Tensorflow.org的《递归神经网络指南》的翻译。该材料讨论了Keras / Tensorflow 2.0的内置功能以实现快速网格划分,以及自定义图层和单元的可能性。还考虑了使用CuDNN内核的情况和局限性,这可以加快学习神经网络的过程。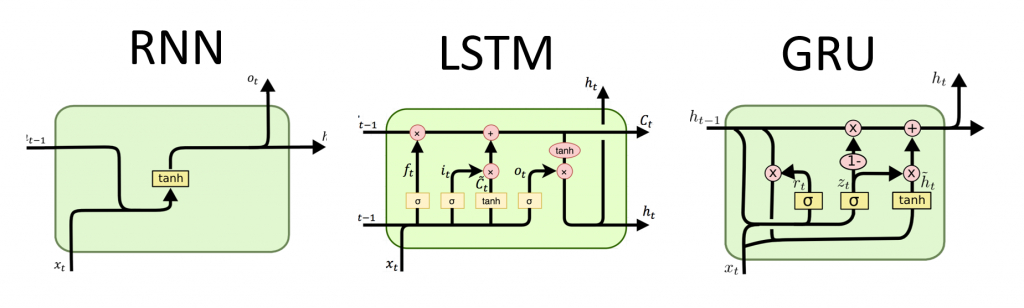 递归神经网络(RNN)是一类神经网络,可以很好地建模串行数据,例如时间序列或自然语言。如果示意性地表示,RNN层使用循环
递归神经网络(RNN)是一类神经网络,可以很好地建模串行数据,例如时间序列或自然语言。如果示意性地表示,RNN层使用循环for遍历时间顺序的序列,同时以内部状态存储有关他已经看到的步骤的编码信息。Keras RNN API的设计重点是:易于使用内置层:tf.keras.layers.RNN,tf.keras.layers.LSTM,tf.keras.layers.GRU让您快速建立一个递归的模型,而无需进行复杂的配置设置。易于定制:您还可以定义自己的RNN单元层(循环的内部)for)具有自定义行为,并将其与“ tf.keras.layers.RNN”的通用层(for循环本身)一起使用。这将使您以最少的代码以灵活的方式快速原型化各种研究思路。安装
from __future__ import absolute_import, division, print_function, unicode_literals
import collections
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
建立一个简单的模型
Keras具有三个内置的RNN层:tf.keras.layers.SimpleRNN,是一个完全连接的RNN,其中前一个时间步的输出应传递到下一步。tf.keras.layers.GRU,在文章“ 使用RNN编解码器研究统计机器翻译中的短语”中首次提出tf.keras.layers.LSTM,首先在文章长期短期记忆中提出
2015年初,Keras推出了第一个可重用的开源Python,LSTM和GRU实现。以下是Sequential模型的示例,该模型通过将每个整数嵌套在64维向量中,然后使用layer处理向量序列来处理整数序列LSTM。model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.LSTM(128))
model.add(layers.Dense(10))
model.summary()
输出和状态
默认情况下,RNN层的输出每个元素包含一个向量。此向量是最后一个RNN单元的输出,其中包含有关整个输入序列的信息。此输出的尺寸(batch_size, units),其中units对应于units传递给图层构造函数的参数。如果指定,则RNN层还可以返回每个元素的整个输出序列(每个步骤一个向量)return_sequences=True。此输出的尺寸为(batch_size, timesteps, units)。model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.GRU(256, return_sequences=True))
model.add(layers.SimpleRNN(128))
model.add(layers.Dense(10))
model.summary()
另外,RNN层可以返回其最终内部状态。返回的状态可以稍后用于恢复RNN的执行或初始化另一个RNN。此设置通常在编码器-解码器模型中按顺序使用,其中编码器的最终状态用于解码器的初始状态。为了使RNN图层返回其内部状态,请在创建图层时将参数设置return_state为value True。请注意,有LSTM2个状态张量,GRU只有一个。要调整图层的初始状态,只需使用附加参数调用该图层即可initial_state。请注意,尺寸必须与图层元素的尺寸匹配,如以下示例所示。encoder_vocab = 1000
decoder_vocab = 2000
encoder_input = layers.Input(shape=(None, ))
encoder_embedded = layers.Embedding(input_dim=encoder_vocab, output_dim=64)(encoder_input)
output, state_h, state_c = layers.LSTM(
64, return_state=True, name='encoder')(encoder_embedded)
encoder_state = [state_h, state_c]
decoder_input = layers.Input(shape=(None, ))
decoder_embedded = layers.Embedding(input_dim=decoder_vocab, output_dim=64)(decoder_input)
decoder_output = layers.LSTM(
64, name='decoder')(decoder_embedded, initial_state=encoder_state)
output = layers.Dense(10)(decoder_output)
model = tf.keras.Model([encoder_input, decoder_input], output)
model.summary()
RNN层和RNN单元
除了内置的RNN层之外,RNN API还提供了单元级API。与处理输入序列的整个包的RNN层不同,RNN单元仅处理一个时间步。该单元位于forRNN层的循环内。用一层包裹一个单元格可以tf.keras.layers.RNN为您提供一层能够处理序列数据包的层,例如 RNN(LSTMCell(10))。从数学上讲,RNN(LSTMCell(10))它的结果与相同LSTM(10)。实际上,在TF v1.x内部执行此层只是创建相应的RNN单元并将其包装在RNN层中。但是,使用嵌入式层GRU并LSTM允许使用CuDNN,它可以为您提供更好的性能。有三个内置的RNN单元,每个单元对应于其自己的RNN层。tf.keras.layers.SimpleRNNCell匹配图层SimpleRNN。tf.keras.layers.GRUCell匹配图层GRU。tf.keras.layers.LSTMCell匹配图层LSTM。
单元的抽象以及一个通用的类tf.keras.layers.RNN使得为您的研究实现自定义RNN体系结构变得非常容易。跨批次保存状态
在处理长序列(可能是无尽的)时,您可能需要使用跨批状态模式。通常,RNN层的内部状态会随着每个新的数据包而重置(即,看到该层的每个示例都假定与过去无关)。该层将仅在处理此元素期间保持状态。但是,如果序列很长,将它们分解成较短的序列,然后依次将它们传输到RNN层而不重置层状态,将很有用。因此,一个层可以存储有关整个序列的信息,尽管一次只能看到一个子序列。您可以通过在构造函数中设置`stateful = True`来实现。如果您具有序列s = [t0,t1,... t1546,t1547]`,则可以将其拆分为:s1 = [t0, t1, ... t100]
s2 = [t101, ... t201]
...
s16 = [t1501, ... t1547]
然后,您可以使用以下方法进行处理:lstm_layer = layers.LSTM(64, stateful=True)
for s in sub_sequences:
output = lstm_layer(s)
当您想要清洁状态时,请使用layer.reset_states()。注意:在这种情况下,假定i此程序包中的示例是i先前程序包示例的延续。这意味着所有包都包含相同数量的元素(包大小)。例如,如果软件包包含[sequence_A_from_t0_to_t100, sequence_B_from_t0_to_t100],则下一个软件包应包含[sequence_A_from_t101_to_t200, sequence_B_from_t101_to_t200]。
这是一个完整的示例:paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph2 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph3 = np.random.random((20, 10, 50)).astype(np.float32)
lstm_layer = layers.LSTM(64, stateful=True)
output = lstm_layer(paragraph1)
output = lstm_layer(paragraph2)
output = lstm_layer(paragraph3)
lstm_layer.reset_states()
双向RNN
对于时间序列以外的序列(例如文本),如果RNN模型不仅从头到尾进行处理,反之亦然,那么经常会发生RNN模型工作得更好的情况。例如,要预测句子中的下一个单词,了解单词周围的上下文(而不仅仅是单词前面的单词)通常很有用。Keras提供了一个用于创建此类双向RNN的简单API:包装器tf.keras.layers.Bidirectional。model = tf.keras.Sequential()
model.add(layers.Bidirectional(layers.LSTM(64, return_sequences=True),
input_shape=(5, 10)))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(10))
model.summary()
在引擎盖下,将复制Bidirectional传输的RNN层,并将go_backwards新复制的层的字段翻转,从而将以相反的顺序处理输入数据。默认情况下,` BidirectionalRNN的输出将是前向层的输出与反向层的输出之和。如果您需要其他合并行为,例如 串联,请在“双向”包装构造函数中更改“ merge_mode”参数。TensorFlow 2.0中的性能优化和CuDNN核心
在TensorFlow 2.0中,如果有图形处理器可用,则默认的CuDNN内核可以使用内置的LSTM和GRU层。进行此更改后,以前的图层keras.layers.CuDNNLSTM/CuDNNGRU已过时,您可以构建模型而不必担心将在其上运行的设备。由于CuDNN内核是基于某些假设构建的,因此这意味着如果您更改内置LSTM或GRU层的默认设置,则该层将无法使用CuDNN内核层。例如。- 将功能
activation从更改为tanh其他。 - 将功能
recurrent_activation从更改为sigmoid其他。 - 用法
recurrent_dropout> 0。 - 将其设置
unroll为True,这将导致LSTM / GRU将内部分解tf.while_loop为展开的循环for。 - 设置
use_bias为False。 - 当输入数据不正确时使用遮罩(如果遮罩与正确严格对齐的数据相匹配,则仍可以使用CuDNN。这是最常见的情况)。
尽可能使用CuDNN内核
batch_size = 64
input_dim = 28
units = 64
output_size = 10
def build_model(allow_cudnn_kernel=True):
if allow_cudnn_kernel:
lstm_layer = tf.keras.layers.LSTM(units, input_shape=(None, input_dim))
else:
lstm_layer = tf.keras.layers.RNN(
tf.keras.layers.LSTMCell(units),
input_shape=(None, input_dim))
model = tf.keras.models.Sequential([
lstm_layer,
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(output_size)]
)
return model
加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
sample, sample_label = x_train[0], y_train[0]
创建模型的实例并进行编译
我们选择sparse_categorical_crossentropy了损失函数。模型的输出具有一个维度[batch_size, 10]。模型的答案是一个整数向量,每个数字的范围是0到9。model = build_model(allow_cudnn_kernel=True)
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=5)
在没有CuDNN核心的情况下建立新模型
slow_model = build_model(allow_cudnn_kernel=False)
slow_model.set_weights(model.get_weights())
slow_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
slow_model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=1)
如您所见,使用CuDNN构建的模型比使用常规TensorFlow核心的模型进行训练要快得多。具有CuDNN支持的相同模型可用于单处理器环境中的输出。注释tf.device仅指示使用的设备。如果没有GPU,该模型将默认在CPU上运行。您只需要担心正在使用的硬件。那不是很酷吗?with tf.device('CPU:0'):
cpu_model = build_model(allow_cudnn_kernel=True)
cpu_model.set_weights(model.get_weights())
result = tf.argmax(cpu_model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)
print('Predicted result is: %s, target result is: %s' % (result.numpy(), sample_label))
plt.imshow(sample, cmap=plt.get_cmap('gray'))
具有列表/字典输入或嵌套输入的RNN
嵌套结构使您可以一步一步包含更多信息。例如,视频帧可能同时包含音频和视频输入。在这种情况下,数据的维度可以是:[batch, timestep, {\"video\": [height, width, channel], \"audio\": [frequency]}]
在另一个示例中,手写数据可以具有当前笔位置的x和y坐标以及压力信息。因此数据可以表示如下:[batch, timestep, {\"location\": [x, y], \"pressure\": [force]}]
以下代码构建了可与这种结构化输入一起使用的自定义RNN单元的示例。定义一个支持嵌套输入/输出的用户单元
NestedInput = collections.namedtuple('NestedInput', ['feature1', 'feature2'])
NestedState = collections.namedtuple('NestedState', ['state1', 'state2'])
class NestedCell(tf.keras.layers.Layer):
def __init__(self, unit_1, unit_2, unit_3, **kwargs):
self.unit_1 = unit_1
self.unit_2 = unit_2
self.unit_3 = unit_3
self.state_size = NestedState(state1=unit_1,
state2=tf.TensorShape([unit_2, unit_3]))
self.output_size = (unit_1, tf.TensorShape([unit_2, unit_3]))
super(NestedCell, self).__init__(**kwargs)
def build(self, input_shapes):
input_1 = input_shapes.feature1[1]
input_2, input_3 = input_shapes.feature2[1:]
self.kernel_1 = self.add_weight(
shape=(input_1, self.unit_1), initializer='uniform', name='kernel_1')
self.kernel_2_3 = self.add_weight(
shape=(input_2, input_3, self.unit_2, self.unit_3),
initializer='uniform',
name='kernel_2_3')
def call(self, inputs, states):
input_1, input_2 = tf.nest.flatten(inputs)
s1, s2 = states
output_1 = tf.matmul(input_1, self.kernel_1)
output_2_3 = tf.einsum('bij,ijkl->bkl', input_2, self.kernel_2_3)
state_1 = s1 + output_1
state_2_3 = s2 + output_2_3
output = [output_1, output_2_3]
new_states = NestedState(state1=state_1, state2=state_2_3)
return output, new_states
使用嵌套的输入/输出构建RNN模型
让我们构建一个Keras模型,该模型使用tf.keras.layers.RNN我们刚刚定义的图层和自定义单元格。unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
在随机生成的数据上训练模型
由于我们没有适合该模型的数据集,因此我们将使用Numpy库生成的随机数据进行演示。input_1_data = np.random.random((batch_size * num_batch, timestep, input_1))
input_2_data = np.random.random((batch_size * num_batch, timestep, input_2, input_3))
target_1_data = np.random.random((batch_size * num_batch, unit_1))
target_2_data = np.random.random((batch_size * num_batch, unit_2, unit_3))
input_data = [input_1_data, input_2_data]
target_data = [target_1_data, target_2_data]
model.fit(input_data, target_data, batch_size=batch_size)
对于层,tf.keras.layers.RNN您只需要确定序列中单个步骤的数学逻辑,该层tf.keras.layers.RNN将为您处理序列的迭代。这是快速新型RNN(例如LSTM变体)原型的强大方法。经过验证后,翻译也将出现在Tensorflow.org上。如果您想参与将Tensorflow.org网站的文档翻译成俄语,请以个人身份或评论联系。任何更正和评论表示赞赏。