HighLoad ++,Mikhail Tyulenev(MongoDB):因果一致性:从理论到实践
下一次HighLoad ++会议将于2020年4月6日至7日在圣彼得堡举行。详细信息和门票在这里。 HighLoad ++西伯利亚2019。大厅“克拉斯诺亚尔斯克”。 6月25日12:00。摘要和介绍。 碰巧实践要求与一个理论相冲突,在理论中没有考虑到对商业产品重要的方面。本报告介绍了基于学术研究基于商业产品需求选择和组合各种方法以创建因果一致性组件的过程。学生将学习有关逻辑时钟,依赖关系跟踪,系统安全性,时钟同步的现有理论方法,以及MongoDB为什么停止使用这些解决方案。Mikhail Tyulenev(以下简称MT): -我将讨论因果一致性-这是我们在MongoDB中研究的功能。我在一组分布式系统中工作,大约两年前就完成了。
碰巧实践要求与一个理论相冲突,在理论中没有考虑到对商业产品重要的方面。本报告介绍了基于学术研究基于商业产品需求选择和组合各种方法以创建因果一致性组件的过程。学生将学习有关逻辑时钟,依赖关系跟踪,系统安全性,时钟同步的现有理论方法,以及MongoDB为什么停止使用这些解决方案。Mikhail Tyulenev(以下简称MT): -我将讨论因果一致性-这是我们在MongoDB中研究的功能。我在一组分布式系统中工作,大约两年前就完成了。 在此过程中,我必须熟悉很多学术研究,因为对此功能进行了深入研究。事实证明,鉴于可能在任何生产应用程序中都有非常具体的要求,因此数据库中没有一个适合产品的文章。我将讨论作为学术研究的消费者,我们如何从中准备一些东西,然后将其作为方便,安全使用的现成菜肴呈现给用户。
在此过程中,我必须熟悉很多学术研究,因为对此功能进行了深入研究。事实证明,鉴于可能在任何生产应用程序中都有非常具体的要求,因此数据库中没有一个适合产品的文章。我将讨论作为学术研究的消费者,我们如何从中准备一些东西,然后将其作为方便,安全使用的现成菜肴呈现给用户。因果一致性。让我们定义概念
首先,我想概述一下因果一致性是什么。有两个角色-伦纳德(Leonard)和潘妮(Penny)(“大爆炸理论”系列):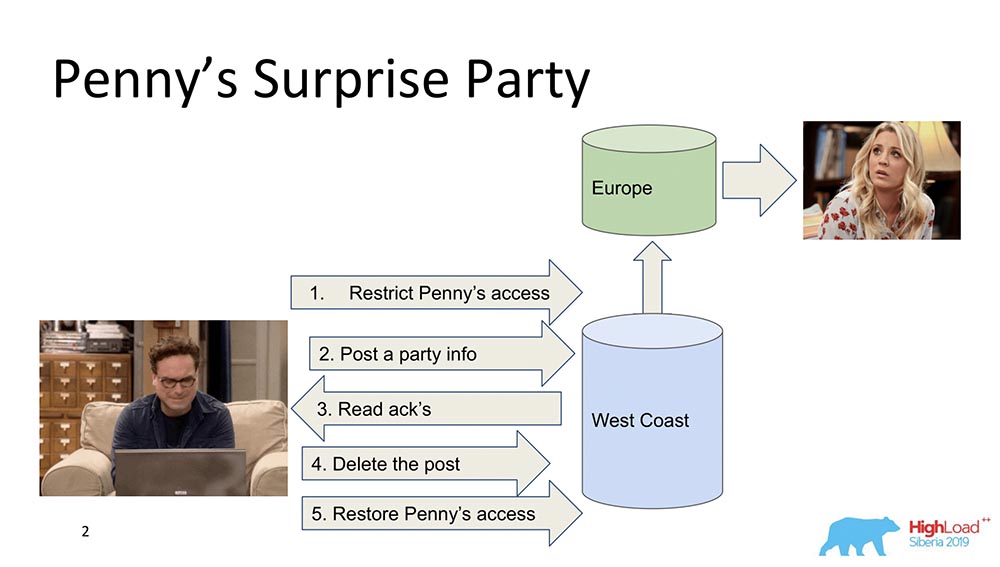 假设潘妮(Penny)在欧洲,伦纳德(Leonard)想要为她的聚会带来一些惊喜。而且,他没有比将她从朋友名单中删除,发送更新信息以养活所有朋友的想法更好的了:“让潘妮开心!” (在欧洲的她在睡觉时看不到这一切,也看不到,因为她不在那儿)。最后,它删除了该帖子,从“ Feed”中删除了该帖子,并恢复了访问权限,因此它不会注意到任何内容,也没有丑闻。一切都很好,但是让我们假设系统是分布式的,事件发生了一些错误。例如,也许可能发生的情况是,如果事件不是由因果关系引起的,便会在出现此帖子后发生Penny访问限制。实际上,这是何时需要因果一致性来实现业务功能的示例(在这种情况下)。实际上,这些是数据库的重要属性-很少有人支持它们。让我们继续进行模型。
假设潘妮(Penny)在欧洲,伦纳德(Leonard)想要为她的聚会带来一些惊喜。而且,他没有比将她从朋友名单中删除,发送更新信息以养活所有朋友的想法更好的了:“让潘妮开心!” (在欧洲的她在睡觉时看不到这一切,也看不到,因为她不在那儿)。最后,它删除了该帖子,从“ Feed”中删除了该帖子,并恢复了访问权限,因此它不会注意到任何内容,也没有丑闻。一切都很好,但是让我们假设系统是分布式的,事件发生了一些错误。例如,也许可能发生的情况是,如果事件不是由因果关系引起的,便会在出现此帖子后发生Penny访问限制。实际上,这是何时需要因果一致性来实现业务功能的示例(在这种情况下)。实际上,这些是数据库的重要属性-很少有人支持它们。让我们继续进行模型。一致性模型
一般而言,数据库中的一致性模型是什么?这些是分布式系统就客户端可以接收哪些数据和顺序提供的一些保证。原则上,所有一致性模型都可以归结为系统的分布方式,就像在笔记本电脑上以相同的方式工作一样。这就是在数千个按地理区域分布的“节点”上运行的系统与笔记本电脑的相似之处,在笔记本电脑中,所有这些属性原则上都是自动执行的。因此,一致性模型仅适用于分布式系统。以前存在并在相同垂直缩放下工作的所有系统都没有遇到此类问题。那里只有一个缓冲区缓存,并且总是从中读取所有内容。强模型
实际上,第一个模型是“强”模型(或通常所说的上升能力线)。这是一个一致性模型,可确保在收到所有更改后,所有更改对系统的所有用户都是可见的。这将创建数据库中所有事件的全局顺序。这是非常强的一致性属性,并且通常非常昂贵。但是,它维护得很好。它非常昂贵且缓慢-很少使用。这称为上升能力。“扩展程序”中还支持另一个更强大的属性,称为“外部一致性”。我们待会儿再谈他。因果关系
以下是因果关系,正是我所说的。我不会在“坚强”和“因果关系”之间有几个子级别,但它们都归结为“因果关系”。这是一个重要的模型,因为它是所有模型中最强的,是存在网络或分区时最强的一致性。因果关系实际上是事件之间因果关系联系在一起的情况。通常,它们被视为从客户的角度阅读您的权利。如果客户观察到一些价值观,他将看不到过去的价值观。他已经开始看到前缀读数。这全都归结为同一件事。因果关系是一致性的模型,它是服务器上事件的部分排序,其中所有客户端的事件都以相同的顺序进行观察。在这种情况下,伦纳德和潘妮。最终的
第三种模型是最终一致性。这就是绝对支持所有分布式系统的基本原理。这意味着:当我们对数据进行某些更改时,它们在某些时候变得一致。在这一刻,她什么也没说,否则她会变成外部一致性-将会出现一个完全不同的故事。尽管如此,这是一个非常流行的模型,最常见。默认情况下,分布式系统的所有用户都使用最终一致性。我想举一些比较的例子: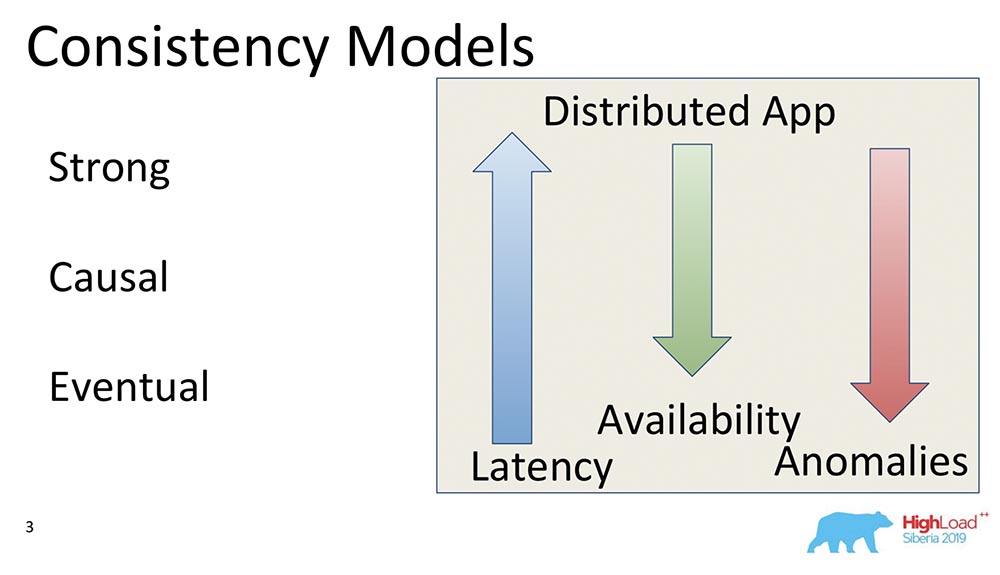 这些箭头是什么意思?
这些箭头是什么意思?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
当您看到“一致性,可用性”一词时,会想到什么?对-CAP定理!现在我想消除这个神话……不是我-马丁·克莱普曼(Martin Kleppman)写了一篇精彩的文章和一本精彩的书。 CAP定理是2000年代制定的一个原则,即一致性,可用性,分区:取任意两个,则不能选择三个。这是一定原则。几年后,吉尔伯特和林奇证明了这是一个定理。然后它成为一种口头禅-系统开始分为CA,CP,AP等。该定理实际上是由于以下原因而证明的:首先,可用性不被视为从零到数百的连续值(0-系统为“死”,100-快速回答;我们习惯于考虑它),而是作为算法的一个属性,以确保其执行所有操作后都返回数据。关于响应时间一言不发!有一种算法可以在100年后返回数据-一种非常好的可用算法,它是CAP定理的一部分。第二:证明了一个定理,即相同键的值发生了变化,尽管这些变化是可调整大小的线。这意味着实际上它们实际上未被使用,因为模型的最终一致性,强一致性(可能)是不同的。为什么都这样?而且,很少使用证明它实际上不适用的形式的CAP定理。从理论上讲,它某种程度上限制了一切。事实证明某个原则在直觉上是正确的,但总的来说,没有任何证据可以证明。
CAP定理是2000年代制定的一个原则,即一致性,可用性,分区:取任意两个,则不能选择三个。这是一定原则。几年后,吉尔伯特和林奇证明了这是一个定理。然后它成为一种口头禅-系统开始分为CA,CP,AP等。该定理实际上是由于以下原因而证明的:首先,可用性不被视为从零到数百的连续值(0-系统为“死”,100-快速回答;我们习惯于考虑它),而是作为算法的一个属性,以确保其执行所有操作后都返回数据。关于响应时间一言不发!有一种算法可以在100年后返回数据-一种非常好的可用算法,它是CAP定理的一部分。第二:证明了一个定理,即相同键的值发生了变化,尽管这些变化是可调整大小的线。这意味着实际上它们实际上未被使用,因为模型的最终一致性,强一致性(可能)是不同的。为什么都这样?而且,很少使用证明它实际上不适用的形式的CAP定理。从理论上讲,它某种程度上限制了一切。事实证明某个原则在直觉上是正确的,但总的来说,没有任何证据可以证明。因果一致性-最强模型
现在正在发生的事情-您可以获得所有三件事:一致性,可用性可以使用分区来获得。尤其是,因果一致性是最强的一致性模型,在存在分区(网络中断)的情况下,该模型仍然有效。因此,它引起了极大的兴趣,因此我们也参与其中。 首先,它简化了应用程序开发人员的工作。特别是,服务器提供了很多支持:当保证一个客户端内部发生的所有记录都按此顺序到达另一客户端时。其次,它可以承受分区。
首先,它简化了应用程序开发人员的工作。特别是,服务器提供了很多支持:当保证一个客户端内部发生的所有记录都按此顺序到达另一客户端时。其次,它可以承受分区。室内厨房MongoDB
记得那顿午餐,我们去了厨房。我将讨论系统模型,即首先了解这种数据库的人的MongoDB是什么。
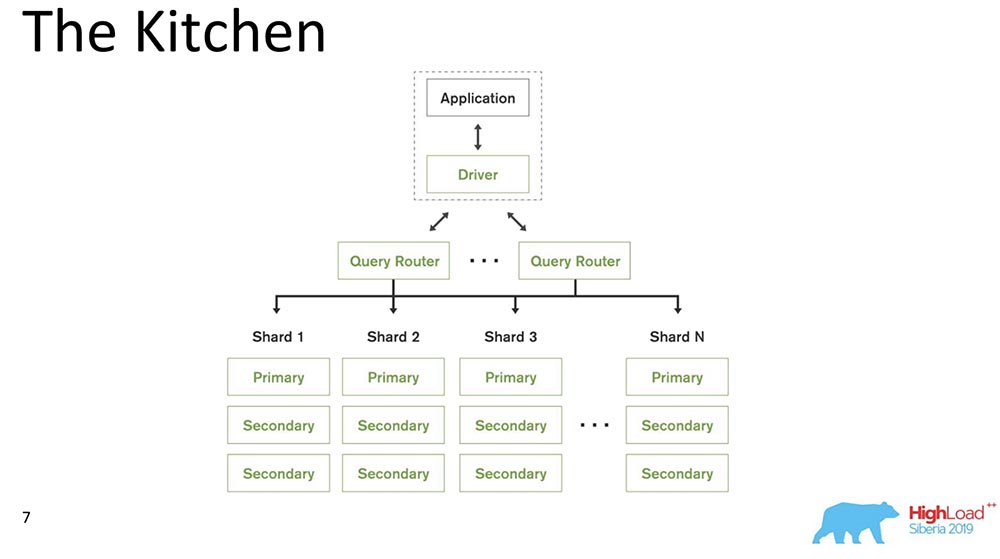 MongoDB(以下称为“ MongoBD”)是一种支持水平扩展(即分片)的分布式系统;并且在每个分片中,它还支持数据冗余,即复制。“ MongoBD”(非关系数据库)中的分片执行自动平衡,即将文档(或关系数据方面的“表”)的每个集合分解成小块,并且服务器已经自动在分片之间移动它们。为客户端分发查询的查询路由器是通过其工作的某些客户端。他已经知道数据的位置和位置,并将所有请求发送到正确的分片。另一个要点:MongoDB是单个主机。有一个主数据库-它可以记录支持其包含的密钥的记录。您无法进行多母版写入。我们制作了4.2版-那里出现了一些有趣的新东西。特别是,他们插入了Lucene(即搜索),它直接在“ Mongo”中是Java可执行文件,因此可以通过Lucene进行搜索,就像在“ Elastic”中一样。他们制作了一个新产品-图表,也可以在Atlas(Mongo自己的云)上使用。他们有免费套餐-您可以尝试一下。我真的很喜欢图表-数据可视化非常直观。
MongoDB(以下称为“ MongoBD”)是一种支持水平扩展(即分片)的分布式系统;并且在每个分片中,它还支持数据冗余,即复制。“ MongoBD”(非关系数据库)中的分片执行自动平衡,即将文档(或关系数据方面的“表”)的每个集合分解成小块,并且服务器已经自动在分片之间移动它们。为客户端分发查询的查询路由器是通过其工作的某些客户端。他已经知道数据的位置和位置,并将所有请求发送到正确的分片。另一个要点:MongoDB是单个主机。有一个主数据库-它可以记录支持其包含的密钥的记录。您无法进行多母版写入。我们制作了4.2版-那里出现了一些有趣的新东西。特别是,他们插入了Lucene(即搜索),它直接在“ Mongo”中是Java可执行文件,因此可以通过Lucene进行搜索,就像在“ Elastic”中一样。他们制作了一个新产品-图表,也可以在Atlas(Mongo自己的云)上使用。他们有免费套餐-您可以尝试一下。我真的很喜欢图表-数据可视化非常直观。因果一致性成分
我统计了莱斯利·兰伯特(Leslie Lampert)发表的有关该主题的约230篇文章。现在,从我的记忆中,我将为您带来这些材料的某些部分。 一切始于1970年代Leslie Lampert的文章。如您所见,有关此主题的一些研究仍在进行中。现在,因果一致性正在引起与分布式系统开发相关的兴趣。
一切始于1970年代Leslie Lampert的文章。如您所见,有关此主题的一些研究仍在进行中。现在,因果一致性正在引起与分布式系统开发相关的兴趣。局限性
有什么限制?这实际上是要点之一,因为生产系统施加的限制与学术文章中存在的限制有很大不同。通常,它们是人为的。
- 首先,正如我已经说过的,“ MongoDB”是一个单一的主机(这大大简化了)。
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- 另一点通常是反学术的:以前和将来版本的兼容性。旧驱动程序必须支持新的更新,并且数据库必须支持旧驱动程序。
通常,所有这些都施加了限制。因果一致性成分
我现在将讨论一些组件。如果考虑一般因果一致性,则可以区分块。我们从属于某个特定领域的作品中进行选择:依赖关系跟踪,小时的选择,这些手表如何彼此同步以及我们如何确保安全性-这是我将要谈论的大致计划:
完全依赖跟踪
为什么需要它?为了在复制数据时(每个记录),每个数据更改都包含有关其所依赖的更改的信息。最先天真的变化是,每条包含一条记录的消息都包含有关先前消息的信息: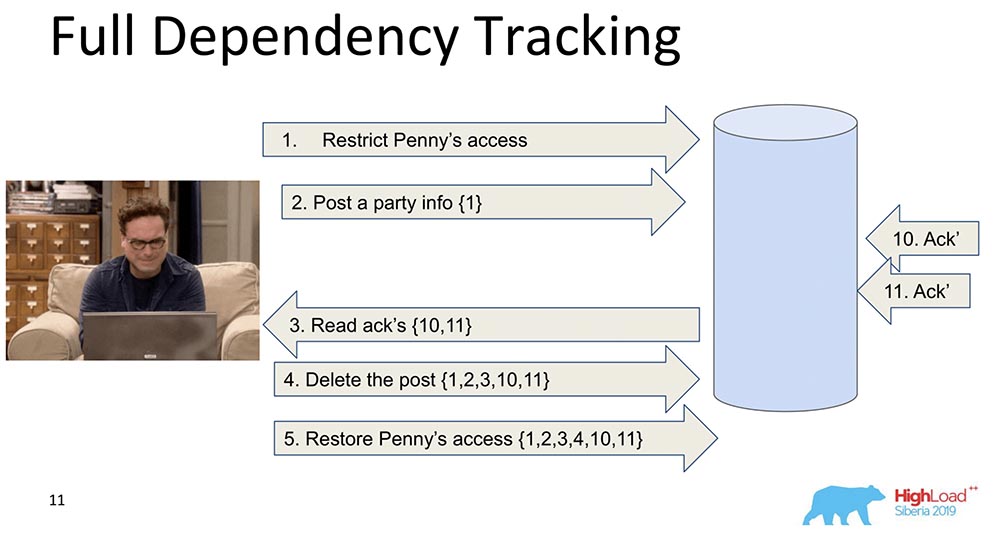 在此示例中,大括号中的数字是记录数。有时这些带有值的记录甚至全部被转移,有时某些版本被转移。最重要的是,每个更改都包含有关上一个更改的信息(显然,它本身包含了所有内容)。为什么我们决定不使用这种方法(完全跟踪)?显然,因为这种方法是不切实际的:社交网络中的任何更改都取决于该社交网络中所有以前的更改,例如在每次更新中都发送Facebook或Vkontakte。但是,有很多研究,即完全依赖跟踪-这些是社交前网络,在某些情况下它确实有效。
在此示例中,大括号中的数字是记录数。有时这些带有值的记录甚至全部被转移,有时某些版本被转移。最重要的是,每个更改都包含有关上一个更改的信息(显然,它本身包含了所有内容)。为什么我们决定不使用这种方法(完全跟踪)?显然,因为这种方法是不切实际的:社交网络中的任何更改都取决于该社交网络中所有以前的更改,例如在每次更新中都发送Facebook或Vkontakte。但是,有很多研究,即完全依赖跟踪-这些是社交前网络,在某些情况下它确实有效。显式依赖项跟踪
下一个比较有限。在这里,也考虑了信息的传输,但是仅考虑了明显的依赖。通常,取决于什么的内容已经由应用程序确定。复制数据时,即在满足先前的依赖性(如所示)时发出请求时仅返回响应。这就是因果一致性如何工作的本质。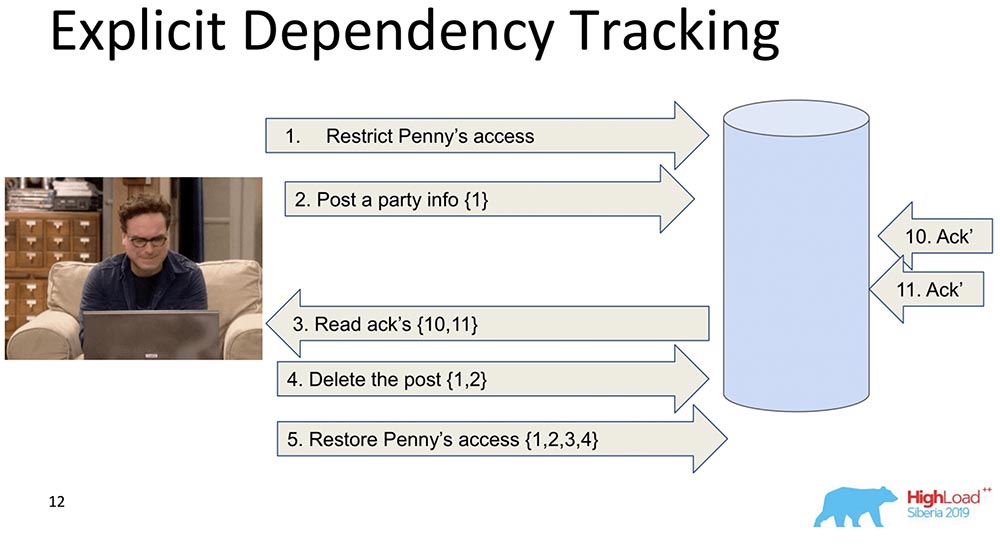 她看到记录5分别依赖于记录1、2、3、4,当所有先前的更改都已传递到数据库时,她等待客户端访问Penny的访问法令所做的更改。这也不适合我们,因为无论如何信息太多,这会减慢速度。有另一种方法...
她看到记录5分别依赖于记录1、2、3、4,当所有先前的更改都已传递到数据库时,她等待客户端访问Penny的访问法令所做的更改。这也不适合我们,因为无论如何信息太多,这会减慢速度。有另一种方法...兰波特时钟
他们很老。 Lamport Clock意味着这些依赖关系被分解为称为Lamport Clock的标量函数。标量函数是一些抽象数。通常称为逻辑时间。在每次事件中,此计数器都会增加。进程当前已知的计数器发送每个消息。显然,进程可能不同步,它们可以具有完全不同的时间。但是,系统在某种程度上平衡了此类消息传递的时钟。在这种情况下会发生什么?我将这个大碎片分成了两部分,这样很清楚:朋友可以生活在一个包含该集合一部分的节点中,而Feed可以生活在一个包含该集合一部分的节点中。很明显,他们如何摆脱困境? Feed首先说“已复制”,然后说“朋友”。如果系统没有提供任何保证,直到还交付了Friends集合中的Friends依赖项后,Feed才会显示,那么我们将遇到我提到的情况。您会看到在Feed上逻辑上计数器时间增加的方式: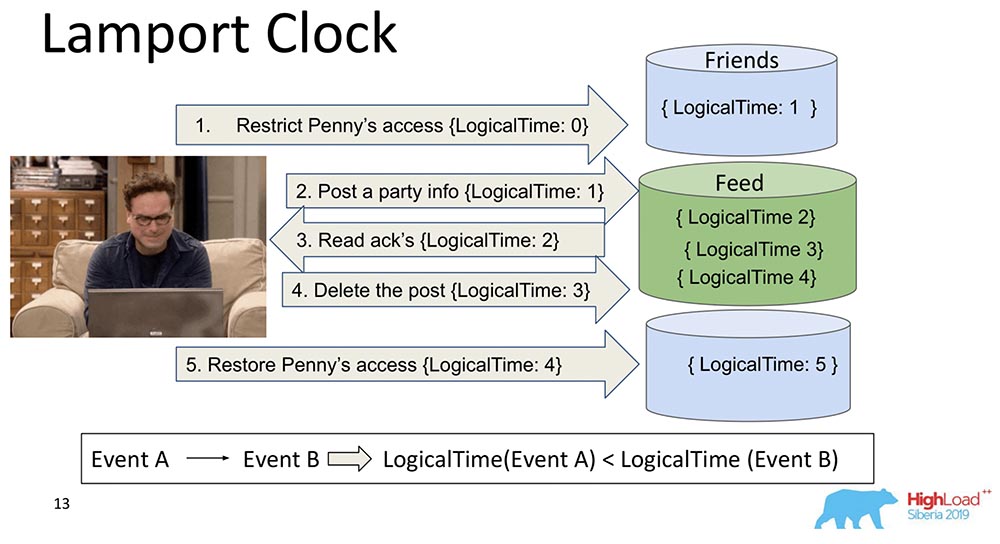 因此,此Lamport Clock的主要属性和因果一致性(通过Lamport Clock解释)如下:如果我们有事件A和B,而事件B取决于事件A *,则得出事件A的LogicalTime较小*有时他们甚至说A发生在B之前,也就是说,A发生在B之前-这是一种关系,可以部分排序通常发生的整个事件集。相反是错误的。实际上,这是Lamport Clock的主要缺点之一-部分排序。有同时发生事件的概念,即(A发生在B之前)或(A发生在B之前)都不发生的事件。一个例子是伦纳德与其他人的朋友并行添加(例如,甚至不是伦纳德,而是谢尔顿)。这是使用Lamport手表时经常使用的属性:它们准确地查看功能并由此得出结论-也许这些事件是相关的。因为从一个方向来看这是正确的:如果LogicalTime A小于LogicalTime B,则B不能在A之前发生;如果更多,那么也许。
因此,此Lamport Clock的主要属性和因果一致性(通过Lamport Clock解释)如下:如果我们有事件A和B,而事件B取决于事件A *,则得出事件A的LogicalTime较小*有时他们甚至说A发生在B之前,也就是说,A发生在B之前-这是一种关系,可以部分排序通常发生的整个事件集。相反是错误的。实际上,这是Lamport Clock的主要缺点之一-部分排序。有同时发生事件的概念,即(A发生在B之前)或(A发生在B之前)都不发生的事件。一个例子是伦纳德与其他人的朋友并行添加(例如,甚至不是伦纳德,而是谢尔顿)。这是使用Lamport手表时经常使用的属性:它们准确地查看功能并由此得出结论-也许这些事件是相关的。因为从一个方向来看这是正确的:如果LogicalTime A小于LogicalTime B,则B不能在A之前发生;如果更多,那么也许。矢量时钟
Lamport手表的逻辑发展是矢量时钟。它们的不同之处在于,此处的每个节点都包含其自己的独立时钟,并且它们作为向量进行传输。在这种情况下,您会看到向量的零索引负责Feed,向量的第一个索引负责Friends(每个节点)。现在它们会增加:录制时“ Feed”的零索引会增加-1,2,3: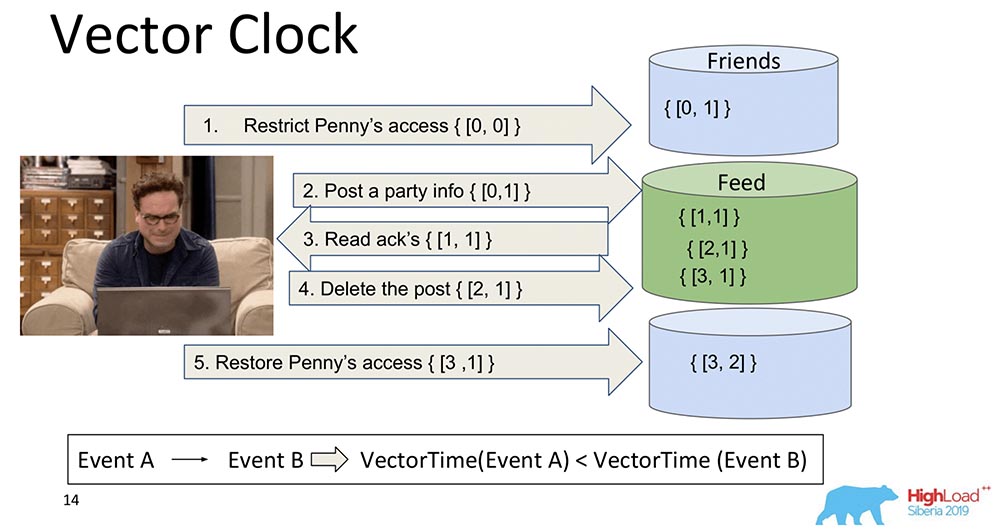 矢量时钟如何更好?他们可以弄清楚哪些事件是同时发生的,以及它们何时发生在不同的节点上。这对于像MongoBD这样的分片系统非常重要。但是,我们没有选择它,尽管这是一件了不起的事情,而且效果很好,并且很可能适合我们...如果我们有1万个分片,就无法传输1万个组件,即使压缩,我们也会想出其他办法-一样,有效载荷将比整个向量的体积小几倍。因此,我们全心全意地放弃了这种方法,而转向另一种方法。
矢量时钟如何更好?他们可以弄清楚哪些事件是同时发生的,以及它们何时发生在不同的节点上。这对于像MongoBD这样的分片系统非常重要。但是,我们没有选择它,尽管这是一件了不起的事情,而且效果很好,并且很可能适合我们...如果我们有1万个分片,就无法传输1万个组件,即使压缩,我们也会想出其他办法-一样,有效载荷将比整个向量的体积小几倍。因此,我们全心全意地放弃了这种方法,而转向另一种方法。扳手TrueTime。原子钟
我说过会有关于Spanner的故事。就在21世纪,这是一件很酷的事情:原子钟,GPS同步。什么主意Spanner是一个Google系统,最近人们甚至可以使用它(他们已经在其中附加了SQL)。那里的每笔交易都有一些时间戳。由于时间是同步的*,因此可以为每个事件分配一个特定的时间-原子钟有一个等待时间,在此之后可以保证会发生另一个时间。 因此,只需写入数据库并等待一定时间,事件序列化就会自动得到保证。它们具有最强的一致性模型,这在原则上可以想象得到-它是外部一致性。*这是Lampart手表的主要问题-它们在分布式系统上永远不会同步。即使使用NTP,它们也可能会发散,但仍然不能很好地工作。“ Spanner”具有原子钟,并且同步似乎只有几微秒。我们为什么不选择呢?我们不假定我们的用户有内置的原子钟。当它们出现在每台笔记本电脑中时,就会出现某种超酷的GPS同步-那么是的……同时,可能的最佳选择是亚马逊,狂热者基地……因此,我们使用了其他手表。
因此,只需写入数据库并等待一定时间,事件序列化就会自动得到保证。它们具有最强的一致性模型,这在原则上可以想象得到-它是外部一致性。*这是Lampart手表的主要问题-它们在分布式系统上永远不会同步。即使使用NTP,它们也可能会发散,但仍然不能很好地工作。“ Spanner”具有原子钟,并且同步似乎只有几微秒。我们为什么不选择呢?我们不假定我们的用户有内置的原子钟。当它们出现在每台笔记本电脑中时,就会出现某种超酷的GPS同步-那么是的……同时,可能的最佳选择是亚马逊,狂热者基地……因此,我们使用了其他手表。混合时钟
这实际上是在确保因果一致性的同时打勾“ MongoBD”的原因。他们是什么混合体?混合是一个标量值,但它包含两个组成部分:
- 第一个是unix时代(自“计算机世界开始”以来已经过去了几秒钟)。
- 第二个是一些增量,也是一个32位unsigned int。
仅此而已。有这样一种方法:负责时间的部分始终与时钟同步;每次发生更新时,该部分就会与时钟同步,结果表明时间始终或多或少是正确的,而增量允许您区分在同一时间发生的事件。为什么这对MongoBD很重要?因为它允许您在特定的时间点创建某种备份还原器,即事件是按时间索引的。当需要一些事件时,这一点很重要。对于数据库,事件是在特定时间发生的数据库更改。我只会告诉您最重要的原因(请不要告诉任何人)!我们这样做是因为MongoDB OpLog中的有序索引数据看起来像这样。OpLog是一种数据结构,它绝对包含数据库中的所有更改:它们首先进入OpLog,然后在它是复制日期或分片的情况下,它们已经被应用于Storage本身。那是主要原因。尽管如此,开发数据库还是有实际要求的,这意味着它应该很简单-很少的代码,需要重写和测试的坏东西越少越好。混合手表将我们的操作日志编入索引这一事实极大地帮助了我们,使我们能够做出正确的选择。在第一个原型上,它确实获得了回报,并且以某种方式神奇地起作用。太酷了!时钟同步
科学文献中描述了几种同步方法。我说的是当我们有两个不同的分片时的同步。如果存在一个副本集,则无需在那里进行同步:它是一个“单主服务器”;我们有一个OpLog,其中包含所有更改-在这种情况下,所有内容都已在“ Oplog”本身中按顺序排序。但是,如果我们有两个不同的分片,那么时间同步就很重要。这里矢量时钟提供了更多帮助!但是我们没有它们。 第二个是心跳。您可以交换每单位时间出现的一些信号。但是Hartbits太慢了,我们无法为客户提供延迟。当然,真正的时间是一件奇妙的事情。但是,这再次可能是未来。尽管已经可以完成Atlas,但已经有了快速的“ Amazonian”时间同步器。但是,并非所有人都能使用。闲聊是指所有消息都包含时间。这大致就是我们使用的。节点之间的每条消息,驱动程序,数据节点的路由器,MongoDB的所有内容绝对都是某些要素,而数据库组件则包含数小时的流量。他们在任何地方都具有混合时间的含义,因此可以传输。64位?它允许,这是可能的。
第二个是心跳。您可以交换每单位时间出现的一些信号。但是Hartbits太慢了,我们无法为客户提供延迟。当然,真正的时间是一件奇妙的事情。但是,这再次可能是未来。尽管已经可以完成Atlas,但已经有了快速的“ Amazonian”时间同步器。但是,并非所有人都能使用。闲聊是指所有消息都包含时间。这大致就是我们使用的。节点之间的每条消息,驱动程序,数据节点的路由器,MongoDB的所有内容绝对都是某些要素,而数据库组件则包含数小时的流量。他们在任何地方都具有混合时间的含义,因此可以传输。64位?它允许,这是可能的。它们如何一起工作?
在这里,我看一个简化的副本集。有小学和中学。辅助服务器执行复制,并且并不总是与主服务器完全同步。在“ Primaries”中有一个带有一定时间值的插入(insert)。如果最大,则此插入将内部计数器增加11。或者如果时钟更大,它将检查时钟值并按时钟同步。这使您可以按时间排序。在他记录之后,一个重要的时刻发生了。小时数在“ MongoDB”中,并且仅在“ Oplog”中记录时才增加。这是一个更改系统状态的事件。绝对在所有经典文章中,事件都被视为进入节点的消息:消息已到达-这意味着系统已更改其状态。这是由于以下事实:在研究过程中无法完全理解如何解释此消息。我们可以肯定地知道,如果它没有反映在“ Oplog”中,则不会以任何方式进行解释,只有“ Oplog”中的条目会改变系统的状态。这为我们简化了一切:模型简化并允许我们在一个副本集和许多其他有用的东西的框架内进行组织。它返回已经记录在“ Oplog”中的值-我们知道在“ Oplog”中该值已经存在,并且其时间为12。现在,例如,读取是从另一个节点(中学)开始的,并且它已经在ClusterTime本身之后传输信息。他说:“我需要至少在12点或12点之后发生的一切”(请参见上图)。这就是所谓的因果一致(CAT)。从理论上讲,这是一个时间片,它本身是一致的。在这种情况下,我们可以说这是在时间12观察到的系统状态。现在这里什么也没有,因为它似乎模拟了Secondary需要从Primary复制数据的情况。他正在等待...现在数据来了-返回这些值。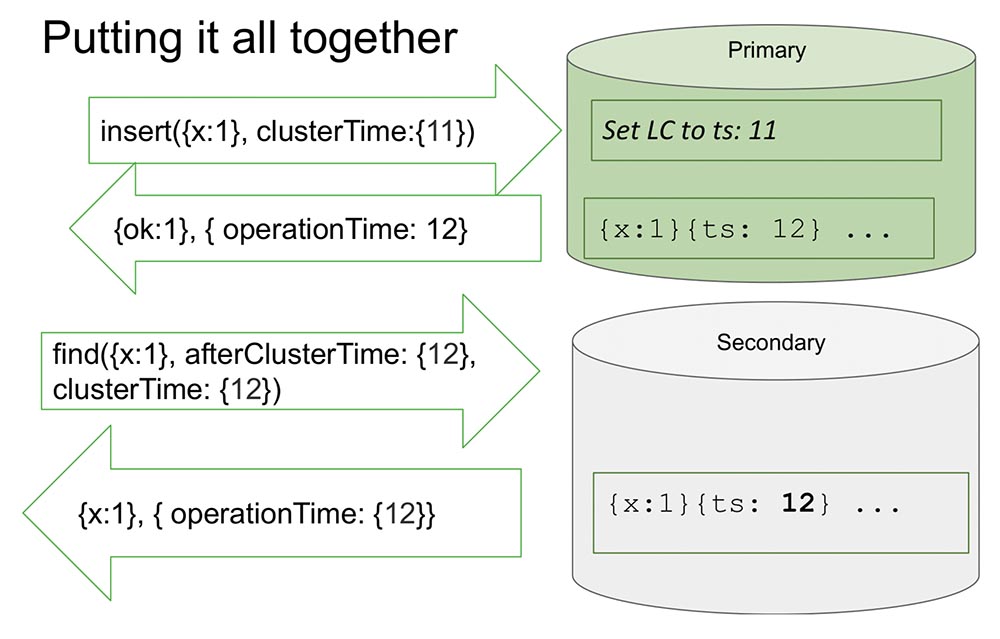 就是这样。几乎。“几乎”是什么意思?假设有人阅读并理解了这一切的工作原理。我意识到,每次ClusterTime发生时,它都会更新内部逻辑时钟,然后下一条记录将增加一。此功能占用20行。假设此人发送的最大可能的64位数字减一。为什么减一?因为将内部时钟替换为该值(显然,这是最大的可能,并且比当前时间更多),所以“ Olog”中将有一个条目,并且时钟将再增加一个-并且已经有一个最大值(仅存在所有单位,无处可去) ,无符号整数)。显然,在此之后,系统将变得完全无法访问。它只能卸下,清洁-大量的手工工作。完全可用性:
就是这样。几乎。“几乎”是什么意思?假设有人阅读并理解了这一切的工作原理。我意识到,每次ClusterTime发生时,它都会更新内部逻辑时钟,然后下一条记录将增加一。此功能占用20行。假设此人发送的最大可能的64位数字减一。为什么减一?因为将内部时钟替换为该值(显然,这是最大的可能,并且比当前时间更多),所以“ Olog”中将有一个条目,并且时钟将再增加一个-并且已经有一个最大值(仅存在所有单位,无处可去) ,无符号整数)。显然,在此之后,系统将变得完全无法访问。它只能卸下,清洁-大量的手工工作。完全可用性: 此外,如果将其复制到其他位置,则整个集群都将处于瘫痪状态。任何人都可以非常快速且简单地组织的绝对不可接受的情况!因此,我们认为这一刻是最重要的时刻。怎么预防呢?
此外,如果将其复制到其他位置,则整个集群都将处于瘫痪状态。任何人都可以非常快速且简单地组织的绝对不可接受的情况!因此,我们认为这一刻是最重要的时刻。怎么预防呢?我们的方法是签署clusterTime
因此它在消息中传输(蓝色文本之前)。但是我们也开始生成签名(蓝色文本): 签名是由存储在数据库内部,受保护范围内的密钥生成的;它已生成,更新(用户什么都看不到)。生成哈希,并在创建过程中对每个消息进行签名,并在收到消息后对其进行验证。人们可能会想到一个问题:“它放慢了多少?”我说过,它应该可以快速运行,尤其是在没有此功能的情况下。在这种情况下,使用因果一致性是什么意思?这将显示afterClusterTime参数。没有它,它将无论如何只会传递值。从3.6版开始,闲聊总能奏效。如果我们不停地生成签名,那么即使没有功能,这也会减慢系统速度,这不符合我们的方法和要求。我们做了什么?
签名是由存储在数据库内部,受保护范围内的密钥生成的;它已生成,更新(用户什么都看不到)。生成哈希,并在创建过程中对每个消息进行签名,并在收到消息后对其进行验证。人们可能会想到一个问题:“它放慢了多少?”我说过,它应该可以快速运行,尤其是在没有此功能的情况下。在这种情况下,使用因果一致性是什么意思?这将显示afterClusterTime参数。没有它,它将无论如何只会传递值。从3.6版开始,闲聊总能奏效。如果我们不停地生成签名,那么即使没有功能,这也会减慢系统速度,这不符合我们的方法和要求。我们做了什么?做快点!
一件很简单的事,但是技巧很有趣-我会分享的,也许有人会感兴趣。我们有一个哈希,用于存储签名数据。所有数据都通过缓存。缓存不专门签署时间,而是签署范围。当某个值到达时,我们生成一个Range,屏蔽最后16位,然后对该值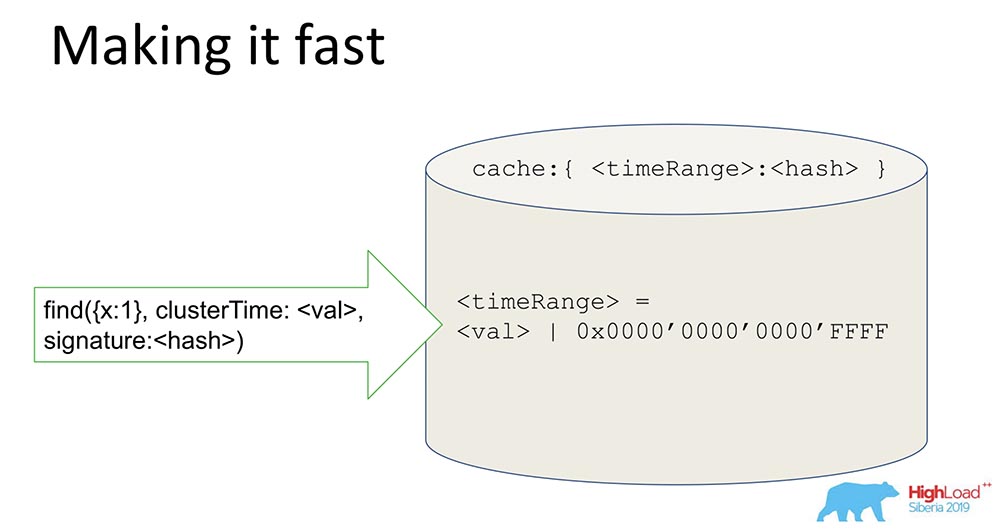 签名:通过接收这样的签名,我们(有条件地)将系统加速了65千倍。效果很好:当他们进行实验时,我们进行一致更新的时间实际上减少了1万次。显然,当它们矛盾时,这是行不通的。但在大多数实际情况下,这是可行的。Range签名与签名的组合解决了安全性问题。
签名:通过接收这样的签名,我们(有条件地)将系统加速了65千倍。效果很好:当他们进行实验时,我们进行一致更新的时间实际上减少了1万次。显然,当它们矛盾时,这是行不通的。但在大多数实际情况下,这是可行的。Range签名与签名的组合解决了安全性问题。我们学到了什么?
我们从中学到的经验教训:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- 最后是我们必须考虑不同的想法,并将几篇大体不同的文章组合成一种方法。例如,签名的想法来自一篇检查Paxos协议的文章,该协议针对授权协议内部的非拜占庭式Faylor,授权协议之外的拜占庭式协议...总的来说,这正是我们最终所做的。
这里绝对没有新东西!但是,一旦我们将它们混合在一起……就好像说奥利维尔沙拉食谱是胡说八道,因为鸡蛋,蛋黄酱和黄瓜已经想出来了……这是同一回事。
 在此我将结束。谢谢!
在此我将结束。谢谢!问题
观众提出的问题(以下简称-B): -谢谢Michael的报告!时间的主题很有趣。您正在使用闲聊。他们说每个人都有自己的时间,每个人都知道自己的当地时间。据我了解,我们有一个驱动程序-可能有很多具有驱动程序的客户,查询计划程序,很多碎片……但是如果我们突然出现差异,系统将如何处理:有人决定他待一会儿前方,有人-落后一分钟?我们将在哪里找到自己?MT: -真的是个好问题!我只是想谈谈分片。如果我正确理解了这个问题,那么我们会遇到这种情况:分片1和分片2会从这两个分片中读取数据-它们之间存在差异,它们不会相互影响,因为它们知道的时间不同,尤其是它们存在于oplog中。假设分片1记录了100万条记录,而分片2却什么也没做,并且请求来自两个分片。并且第一个在集群时间之后超过一百万。正如我所解释的,在这种情况下,分片2将永远不会响应。问: -我想知道他们如何同步并选择一个逻辑时间?MT: -非常容易同步。 Shard,在afterClusterTime到来时,他没有在“捕获”中找到时间-不批准启动。就是说,他用手举起手达到了这一价值。这意味着它没有与该查询匹配的事件。他人为地创建了此事件,因此成为因果一致。问: -然后,是否仍然有其他事件在网络上丢失了?公吨:-分片的排列方式使它们不再出现,因为它是单个主片。如果他已经录制过,那么它们不会来,但是会来的。不可能发生某事被卡住的情况,然后他不做任何写操作,然后这些事件到来-并违反了因果一致性。当他不写信时,他们都必须下一步(他将等待他们)。 在:-关于线路我有几个问题。因果一致性假定存在需要执行的特定操作队列。如果我们丢掉一个包裹会怎样?因此,第十名消失了,十一岁……十二岁消失了,其他所有人都在等待实现。突然我们的车死了,我们无能为力。在执行之前是否有最大队列长度累积?当任何一种状态丢失时,会发生什么致命故障?而且,如果我们写下以前存在某种状态,那我们应该以某种方式开始吗?他们没有从他那里逼出来!公吨:-也是一个很好的问题!我们在做什么?仲裁读取表示,MongoDB具有仲裁记录的概念。消息什么时候可以消失?当记录不是法定人数或阅读不是法定人数时(某些垃圾也可能残留)。关于因果一致性,我们进行了一项大型的实验测试,结果是,当记录和阅读不达到法定人数时,就会发生因果一致性违规。正是您所说的!我们的提示:使用因果一致性时,至少应使用法定人数的读数。在这种情况下,即使丢失了仲裁记录也不会丢失任何信息。这是一种正交的情况:如果用户不希望丢失数据,则需要使用仲裁记录。因果一致性不能保证耐用性。持久性保证由复制和与复制关联的机制提供。问: -当我们创建一个分片为我们做的实例(分别不是主机,而是从机)时,它依赖于自己计算机的Unix时间或“主机”的时间;第一次同步还是定期同步?公吨:-现在我要讲清楚。碎片(即水平分区)-始终存在主分区。在分片中可能有一个“母版”,并且可能有副本。但是分片始终支持写入,因为它必须支持特定的域(Primary位于分片中)。问: -也就是说,一切都完全取决于“主人”吗?始终使用“主”时间吗?MT: -是的。您可以用比喻的方式说:当“主”中的“ Olog”中有录音时,时钟在滴答。问: -我们有一个可以联系的客户,他不需要了解时间吗?公吨:-一般来说,您无需了解任何信息!如果我们谈论它如何在客户端上工作:在客户端上,当他想使用因果一致性时,他需要打开一个会话。现在一切就绪:会话中的事务和获取权限……会话是客户端发生的逻辑事件的顺序。如果他打开此会话并说他想要因果一致性(如果默认情况下,该会话支持因果一致性),则一切都会自动进行。驱动程序会记住此时间,并在收到新消息时增加时间。它会记住哪个答案从返回数据的服务器返回了前一个答案。以下请求将包含afterCluster(“时间大于此时间”)。客户不需要完全不知道!这对他来说绝对是不透明的。如果人们使用这些功能,该怎么办?首先,您可以安全地读取次要文件:可以使用Primary进行编写,并可以从地理上复制的次要文件中进行读取,并确保它可以工作。同时,在Primary上记录的会话甚至可以转移到Secondary,即,您不能使用一个会话,而可以使用多个会话。问: -最终一致性主题与新的计算科学层-CRDT(无冲突复制数据类型)数据类型密切相关。您是否考虑过将这些类型的数据集成到数据库中,您对此有何评论?MT: -好问题! CRDT对于写冲突很有意义:在MongoDB中-单个主机。在:-我有一个关于devops的问题。在现实世界中,会发生这样的耶稣会情况,即拜占庭式的失败发生,并且受保护的边界内的恶人开始遵守协议,以特殊的方式发送工艺包吗?
在:-关于线路我有几个问题。因果一致性假定存在需要执行的特定操作队列。如果我们丢掉一个包裹会怎样?因此,第十名消失了,十一岁……十二岁消失了,其他所有人都在等待实现。突然我们的车死了,我们无能为力。在执行之前是否有最大队列长度累积?当任何一种状态丢失时,会发生什么致命故障?而且,如果我们写下以前存在某种状态,那我们应该以某种方式开始吗?他们没有从他那里逼出来!公吨:-也是一个很好的问题!我们在做什么?仲裁读取表示,MongoDB具有仲裁记录的概念。消息什么时候可以消失?当记录不是法定人数或阅读不是法定人数时(某些垃圾也可能残留)。关于因果一致性,我们进行了一项大型的实验测试,结果是,当记录和阅读不达到法定人数时,就会发生因果一致性违规。正是您所说的!我们的提示:使用因果一致性时,至少应使用法定人数的读数。在这种情况下,即使丢失了仲裁记录也不会丢失任何信息。这是一种正交的情况:如果用户不希望丢失数据,则需要使用仲裁记录。因果一致性不能保证耐用性。持久性保证由复制和与复制关联的机制提供。问: -当我们创建一个分片为我们做的实例(分别不是主机,而是从机)时,它依赖于自己计算机的Unix时间或“主机”的时间;第一次同步还是定期同步?公吨:-现在我要讲清楚。碎片(即水平分区)-始终存在主分区。在分片中可能有一个“母版”,并且可能有副本。但是分片始终支持写入,因为它必须支持特定的域(Primary位于分片中)。问: -也就是说,一切都完全取决于“主人”吗?始终使用“主”时间吗?MT: -是的。您可以用比喻的方式说:当“主”中的“ Olog”中有录音时,时钟在滴答。问: -我们有一个可以联系的客户,他不需要了解时间吗?公吨:-一般来说,您无需了解任何信息!如果我们谈论它如何在客户端上工作:在客户端上,当他想使用因果一致性时,他需要打开一个会话。现在一切就绪:会话中的事务和获取权限……会话是客户端发生的逻辑事件的顺序。如果他打开此会话并说他想要因果一致性(如果默认情况下,该会话支持因果一致性),则一切都会自动进行。驱动程序会记住此时间,并在收到新消息时增加时间。它会记住哪个答案从返回数据的服务器返回了前一个答案。以下请求将包含afterCluster(“时间大于此时间”)。客户不需要完全不知道!这对他来说绝对是不透明的。如果人们使用这些功能,该怎么办?首先,您可以安全地读取次要文件:可以使用Primary进行编写,并可以从地理上复制的次要文件中进行读取,并确保它可以工作。同时,在Primary上记录的会话甚至可以转移到Secondary,即,您不能使用一个会话,而可以使用多个会话。问: -最终一致性主题与新的计算科学层-CRDT(无冲突复制数据类型)数据类型密切相关。您是否考虑过将这些类型的数据集成到数据库中,您对此有何评论?MT: -好问题! CRDT对于写冲突很有意义:在MongoDB中-单个主机。在:-我有一个关于devops的问题。在现实世界中,会发生这样的耶稣会情况,即拜占庭式的失败发生,并且受保护的边界内的恶人开始遵守协议,以特殊的方式发送工艺包吗? MT: -外围的邪恶人物就像特洛伊木马!外围的邪恶人会做很多坏事。问: -很明显,大致来说,在服务器上留下了一个漏洞,您可以通过该漏洞粘住大象动物园并永久崩溃整个集群……手动恢复将花费一些时间……从某种程度上来说,这是错误的。另一方面,这很好奇:在现实生活中,在实践中是否存在自然发生类似内部攻击的情况?公吨:-由于我在现实生活中很少遇到安全漏洞,所以我不能说-也许它们确实发生了。但是,如果我们谈论发展理念,那么我们会这样认为:我们有一个边界,可以为安全提供保障。这是一座城堡,一堵墙;在外围您可以做任何您想做的事。显然,有些用户只能看,有些用户可以删除目录。根据权利的不同,用户可能造成的损害可能是鼠标,也可能是大象。显然,拥有完全权限的用户可以做任何事情。没有广泛的伤害权的使用者所造成的伤害要小得多。特别是,他不能破坏系统。在:-在安全的范围内,有人为服务器设置了意外的协议,以将服务器设置为患有癌症,如果幸运的话,那么整个集群……是那么“好”吗?MT: -我从未听说过这样的事情。用这种方法可以填满服务器的事实并不是秘密。要在协议中充实,可以是协议的授权用户,可以在消息中写类似的内容...实际上,这是不可能的,因为无论如何都会对其进行验证。可以为不需要的用户禁用此身份验证-这就是他们的问题;粗略地说,它们自己摧毁了墙壁,您可以在那儿塞大象,这会践踏……一般来说,您可以打扮成修理工,快来拿!在:-感谢您的报告。谢尔盖(Yandex)。在“旺”中,有一个常量限制副本集中投票成员的数量,该常量为7(七个)。为什么这是常数?为什么这不是某种参数?MT: -副本集,我们也有40个节点。总是有多数。我不知道哪个版本...问: -在副本集中,您可以运行非投票成员,但可以投票-最多7个。那么,如果我们将副本集拉到3个数据中心,那么如何关闭?一个数据中心可以轻松关闭,而另一台计算机掉线。MT: -这已经超出了报告的范围。这是一个常见的问题。也许那我可以告诉他。
MT: -外围的邪恶人物就像特洛伊木马!外围的邪恶人会做很多坏事。问: -很明显,大致来说,在服务器上留下了一个漏洞,您可以通过该漏洞粘住大象动物园并永久崩溃整个集群……手动恢复将花费一些时间……从某种程度上来说,这是错误的。另一方面,这很好奇:在现实生活中,在实践中是否存在自然发生类似内部攻击的情况?公吨:-由于我在现实生活中很少遇到安全漏洞,所以我不能说-也许它们确实发生了。但是,如果我们谈论发展理念,那么我们会这样认为:我们有一个边界,可以为安全提供保障。这是一座城堡,一堵墙;在外围您可以做任何您想做的事。显然,有些用户只能看,有些用户可以删除目录。根据权利的不同,用户可能造成的损害可能是鼠标,也可能是大象。显然,拥有完全权限的用户可以做任何事情。没有广泛的伤害权的使用者所造成的伤害要小得多。特别是,他不能破坏系统。在:-在安全的范围内,有人为服务器设置了意外的协议,以将服务器设置为患有癌症,如果幸运的话,那么整个集群……是那么“好”吗?MT: -我从未听说过这样的事情。用这种方法可以填满服务器的事实并不是秘密。要在协议中充实,可以是协议的授权用户,可以在消息中写类似的内容...实际上,这是不可能的,因为无论如何都会对其进行验证。可以为不需要的用户禁用此身份验证-这就是他们的问题;粗略地说,它们自己摧毁了墙壁,您可以在那儿塞大象,这会践踏……一般来说,您可以打扮成修理工,快来拿!在:-感谢您的报告。谢尔盖(Yandex)。在“旺”中,有一个常量限制副本集中投票成员的数量,该常量为7(七个)。为什么这是常数?为什么这不是某种参数?MT: -副本集,我们也有40个节点。总是有多数。我不知道哪个版本...问: -在副本集中,您可以运行非投票成员,但可以投票-最多7个。那么,如果我们将副本集拉到3个数据中心,那么如何关闭?一个数据中心可以轻松关闭,而另一台计算机掉线。MT: -这已经超出了报告的范围。这是一个常见的问题。也许那我可以告诉他。
一点广告:)
感谢您与我们在一起。你喜欢我们的文章吗?想看更多有趣的资料吗?通过下订单或向您的朋友推荐给开发人员的基于云的VPS,最低价格为4.99美元,这是我们为您发明的入门级服务器 的独特类似物:关于VPS(KVM)E5-2697 v3(6核)的全部真相10GB DDR4 480GB SSD 1Gbps从$ 19还是如何划分服务器?(RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。阿姆斯特丹的Equinix Tier IV数据中心的戴尔R730xd便宜2倍吗?仅在荷兰,我们有2台Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100电视!戴尔R420-2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB-$ 99起!阅读有关如何构建基础设施大厦的信息。使用Dell R730xd E5-2650 v4服务器花费一欧元9000欧元的c类? Source: https://habr.com/ru/post/undefined/
All Articles