在本文中,我将告诉您如何在30分钟内设置机器学习环境,创建用于图像识别的神经网络,然后在图形处理单元(GPU)上运行相同的网络。首先,让我们定义什么是神经网络。在我们的案例中,这是一个数学模型及其软件或硬件实现,建立在生物神经网络(活生物体神经细胞网络)的组织和功能原理之上。这个概念产生于研究大脑中发生的过程,并试图模拟这些过程。神经网络不是按照通常的含义编程的,而是经过训练的。与传统算法相比,学习能力是神经网络的主要优势之一。从技术上讲,训练在于找到神经元之间的连接系数。在学习过程中,神经网络能够识别输入和输出之间的复杂关系,并进行概括。从机器学习的角度来看,神经网络是模式识别方法,判别分析,聚类方法和其他方法的特例。设备
首先,让我们处理设备。我们需要一台装有Linux操作系统的服务器。用于机器学习系统的操作的设备需要足够强大并且因此很昂贵。对于那些没有好的汽车的人,我建议您注意云提供商的服务。可以快速租用必要的服务器,并且只需为使用时间付费。在需要创建神经网络的项目中,我使用俄罗斯一家云提供商的服务器。该公司通过NVIDIA提供的强大的Tesla V100图形处理单元(GPU)提供专门用于机器学习的租赁云服务器。简而言之:与具有类似成本并且使用CPU(众所周知的中央处理器)的服务器相比,将具有GPU的服务器使用起来效率(速度)提高数十倍。这是由于GPU架构的细节而实现的,它可以更快地处理计算。为了执行以下示例,我们花了几天时间购买了以下服务器:- 150 GB固态硬盘
- 内存32 GB
- 具有4核的Tesla V100 16 Gb处理器
Ubuntu 18.04已安装在计算机上。设置环境
现在,在服务器上安装您需要工作的所有内容。由于我们的文章主要是针对初学者的,因此我将在其中讨论一些对他们有用的观点。设置环境时,许多工作都是通过命令行完成的。大多数用户将Windows用作工作操作系统。这个操作系统中的标准控制台还有很多不足之处。因此,我们将使用方便的Cmder /工具。下载迷你版本并运行Cmder.exe。接下来,您需要通过SSH连接到服务器:ssh root@server-ip-or-hostname
指定服务器的IP地址或DNS名称而不是server-ip-or-hostname。接下来,输入密码,成功连接后,我们应该会得到类似的信息。Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
开发ML模型的主要语言是Python。在Linux上使用它的最受欢迎的平台是Anaconda。将其安装在我们的服务器上。我们首先更新本地软件包管理器:sudo apt-get update
安装curl(命令行实用程序):sudo apt-get install curl
下载最新版本的Anaconda发行版:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
我们开始安装:bash Anaconda3-2019.10-Linux-x86_64.sh
在安装过程中,您需要确认许可协议。成功安装后,您应该会看到以下内容:Thank you for installing Anaconda3!
为了开发ML模型,现在创建了许多框架,我们使用最受欢迎的框架:PyTorch和Tensorflow。使用该框架可以提高开发速度,并可以将现成的工具用于标准任务。在此示例中,我们将使用PyTorch。安装它:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
现在我们需要启动Jupyter Notebook-ML专家中流行的开发工具。它允许您编写代码并立即查看其执行结果。Jupyter Notebook是Anaconda的一部分,已经安装在我们的服务器上。您需要从我们的桌面系统连接到它。为此,我们首先通过指定端口8080在服务器上运行Jupyter:jupyter notebook --no-browser --port=8080 --allow-root
接下来,在我们的Cmder控制台中打开另一个选项卡(顶部菜单是“新建”控制台对话框),通过SSH将端口8080连接到服务器:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
当您输入第一个命令时,将为我们提供在浏览器中打开Jupyter的链接:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
使用本地主机的链接:8080。复制完整路径,然后粘贴到PC本地浏览器的地址栏中。Jupyter笔记本打开。让我们创建一个新的笔记本电脑:新建-笔记本电脑-Python 3.检查我们安装的所有组件的正确操作。我们在Jupyter中引入了一个PyTorch代码示例,并开始执行(运行按钮):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
结果应该是这样的: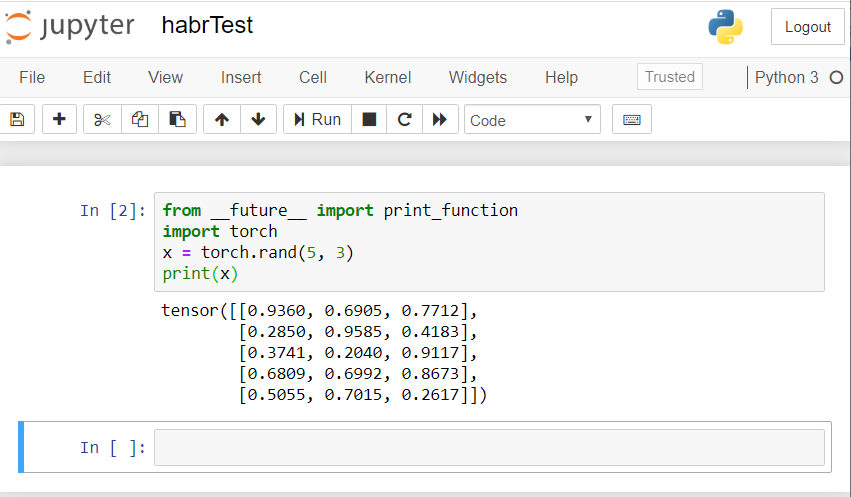 如果您有类似的结果,那么我们所有人都正确设置了,就可以开始开发神经网络了!
如果您有类似的结果,那么我们所有人都正确设置了,就可以开始开发神经网络了!创建一个神经网络
我们将创建一个用于图像识别的神经网络。我们以本指南为基础。为了训练网络,我们将使用公共可用的CIFAR10数据集。他上过课:“飞机”,“汽车”,“鸟”,“猫”,“鹿”,“狗”,“青蛙”,“马”,“船”,“卡车”。CIFAR10中的图像尺寸为3x32x32,即32x32像素的3通道彩色图像。对于工作,我们将使用创建的PyTorch软件包来处理图像-torchvision。我们将按以下步骤进行操作:- 下载并标准化培训和测试数据集
- 神经网络定义
- 培训数据网络培训
- 使用测试数据测试网络
- 重复进行GPU培训和测试
下面的所有代码我们都将在Jupyter Notebook中执行。下载并标准化CIFAR10
在Jupyter中复制并执行以下代码:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
答案应该是这样的:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
我们将导出几个训练图像进行检查:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

神经网络定义
让我们首先检查一下用于图像识别的神经网络如何工作。这是一个简单的直接连接网络。它获取输入,将其一层一层地传递给多层,然后最终给出输出。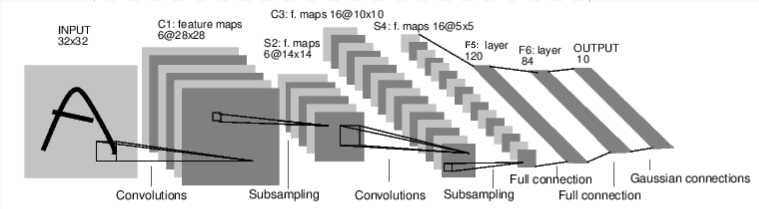 让我们在环境中创建一个类似的网络:
让我们在环境中创建一个类似的网络:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
我们还定义了损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
培训数据网络培训
我们开始训练我们的神经网络。我提请您注意,在此之后,在运行此代码时,您将需要等待一段时间才能完成工作。我花了5分钟。联网需要时间。 for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
我们得到以下结果:我们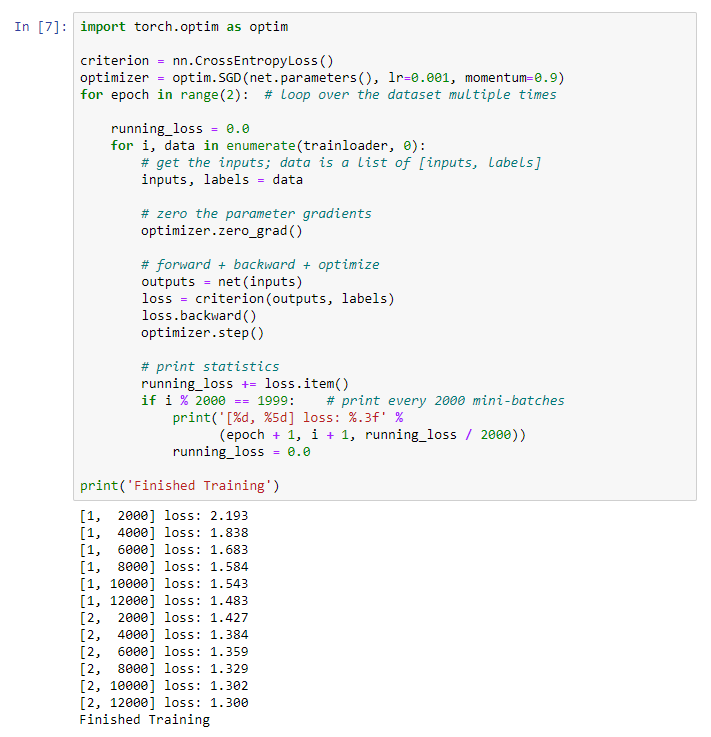 保存训练有素的模型:
保存训练有素的模型:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
使用测试数据测试网络
我们使用了一组训练数据来训练网络。但是我们需要检查网络是否学到了什么。我们将通过预测神经网络输出的类别标签并检查真相来验证这一点。如果预测正确,则将样本添加到正确预测列表中。让我们显示测试套件中的图像:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 现在让神经网络告诉我们这些图片是什么:
现在让神经网络告诉我们这些图片是什么:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
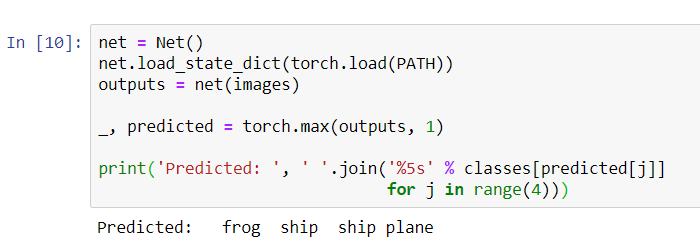 结果似乎还不错:网络正确识别了四张图片中的三张。让我们看看网络如何在整个数据集中工作。
结果似乎还不错:网络正确识别了四张图片中的三张。让我们看看网络如何在整个数据集中工作。
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
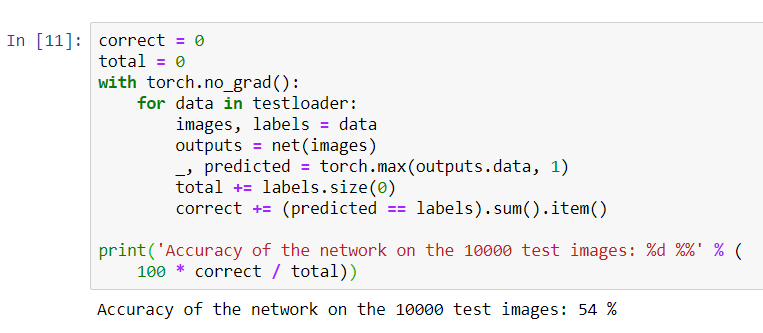 看起来网络知道并且可以正常工作。如果他随机定义班级,那么准确性将是10%。现在,让我们看看网络定义的更好的类:
看起来网络知道并且可以正常工作。如果他随机定义班级,那么准确性将是10%。现在,让我们看看网络定义的更好的类:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
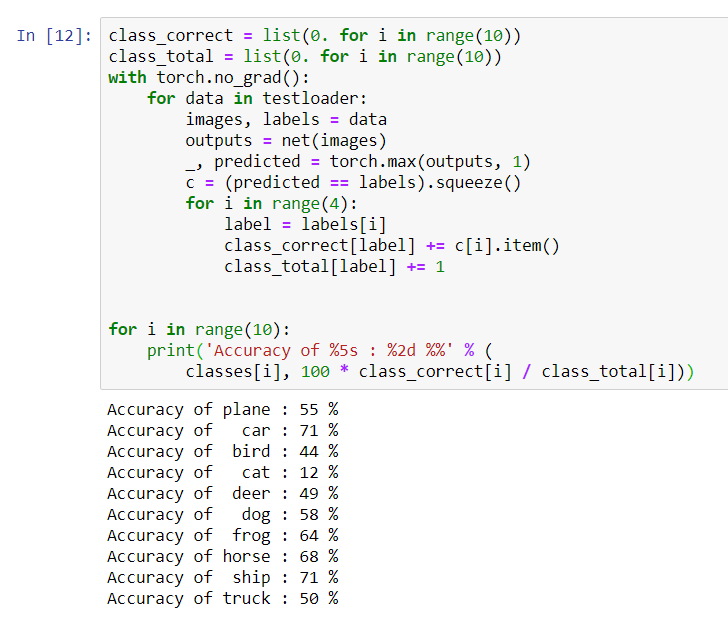 该网络似乎确定了汽车和船舶的最佳状态:准确性为71%。因此网络正在运行。现在,让我们尝试将其工作转移到图形处理器(GPU),看看有什么变化。
该网络似乎确定了汽车和船舶的最佳状态:准确性为71%。因此网络正在运行。现在,让我们尝试将其工作转移到图形处理器(GPU),看看有什么变化。GPU神经网络训练
首先,我将简要说明什么是CUDA。CUDA(计算统一设备体系结构)是NVIDIA开发的一种并行计算平台,用于GPU上的常规计算。借助CUDA,开发人员可以使用GPU的功能极大地加速计算应用程序。在我们购买的服务器上,已经安装了该平台。首先让我们将GPU定义为第一个可见的cuda设备。device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 将网络发送到GPU:
将网络发送到GPU:net.to(device)
我们还必须在每一步将输入和目标发送到GPU:inputs, labels = data[0].to(device), data[1].to(device)
在GPU上运行网络重新训练:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
这次,网络培训持续了大约3分钟。回想一下,在常规处理器上的同一阶段持续了5分钟。差异不大,这是因为我们的网络不是很大。当使用大型阵列进行训练时,GPU和传统处理器之间的速度差异将增大。好像就这些了。我们设法做到的:- 我们检查了GPU是什么,并选择了安装GPU的服务器;
- 我们建立了一个用于创建神经网络的软件环境;
- 我们创建了一个用于图像识别的神经网络并对其进行了训练。
- 我们使用GPU重复了网络训练,并提高了速度。
我很高兴在评论中回答问题。