预期“ Developer Golang”课程将迎来新的发展,准备了一些有趣的材料的翻译。
数以万计的网站使用
我们权威的DNS服务器。我们每天都会回应数百万个查询。如今,DNS攻击变得越来越普遍,DNS已成为我们系统的重要组成部分,我们需要确保在高负载下能够正常工作。dnsflood是一个小型工具,可以生成大量udp请求。# timeout 20s ./dnsflood example.com 127.0.0.1 -p 2053
系统监视表明,我们的服务的内存使用量增长如此之快,以至于我们不得不停止它,否则我们将遇到OOM错误。这就像一个内存泄漏问题;go中“相似”和“实际”内存泄漏的原因多种多样:- 悬挂goroutines
- 延迟和终结器的滥用
- 子字符串和子片段
- 全局变量
这篇文章提供了各种泄漏的详细说明。在做出任何结论之前,让我们首先进行分析。Godebug
可以使用环境变量启用各种调试工具GODEBUG,并传递以逗号分隔的对列表name=value。跟踪计划器
调度程序跟踪可以提供有关运行时goroutine行为的信息。要启用调度程序跟踪,请使用运行程序GODEBUG=schedtrace=100,该值确定以ms为单位的输出周期。$ GODEBUG=schedtrace=100 ./redins -c config.json
SCHED 2952ms: ... runqueue=3 [26 11 7 18 13 30 6 3 24 25 11 0]
SCHED 3053ms: ... runqueue=3 [0 0 0 0 0 0 0 0 4 0 21 0]
SCHED 3154ms: ... runqueue=0 [0 6 2 4 0 30 0 5 0 11 2 5]
SCHED 3255ms: ... runqueue=1 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3355ms: ... runqueue=0 [1 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3456ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3557ms: ... runqueue=0 [13 0 3 0 3 33 2 0 10 8 10 14]
SCHED 3657ms: ...runqueue=3 [14 1 0 5 19 54 9 1 0 1 29 0]
SCHED 3758ms: ... runqueue=0 [67 1 5 0 0 1 0 0 87 4 0 0]
SCHED 3859ms: ... runqueue=6 [0 0 3 6 0 0 0 0 3 2 2 19]
SCHED 3960ms: ... runqueue=0 [0 0 1 0 1 0 0 1 0 1 0 0]
SCHED 4060ms: ... runqueue=5 [4 0 5 0 1 0 0 0 0 0 0 0]
SCHED 4161ms: ... runqueue=0 [0 0 0 0 0 0 0 1 0 0 0 0]
SCHED 4262ms: ... runqueue=4 [0 128 21 172 1 19 8 2 43 5 139 37]
SCHED 4362ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 4463ms: ... runqueue=6 [0 28 23 39 4 11 4 11 25 0 25 0]
SCHED 4564ms: ... runqueue=354 [51 45 33 32 15 20 8 7 5 42 6 0]
runqueue是要运行的goroutine的全局队列的长度。括号中的数字是处理队列的长度。理想的情况是所有进程都在忙于执行goroutine,并且适当长度的执行队列在所有进程之间平均分配:SCHED 2449ms: gomaxprocs=12 idleprocs=0 threads=40 spinningthreads=1 idlethreads=1 runqueue=20 [20 20 20 20 20 20 20 20 20 20 20]
查看schedtrace的输出,我们可以看到几乎所有进程都处于空闲状态的时间段。这意味着我们没有满负荷使用处理器。垃圾收集器跟踪
要启用垃圾收集(GC)跟踪,请使用环境变量运行程序GODEBUG=gctrace=1:GODEBUG=gctrace=1 ./redins -c config1.json
.
.
.
gc 30 @3.727s 1%: 0.066+21+0.093 ms clock, 0.79+128/59/0+1.1 ms cpu, 67->71->45 MB, 76 MB goal, 12 P
gc 31 @3.784s 2%: 0.030+27+0.053 ms clock, 0.36+177/81/7.8+0.63 ms cpu, 79->84->55 MB, 90 MB goal, 12 P
gc 32 @3.858s 3%: 0.026+34+0.024 ms clock, 0.32+234/104/0+0.29 ms cpu, 96->100->65 MB, 110 MB goal, 12 P
gc 33 @3.954s 3%: 0.026+44+0.13 ms clock, 0.32+191/131/57+1.6 ms cpu, 117->123->79 MB, 131 MB goal, 12 P
gc 34 @4.077s 4%: 0.010+53+0.024 ms clock, 0.12+241/159/69+0.29 ms cpu, 142->147->91 MB, 158 MB goal, 12 P
gc 35 @4.228s 5%: 0.017+61+0.12 ms clock, 0.20+296/179/94+1.5 ms cpu, 166->174->105 MB, 182 MB goal, 12 P
gc 36 @4.391s 6%: 0.017+73+0.086 ms clock, 0.21+492/216/4.0+1.0 ms cpu, 191->198->122 MB, 210 MB goal, 12 P
gc 37 @4.590s 7%: 0.049+85+0.095 ms clock, 0.59+618/253/0+1.1 ms cpu, 222->230->140 MB, 244 MB goal, 12 P
.
.
.
如我们在这里看到的,使用的内存量增加了,而gc完成他的工作所花费的时间也增加了。这意味着我们消耗的内存超出了它的处理能力。您GODEBUG可以在此处了解更多信息以及其他一些golang环境变量。启用探查器
go tool pprof-用于分析和分析数据的工具。有两种配置方法pprof:直接runtime/pprof在代码中调用函数(例如)pprof.StartCPUProfile(),或安装net/http/pprofhttp列表器并从那里获取数据,我们就是这样做的。它的pprof资源消耗非常小,因此可以在开发中安全使用,但是概要端点不应公开可用,因为可以公开敏感数据。我们需要做的第二个选择就是导入“ net / http / pprof”包:import (
_ "net/http/pprof"
)
然后添加一个http列表器:go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
Pprof具有几个默认配置文件:- allocs:获取所有过去的内存分配
- block:导致跟踪原语阻塞的堆栈跟踪
- goroutine:当前所有goroutine的堆栈跟踪
- 堆:获取活动对象的内存分配。
- 互斥体:冲突互斥体持有者的堆栈跟踪
- profile:处理器配置文件。
- threadcreate:堆栈跟踪,导致在OS中创建新线程
- trace:跟踪当前程序的执行。
注意:与所有其他端点不同,跟踪端点是一个跟踪配置文件,而不是pprof,您可以使用go tool trace来查看它go tool pprof。
现在一切就绪,我们可以看看可用的工具。处理器分析器
$ go tool pprof http:
默认情况下,处理器分析器工作30秒(我们可以通过设置参数来更改此设置seconds),并且每100毫秒收集一次样本,然后进入交互模式。最常用的命令可用top,list,web。使用top n查看文本格式的最热的项目,还有用于分拣输出,两个选项-cum供累计订单和-flat。(pprof) top 10 -cum
Showing nodes accounting for 1.50s, 6.19% of 24.23s total
Dropped 347 nodes (cum <= 0.12s)
Showing top 10 nodes out of 186
flat flat% sum% cum cum%
0.03s 0.12% 0.12% 16.7s 69.13% (*Server).serveUDPPacket
0.05s 0.21% 0.33% 15.6s 64.51% (*Server).serveDNS
0 0% 0.33% 14.3s 59.10% (*ServeMux).ServeDNS
0 0% 0.33% 14.2s 58.73% HandlerFunc.ServeDNS
0.01s 0.04% 0.37% 14.2s 58.73% main.handleRequest
0.07s 0.29% 0.66% 13.5s 56.00% (*DnsRequestHandler).HandleRequest
0.99s 4.09% 4.75% 7.56s 31.20% runtime.gentraceback
0.02s 0.08% 4.83% 7.02s 28.97% runtime.systemstack
0.31s 1.28% 6.11% 6.62s 27.32% runtime.mallocgc
0.02s 0.08% 6.19% 6.35s 26.21% (*DnsRequestHandler).FindANAME
(pprof)
用于list探索功能。(pprof) list handleRequest
Total: 24.23s
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
10ms 14.23s (flat, cum) 58.73% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
10ms 610ms 40: context := handler.NewRequestContext(w, r)
. 50ms 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 13.57s 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
(pprof)
该团队web生成了关键区域的SVG图形,并在浏览器中将其打开。(pprof)web handleReques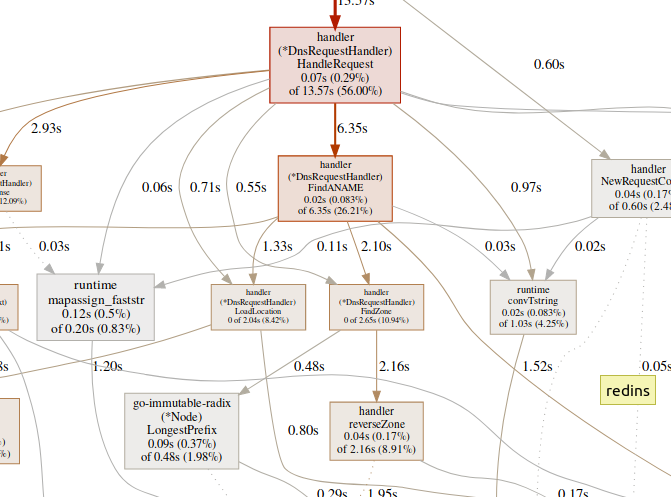 在GC功能(例如)上花费大量时间
在GC功能(例如)上花费大量时间runtime.mallocgc通常会导致大量的内存分配,这可能会增加垃圾收集器的负载并增加延迟。在同步机制(例如runtime.chansend或)上花费大量时间runtime.lock可能是冲突的迹象。花费大量时间syscall.Read/Write意味着过度使用I / O操作。内存分析器
$ go tool pprof http:
默认情况下,它显示分配的内存的生存期。我们可以使用-alloc_objects其他有用的选项查看选定对象的数量:-iuse_objects以及-inuse_space用于检查实时内存。通常,如果要减少内存消耗,则需要查看-inuse_space,但是如果要减少延迟,请在-alloc_objects足够的运行/加载时间后查看。识别瓶颈
首先确定我们要处理的瓶颈类型(处理器,I / O,内存),这一点很重要。除探查器外,还有另一种工具。go tool trace可以显示goroutine的详细功能。要收集跟踪示例,我们需要向跟踪端点发送一个http请求:$ curl http:
可以使用跟踪工具查看生成的文件:$ go tool trace trace.out
2019/12/25 15:30:50 Parsing trace...
2019/12/25 15:30:59 Splitting trace...
2019/12/25 15:31:10 Opening browser. Trace viewer is listening on http:
Go工具跟踪是一个使用Chrome DevTools协议的Web应用程序,仅与Chrome浏览器兼容。主页看起来像这样:查看跟踪(0s-409.575266ms)查看跟踪(411.075559ms-747.252311ms)查看跟踪(747.252311ms-1.234968945s)查看跟踪(1.234968945s-1.774245108s)查看跟踪(1.774245484s-2.111339514s)查看跟踪(2.111339514s-2.674030898s)查看跟踪(2.674031362s-3.044145798s)查看跟踪(3.044145798s-3.458795252s)查看跟踪(3.43953778s-4.075080634s)查看跟踪(4.075081098s-4.439271287s)查看跟踪4.4(4.439271287s) -4.814869651s)视图跟踪(4.814869651s-5.253597835s)Goroutine分析网络阻止配置文件()同步阻塞型材()系统调用阻塞的个人资料()调度延迟曲线()的用户定义的任务用户定义的区域最小突变利用跟踪分歧的跟踪时间,使你的浏览器可以处理它。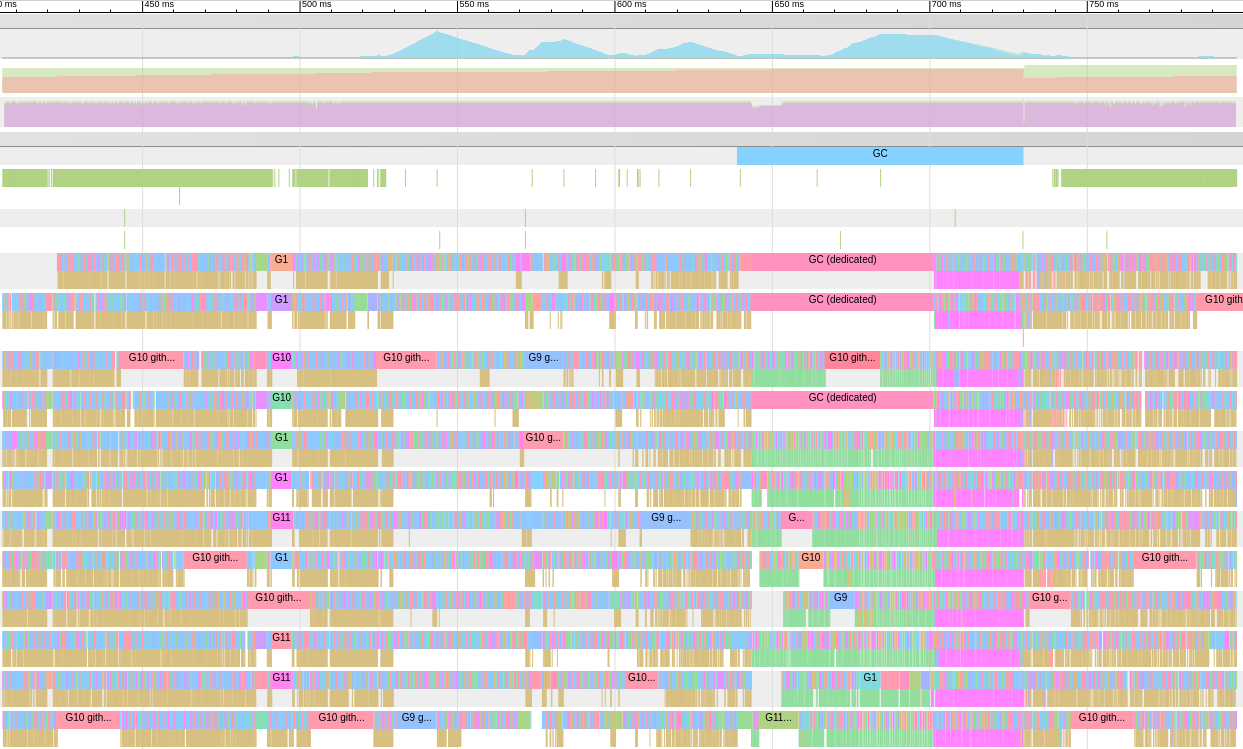 有一个巨大这里的数据量,这使得他们如果几乎不可读我们不知道我们在寻找什么。让我们暂时离开。主页上的以下链接是“ goroutine分析”,它显示了跟踪期间程序中不同类型的工作例程。
有一个巨大这里的数据量,这使得他们如果几乎不可读我们不知道我们在寻找什么。让我们暂时离开。主页上的以下链接是“ goroutine分析”,它显示了跟踪期间程序中不同类型的工作例程。Goroutines:
github.com/miekg/dns.(*Server).serveUDPPacket N=441703
runtime.gcBgMarkWorker N=12
github.com/karlseguin/ccache.(*Cache).worker N=2
main.Start.func1 N=1
runtime.bgsweep N=1
arvancloud/redins/handler.NewHandler.func2 N=1
runtime/trace.Start.func1 N=1
net/http.(*conn).serve N=1
runtime.timerproc N=3
net/http.(*connReader).backgroundRead N=1
N=40
单击N = 441703的第一个元素,这就是我们得到的: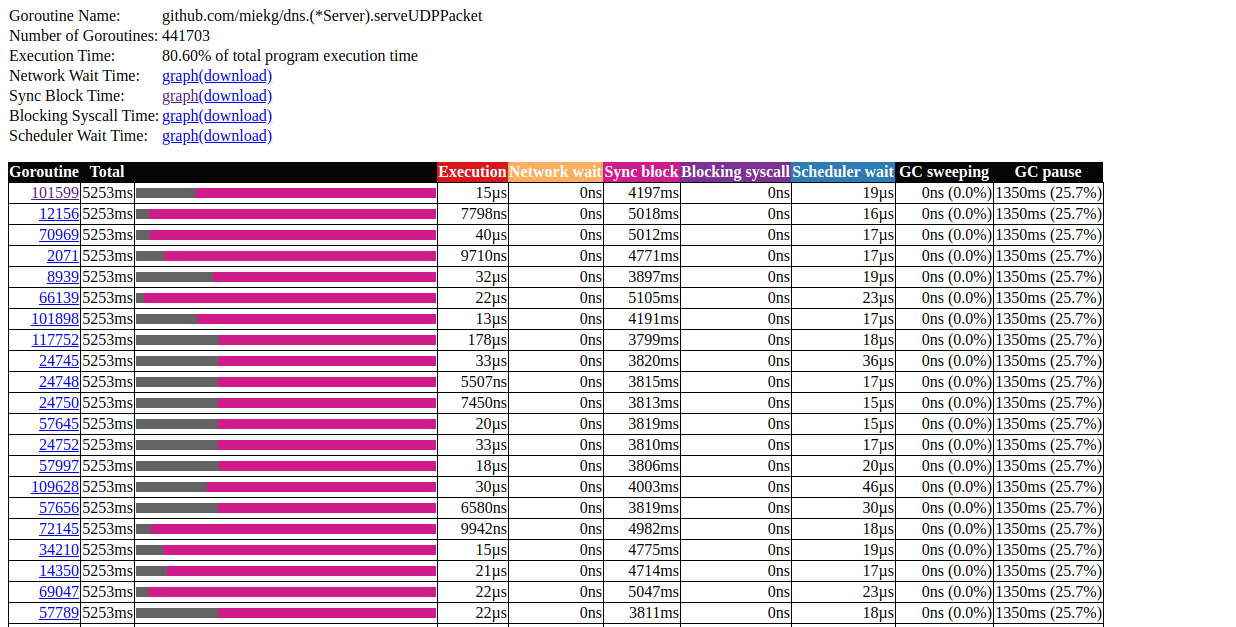 goroutin分析这非常有趣。大多数操作几乎不需要时间即可完成,并且大部分时间都用在Sync块中。让我们仔细看看其中之一:
goroutin分析这非常有趣。大多数操作几乎不需要时间即可完成,并且大部分时间都用在Sync块中。让我们仔细看看其中之一: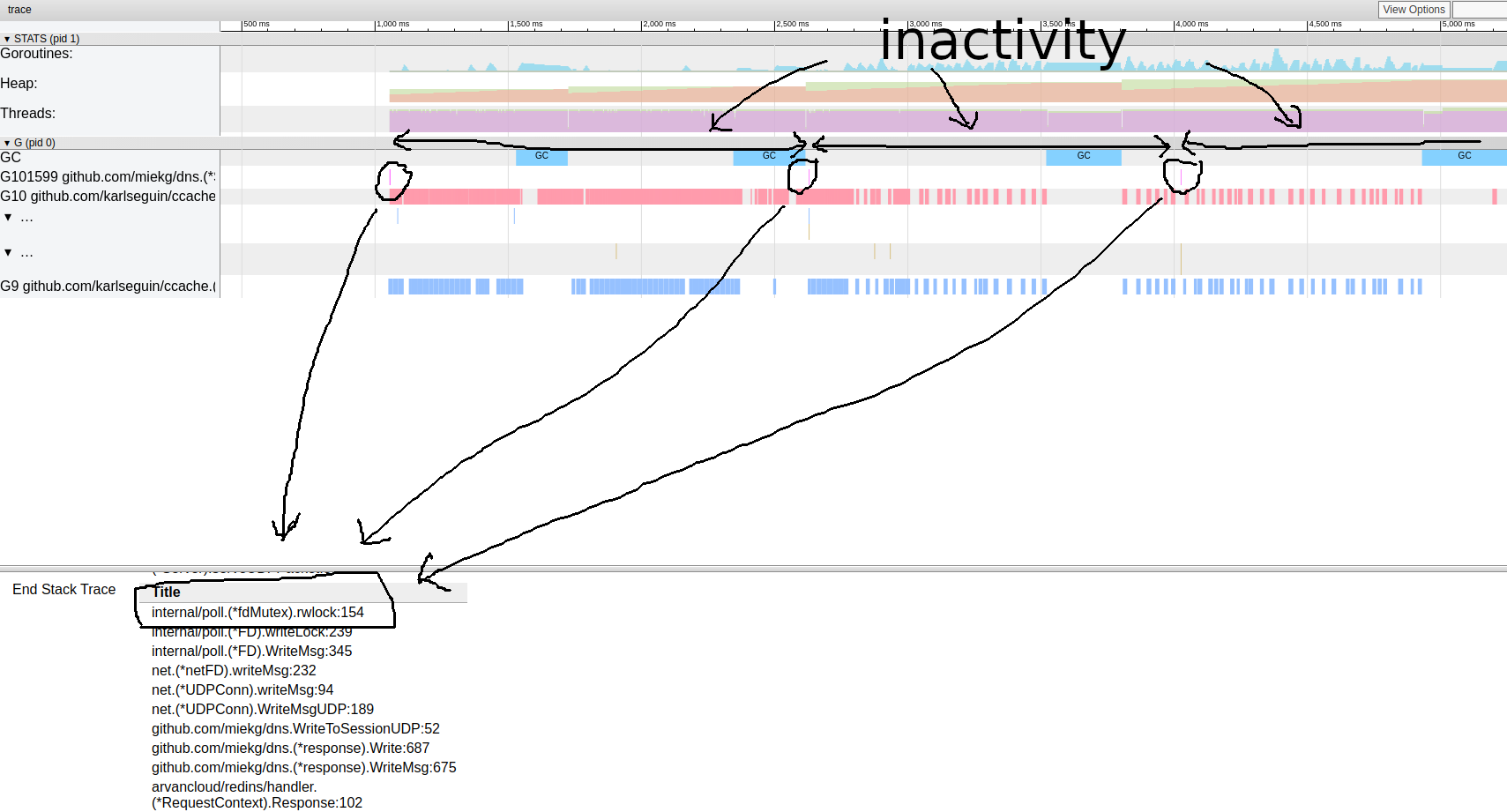 goroutine跟踪模式看来我们的程序几乎总是处于非活动状态。从这里我们可以直接进入锁定工具;默认情况下,锁分析是禁用的,我们需要首先在代码中启用它:
goroutine跟踪模式看来我们的程序几乎总是处于非活动状态。从这里我们可以直接进入锁定工具;默认情况下,锁分析是禁用的,我们需要首先在代码中启用它:runtime.SetBlockProfileRate(1)
现在我们可以选择一些锁:$ go tool pprof http:
(pprof) top
Showing nodes accounting for 16.03wks, 99.75% of 16.07wks total
Dropped 87 nodes (cum <= 0.08wks)
Showing top 10 nodes out of 27
flat flat% sum% cum cum%
10.78wks 67.08% 67.08% 10.78wks 67.08% internal/poll.(*fdMutex).rwlock
5.25wks 32.67% 99.75% 5.25wks 32.67% sync.(*Mutex).Lock
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 99.75% 5.25wks 32.68% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 99.75% 16.04wks 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*RequestContext).Response
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.ChooseIp
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*Server).serveDNS
(pprof)
在这里,我们有两个不同的锁(poll.fdMutex和sync.Mutex),它们几乎占了100%的锁。这证实了我们关于锁冲突的假设,现在我们只需要查找发生这种情况的位置即可:(pprof) svg lock
此命令创建所有冲突敏感节点的矢量图,重点放在阻塞功能上: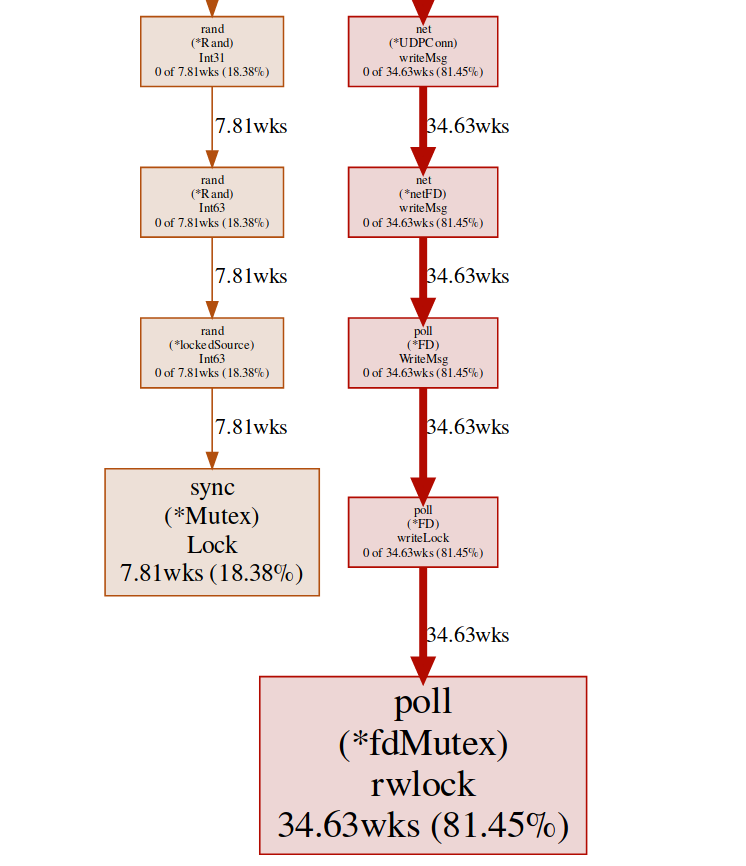 阻塞端点的svg-graph我们可以从goroutine端点获得相同的结果:
阻塞端点的svg-graph我们可以从goroutine端点获得相同的结果:$ go tool pprof http:
然后:(pprof) top
Showing nodes accounting for 294412, 100% of 294424 total
Dropped 84 nodes (cum <= 1472)
Showing top 10 nodes out of 32
flat flat% sum% cum cum%
294404 100% 100% 294404 100% runtime.gopark
8 0.0027% 100% 294405 100% github.com/miekg/dns.(*Server).serveUDPPacket
0 0% 100% 58257 19.79% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 100% 58259 19.79% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 100% 293852 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*RequestContext).Response
0 0% 100% 58140 19.75% arvancloud/redins/handler.ChooseIp
0 0% 100% 293852 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 100% 293900 99.82% github.com/miekg/dns.(*Server).serveDNS
(pprof)
我们几乎所有的程序都位于runtime.gopark中,它是一个go调度程序,用于休眠goroutines。一个很常见的原因是锁冲突(pprof) svg gopark
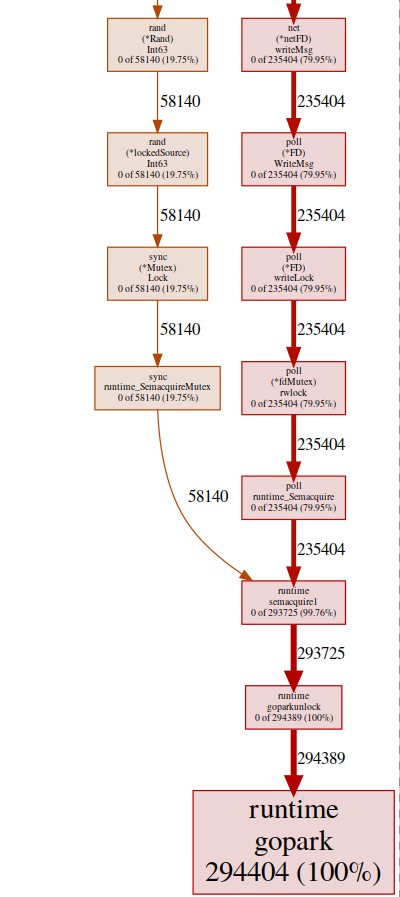 端点goroutin的svg-graph在这里,我们看到两个冲突源:
端点goroutin的svg-graph在这里,我们看到两个冲突源:UDPConn.WriteMsg()
似乎所有答案最终都写入相同的FD(因此具有锁定),这是有道理的,因为它们都具有相同的源地址。我们使用各种解决方案进行了一个小实验,最终我们决定使用多个侦听器来平衡负载。因此,我们允许OS平衡不同连接之间的传入请求并减少冲突。兰德()
正常的数学/ rand函数似乎有一个锁(此处有更多信息)。这可以借助Rand.New()创建无阻塞包装器的随机数生成器轻松解决。rg := rand.New(rand.NewSource(int64(time.Now().Nanosecond())))
情况要好一些,但是每次创建新资源都非常昂贵。有可能做得更好吗?就我们而言,我们确实不需要随机数。我们只需要一个均匀的分布来平衡负载,事实证明它Time.Nanoseconds()可能适合我们。现在,我们已经删除了所有不必要的锁,让我们看一下结果: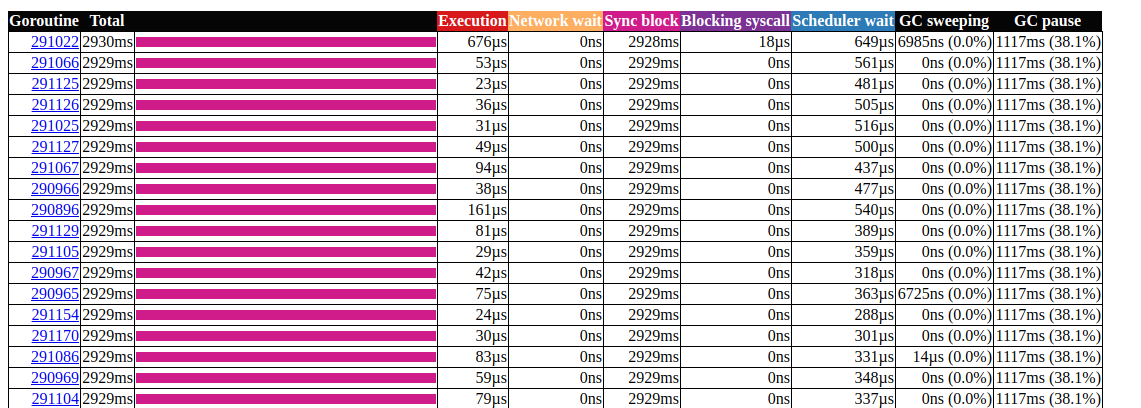 goroutin分析看起来更好,但是,大多数情况下,锁定同步需要花费时间。让我们从跟踪用户界面的主页上看一下同步锁配置文件:
goroutin分析看起来更好,但是,大多数情况下,锁定同步需要花费时间。让我们从跟踪用户界面的主页上看一下同步锁配置文件: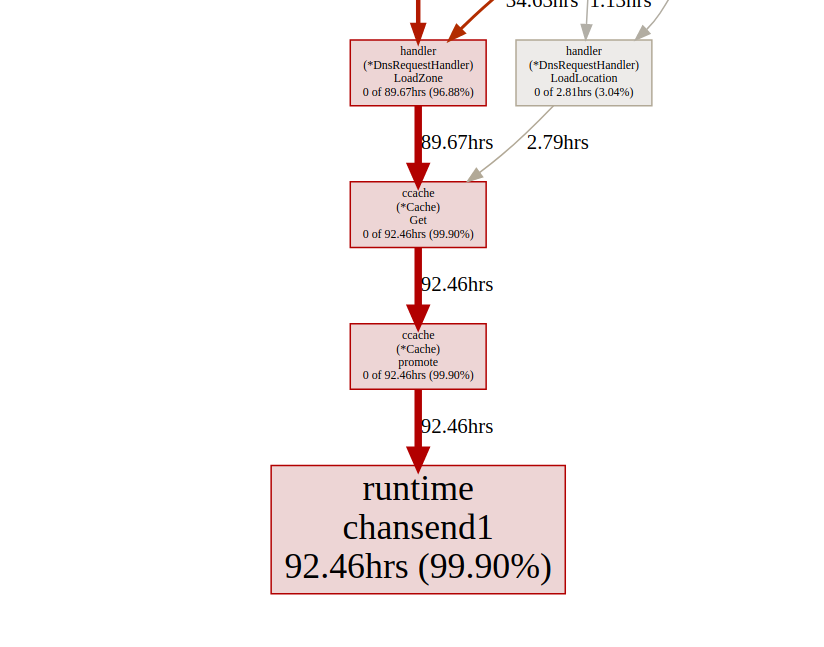 同步锁时间轴让我们
同步锁时间轴让我们ccache从锁端点看一下boost函数pprof:(pprof) list promote
ROUTINE ======================== github.com/karlseguin/ccache.(*Cache).promote in ...
0 9.66days (flat, cum) 99.70% of Total
. . 155: h.Write([]byte(key))
. . 156: return c.buckets[h.Sum32()&c.bucketMask]
. . 157:}
. . 158:
. . 159:func (c *Cache) promote(item *Item) {
. 9.66days 160: c.promotables <- item
. . 161:}
. . 162:
. . 163:func (c *Cache) worker() {
. . 164: defer close(c.donec)
. . 165:
所有呼叫均ccache.Get()在一个通道中结束c.promotables。缓存是我们服务的重要组成部分,我们应该考虑其他选择;在Dgraph中,有一篇关于缓存状态的精彩文章!Go,他们也有一个名为ristretto的出色缓存模块。不幸的是,ristretto尚不支持基于Ttl的发行版,我们可以通过使用一个非常大的版本MaxCost并将超时值保留在我们的缓存结构中来解决此问题(我们希望将过时的数据保留在缓存中)。让我们看看使用ristretto时的结果: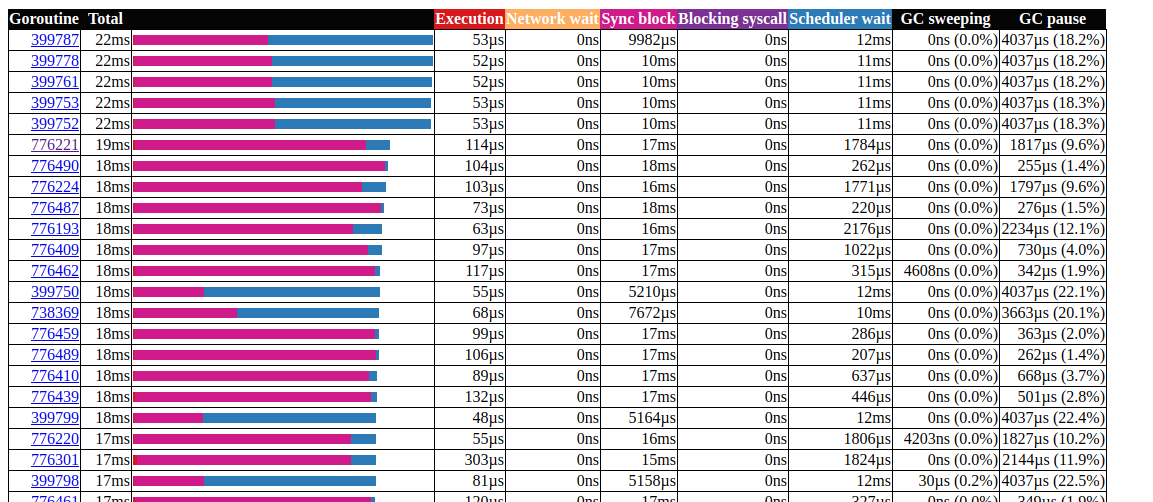 goroutin分析太好了!我们能够将gorutin的最大运行时间从5000毫秒减少到22毫秒。但是,大多数执行时间都在“同步锁定”和“等待调度程序”之间划分。让我们看看我们是否可以做些什么:
goroutin分析太好了!我们能够将gorutin的最大运行时间从5000毫秒减少到22毫秒。但是,大多数执行时间都在“同步锁定”和“等待调度程序”之间划分。让我们看看我们是否可以做些什么: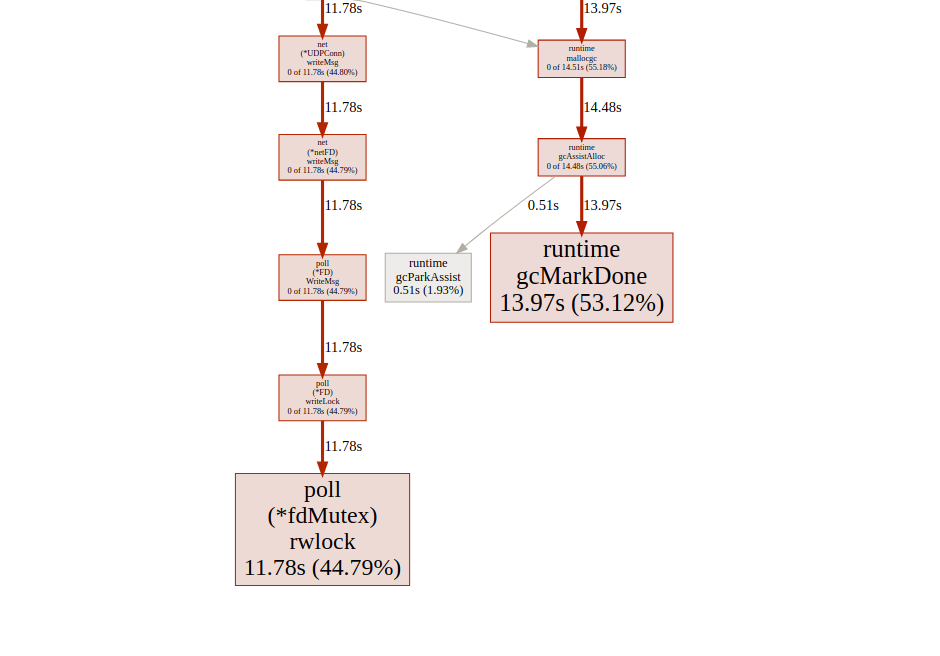 同步锁定时间轴我们可以用它做些什么
同步锁定时间轴我们可以用它做些什么fdMutex.rwlock,现在让我们关注另一个:gcMarkDone,它负责53%的块时间。此功能是垃圾收集过程的一部分。它们出现在关键部分通常表明我们超载了gc。分配优化
在这一点上,了解垃圾回收的工作方式可能会很有用。Go使用标记扫掠选择器。它会跟踪选定的所有内容,并且一旦其大小达到先前大小的两倍(或GOGC设置为其他任何值),GC就会开始清理。评估分为三个阶段:尽管世界停止(STW)阶段通常很短,但它们会停止整个过程,但连续的周期会增加持续时间。这是因为目前(执行v1.13)goroutine仅在函数调用的位置被替换,因此,对于一个连续的周期,可能会有任意长的暂停时间,因为GC希望所有goroutine停止。在标记过程中,gc使用了大约25%的内存GOMAXPROCS,但是可以强制添加其他辅助功能来标记辅助,这种情况发生在快速移动的goroutine超过背景标记以减少gc引起的延迟时,我们需要最小化堆的使用。有两件事要注意:- 分配的数量比大小更重要(例如,一个20字节结构的1000个内存分配比单个20,000字节的分配在堆上创建的负载要大得多);
- 与C / C ++之类的语言不同,并不是所有的内存分配最终都在堆上。go编译器决定变量是否将移至堆或是否可以将其放置在堆栈框架中。与在堆上分配的变量不同,在堆上分配的变量不会加载gc。
有关Go内存模型和GC架构的更多信息,请参阅此演示文稿。为了优化内存分配,我们使用go工具箱:- 处理器探查器以查找热分布;
- 内存分析器,用于跟踪分配;
- 模式跟踪器;GC
- 转义分析以找出为什么会发生分配。
让我们从处理器分析器开始:$ go tool pprof http:
(pprof) top 20 -cum
Showing nodes accounting for 7.27s, 29.10% of 24.98s total
Dropped 315 nodes (cum <= 0.12s)
Showing top 20 nodes out of 201
flat flat% sum% cum cum%
0 0% 0% 16.42s 65.73% github.com/miekg/dns.(*Server).serveUDPPacket
0.02s 0.08% 0.08% 16.02s 64.13% github.com/miekg/dns.(*Server).serveDNS
0.02s 0.08% 0.16% 13.69s 54.80% github.com/miekg/dns.(*ServeMux).ServeDNS
0.01s 0.04% 0.2% 13.48s 53.96% github.com/miekg/dns.HandlerFunc.ServeDNS
0.02s 0.08% 0.28% 13.47s 53.92% main.handleRequest
0.24s 0.96% 1.24% 12.50s 50.04% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0.81s 3.24% 4.48% 6.91s 27.66% runtime.gentraceback
3.82s 15.29% 19.78% 5.48s 21.94% syscall.Syscall
0.02s 0.08% 19.86% 5.44s 21.78% arvancloud/redins/handler.(*DnsRequestHandler).Response
0.06s 0.24% 20.10% 5.25s 21.02% arvancloud/redins/handler.(*RequestContext).Response
0.03s 0.12% 20.22% 4.97s 19.90% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0.56s 2.24% 22.46% 4.92s 19.70% runtime.mallocgc
0.07s 0.28% 22.74% 4.90s 19.62% github.com/miekg/dns.(*response).WriteMsg
0.04s 0.16% 22.90% 4.40s 17.61% github.com/miekg/dns.(*response).Write
0.01s 0.04% 22.94% 4.36s 17.45% github.com/miekg/dns.WriteToSessionUDP
1.43s 5.72% 28.66% 4.30s 17.21% runtime.pcvalue
0.01s 0.04% 28.70% 4.15s 16.61% runtime.newstack
0.06s 0.24% 28.94% 4.09s 16.37% runtime.copystack
0.01s 0.04% 28.98% 4.05s 16.21% net.(*UDPConn).WriteMsgUDP
0.03s 0.12% 29.10% 4.04s 16.17% net.(*UDPConn).writeMsg
我们对相关功能特别感兴趣,mallocgc这是标签帮助的地方(pprof) svg mallocgc
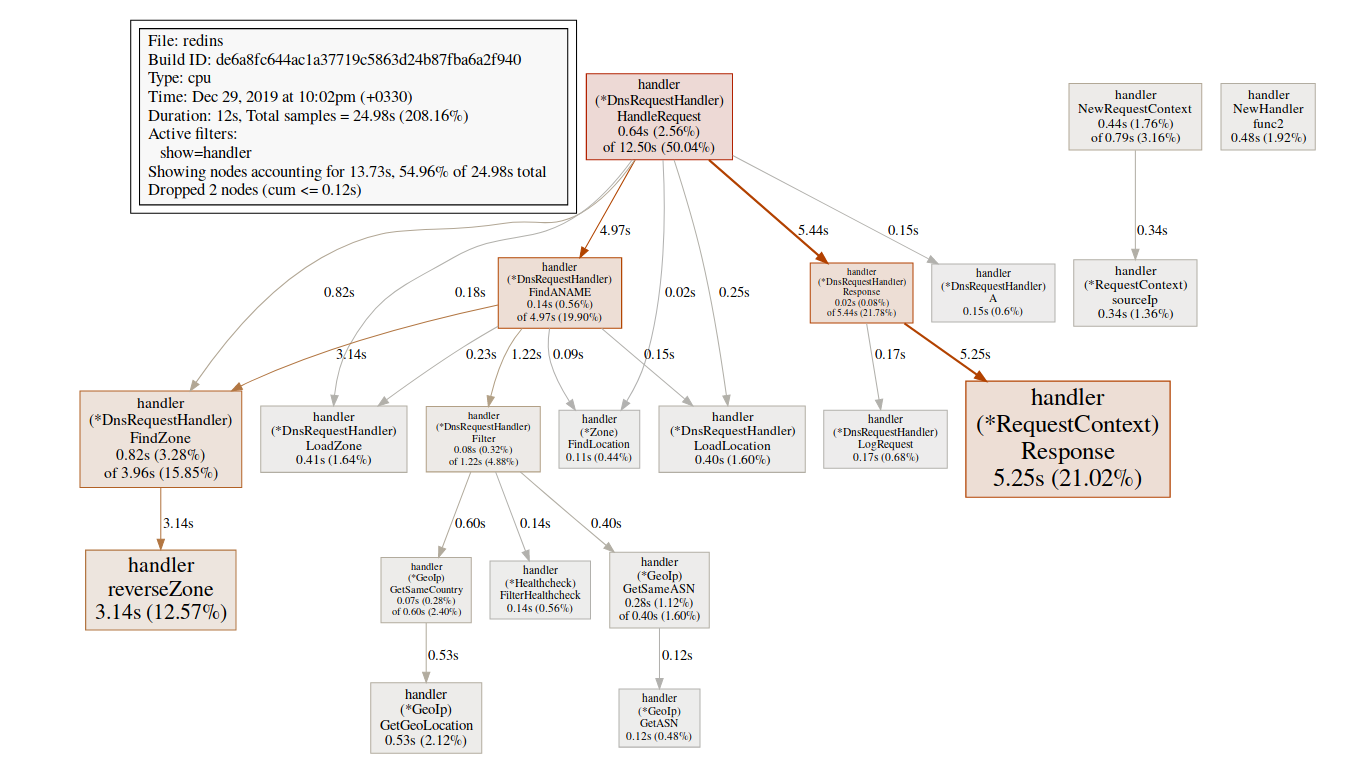 我们可以使用端点跟踪分布
我们可以使用端点跟踪分布alloc,该选项alloc_object表示分配的总数,还有其他使用内存和分配空间的选项。$ go tool pprof -alloc_objects http:
(pprof) top -cum
Active filters:
show=handler
Showing nodes accounting for 58464353, 59.78% of 97803168 total
Dropped 1 node (cum <= 489015)
Showing top 10 nodes out of 19
flat flat% sum% cum cum%
15401215 15.75% 15.75% 70279955 71.86% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
2392100 2.45% 18.19% 27198697 27.81% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
711174 0.73% 18.92% 14936976 15.27% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 18.92% 14161410 14.48% arvancloud/redins/handler.(*DnsRequestHandler).Response
14161410 14.48% 33.40% 14161410 14.48% arvancloud/redins/handler.(*RequestContext).Response
7284487 7.45% 40.85% 11118401 11.37% arvancloud/redins/handler.NewRequestContext
10439697 10.67% 51.52% 10439697 10.67% arvancloud/redins/handler.reverseZone
0 0% 51.52% 10371430 10.60% arvancloud/redins/handler.(*DnsRequestHandler).FindZone
2680723 2.74% 54.26% 8022046 8.20% arvancloud/redins/handler.(*GeoIp).GetSameCountry
5393547 5.51% 59.78% 5393547 5.51% arvancloud/redins/handler.(*DnsRequestHandler).LoadLocation
从现在开始,我们可以为每个功能使用列表,看看是否可以减少内存分配。让我们检查一下:类似于printf的函数(pprof) list handleRequest
Total: 97803168
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
2555943 83954299 (flat, cum) 85.84% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
. 11118401 40: context := handler.NewRequestContext(w, r)
2555943 2555943 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 70279955 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
第41行特别有趣,即使在关闭调试的情况下,仍在此处分配内存,我们可以使用转义分析对其进行更详细的检查。Go Escape Analysis Tool实际上是一个编译器标志$ go build -gcflags '-m'
您可以添加另一个-m以获得更多信息。$ go build -gcflags '-m '
要获得更方便的界面,请使用view-annotated-file。$ go build -gcflags '-m'
.
.
.
../redins.go:39:20: leaking param: w
./redins.go:39:42: leaking param: r
./redins.go:41:55: r.MsgHdr.Id escapes to heap
./redins.go:41:75: context.RawName() escapes to heap
./redins.go:41:91: context.Request.Type() escapes to heap
./redins.go:41:23: handleRequest []interface {} literal does not escape
./redins.go:219:17: leaking param: path
.
.
.
这里所有参数Debugf都放入堆。这是由于确定方式Debugf:func (l *EventLogger) Debugf(format string, args ...interface{})
所有参数都args将转换interface{}为始终转储到堆的类型。我们可以删除调试日志,也可以使用分布为零的日志库,例如zerolog。有关转义分析的更多信息,请参见“ golang的分配效率”。使用琴弦(pprof) list reverseZone
Total: 100817064
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
6127746 10379086 (flat, cum) 10.29% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 4251340 401: x := strings.Split(zone, ".")
. . 402: var y string
. . 403: for i := len(x) - 1; i >= 0; i-- {
6127746 6127746 404: y += x[i] + "."
. . 405: }
. . 406: return y
. . 407:}
. . 408:
. . 409:func (h *DnsRequestHandler) LoadZones() {
(pprof)
由于Go中的一行是不可变的,因此创建临时行会导致内存分配。从Go 1.10开始,您可以使用它strings.Builder来创建字符串。(pprof) list reverseZone
Total: 93437002
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
0 7580611 (flat, cum) 8.11% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 3681140 401: x := strings.Split(zone, ".")
. . 402: var sb strings.Builder
. 3899471 403: sb.Grow(len(zone)+1)
. . 404: for i := len(x) - 1; i >= 0; i-- {
. . 405: sb.WriteString(x[i])
. . 406: sb.WriteByte('.')
. . 407: }
. . 408: return sb.String()
由于我们不在乎反转线的值,因此可以Split()通过简单地翻转整条线来消除它。(pprof) list reverseZone
Total: 89094296
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
3801168 3801168 (flat, cum) 4.27% of Total
. . 400:func reverseZone(zone string) []byte {
. . 401: runes := []rune("." + zone)
. . 402: for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
. . 403: runes[i], runes[j] = runes[j], runes[i]
. . 404: }
3801168 3801168 405: return []byte(string(runes))
. . 406:}
. . 407:
. . 408:func (h *DnsRequestHandler) LoadZones() {
. . 409: h.LastZoneUpdate = time.Now()
. . 410: zones, err := h.Redis.SMembers("redins:zones")
在此处
阅读有关使用字符串的更多信息。同步池
(pprof) list GetASN
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetASN in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1146897 1146897 (flat, cum) 1.66% of Total
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
1146897 1146897 232: var record struct {
. . 233: AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
. . 234: }
. . 235: err := g.ASNDB.Lookup(ip, &record)
. . 236: if err != nil {
. . 237: logger.Default.Errorf("lookup failed : %s", err)
(pprof) list GetGeoLocation
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetGeoLocation in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1376298 3604572 (flat, cum) 5.22% of Total
. . 207:
. . 208:func (g *GeoIp) GetGeoLocation(ip net.IP) (latitude float64, longitude float64, country string, err error) {
. . 209: if !g.Enable || g.CountryDB == nil {
. . 210: return
. . 211: }
1376298 1376298 212: var record struct {
. . 213: Location struct {
. . 214: Latitude float64 `maxminddb:"latitude"`
. . 215: LongitudeOffset uintptr `maxminddb:"longitude"`
. . 216: } `maxminddb:"location"`
. . 217: Country struct {
. . 218: ISOCode string `maxminddb:"iso_code"`
. . 219: } `maxminddb:"country"`
. . 220: }
. . 221:
. . 222: if err := g.CountryDB.Lookup(ip, &record); err != nil {
. . 223: logger.Default.Errorf("lookup failed : %s", err)
. . 224: return 0, 0, "", err
. . 225: }
. 2228274 226: _ = g.CountryDB.Decode(record.Location.LongitudeOffset, &longitude)
. . 227:
. . 228: return record.Location.Latitude, longitude, record.Country.ISOCode, nil
. . 229:}
. . 230:
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
我们使用maxmiddb函数获取地理位置数据。这些函数被interface{}当作参数,正如我们前面所看到的,它可能导致堆芽。我们可以将sync.Pool选定但未使用的元素用于以后的重用。type MMDBGeoLocation struct {
Coordinations struct {
Latitude float64 `maxminddb:"latitude"`
Longitude float64
LongitudeOffset uintptr `maxminddb:"longitude"`
} `maxminddb:"location"`
Country struct {
ISOCode string `maxminddb:"iso_code"`
} `maxminddb:"country"`
}
type MMDBASN struct {
AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
}
func (g *GeoIp) GetGeoLocation(ip net.IP) (*MMDBGeoLocation, error) {
if !g.Enable || g.CountryDB == nil {
return nil, EMMDBNotAvailable
}
var record *MMDBGeoLocation = g.LocationPool.Get().(*MMDBGeoLocation)
logger.Default.Debugf("ip : %s", ip)
if err := g.CountryDB.Lookup(ip, &record); err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return nil, err
}
_ = g.CountryDB.Decode(record.Coordinations.LongitudeOffset, &record.Coordinations.Longitude)
logger.Default.Debug("lat = ", record.Coordinations.Latitude, " lang = ", record.Coordinations.Longitude, " country = ", record.Country.ISOCode)
return record, nil
}
func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
var record *MMDBASN = g.AsnPool.Get().(*MMDBASN)
err := g.ASNDB.Lookup(ip, record)
if err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return 0, err
}
logger.Default.Debug("asn = ", record.AutonomousSystemNumber)
return record.AutonomousSystemNumber, nil
}
有关sync.Pool的更多信息,请点击此处。还有许多其他可能的优化,但是目前看来,我们已经做了足够的工作。有关内存优化技术的更多信息,您可以阅读高性能Go服务中的分配效率。结果
为了可视化内存优化的结果,我们使用go tool trace标题为“ Minimum Mutator Utilization”的图,此处的Mutator表示不是gc。优化之前: 这里有一个大约500毫秒的窗口,没有有效使用(gc消耗了所有资源),从长远来看,我们永远不会获得80%的有效使用率。我们希望零有效使用的窗口尽可能小,并尽快达到100%使用,如下所示:优化后:
这里有一个大约500毫秒的窗口,没有有效使用(gc消耗了所有资源),从长远来看,我们永远不会获得80%的有效使用率。我们希望零有效使用的窗口尽可能小,并尽快达到100%使用,如下所示:优化后: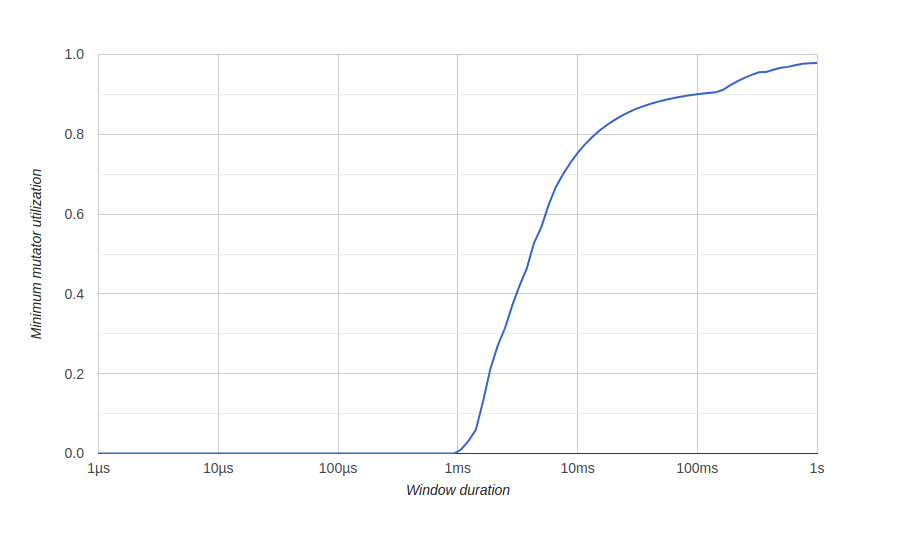
结论
使用go工具,我们能够优化服务以处理大量请求并更好地利用系统资源。您可以在GitHub上查看我们的源代码。这是未经优化的版本,这是经过优化的版本。这也将是有用的
就这样。在课程中见!