几周前,在一次晚餐聚餐中,一位同事抱怨过程缓慢。他计算了生成的字节数,处理周期数以及最终的RAM量。一位同事说,内存带宽超过500 GB / s的现代GPU会耗尽其工作量,不会阻塞。在我看来,这是一种有趣的方法。我个人以前从未从这个角度评估过绩效目标。是的,我知道处理器和内存性能的差异。 我知道如何编写大量使用缓存的代码。我知道大概的延迟数字。但这不足以立即评估内存带宽。这是一个思想实验。想象一下内存中十亿个32位整数的连续数组。这是4 GB。遍历此数组并加总值需要多长时间?CPU每秒可以从RAM读取多少字节?连续数据?随机访问?这个过程可以并行化的程度如何?您会说这些都是无用的问题。真正的程序太复杂了,以至于无法成为如此幼稚的里程碑。还有!真正的答案是“取决于情况”。但是,我认为这个问题值得探讨。我不是在寻找答案。但是我认为我们可以定义一些上下边界,在中间定义一些有趣的点,并在此过程中学到一些东西。
我知道如何编写大量使用缓存的代码。我知道大概的延迟数字。但这不足以立即评估内存带宽。这是一个思想实验。想象一下内存中十亿个32位整数的连续数组。这是4 GB。遍历此数组并加总值需要多长时间?CPU每秒可以从RAM读取多少字节?连续数据?随机访问?这个过程可以并行化的程度如何?您会说这些都是无用的问题。真正的程序太复杂了,以至于无法成为如此幼稚的里程碑。还有!真正的答案是“取决于情况”。但是,我认为这个问题值得探讨。我不是在寻找答案。但是我认为我们可以定义一些上下边界,在中间定义一些有趣的点,并在此过程中学到一些东西。每个程序员都应该知道的数字
如果您阅读编程博客,则可能会遇到“每个程序员都应该知道的数字”。他们看起来像这样:链接到L1缓存0.5 ns
错误的5 ns预测
链接到L2缓存7 ns 14x到L1缓存
Mutex捕获/释放25 ns
链接到主存储器100 ns 20x到L2高速缓存,200x到L1高速缓存
使用Zippy 3000 ns 3μs压缩1000字节
通过1 Gbps网络发送1000字节10,000 ns 10μs
带有SSD的随机读取4000 150,000 ns 150μs〜1GB / s SSD
从250,000 ns 250μs顺序读取1 MB
数据中心内部的往返数据包500,000 ns 500μs
1 MB顺序读取SSD 1,000,000 ns 1,000μs1 ms〜1 GB / s SSD,4x内存
磁盘搜索10,000,000 ns 10,000μs10 ms 20x到数据中心
从磁盘20,000,000 ns 20,000μs20 ms顺序读取1 MB 80x到内存,20x到SSD
打包发送CA->荷兰-> CA 150,000,000 ns 150,000μs150 ms
来源:乔纳斯鲍纳大名单。他每年至少一次出现在HackerNews上。每个程序员都应该知道这些数字。但是这些数字是关于其他的东西。延迟和带宽不是一回事。推迟到2020年
该清单于2012年编制,而2020年的这篇文章已经改变了。这是带有StackOverflow的 Intel i7的编号。命中L1缓存,大约4个周期(2.1-1.2 ns)
命中L2缓存,大约10个周期(5.3-3.0 ns)
命中L3缓存,单核〜40个周期(21.4-12.0 ns)
命中L3高速缓存,一起使用另一个内核〜65个周期(34.8-19.5 ns)
命中L3高速缓存,并换另一个内核〜75个周期(40.2-22.5 ns)
本地RAM〜60 ns
有趣!发生了什么变化?- L1变慢;
0,5 → 1,5
- L2更快;
7 → 4,2
- L1和L2的比率大大降低;
2,5x 14(哇!)
- L3缓存现已成为标准配置;
12 40
- RAM变得更快;
100 → 60
我们不会得出深远的结论。尚不清楚原始数字是如何计算的。我们不会将苹果与橙子进行比较。以下是来自wikichip的一些有关我的处理器的带宽和缓存大小的数字。内存带宽:每秒39.74 GB
L1高速缓存:192 KB(每个内核32 KB)
L2缓存:1.5兆字节(每个内核256 KB)
L3高速缓存:12 MB(共享;每个内核2 MB)
我想知道的是:- RAM性能上限
- 下限
- L1 / L2 / L3缓存限制
天真的基准测试
让我们做一些测试。为了测量带宽,我编写了一个简单的C ++程序。她看起来很像这样。
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
一些细节被省略。但是你明白这个主意。创建一个大的,连续的元素数组。将数组分成单独的片段。在单独的线程中处理每个片段。累积结果。您还需要测量随机访问。这非常困难。我尝试了几种方法,最终决定混合使用预先计算的索引。每个索引仅存在一次。然后,内部循环遍历索引并进行计算sum += nums[index]。std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
在计算吞吐量时,我不考虑索引数组的内存。只计入有助于总数的字节sum。我不对硬件进行基准测试,而是评估使用不同大小和不同访问方案的数据集的能力。我们将使用以下三种数据类型进行测试:int-主32位整数matri4x4-包含int[16];适合64字节的缓存行matrix4x4_simd-使用内置工具__m256i大块
我的第一个测试使用了很大的内存。 1 GB的N项目块将突出显示并填充较小的随机值。一个简单的循环遍历数组N次,因此它以一定的容量访问内存N 以计算总和int64_t。几个线程拆分了数组,每个线程都可以访问相同数量的元素。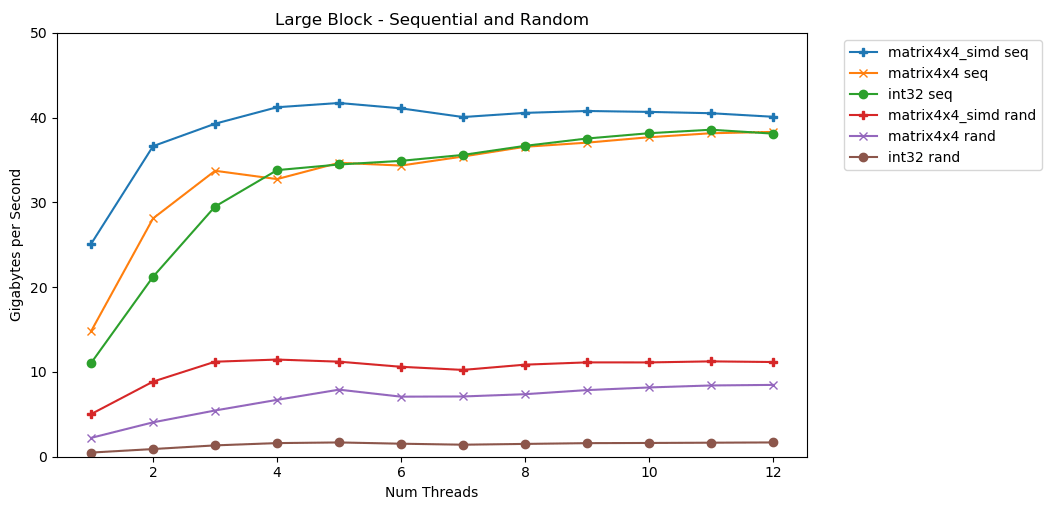 塔达!在此图中,我们将求和运算的平均执行时间取
塔达!在此图中,我们将求和运算的平均执行时间取runtime_in_nanoseconds为gigabytes_per_second。相当不错的结果。int32可以在单个流中顺序读取11 GB / s。它线性扩展,直到达到38 GB / s。测试matrix4x4和matrix4x4_simd快,但其余针对同一天花板。我们每秒可以从RAM读取多少数据有一个明确而明显的上限。在我的系统上,这大约为40 GB / s。这符合上面列出的当前规格。从底部的三个图表来看,随机访问速度很慢。非常非常慢 单线程性能int32是可以忽略的0.46 GB / s。这比11.03 GB / s的顺序堆叠慢24倍!该测试matrix4x4显示最佳结果,因为它在完整的缓存行上运行。但是它仍然比顺序访问慢四到七倍,并且峰值仅为8 GB / s。小块:顺序读取
在我的系统上,每个流的L1 / L2 / L3高速缓存大小分别为32 KB,256 KB和2 MB。如果您将一个32 KB的元素块迭代125,000次,会发生什么?这是4 GB的内存,但是我们将始终进入缓存。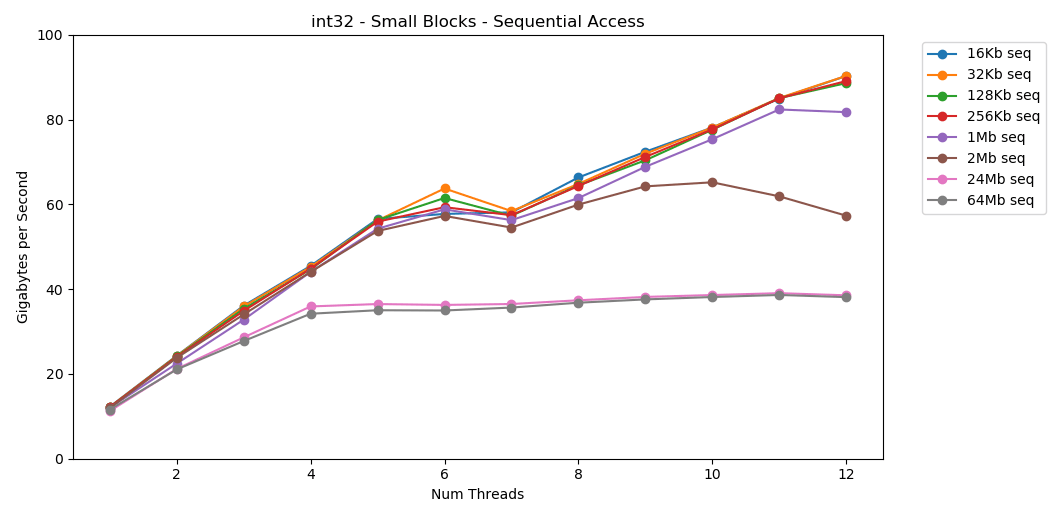 太棒了!单线程性能类似于读取大块,大约12 GB / s。除了这次,多线程突破了40 GB / s的上限。这说得通。数据保留在缓存中,因此不会出现RAM瓶颈。对于不适合L3缓存的数据,则适用大约38 GB / s的上限。测试
太棒了!单线程性能类似于读取大块,大约12 GB / s。除了这次,多线程突破了40 GB / s的上限。这说得通。数据保留在缓存中,因此不会出现RAM瓶颈。对于不适合L3缓存的数据,则适用大约38 GB / s的上限。测试matrix4x4显示出与电路相似的结果,但速度更快。单线程模式下为31 GB / s,多线程下为171 GB / s。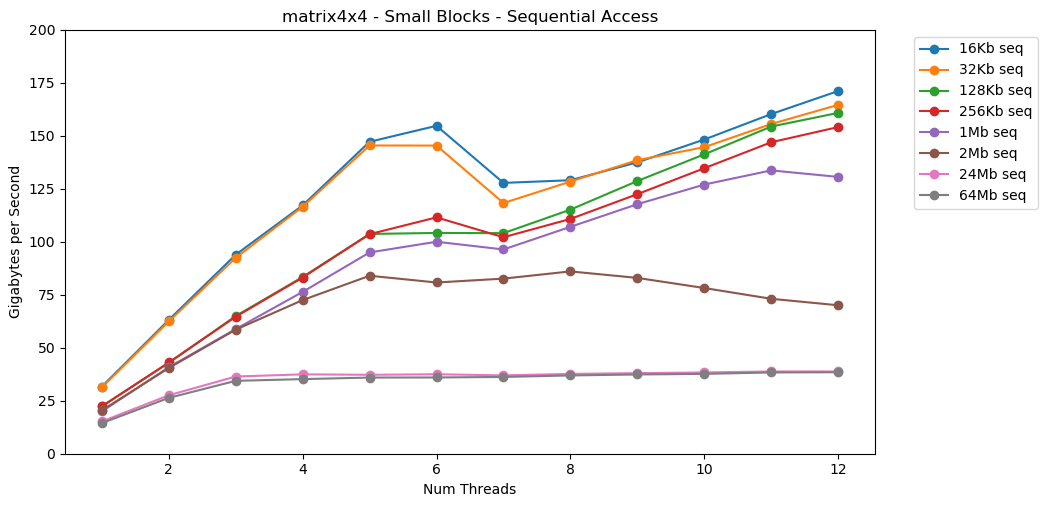 现在让我们看一下
现在让我们看一下matrix4x4_simd。注意y轴。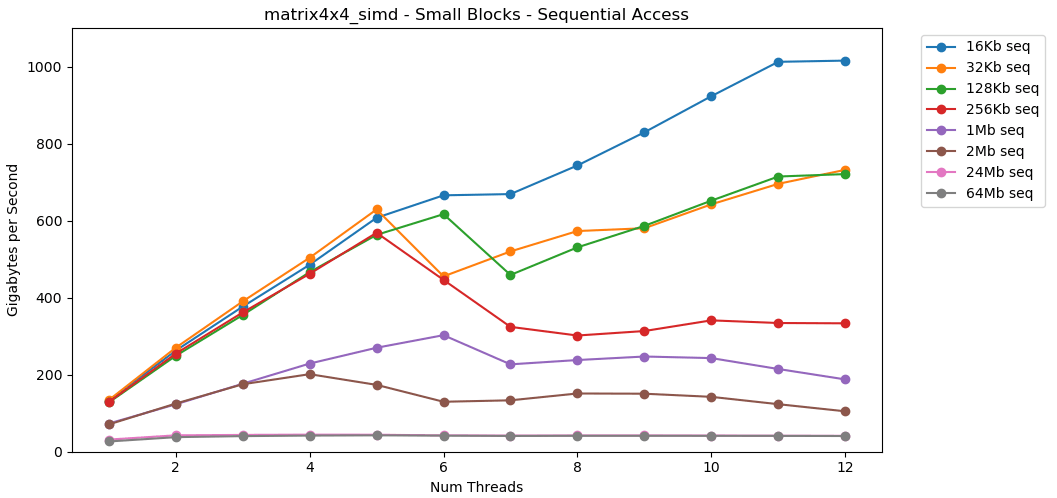
matrix4x4_simd执行异常快。比快10倍int32。在16 KB的块上,它甚至可以突破1000 GB / s!显然,这是表面合成测试。大多数应用程序不会连续百万次对相同数据执行相同操作。该测试未显示真实世界中的性能。但是,教训很明确。在缓存内部,可以快速处理数据。使用SIMD时具有很高的上限:单线程模式下超过100 GB / s,多线程下超过1000 GB / s。将数据写入高速缓存速度很慢,并且硬限制约为40 GB / s。小块:随机读取
让我们做同样的事情,但是现在有了随机访问权限。这是我最喜欢的文章。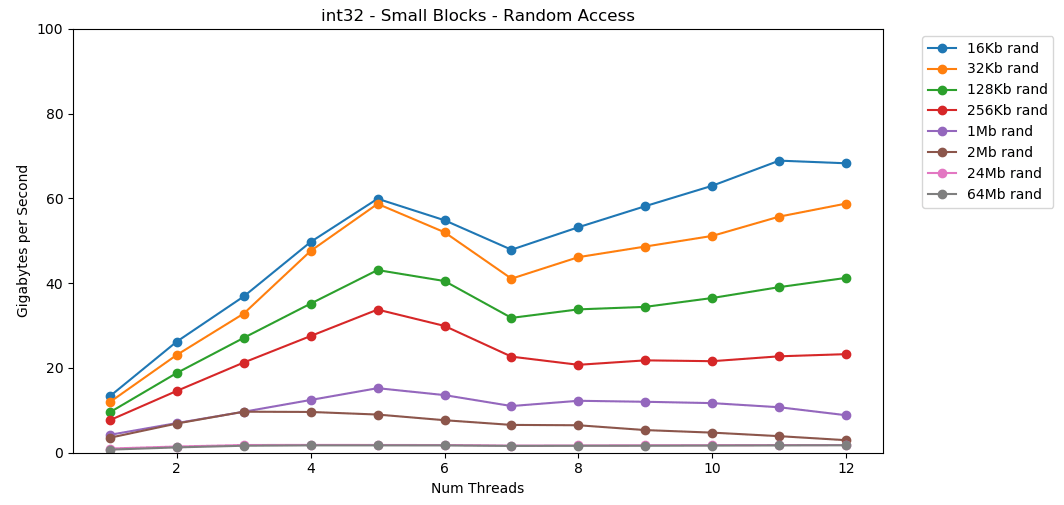 从RAM读取随机值很慢,只有0.46 GB / s。从L1缓存读取随机值非常快:13 GB / s。这比
从RAM读取随机值很慢,只有0.46 GB / s。从L1缓存读取随机值非常快:13 GB / s。这比int32从RAM 读取串行数据(11 GB / s)更快。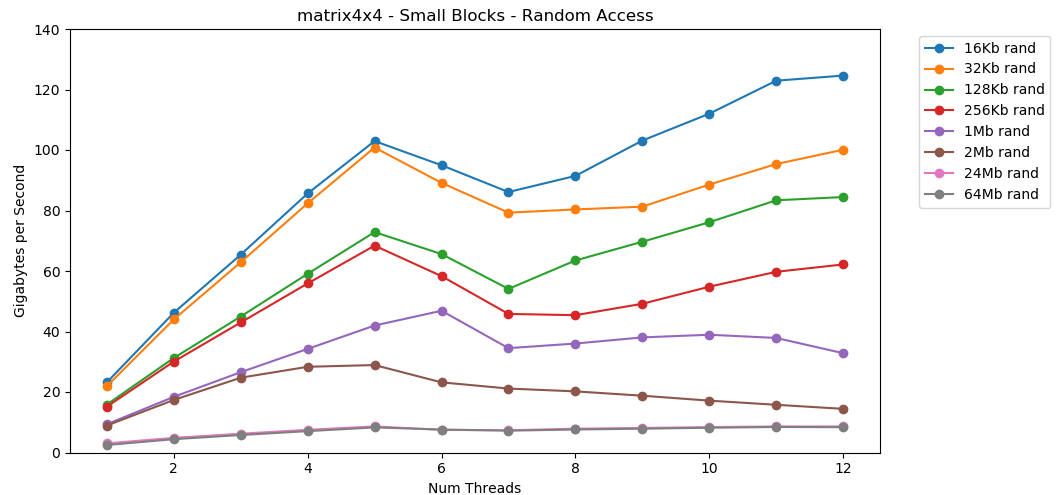 测试
测试matrix4x4显示相同模板的结果相似,但速度约为的两倍int。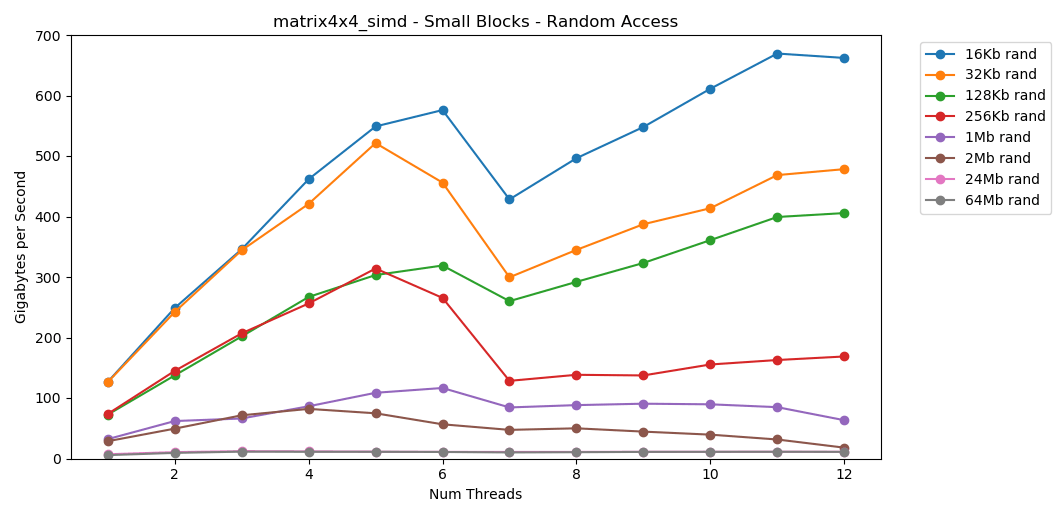 随机访问
随机访问matrix4x4_simd非常快。随机访问结果
从内存中进行免费读取很慢。灾难性的缓慢。两个测试用例均小于1 GB / s int32。同时,从缓存中随机读取的速度惊人地快。这相当于从RAM 顺序读取。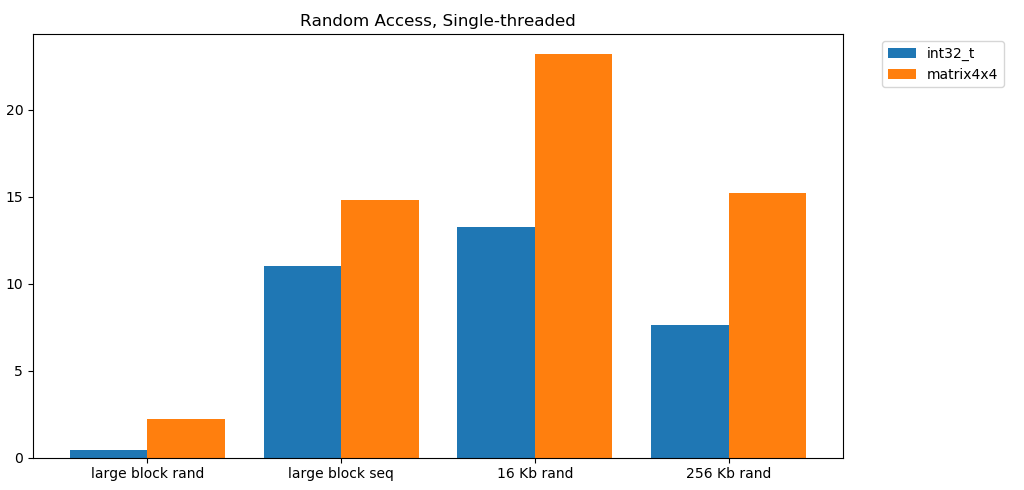 它需要被消化。随机访问高速缓存的速度与顺序访问RAM的速度相当。从L1 16 KB到L2 256 KB的下降只有一半或更少。我认为这将产生深远的影响。
它需要被消化。随机访问高速缓存的速度与顺序访问RAM的速度相当。从L1 16 KB到L2 256 KB的下降只有一半或更少。我认为这将产生深远的影响。链接列表被认为是有害的
追逐指针(跳指针)是不好的。非常非常糟糕。性能降低了多少?你自己看。我做了一个额外的测试,将其封装matrix4x4了std::unique_ptr。每次访问都通过一个指针。这是一个可怕的灾难性后果。 1个线程| 矩阵4x4 | unique_ptr | 差异|
-------------------- | --------------- | ------------ | -------- |
大块-Seq | 14.8 GB /秒| 0.8 GB /秒| 19倍|
16 KB-序列| 31.6 GB /秒| 2.2 GB /秒| 14倍|
256 KB-序列| 22.2 GB /秒| 1.9 GB /秒| 12x |
大块-兰德| 2.2 GB /秒| 0.1 GB /秒| 22x |
16 KB-兰德| 23.2 GB /秒| 1.7 GB /秒| 14倍|
256 KB-兰德| 15.2 GB /秒| 0.8 GB /秒| 19倍|
6个线程| 矩阵4x4 | unique_ptr | 差异|
-------------------- | --------------- | ------------ | -------- |
大块-Seq | 34.4 GB /秒| 2.5 GB /秒| 14倍|
16 KB-序列| 154.8 GB /秒| 8.0 GB /秒| 19倍|
256 KB-序列| 111.6 GB /秒| 5.7 GB /秒| 20倍|
大块-兰德| 7.1 GB /秒| 0.4 GB /秒| 18x |
16 KB-兰德| 95.0 GB /秒| 7.8 GB /秒| 12x |
256 KB-兰德| 58.3 GB /秒| 1.6 GB /秒| 36倍|指针后面的值的顺序求和以小于1 GB / s的速度执行。缓存的两次跳过的随机访问速度仅为0.1 GB / s。追逐指针会使代码执行速度降低10-20倍。不要让您的朋友使用链接列表。请考虑一下缓存。框架预算估算
游戏开发人员通常会为CPU的负载和内存量设置一个限制(预算)。但是我从未见过带宽预算。在现代游戏中,FPS持续增长。现在是60 FPS。 VR以90 Hz的频率运行。我有一台144 Hz游戏显示器。太棒了,所以60 FPS似乎很烂。我将永远不会回到旧的显示器。电竞和彩带Twitch监控240 Hz。今年,华硕在CES上推出了一款360 Hz的怪物。我的处理器的上限大约为40 GB / s。这似乎是一个很大的数目!但是,在240 Hz的频率下,每帧仅获得167 MB。实际的应用程序可以以144 Hz的频率生成5 GB / s的流量,每帧只有69 MB。这是一个有几个数字的表。 | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ -| -------- | -------- | -------- |
40 GB /秒| 40 GB | 4 GB | 1.3 GB | 667 MB | 444 MB | 278 MB | 167 MB | 111 MB |
10 GB /秒| 10 GB | 1 GB | 333 MB | 166 MB | 111 MB | 69 MB | 42 MB | 28 MB |
1 GB /秒| 1 GB | 100 MB | 33 MB | 17 MB | 11 MB | 7 MB | 4 MB | 3 MB |
在我看来,从这个角度评估问题很有用。这清楚表明某些想法是不可行的。达到240 Hz并不容易。这本身不会发生。每个程序员都应该知道的数字(2020)
先前的列表已过期。现在需要对其进行更新,并在2020年之前实现合规性。这是我家用电脑的一些号码。这是AIDA64,Sandra和我的基准测试的混合。这些图并没有提供完整的图片,仅是一个起点。延迟L1:1 ns
L2延迟:2.5 ns
延迟L3:10 ns
RAM延迟:50 ns
(每个线程)
L1频段:210 GB /秒
L2频段:80 GB /秒
L3频段:60 GB /秒
(整个系统)
RAM带宽:45 GB /秒
创建一个小型,简单的开源基准测试会很不错。可以在台式计算机,服务器,移动设备,控制台等上运行的一些C文件。但是我不是那种编写此类工具的人。拒绝责任
测量内存带宽很困难。非常困难。我的代码中可能有错误。许多无法解释的因素。如果您对我的技术有所批评,那可能是对的。最终,我认为这很正常。本文不是关于我的桌面的确切性能。从某种角度来看,这是一个问题陈述。关于如何学习如何进行一些粗略的数学计算。结论
一位同事与我分享了有关GPU内存带宽和应用程序性能的有趣观点。这促使我研究现代计算机上的内存性能。为了进行近似计算,以下是现代台式机的一些数字:- RAM性能
- 最大:
45 / - 平均而言:
5 / - 最低要求:
1 /
- L1 / L2 / L3缓存性能(每核)
- 最大值(c simd):
210 // 80 //60 / - 平均大约:
25 // 15 //9 / - 最低:
13 // 8 //3,5 /
样本评级与性能有关matrix4x4。真实的代码永远不会如此简单。但是对于餐巾纸的计算,这是一个合理的起点。您需要根据程序中的内存访问模式,设备的特性和代码来调整此数字。但是,最重要的是思考问题的新方法。用每秒字节数或每帧字节数显示问题是另一个需要检查的问题。这是一个有用的工具,以防万一。谢谢阅读。资源
基准C ++Python Graphdata.json进一步的研究
本文仅涉及该主题。我可能不会讲。但是,如果他这样做了,那么他可以涵盖以下方面:系统规格
测试是在我的家用PC上进行的。仅库存设置,无超频。- 操作系统:Windows 10 v1903 build 18362
- 处理器:Intel i7-8700k @ 3.70 GHz
- 内存:2x16 GSkill Ripjaw DDR4-3200(16-18-18-38 @ 1600 MHz)
- 主板:华硕TUF Z370-Plus游戏