读取,我们的函数将如下所示:def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
通过指定完全合理的百万行,您可以在1:46中执行查询,并在峰值时使用1965 M的内存。一个笨拙的台式机的所有数字,它具有古老的八核,约8 GB的内存,并且在第七个Windows下。
 如果更改了块大小,那么峰值内存消耗将在字面上跟随它,执行时间不会有太大变化。对于50万行,请求占用1:44和1063 MB,对于2M 1:53和3762 MB。速度不是很令人满意,更令人讨厌的是,读取片段中的文件会迫使您编写适合该功能的文件,并处理必须在数据帧中收集的片段列表。另外,csv格式本身也不是很令人满意,它占用了大量空间并被缓慢读取。由于我们可以将数据驱动到斜坡上,因此可以使用更紧凑的Apachev格式进行存储具有压缩功能的拼花地板,而且由于采用了数据方案,因此读取时读取速度要快得多。坡道非常有能力与他合作。只是现在无法阅读它们的片段。该怎么办?-让我们玩得开心,拿起Dask
如果更改了块大小,那么峰值内存消耗将在字面上跟随它,执行时间不会有太大变化。对于50万行,请求占用1:44和1063 MB,对于2M 1:53和3762 MB。速度不是很令人满意,更令人讨厌的是,读取片段中的文件会迫使您编写适合该功能的文件,并处理必须在数据帧中收集的片段列表。另外,csv格式本身也不是很令人满意,它占用了大量空间并被缓慢读取。由于我们可以将数据驱动到斜坡上,因此可以使用更紧凑的Apachev格式进行存储具有压缩功能的拼花地板,而且由于采用了数据方案,因此读取时读取速度要快得多。坡道非常有能力与他合作。只是现在无法阅读它们的片段。该怎么办?-让我们玩得开心,拿起Dask 按钮手风琴,加快速度!快点开箱即用的替代产品,能够读取大型文件,能够在多个内核上并行工作,并使用惰性计算。令我惊讶的是,哈斯(Dabr)上的达斯克(Dask)只有4种出版物。因此,我们花了很多时间,将原始的csv驱动到其中,并以最少的转换将其驱动到地面。阅读时,dask会发誓某些列中的数据类型会含混不清,因此我们对其进行了明确设置(为清楚起见,对坡道进行了同样的操作,考虑到该因素,运行时间更长,所有为清楚起见而对dtypes的字典都进行了删节),其余的则是他本人。此外,为了进行验证,我们在地板上做了一些小的改进,即我们尝试将数据类型减少到最紧凑的类型,用布尔值将文本为yes / no的一对列替换为布尔值,然后将其他数据转换为最经济的类型(对于发动机气缸数,uint8绝对足够)。我们单独保存优化地板,然后看看会得到什么。使用Dask时,首先要取悦的是,我们不必仅仅因为我们拥有大量数据而编写任何多余的东西。如果您不注意导入了dask而不是导入渐变的事实,那么一切看起来都与处理在渐变中包含一百行的文件(加上几个用于轮廓分析的装饰哨子)相同。def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
现在,比较使用dasko时源文件对性能的影响。首先,我们读取与使用渐变时相同的csv文件。大约两分钟和两个千兆字节的内存(1:38 2096 Mb)相同。似乎,在灌木丛中亲吻是否值得?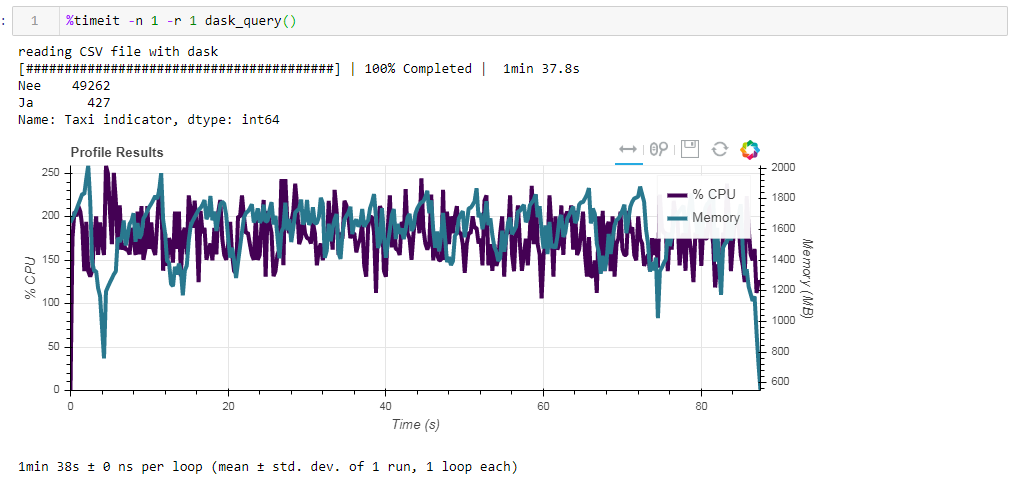 现在,将板未优化的实木复合地板文件送入。该请求在大约54秒内得到处理,消耗了1388 MB的内存,并且该请求的文件本身现在小了10倍(大约700 MB)。在这里,奖金已经凸出可见。数百%的CPU使用率是跨多个内核的并行化。
现在,将板未优化的实木复合地板文件送入。该请求在大约54秒内得到处理,消耗了1388 MB的内存,并且该请求的文件本身现在小了10倍(大约700 MB)。在这里,奖金已经凸出可见。数百%的CPU使用率是跨多个内核的并行化。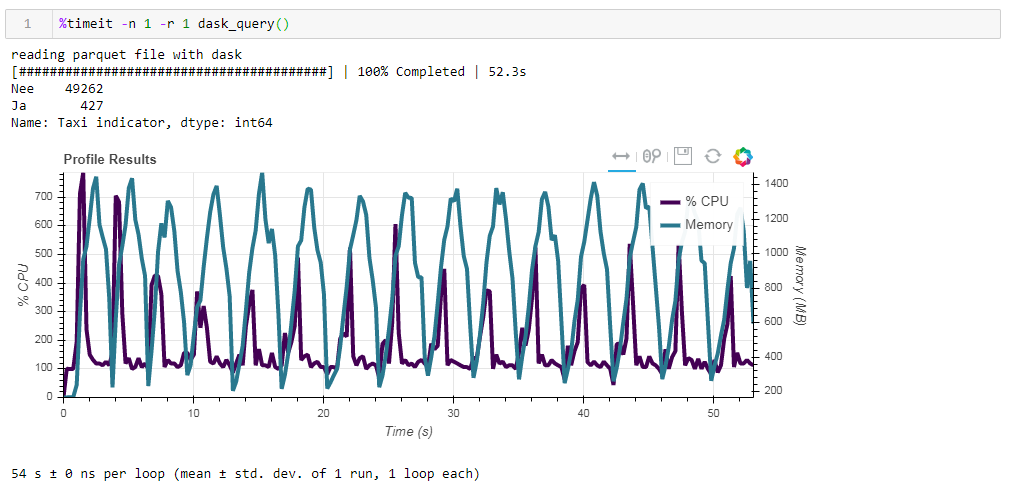 之前经过优化的镶木地板,其压缩格式的数据类型略有修改,仅减少了1 MB,这意味着在没有提示的情况下,所有内容都得到了非常有效的压缩。生产率的提高也不是特别重要。该请求将花费相同的53秒,并且占用更少的内存-1332 MB。根据我们的练习结果,我们可以说以下内容:
之前经过优化的镶木地板,其压缩格式的数据类型略有修改,仅减少了1 MB,这意味着在没有提示的情况下,所有内容都得到了非常有效的压缩。生产率的提高也不是特别重要。该请求将花费相同的53秒,并且占用更少的内存-1332 MB。根据我们的练习结果,我们可以说以下内容:- 如果您的数据是“胖”的,并且您习惯了渐变-块大小将帮助渐变来消化该体积,那么速度是可以承受的。
- 如果您想提高速度,在存储过程中节省空间,而又不仅仅使用斜坡,那么黄昏与镶木地板是一个很好的组合。
最后,关于延迟计算。 dask的功能之一是它使用惰性计算,也就是说,并不像在代码中那样立即执行计算,而是在真正需要它们时或使用compute方法明确请求时才执行。例如,在我们的函数中,当我们指示读取文件时,dask不会将所有数据读取到内存中。他稍后再阅读它们,并且仅阅读与请求相关的那些列。在下面的示例中很容易看出这一点。我们使用一个预先过滤的文件,在该文件中,我们从最初的64个记录中只保留了12列,压缩后的镶木花了203 MB。如果您对它执行常规请求,则该请求将在8.8秒内完成,并且峰值内存使用量将约为300 MB,如果在简单的csv中超过压缩文件的十分之一,则该峰值将占压缩文件的十分之一。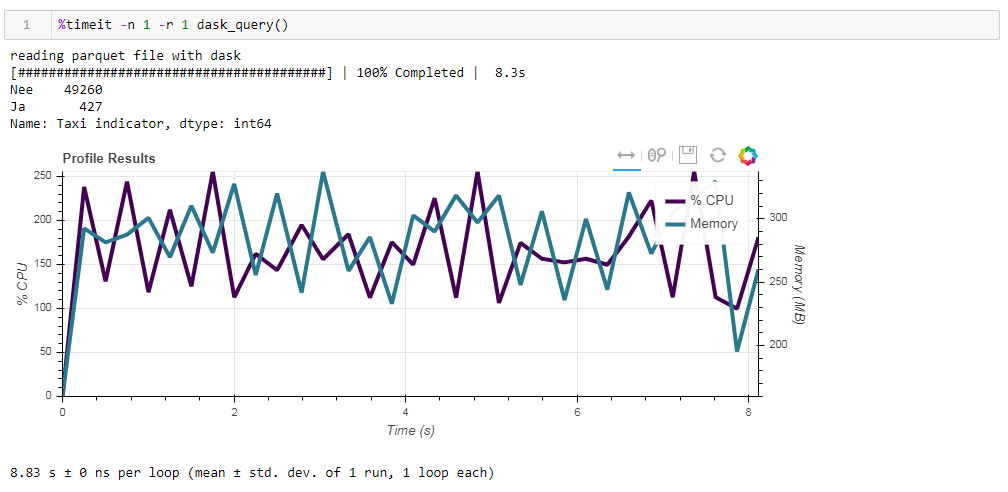 如果我们明确要求您读取文件,然后执行请求,则内存消耗将增加近10倍。我们通过显式读取文件来稍微修改函数:
如果我们明确要求您读取文件,然后执行请求,则内存消耗将增加近10倍。我们通过显式读取文件来稍微修改函数:def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
这就是我们所得到的10.5秒和3568 MB的内存(!)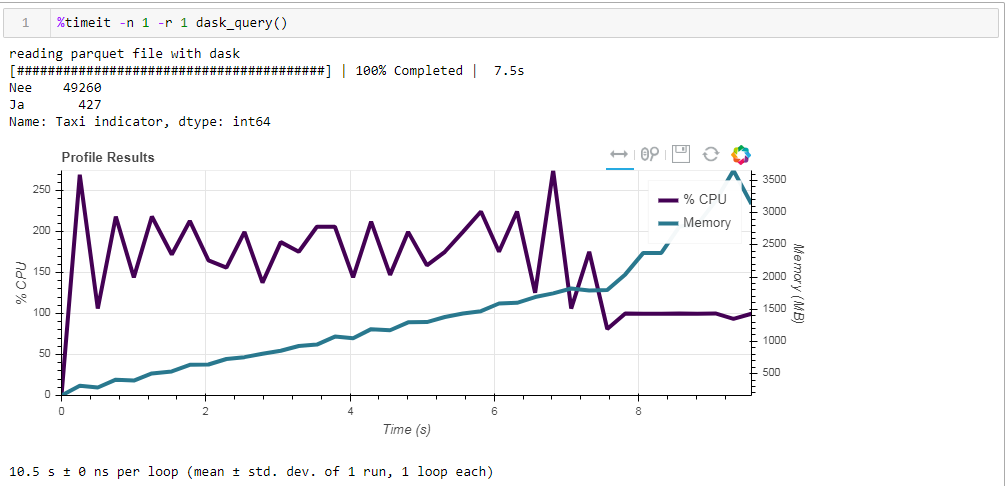 。我们再次确信,敏捷-它能胜任其任务,并且不值得再次进行微管理。
。我们再次确信,敏捷-它能胜任其任务,并且不值得再次进行微管理。