 当分析问题超出了预建工具的范围时,可能是时候选择一个数据库进行分析了。您不应该将查询脚本编写到工作数据库中,因为您可以更改数据顺序,并且很可能会使应用程序变慢。如果分析师或工程师在那里工作,您也可能会意外删除重要信息。为了进行分析,您需要单独的数据库类型。但是哪一个是真的?在这篇文章中,我们将考虑为刚刚开始工作的普通公司提供的优惠和最佳实践。无论您选择哪种设置,您都可以在将来找到一个折衷方案,以提高我们在此讨论的性能。与大量客户合作,我们发现必须考虑的最重要标准是:
当分析问题超出了预建工具的范围时,可能是时候选择一个数据库进行分析了。您不应该将查询脚本编写到工作数据库中,因为您可以更改数据顺序,并且很可能会使应用程序变慢。如果分析师或工程师在那里工作,您也可能会意外删除重要信息。为了进行分析,您需要单独的数据库类型。但是哪一个是真的?在这篇文章中,我们将考虑为刚刚开始工作的普通公司提供的优惠和最佳实践。无论您选择哪种设置,您都可以在将来找到一个折衷方案,以提高我们在此讨论的性能。与大量客户合作,我们发现必须考虑的最重要标准是:- 分析的数据类型
- 您有多少数据?
- 工程团队的重点
- 您需要多快的信息
您分析什么类型的数据?
考虑一下要分析的数据。它们是否适合像大型Excel电子表格那样的行和列?还是将它们放在Word文档中会更有意义?如果您回答了Excel,则关系数据库(如Postgres,MySQL,Amazon Redshift或BigQuery)将满足您的需求。当您确切地知道要接收什么数据以及它们如何相互关联时,这些结构化的关系数据库非常有用-基本上,行和列如何关联。对于大多数类型的用户分析,关系数据库都能很好地工作。用户属性(例如名称,电子邮件和计费方案)非常适合该表,例如用户事件及其属性。另一方面,如果您的数据适合放在一张纸上,则应引用非关系(NoSQL)数据库,例如Hadoop或Mongo。非关系型数据库的特点是拥有大量的半结构化数据的私有值(百万)。半结构化数据的经典示例是诸如电子邮件,书籍和社交网络之类的文本,视听数据和地理数据。如果您要进行大量文本挖掘,语言处理或图像处理,则很可能需要使用非关系数据存储。
您要处理多少数据?
下一个要问自己的问题是您要处理多少数据。您拥有的数据越多,非关系数据库将越有用,因为它不会对传入数据施加限制,从而使您可以更快地写入数据库。 这些不是严格的限制,并且每个数据库可以根据各种因素处理或多或少的数据,但是我们发现每个数据库都可以在这些限制内完美运行。如果您的数据少于1 TB,那么使用Postgres,您将获得良好的性能。但是它的速度减慢了大约6 TB。如果您喜欢MySQL但需要稍大一点的扩展,Aurora(Amazon自己的版本)可以达到64 TB。对于PB级大小,Amazon Redshift通常是一个不错的选择,因为它已针对高达2PB的分析进行了优化。对于并行处理甚至是MOAR数据,可能是时候来看一下Hadoop了。但是,AWS告诉我们他们在Redshift上运行Amazon.com,因此,如果您拥有一流的DBA团队,则可以扩展到超过2PB“限制”。
这些不是严格的限制,并且每个数据库可以根据各种因素处理或多或少的数据,但是我们发现每个数据库都可以在这些限制内完美运行。如果您的数据少于1 TB,那么使用Postgres,您将获得良好的性能。但是它的速度减慢了大约6 TB。如果您喜欢MySQL但需要稍大一点的扩展,Aurora(Amazon自己的版本)可以达到64 TB。对于PB级大小,Amazon Redshift通常是一个不错的选择,因为它已针对高达2PB的分析进行了优化。对于并行处理甚至是MOAR数据,可能是时候来看一下Hadoop了。但是,AWS告诉我们他们在Redshift上运行Amazon.com,因此,如果您拥有一流的DBA团队,则可以扩展到超过2PB“限制”。您的工程团队专注于什么?
这是讨论数据库时要问自己的另一个重要问题。总体团队越小,工程师将更多的精力主要放在产品创建而不是数据处理和管理上。您可以投入这些项目的人数将极大地影响您的选择。使用一些工程资源,您有更多选择-您可以转到关系数据库或非关系数据库。关系数据库比NoSQL花费的时间更少。如果您有几个正在从事安装工作的工程师,但是无法带任何人使用该服务,请选择诸如Postgres,Google SQL(可选的MySQL托管)或Segment Warehouses之类的东西。(Redshift托管)可能比Redshift,Aurora或BigQuery更好,因为它们需要定期纠正数据处理。如果您有更多的服务时间,则选择Redshift或BigQuery将提供更快,更大规模的查询。关系数据库还有另一个优点:您可以使用SQL查询它们。 SQL对分析人员和工程师而言都是众所周知的,并且比大多数编程语言更易于学习。另一方面,对半结构化数据的分析通常至少需要具有面向对象编程的经验,或者更好的是,需要编写用于处理大数据的代码的经验。即使Hunk等分析工具问世对于适用于MongoDB的Hadoop或Slamdata,您将需要经验丰富的分析师或数据专家来分析这些类型的数据库。您需要多少数据?
尽管“实时分析”在欺诈检测和系统监视等案例中非常流行,但大多数分析并不需要实时数据或即时分析。例如,当您回答问题时,是什么原因导致用户外流或人们如何从您的应用程序切换到您的网站,可以稍稍延迟(每小时或每天一次)访问数据。您的数据不会每分钟更改一次。因此,如果您主要从事实际分析,则应参考针对分析优化的数据库,例如Redshift或BigQuery。此类数据库旨在容纳大量数据并快速读取和合并数据,从而使查询速度更快。他们还可以在有人执行清理过程,调整大小和监视集群时足够快(每小时)下载数据。如果您绝对需要实时数据,则应使用非结构化数据库,例如Hadoop。您可以设计Hadoop数据库,以便将数据非常快速地加载到其中,尽管查询它可能需要更长的时间,具体取决于RAM使用情况,可用磁盘空间和数据结构。Postgres与 亚马逊Redshift与 谷歌bigquery
您可能已经意识到,关系数据库将是分析大多数类型的用户行为的最佳选择。有关您的用户如何与您的网站和应用程序交互的信息可以很容易地适应结构化格式。analytics.track('Completed Order') — select * from ios.completed_order
 那么问题是要使用哪个SQL数据库?必须考虑四个标准。
那么问题是要使用哪个SQL数据库?必须考虑四个标准。尺寸与 速度
当您需要速度时,值得考虑使用Postgres:对于小于1TB的数据库,Postgres加载数据和查询的速度非常快。另外,它是可用的。当您接近6TB(从Amazon RDS继承)时,您的查询将运行缓慢。因此,当您需要更大的尺寸时,我们通常建议您使用Redshift。我们的经验表明,Redshift具有最佳的性价比。SQL高亮
Redshift建立在Postgres的变体上,并且都支持良好的旧SQL。Redshift并不支持postgres支持的所有数据类型和功能,但它比具有自己的SQL的BigQuery更接近行业标准。与许多其他基于SQL的系统不同,BigQuery使用逗号分隔的语法来表示表联接,而不是根据SQL文档。这意味着,如果不加注意,SQL查询可能会导致错误或意外结果。因此,我们遇到的许多团队无法说服他们的分析师学习BigQuery SQL。第三方生态系统
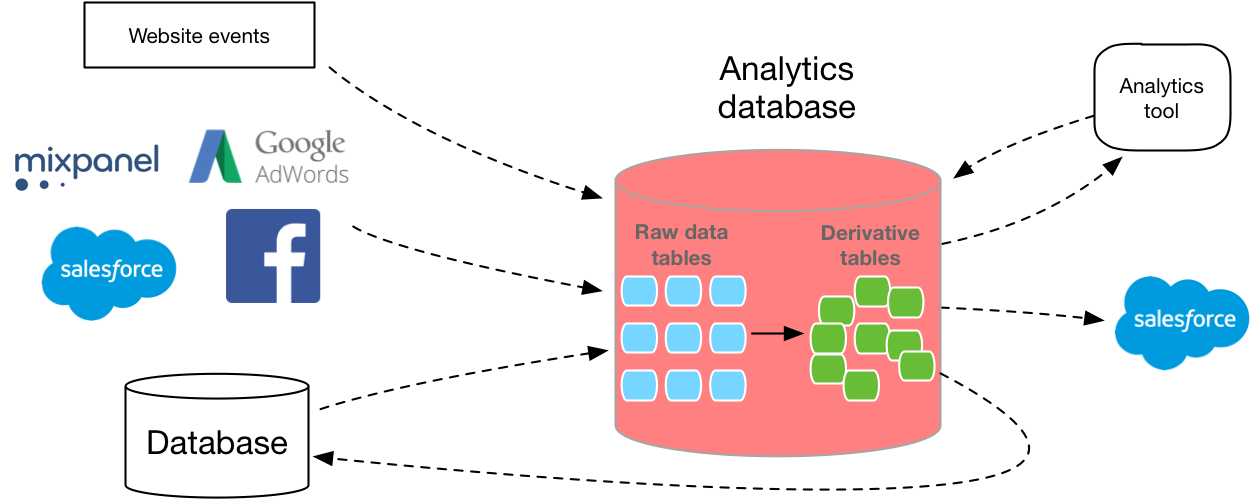
您的数据仓库很少单独运行。您需要将数据放入数据库中,此外,还需要使用某种软件进行分析。 (除非您从命令行运行SQL查询)。因此,经常喜欢Redshift的人拥有非常庞大的第三方工具生态系统。 AWS具有细分数据仓库等功能,可将数据从分析API加载到Redshift中,并且还可以与市场上几乎所有的数据可视化工具一起使用。较少的第三方服务连接到Google,因此将相同的数据移至BigQuery可能需要花费更多的时间进行开发,并且BI软件的选择不会太多。您可以看到亚马逊合作伙伴在这里和谷歌在这里。但是,如果您已经使用Google Cloud Storage而不是Amazon S3,则留在Google生态系统中可能会有所帮助。如果这两种服务都已经存在于相应的云存储资源库中,那么它们将简化数据加载,因此,尽管它们不会违反使用条款,但是如果您停止使用这些提供者之一,则将更加容易。训练
既然您对使用哪个数据库有了更清晰的了解,下一步就是弄清楚如何将数据收集到数据库中。许多新的数据库开发人员低估了构建可伸缩数据管道的难度。您必须编写自己的提取层,数据收集API,查询和转换层。每个人都必须扩展。另外,您需要根据每列的大小和类型确定正确的布局。 MVP将生产数据库复制到新实例,但这通常意味着使用未针对分析进行优化的数据库。幸运的是,市场上有多种选择可以帮助您解决这些障碍并自动为您执行ETL。但是,无论是您自己开发还是购买,使用SQL获取数据都是值得的。根据初始用户数据,只有借助灵活的SQL格式,您才能详细回答有关客户正在做什么的问题,准确评估分布,了解跨平台行为,为特定公司创建仪表板等等。