我经常遇到这样一种情况,许多开发人员真诚地认为PostgreSQL中的索引是一把瑞士刀,可以普遍帮助解决任何查询性能问题。在表中添加一些新索引或将字段包含在现有索引中的某处就足够了,然后(magic-magic!)所有查询将有效地使用此索引。 首先,当然,它们要么不会,要么效率不高,或者不是全部。其次,额外的索引只会在编写时增加性能问题。大多数情况下,这种情况发生在“长期”开发过程中,即不是根据“一次写完,放弃,忘了”模型来制作定制产品,而是按照我们的情况创建使用寿命长的服务。许多分布式团队的力量不断地进行改进,这些团队不仅在空间上而且在时间上都分布。然后,不知道项目开发的整个历史或数据库中数据的实际应用分布的特征,就可以轻松地“索引”索引。但是考虑到削减因素和测试要求,您可以提前预测和发现部分问题:
首先,当然,它们要么不会,要么效率不高,或者不是全部。其次,额外的索引只会在编写时增加性能问题。大多数情况下,这种情况发生在“长期”开发过程中,即不是根据“一次写完,放弃,忘了”模型来制作定制产品,而是按照我们的情况创建使用寿命长的服务。许多分布式团队的力量不断地进行改进,这些团队不仅在空间上而且在时间上都分布。然后,不知道项目开发的整个历史或数据库中数据的实际应用分布的特征,就可以轻松地“索引”索引。但是考虑到削减因素和测试要求,您可以提前预测和发现部分问题:- 未使用的索引
- 前缀“克隆”
- 时间戳“在中间”
- 可索引的布尔值
- 索引中的数组
- 空垃圾
最简单的事情是找到根本没有通过的索引。您只需要确保统计信息(pg_stat_reset())重置是在很久以前发生的,并且您不想删除已使用的“很少但适当的”密码。我们使用系统视图pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
但是,即使使用了索引并且没有将其归入此选择,这也并不意味着它完全适合您的查询。什么索引[不适合]
为了理解为什么某些查询“对索引不利”,我们将考虑常规btree索引的结构,这是自然界中最常见的实例。来自单个字段的索引通常不会产生任何问题,因此,我们考虑在一对字段的组合中出现的问题。可以想象到,一种极其简化的方式是一个``分层蛋糕'',其中在每一层中根据相应字段的值依次排序树。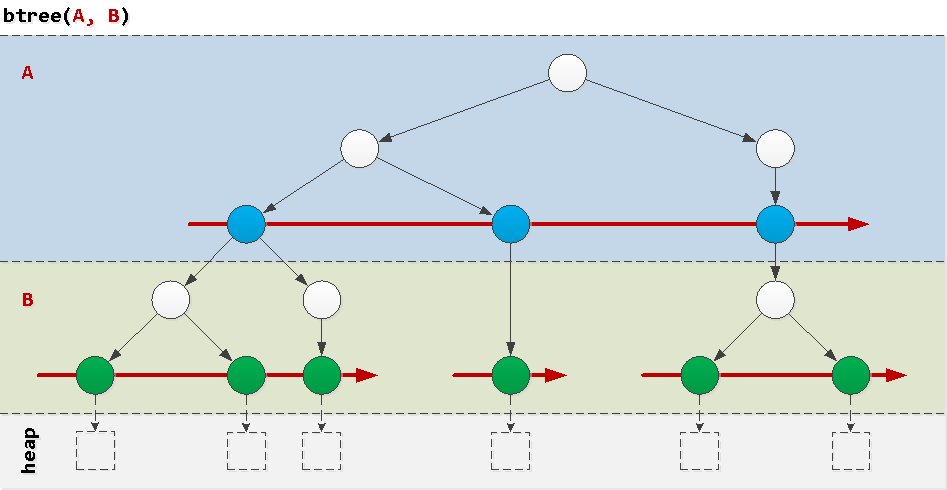 现在很明显,字段A全局排序,并且B-仅在特定值A内。让我们看一下实际查询中发生的条件的示例,以及它们如何“遍历”索引。
现在很明显,字段A全局排序,并且B-仅在特定值A内。让我们看一下实际查询中发生的条件的示例,以及它们如何“遍历”索引。良好:前缀条件
注意,索引btree(A, B)包括“ subindex” btree(A)。这意味着下面描述的所有规则将适用于任何前缀索引。也就是说,如果您创建的索引比我们的示例中的索引更为复杂,则可以使用某种类型的索引btree(A, B, C)-您可以假定数据库自动“出现”:btree(A, B, C)btree(A, B)btree(A)
这意味着在大多数情况下,数据库中前缀索引的“物理”存在是多余的。毕竟,表必须写入的索引越多-PostgreSQL就越差,因为它调用Write Amplification- Uber对此有所抱怨(在这里您可以找到对其声明的分析)。而且,如果有什么原因妨碍了基地的正常运转,那么就值得寻找并消除它。让我们看一个例子:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
前缀索引搜索查询WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
理想情况下,您应该得到一个空的选择,但是请看-这些是我们可疑的索引组:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
然后,您可以为每个组自己决定是值得删除较短的索引还是根本不需要删除较长的索引。好:除最后一个字段外的所有常量
如果索引中除最后一个字段外的所有字段的值均由常量设置(在我们的示例中为字段A),则索引可以正常使用。在这种情况下,可以任意设置最后一个字段的值:常量,不等式,间隔,通过IN (...)或拨号= ANY(...)。也可以按它排序。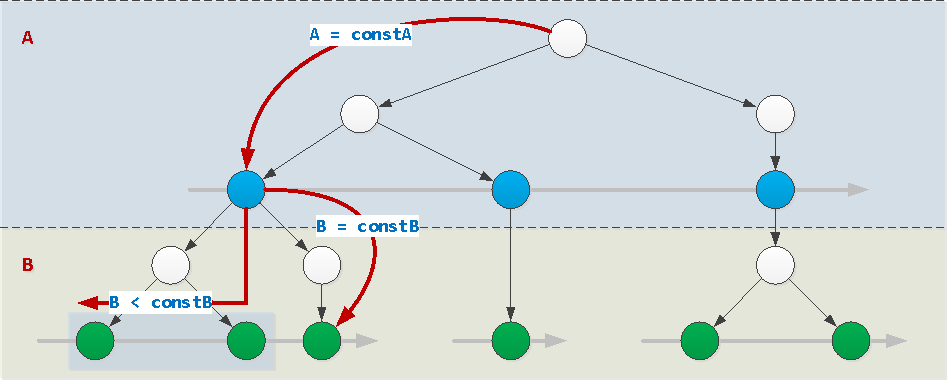
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
基于上述的前缀索引,这将很好地工作:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
坏:“层”的完整枚举
对于部分查询,索引中移动的唯一枚举将成为“层”之一中所有值的完整枚举。幸运的是,这样的值是统一的-如果有数千个..通常,如果在查询中使用不等式,条件不能确定索引顺序中先前的字段,或者在排序过程中违反了此顺序,通常会出现这样的问题。WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
错误:时间间隔或集合不在最后一个字段中
作为上一个的结果-如果您需要在某个中间``层''上找到多个值或其范围,然后按索引中``较深''的字段进行过滤或排序,则如果索引``中''的唯一值的数量为大。WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
坏:用表达式代替字段
有时,开发人员会在不知不觉中将查询中的列转换为其他内容-变成某些没有索引的表达式。可以通过从所需表达式创建索引或执行逆变换来解决此问题:WHERE A - const1 [op] const2
固定: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
固定: WHERE A = const::typeOfA
我们考虑了字段的基数
假设您需要一个索引(A, B),并且您只想通过相等来选择:(A, B) = (constA, constB)。散列索引的使用将是理想的选择,但是...除了这些版本的非索引(沃尔玛日志记录)(直到版本10)以外,它们还不能存在于以下几个字段中:CREATE INDEX ON tbl USING hash(A, B);
通常,您选择了btree。那么,什么是安排在其列的最佳方式- (A, B)或(B, A)?为了回答这个问题,有必要考虑诸如对应列中数据的基数之类的参数-即它包含多少个唯一值。让我们想象一下A = {1,2}, B = {1,2,3,4},并为这两个选项绘制索引树的轮廓: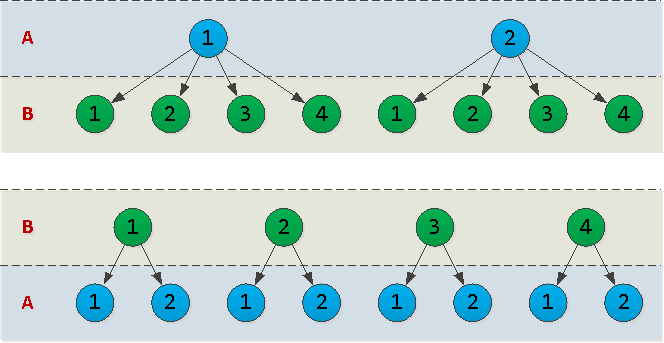 实际上,我们绘制的树中的每个节点都是索引中的一页。并且,存在的空间越多,索引将占用的磁盘空间越多,从中读取索引所花费的时间就越长。在我们的示例中,该选项
实际上,我们绘制的树中的每个节点都是索引中的一页。并且,存在的空间越多,索引将占用的磁盘空间越多,从中读取索引所花费的时间就越长。在我们的示例中,该选项(A, B)具有10个节点和(B, A)-12 个节点。也就是说,将`` 字段''具有尽可能少的唯一值放在`` 第一个''会更有利可图。不好:太多而且不合适(时间戳记在“中间”)
正是由于这个原因,如果具有明显大的可变性(例如时间戳[tz])的字段不是索引中的最后一个字段,则总是可疑的。通常,时间戳字段的值单调增加,并且以下索引字段在每个时间点仅具有一个值。CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

搜索查询非最终时间戳[tz]索引WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
在这里,我们立即分析输入字段本身的类型以及应用于它们的运算符的类型-因为某些timestamptz函数(例如date_trunc)可能变成索引字段。nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
不好:太少(布尔值)
同一枚硬币的另一面,则变成索引为boolean-field的情况,该字段只能采用3个值NULL, FALSE, TRUE。当然,如果您想将其用于应用排序(例如,通过将其指定为树层次结构中的节点类型),则它的存在是有意义的,无论它是文件夹还是叶子(“文件夹优先”)。CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
但是,在大多数情况下,情况并非如此,请求带有布尔字段的某些特定值。然后就可以用该字段的条件版本替换索引:CREATE INDEX ON tbl(id) WHERE public;
索引中的布尔搜索查询WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
btree中的数组
另一个要点是尝试使用btree索引为数组建立索引。这是完全可能的,因为相应的运算符适用于它们:(<, >, = . .) , B-, , . ( ). , , .
但是麻烦的是,将他想要的东西用于包含和交点运算符:<@, @>, &&。当然,这行不通-因为它们需要其他类型的索引。这样的btree如何无法访问特定元素的功能arr[i]。我们学会找到这样的:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
btree中的数组搜索查询WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
空索引条目
最后一个非常普遍的问题是使用完全为NULL的条目“乱丢”索引。即,记录每个列中的索引表达式为NULL的位置。这样的记录没有任何实际的好处,但是会增加每次插入的危害。通常,它们在您使用表中的可选填充创建FK字段或值关系时出现。然后滚动索引,以使FK迅速解决……就在这里。连接被填充的次数越少,越多的“垃圾”将落入索引中。我们将模拟:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
在大多数情况下,这样的索引可以转换为条件索引,而索引索引的花费更少:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
为了找到这样的索引,我们需要知道数据的实际分布-毕竟,读取表的所有内容并根据事件的WHERE条件对其进行叠加(我们将使用dblink进行此操作),这可能需要很长时间。搜索索引中的NULL条目的查询WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
希望本文中的某些查询对您有所帮助。