大规模PostgreSQL查询优化。基里尔·波罗维科夫(张量)
该报告提供了一些方法,这些方法允许您在每天有数百万个SQL查询和数百个受控PostgreSQL服务器时监视SQL查询的性能。哪些技术解决方案可以使我们有效地处理如此大量的信息,以及它如何促进普通开发人员的生活。谁有兴趣分析特定问题以及在PostgreSQL中优化 SQL查询和解决典型DBA问题的各种技术?您还可以阅读有关此主题的一系列文章。 我的名字叫Kirill Borovikov,我代表“ Tensor”公司。具体来说,我专门研究公司的数据库。今天,我将告诉您我们如何进行查询优化,当您不需要“拾取”单个请求的性能,而是需要整体解决问题时。当有数百万个请求时,您需要找到一些方法来解决这个大问题。总的来说,对我们的上百万客户来说,“张量”是VLSI-我们的应用:企业社交网络,用于内部和外部文档管理的视频通信解决方案,用于簿记和存储的会计系统...也就是说,这种用于集成业务管理的“大型机”,这是100多个不同的内部项目。为了确保他们都能正常工作和发展,我们在全国设有10个开发中心,他们有1000多名开发人员。自2008年以来,我们一直在使用PostgreSQL,并且已经积累了大量的处理数据- 超过400TB的客户数据,统计,分析和来自外部信息系统的数据。仅“生产中”大约有250台服务器,而我们监控的数据库服务器总数约为1000台
我的名字叫Kirill Borovikov,我代表“ Tensor”公司。具体来说,我专门研究公司的数据库。今天,我将告诉您我们如何进行查询优化,当您不需要“拾取”单个请求的性能,而是需要整体解决问题时。当有数百万个请求时,您需要找到一些方法来解决这个大问题。总的来说,对我们的上百万客户来说,“张量”是VLSI-我们的应用:企业社交网络,用于内部和外部文档管理的视频通信解决方案,用于簿记和存储的会计系统...也就是说,这种用于集成业务管理的“大型机”,这是100多个不同的内部项目。为了确保他们都能正常工作和发展,我们在全国设有10个开发中心,他们有1000多名开发人员。自2008年以来,我们一直在使用PostgreSQL,并且已经积累了大量的处理数据- 超过400TB的客户数据,统计,分析和来自外部信息系统的数据。仅“生产中”大约有250台服务器,而我们监控的数据库服务器总数约为1000台 。SQL是一种声明性语言。您不是在描述某事应该如何工作,而是要接收什么。 DBMS更了解如何进行JOIN-如何连接平板电脑,施加什么条件,按索引执行什么,不执行什么操作...一些DBMS接受提示:“不,以这样的队列连接这两个平板电脑”,而PostgreSQL则不这样。这是领先开发人员的自觉立场:“最好让我们完成查询优化程序,而不是让开发人员使用某种提示。”但是,尽管PostgreSQL不允许“外部”控制自己,但它完美地允许您查看执行查询时“内部”发生的情况以及问题所在。
。SQL是一种声明性语言。您不是在描述某事应该如何工作,而是要接收什么。 DBMS更了解如何进行JOIN-如何连接平板电脑,施加什么条件,按索引执行什么,不执行什么操作...一些DBMS接受提示:“不,以这样的队列连接这两个平板电脑”,而PostgreSQL则不这样。这是领先开发人员的自觉立场:“最好让我们完成查询优化程序,而不是让开发人员使用某种提示。”但是,尽管PostgreSQL不允许“外部”控制自己,但它完美地允许您查看执行查询时“内部”发生的情况以及问题所在。 通常,开发人员通常会遇到哪些经典问题? “在这里,我们已经满足了请求,一切都很缓慢,一切都挂起了,发生了某些事情……有些麻烦!”原因几乎总是相同的:
通常,开发人员通常会遇到哪些经典问题? “在这里,我们已经满足了请求,一切都很缓慢,一切都挂起了,发生了某些事情……有些麻烦!”原因几乎总是相同的:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
...对于其他一切,我们需要一个计划!我们需要查看服务器内部发生了什么。 PostgreSQL的查询执行计划是以文本表示形式的查询执行算法的树。计划者的分析结果是该算法被认为是最有效的。每个树节点都是一项操作:从表或索引中提取数据,构建位图,联接两个表,联接,相交或消除样本。完成请求是通过该树的节点的通道。要获得查询计划,最简单的方法是执行语句
PostgreSQL的查询执行计划是以文本表示形式的查询执行算法的树。计划者的分析结果是该算法被认为是最有效的。每个树节点都是一项操作:从表或索引中提取数据,构建位图,联接两个表,联接,相交或消除样本。完成请求是通过该树的节点的通道。要获得查询计划,最简单的方法是执行语句EXPLAIN。要获得所有真实属性,即实际上基于-执行查询EXPLAIN (ANALYZE, BUFFERS) SELECT ...。不好的地方:执行它时,它“在这里和现在”发生,因此仅适用于本地调试。如果您使用一些高负载的服务器,而该服务器正在承受大量数据更改,那么您会看到:在这里,我们对夏的要求较慢。”一个小时前半小时-在您运行并从日志中获取此请求,并将其再次传送到服务器时,整个数据集和统计信息都已更改。您执行它来调试-它运行速度很快!而且您不明白为什么,为什么这么慢。 为了了解在服务器上执行请求时的确切情况,聪明的人编写了auto_explain模块。几乎所有最常用的PostgreSQL发行版中都存在它,您只需在配置文件中激活它即可。如果他知道请求的执行时间比您告诉他的边界要长,那么他会为该请求获取计划的“快照”,并将其一起写入日志中。
为了了解在服务器上执行请求时的确切情况,聪明的人编写了auto_explain模块。几乎所有最常用的PostgreSQL发行版中都存在它,您只需在配置文件中激活它即可。如果他知道请求的执行时间比您告诉他的边界要长,那么他会为该请求获取计划的“快照”,并将其一起写入日志中。 现在一切似乎都很好,我们转到日志,然后在此处查看... [文字脚步声]。但是除了他这是一个很棒的计划外,我们无话可说,因为这需要11毫秒才能完成。一切似乎都很好-但实际发生的事情并不清楚。除了总时间,我们看不到太多。因为看这样的“ latuha”纯文本通常是人们所钟爱的。但是,即使它受到爱戴,尽管不舒服,但仍然存在更多主要问题:
现在一切似乎都很好,我们转到日志,然后在此处查看... [文字脚步声]。但是除了他这是一个很棒的计划外,我们无话可说,因为这需要11毫秒才能完成。一切似乎都很好-但实际发生的事情并不清楚。除了总时间,我们看不到太多。因为看这样的“ latuha”纯文本通常是人们所钟爱的。但是,即使它受到爱戴,尽管不舒服,但仍然存在更多主要问题:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
在这种情况下,请了解“谁是最薄弱的环节?” 几乎是不现实的。因此,即使是开发人员自己在“手册”中也写道:“理解计划是一门需要学习,体验的艺术……”。但是我们有1000个开发人员,每个开发人员都不会将这种经验传递给他们。我,你,他-他们知道,那边有人-不再在那里。也许他会学习,或者也许不会,但是他现在需要工作-他将从何处获得这种经验。计划可视化
因此,我们意识到,为了解决这些问题,我们需要对该计划进行良好的可视化。[文章]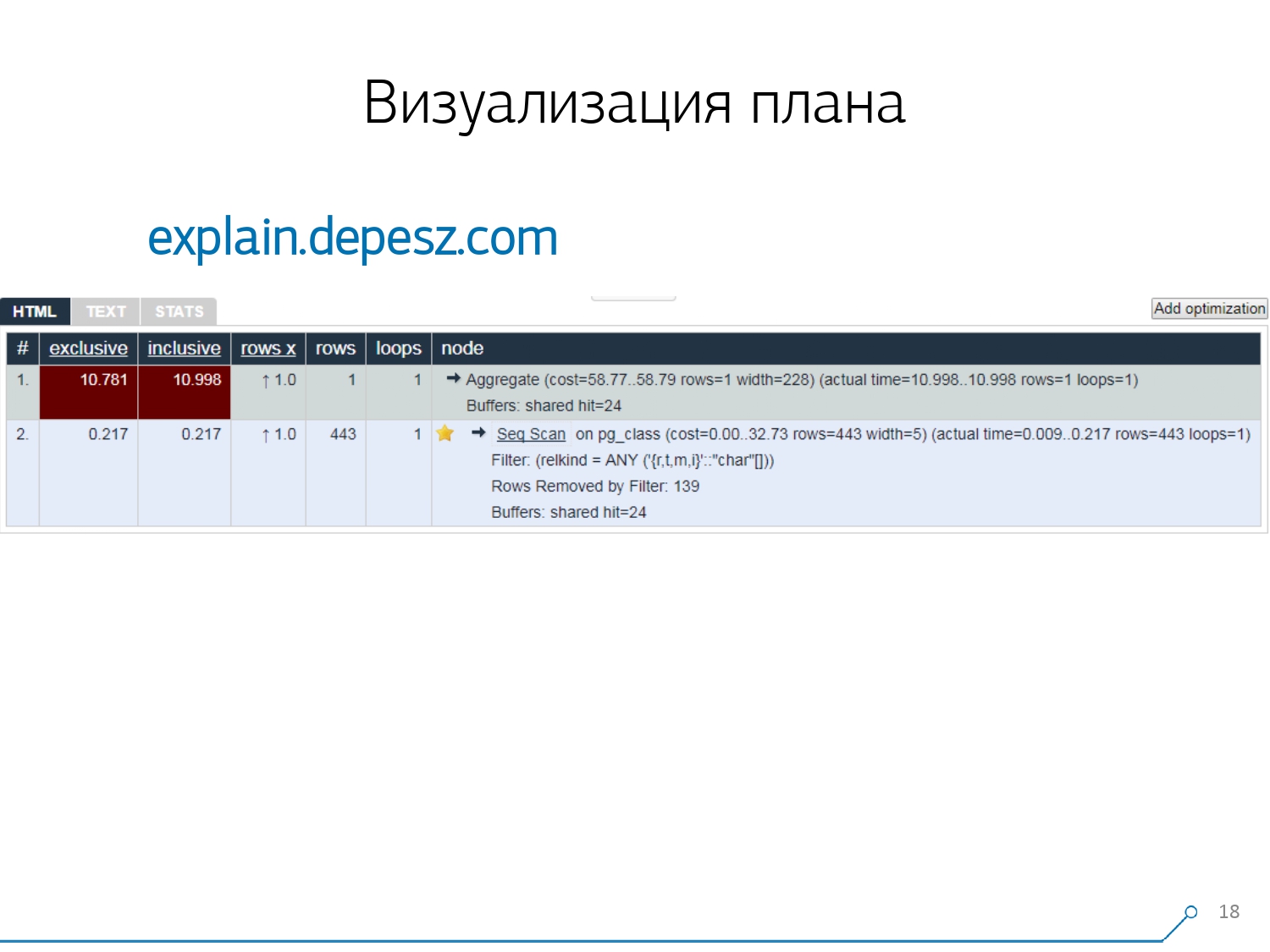 我们首先“围绕市场”-让我们在Internet上查看一般存在的内容。:从字面上看,有一两件事-但是,事实证明,相对那些或多或少研制的“活”的解决方案,也有极少数explain.depesz.com从休伯特Lubaczewski。在字段“输入”计划的文本表示的入口处,它向您显示带有已解析数据的板:
我们首先“围绕市场”-让我们在Internet上查看一般存在的内容。:从字面上看,有一两件事-但是,事实证明,相对那些或多或少研制的“活”的解决方案,也有极少数explain.depesz.com从休伯特Lubaczewski。在字段“输入”计划的文本表示的入口处,它向您显示带有已解析数据的板:- 正确的节点工作时间
- 整个子树上的总时间
- 检索到的并在统计上预期的记录数
- 节点主体本身
该服务还具有共享链接存档的功能。您将计划扔在那里,然后说:“嘿,瓦西亚,这是给您的链接,那里出了点问题。” 但是有一些小问题。首先,大量的复制粘贴。您取了一块原木,一次又一次地放在那里。其次,没有分析读取的数据量 -它显示的缓冲区非常多
但是有一些小问题。首先,大量的复制粘贴。您取了一块原木,一次又一次地放在那里。其次,没有分析读取的数据量 -它显示的缓冲区非常多EXPLAIN (ANALYZE, BUFFERS),在这里我们看不到。他根本不知道如何分解,理解和与他们合作。当您读取大量数据并了解可以在磁盘上错误地“分解”并缓存在内存中时,此信息非常重要。第三个缺点是该项目的发展非常薄弱。提交非常小,每六个月提交一次,Perl中的代码非常好。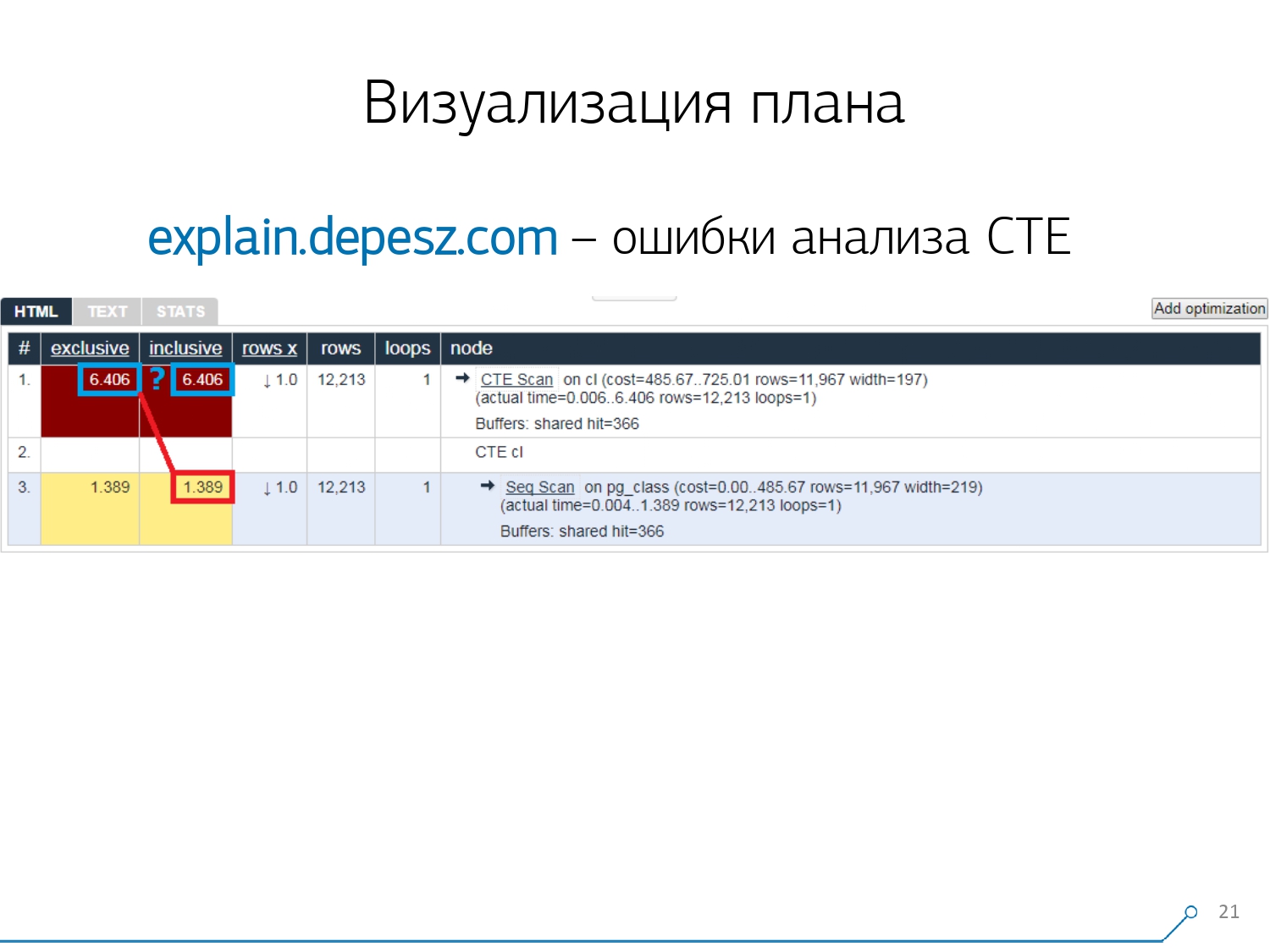 但是,所有这些都是“歌词”,可以以某种方式使用它,但是有一件事使我们无法使用这项服务。这些是通用表表达式(CTE)分析错误以及各种动态节点,例如InitPlan / SubPlan。如果您相信此图,那么我们每个节点的总执行时间大于整个请求的总执行时间。这很简单-CTE的生成时间没有从CTE Scan节点中减去。因此,我们不再知道正确的答案,CTE扫描本身需要花费多少。
但是,所有这些都是“歌词”,可以以某种方式使用它,但是有一件事使我们无法使用这项服务。这些是通用表表达式(CTE)分析错误以及各种动态节点,例如InitPlan / SubPlan。如果您相信此图,那么我们每个节点的总执行时间大于整个请求的总执行时间。这很简单-CTE的生成时间没有从CTE Scan节点中减去。因此,我们不再知道正确的答案,CTE扫描本身需要花费多少。 然后我们意识到是时候编写我们自己的了!每个开发人员都说:“现在,我们将编写自己的东西,它将变得超级棒!”他们采用了一个典型的Web服务堆栈:Node.js + Express上的核心,提取了Bootstrap并获得了漂亮的图表-D3.js。我们的期望是合理的-我们在两周内收到了第一个原型:
然后我们意识到是时候编写我们自己的了!每个开发人员都说:“现在,我们将编写自己的东西,它将变得超级棒!”他们采用了一个典型的Web服务堆栈:Node.js + Express上的核心,提取了Bootstrap并获得了漂亮的图表-D3.js。我们的期望是合理的-我们在两周内收到了第一个原型:- 自己的计划解析器
也就是说,现在我们通常可以从PostgreSQL生成的计划中解析任何计划。 - 正确分析动态节点 -CTE扫描,InitPlan,SubPlan
- 缓冲区分布的分析 -从内存中读取数据页,从本地缓存中读取数据,从磁盘中读取数据
- 获得可见性,
这样就不会在日志中“挖掘”,而是可以在图片中立即看到“最弱的链接”。
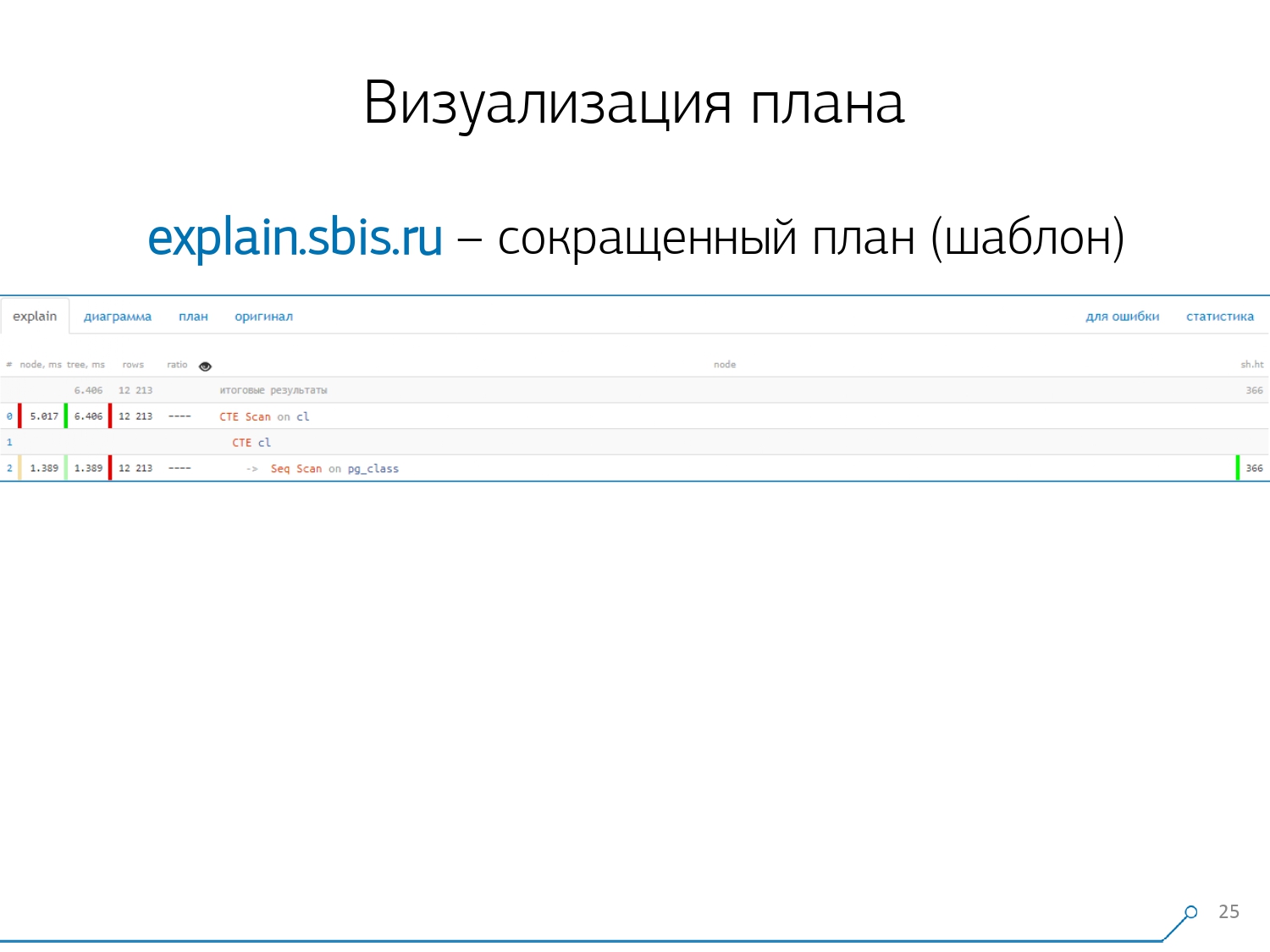 我们得到了这样的东西-立即突出显示语法。但是通常,我们的开发人员不再使用计划的完整介绍,而是使用简短的介绍。毕竟,我们已经解析了所有数字并将其左右扔了,在中间我们只剩下了第一行:它是哪种节点:通过某种类型的标签生成CTE Scan,CTE或Seq Scan。这个简短的视图就是我们所说的计划模板。
我们得到了这样的东西-立即突出显示语法。但是通常,我们的开发人员不再使用计划的完整介绍,而是使用简短的介绍。毕竟,我们已经解析了所有数字并将其左右扔了,在中间我们只剩下了第一行:它是哪种节点:通过某种类型的标签生成CTE Scan,CTE或Seq Scan。这个简短的视图就是我们所说的计划模板。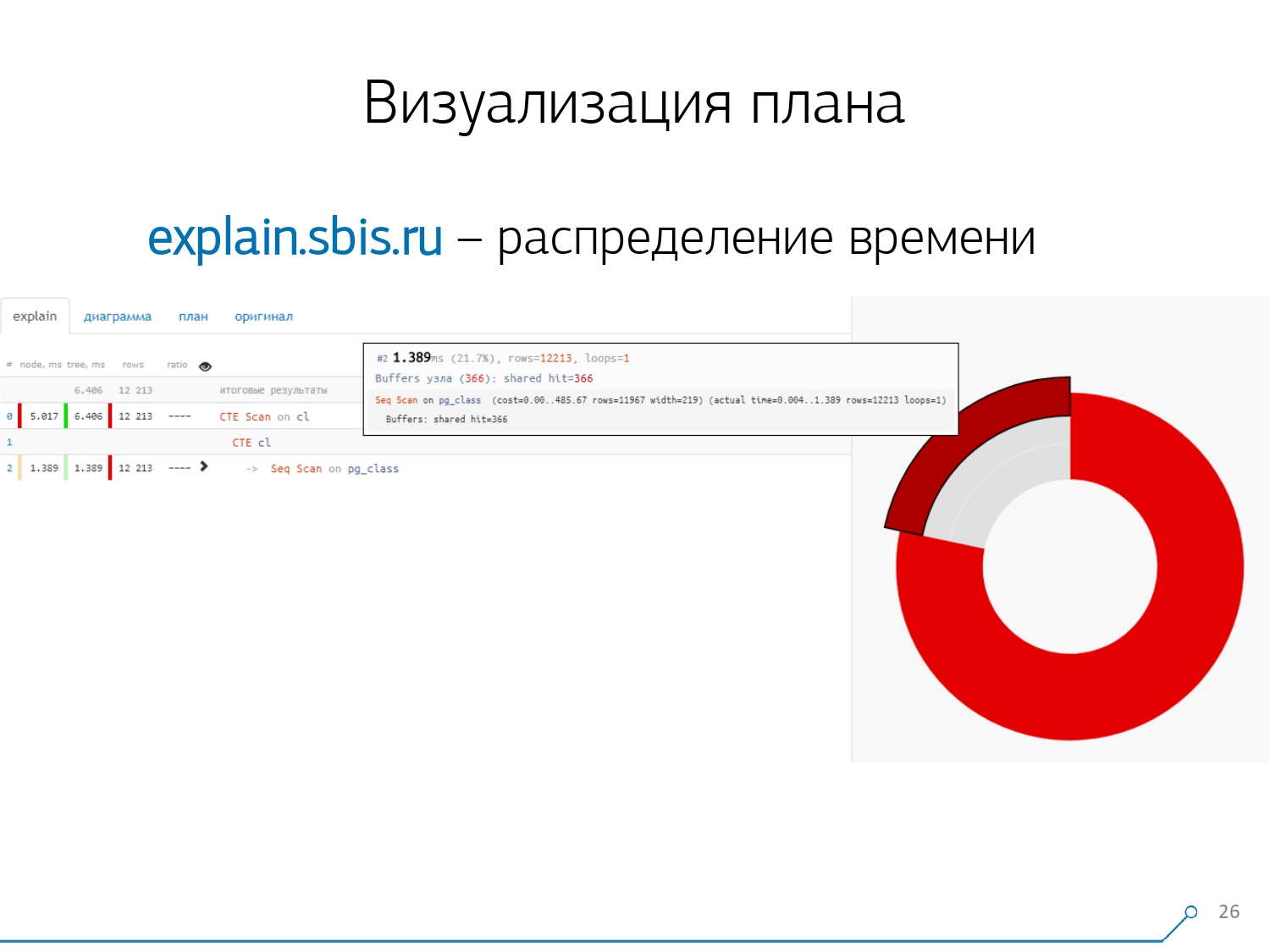 还有什么方便的呢?查看总时间中哪个节点分配给我们的比例很方便-只需“粘贴”侧面的饼形图即可。我们指向该节点,然后发现-与我们一起,事实证明Seq Scan花费的时间不到整个时间的四分之一,而其余3/4花费了CTE Scan。恐怖!如果您在查询中积极使用CTE Scan,那么这只是一小部分。它们不是非常快-它们甚至输给了通常的表扫描。[文章] [文章]但通常这种图表更有趣,更复杂,当我们立即指向一个段,而我们看到的,例如,有超过一半的时间所有的一些序列扫描“吃”。而且,里面有一个筛选器,上面放了很多记录……您可以直接将这张图片扔给开发人员,然后说:“瓦西娅,这里的一切对您不利!明白了,看-出问题了!”
还有什么方便的呢?查看总时间中哪个节点分配给我们的比例很方便-只需“粘贴”侧面的饼形图即可。我们指向该节点,然后发现-与我们一起,事实证明Seq Scan花费的时间不到整个时间的四分之一,而其余3/4花费了CTE Scan。恐怖!如果您在查询中积极使用CTE Scan,那么这只是一小部分。它们不是非常快-它们甚至输给了通常的表扫描。[文章] [文章]但通常这种图表更有趣,更复杂,当我们立即指向一个段,而我们看到的,例如,有超过一半的时间所有的一些序列扫描“吃”。而且,里面有一个筛选器,上面放了很多记录……您可以直接将这张图片扔给开发人员,然后说:“瓦西娅,这里的一切对您不利!明白了,看-出问题了!” 自然地,有一个“耙子”。他们“踩”的第一件事是四舍五入的问题。计划中每个人的节点时间以1μs的精度表示。并且当节点周期数超过例如1000时-执行PostgreSQL后将其除以“ up”,然后在反向计算中,总时间为“介于0.95ms和1.05ms之间”。当帐户花费的时间是微秒时-什么都没有,但是已经花费了[milli]秒-当“解散”“谁消耗了多少人”的节点上的资源时,有必要考虑此信息。
自然地,有一个“耙子”。他们“踩”的第一件事是四舍五入的问题。计划中每个人的节点时间以1μs的精度表示。并且当节点周期数超过例如1000时-执行PostgreSQL后将其除以“ up”,然后在反向计算中,总时间为“介于0.95ms和1.05ms之间”。当帐户花费的时间是微秒时-什么都没有,但是已经花费了[milli]秒-当“解散”“谁消耗了多少人”的节点上的资源时,有必要考虑此信息。 第二点,更复杂的是动态节点之间的资源分配(那些相同的缓冲区)。这使我们花了原型的前2周加上第4周的时间。要解决此问题非常简单-我们进行CTE,并且据说正在阅读其中的内容。实际上,PostgreSQL很聪明,不会在那里读任何东西。然后,我们从中获取第一条记录,并从同一CTE中获得第一条记录。
第二点,更复杂的是动态节点之间的资源分配(那些相同的缓冲区)。这使我们花了原型的前2周加上第4周的时间。要解决此问题非常简单-我们进行CTE,并且据说正在阅读其中的内容。实际上,PostgreSQL很聪明,不会在那里读任何东西。然后,我们从中获取第一条记录,并从同一CTE中获得第一条记录。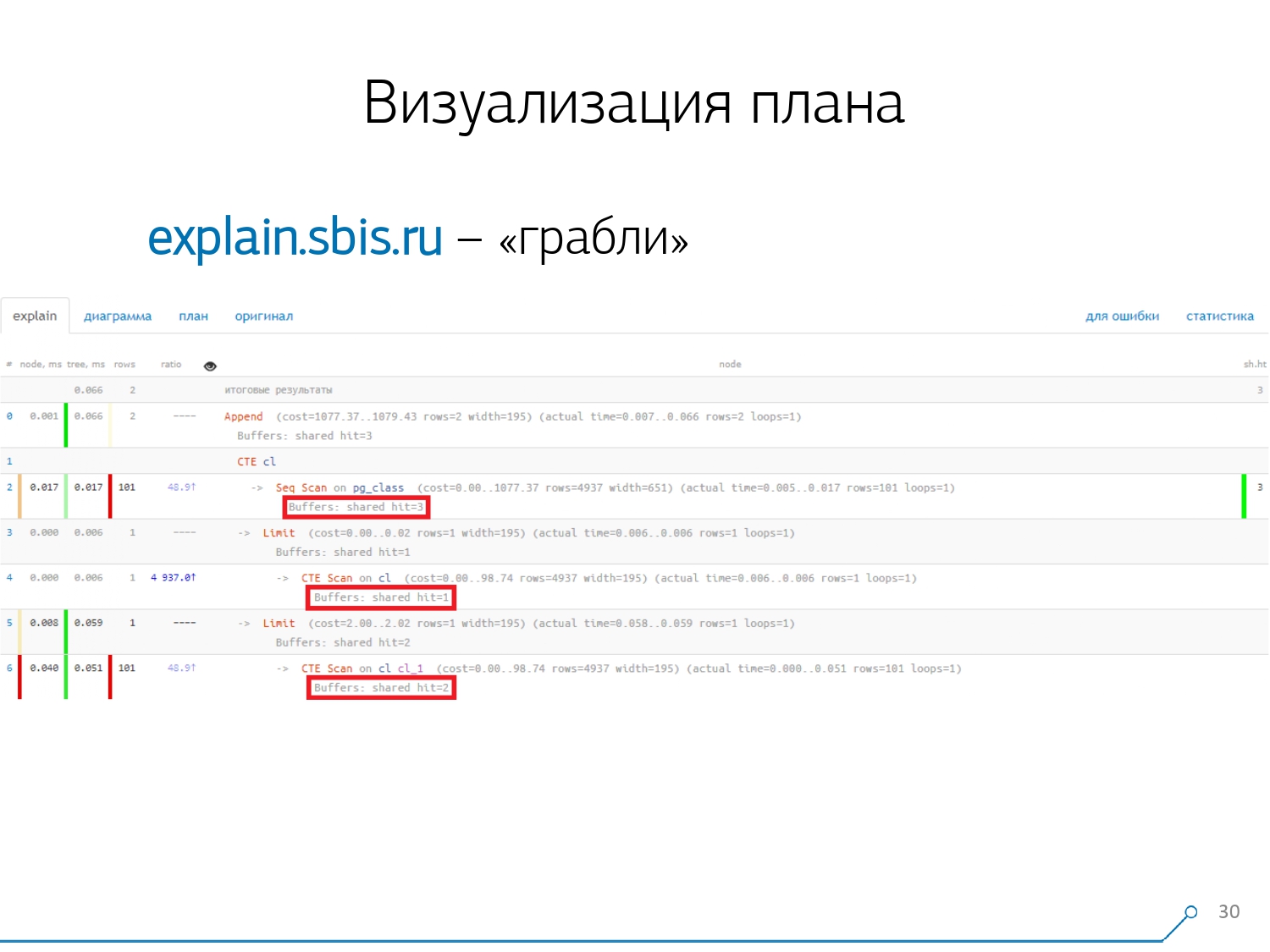 我们看一下计划并了解了-奇怪的是,我们在Seq Scan中“消耗”了3个缓冲区(数据页),在CTE Scan中增加了1个,在第二CTE Scan中增加了2个。就是说,如果简单地将所有内容相加,我们得到6,但是从盘子里我们只能读到3! CTE Scan不会从任何地方读取任何内容,而是直接与过程存储器一起使用。也就是说,这里显然有问题!实际上,事实证明,这里所有从Seq Scan请求的那三页数据,首先是第一页,是第一次CTE扫描,然后是第二页,然后又读取了2页。也就是说,总共读取了3页。数据,而不是6。
我们看一下计划并了解了-奇怪的是,我们在Seq Scan中“消耗”了3个缓冲区(数据页),在CTE Scan中增加了1个,在第二CTE Scan中增加了2个。就是说,如果简单地将所有内容相加,我们得到6,但是从盘子里我们只能读到3! CTE Scan不会从任何地方读取任何内容,而是直接与过程存储器一起使用。也就是说,这里显然有问题!实际上,事实证明,这里所有从Seq Scan请求的那三页数据,首先是第一页,是第一次CTE扫描,然后是第二页,然后又读取了2页。也就是说,总共读取了3页。数据,而不是6。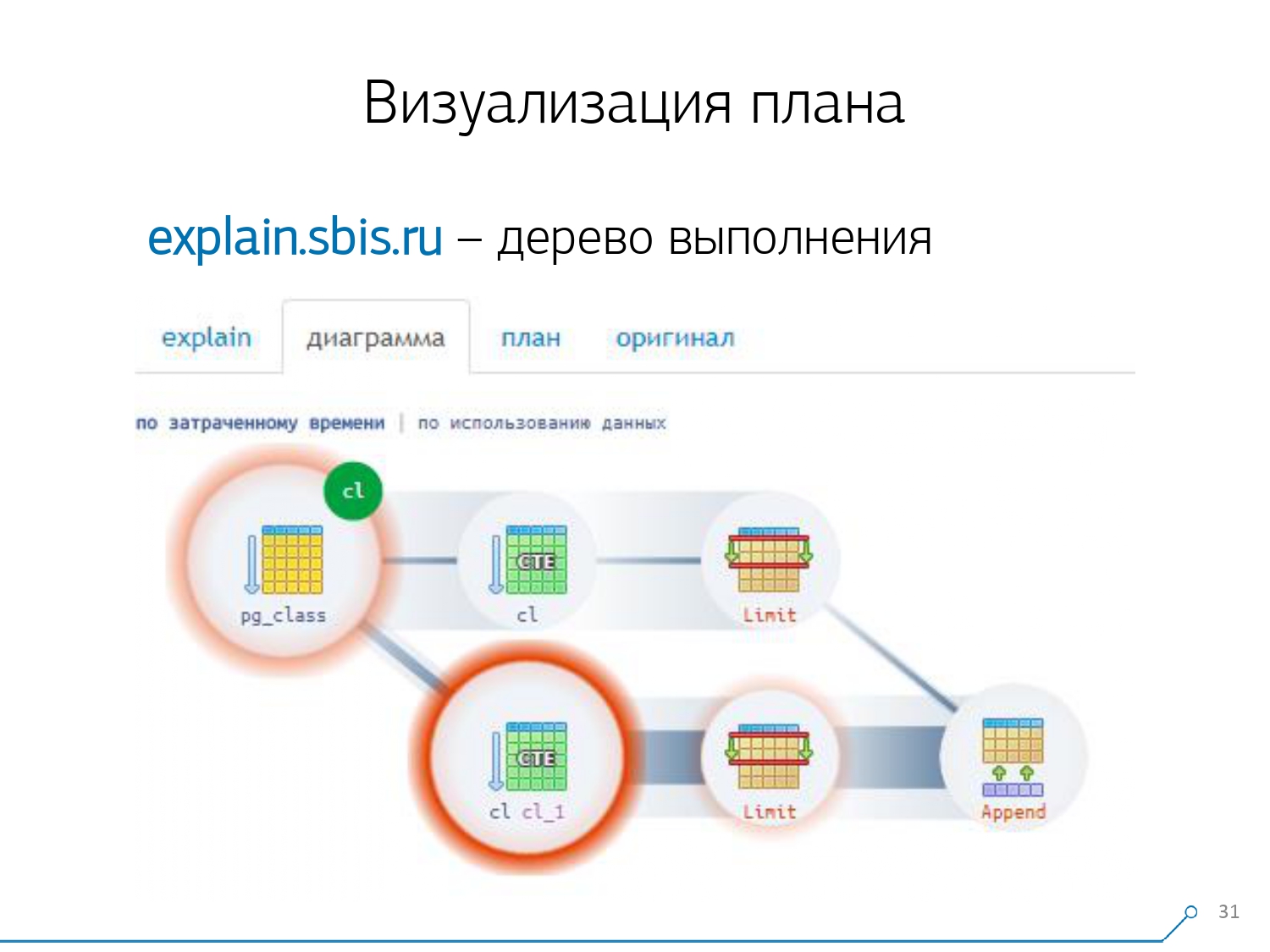 这张图使我们了解到,计划的实施不再是一棵树,而是某种非循环图。我们得到了这样的图表,以便我们理解“它从何而来”。也就是说,在这里我们从pg_class创建了一个CTE,并要求它两次,并且几乎所有时间都在第二次要求它时占用了我们。显然,读取第101条记录比仅使用平板电脑的第1条记录要贵得多。
这张图使我们了解到,计划的实施不再是一棵树,而是某种非循环图。我们得到了这样的图表,以便我们理解“它从何而来”。也就是说,在这里我们从pg_class创建了一个CTE,并要求它两次,并且几乎所有时间都在第二次要求它时占用了我们。显然,读取第101条记录比仅使用平板电脑的第1条记录要贵得多。 我们呼气了一会儿。他们说:“现在,新,你知道功夫!现在,我们的经验就在您的屏幕上。现在您可以使用它。” [文章]
我们呼气了一会儿。他们说:“现在,新,你知道功夫!现在,我们的经验就在您的屏幕上。现在您可以使用它。” [文章]日志合并
我们的1000名开发人员松了一口气。但是我们了解到,我们只有数百个“战斗”服务器,开发人员进行的所有这些“复制粘贴”操作都不方便。我们意识到我们需要自己收集它。 通常,有一个常规模块可以收集统计信息,但是,它也需要在config中激活-这是pg_stat_statements模块。但是他不适合我们。首先,它将不同的QueryId分配给同一数据库内不同方案上的相同查询。也就是说,如果您先发出
通常,有一个常规模块可以收集统计信息,但是,它也需要在config中激活-这是pg_stat_statements模块。但是他不适合我们。首先,它将不同的QueryId分配给同一数据库内不同方案上的相同查询。也就是说,如果您先发出SET search_path = '01'; SELECT * FROM user LIMIT 1;,然后SET search_path = '02';发出相同的请求,则此模块的统计信息将具有不同的条目,并且在不考虑方案的情况下,我将无法在此请求配置文件的上下文中准确收集常规统计信息。阻碍我们使用它的第二点是缺乏计划。也就是说,没有计划,只有请求本身。我们看到了变慢的原因,但我们不明白为什么。在这里,我们回到数据集快速变化的问题。最后一点是缺乏“事实”。也就是说,不可能解决查询执行的特定实例-它不在那里,只有聚合统计信息。尽管可以使用它,但这非常困难。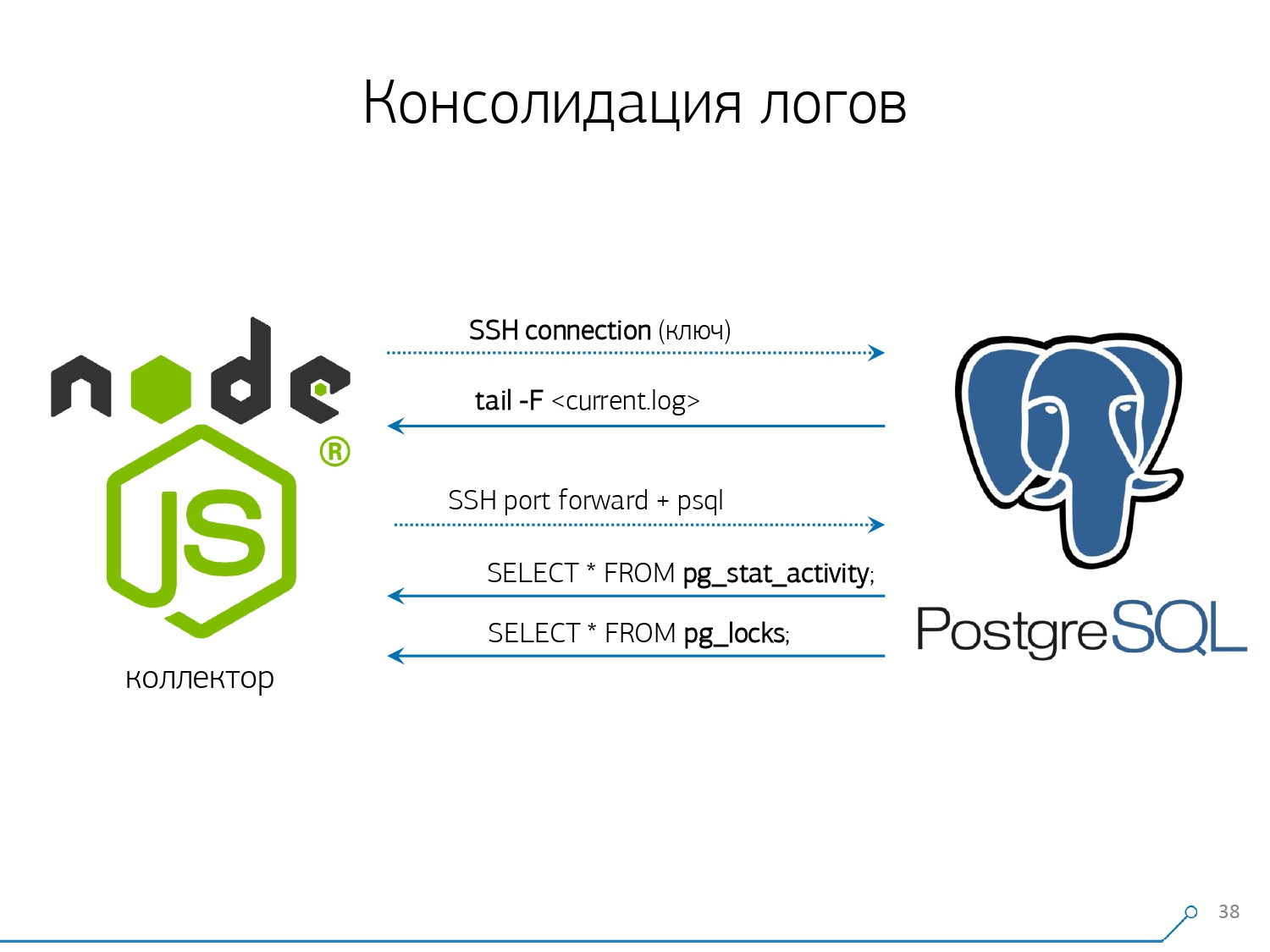 因此,我们决定与“复制粘贴”作斗争,并开始写一个收藏家。收集器通过SSH连接,使用证书“拉”安全连接到带有数据库的服务器,并将其
因此,我们决定与“复制粘贴”作斗争,并开始写一个收藏家。收集器通过SSH连接,使用证书“拉”安全连接到带有数据库的服务器,并将其tail -F“紧贴”到日志文件。所以在这个环节我们将获得服务器生成的整个日志文件的完整“镜像”。服务器本身的负载是最小的,因为我们不在那里解析任何内容,我们只是镜像流量。由于我们已经开始在Node.js上编写接口,因此我们继续在其上编写收集器。这项技术取得了成功,因为使用JavaScript处理格式较差的文本数据(即日志)非常方便。而作为后端平台的Node.js基础架构本身使您可以轻松便捷地使用网络连接,甚至可以使用某种数据流。因此,我们“拉”两个连接:第一个是“侦听”日志本身并将其带给我们,第二个是定期询问数据库。 “但是在日志中,到达oid 123的盘子被阻止了,”但它没有对开发人员说任何话,最好向数据库询问“ OID = 123到底是什么?”因此,我们会定期向基地询问一些我们在家尚不了解的事情。 “您只是没有考虑到,有一种象大象的蜜蜂!..”当我们想监视10台服务器时,我们开始开发此系统。在我们的理解中,最关键的是一些难以解决的问题。但是在第一季度,我们得到了一百个人进行监控-因为该系统“进入”了,每个人都想要它,每个人都很舒适。必须添加所有这些内容,数据流很大且处于活动状态。实际上,我们监视我们能够处理的内容-然后我们使用它。我们还将PostgreSQL用作数据仓库。但是,没有什么比
“您只是没有考虑到,有一种象大象的蜜蜂!..”当我们想监视10台服务器时,我们开始开发此系统。在我们的理解中,最关键的是一些难以解决的问题。但是在第一季度,我们得到了一百个人进行监控-因为该系统“进入”了,每个人都想要它,每个人都很舒适。必须添加所有这些内容,数据流很大且处于活动状态。实际上,我们监视我们能够处理的内容-然后我们使用它。我们还将PostgreSQL用作数据仓库。但是,没有什么比COPY将操作符“注入”数据更快的了。但是仅仅“倾倒”数据并不是我们真正的技术。因为如果您每秒在一百台服务器上有大约5万个请求,那么每天将为您生成100-150GB的日志。因此,我们必须仔细地“看见”基地。首先,我们每天进行分区,因为总的来说,没有人对两天之间的相关性感兴趣。与昨天相比有什么区别,如果今晚您推出了该应用程序的新版本-已经有一些新的统计信息。其次,我们学会了(被迫)非常非常快速地使用编写COPY。也就是说,不仅COPY因为它比更快INSERT,而且甚至更快。 第三点-我不得不分别放弃触发器和外键。也就是说,我们没有绝对的参照完整性。因为如果您有一个表,上面有一对FK,并且您在数据库结构中说“这里有一个日志条目引用了FK,例如,一组记录”,那么当您插入该表时,PostgreSQL无关紧要如何获取并诚实地
第三点-我不得不分别放弃触发器和外键。也就是说,我们没有绝对的参照完整性。因为如果您有一个表,上面有一对FK,并且您在数据库结构中说“这里有一个日志条目引用了FK,例如,一组记录”,那么当您插入该表时,PostgreSQL无关紧要如何获取并诚实地SELECT 1 FROM master_fk1_table WHERE ...使用您要插入的标识符执行操作-只是要检查该条目是否存在,即您没有随插入内容“断开”此外键。我们得到的不是目标表及其索引中的一条记录,而是从它所引用的所有表中读取的另一条记录。而且我们根本不需要它-我们的任务是以最少的负担尽可能快地写下尽可能多的东西。 FK-下来!接下来的一点是聚合和散列。最初,它们是在我们的数据库中实现的-毕竟,方便的是,当记录到达时,立即在触发器中用某种板块“加一”即可。很好,很方便,但是同样不好-插入一条记录,但是您不得不从另一张表中读取和写入其他内容。而且,不仅如此,还可以读取和写入-并且每次都执行。现在,假设您有一个盘子,您可以在其中简单地计算在特定主机上传递的请求数:+1, +1, +1, ..., +1。原则上您不需要它-所有这些都可以汇总到收集器的内存中,并一次发送到数据库+10。是的,在发生某些问题时,您的逻辑完整性可能会“崩溃”,但这几乎是不现实的情况-因为您有一个正常的服务器,它在控制器中有一个电池,您有一个事务日志,在文件系统上的日志...通常,不是值得。由于触发器/ FK的工作而造成的生产力损失,以及同时产生的成本,这是不值得的。哈希也是如此。某个请求会向您发送,您需要从数据库中计算出某个标识符,然后将其写入数据库,然后将其告知所有人。一切都很好,直到进行录制时,第二个人找来您要录制的人-您已经锁定,这已经很糟糕了。因此,如果您可以在客户端上生成一些ID(相对于数据库),则最好这样做。我们非常适合从文本中使用MD5-请求,计划,模板等。我们在收集器侧进行计算,然后将现成的ID“倒入”数据库中。 MD5的长度和每日分区使我们不必担心可能发生的冲突。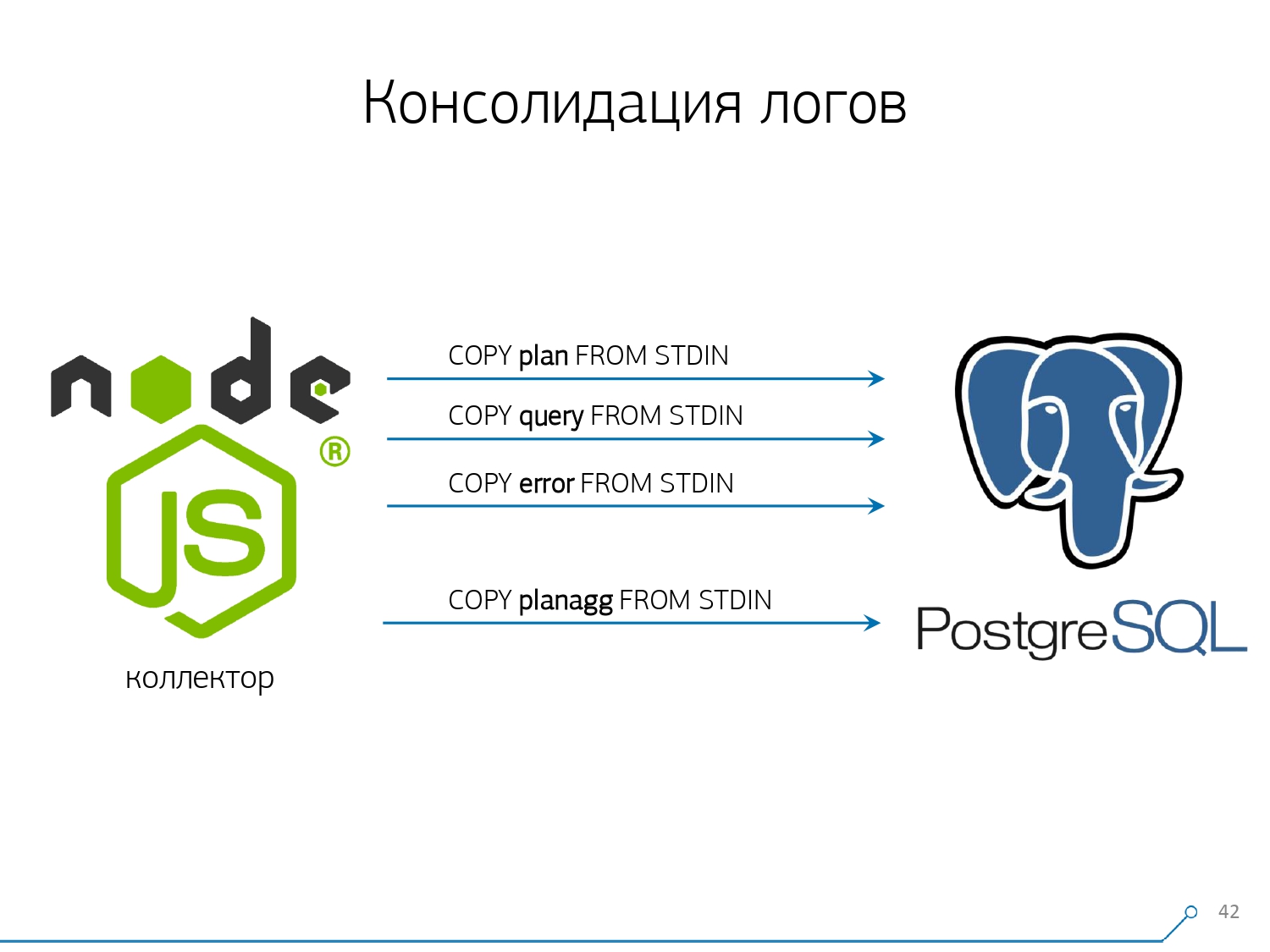 但是为了快速记录所有这些,我们需要修改记录过程本身。您通常如何写数据?我们有某种数据集,我们将其分解成多个表,然后将其分解为COPY-首先在第一个表中,然后在第二个表中,在第三个表中……这很不方便,因为我们有点喜欢按三个步骤依次写入一个数据流。不愉快。有可能做得更快吗?能够!为此,仅将这些流彼此并行分解就足够了。事实证明,我们有错误,请求,模板,锁,在不同的流中飞行……-我们全部并行编写。为此,只需在每个目标表上保持COPY通道永久打开。
但是为了快速记录所有这些,我们需要修改记录过程本身。您通常如何写数据?我们有某种数据集,我们将其分解成多个表,然后将其分解为COPY-首先在第一个表中,然后在第二个表中,在第三个表中……这很不方便,因为我们有点喜欢按三个步骤依次写入一个数据流。不愉快。有可能做得更快吗?能够!为此,仅将这些流彼此并行分解就足够了。事实证明,我们有错误,请求,模板,锁,在不同的流中飞行……-我们全部并行编写。为此,只需在每个目标表上保持COPY通道永久打开。 也就是说,收集器总是有一个流我可以在其中写入所需的数据。但是,为了使数据库能够看到此数据,并且没有人挂锁,等待该数据被写入,必须以一定的频率中断COPY。对于我们来说,最有效的时间是100毫秒-关闭并立即在同一张桌子上再次打开它。而且,如果我们在某些高峰期没有一个视频流,那么我们会将池汇集到一定的极限。此外,我们发现,对于这样的负载配置文件,将记录收集到数据包中时进行任何聚合都是有害的。古典邪恶已
也就是说,收集器总是有一个流我可以在其中写入所需的数据。但是,为了使数据库能够看到此数据,并且没有人挂锁,等待该数据被写入,必须以一定的频率中断COPY。对于我们来说,最有效的时间是100毫秒-关闭并立即在同一张桌子上再次打开它。而且,如果我们在某些高峰期没有一个视频流,那么我们会将池汇集到一定的极限。此外,我们发现,对于这样的负载配置文件,将记录收集到数据包中时进行任何聚合都是有害的。古典邪恶已INSERT ... VALUES超过1000条记录。因为这时您在媒体上的记录达到了高峰,并且其他所有尝试向磁盘写入内容的人都将等待。要消除此类异常,只需不聚合任何内容,就根本不要缓冲。并且如果确实发生了对磁盘的缓冲(很幸运,Node.js中的Stream API允许您查找)-推迟此连接。那就是当事件到来时,它又是免费的-从累积的队列中写入该事件。同时,它很忙-从池中取出下一个空闲的池并写入。在实施这种数据记录方法之前,我们有大约4K的写操作,并通过这种方式将负载减少了4倍。现在,由于有了新的可观察的基础,它们又增长了6倍-高达100MB / s。现在,我们将过去三个月的日志存储量大约为10-15TB,希望任何开发人员都能在三个月内解决任何问题。我们了解问题
但是仅仅收集所有这些数据是好的,有用的,适当的,但还不够-您需要了解它。因为每天有数百万种不同的计划。 但是数百万人是无法控制的,您必须首先做到“少”。而且,首先,必须确定如何组织这个“较小”的组织。我们为自己确定了三个关键点:
但是数百万人是无法控制的,您必须首先做到“少”。而且,首先,必须确定如何组织这个“较小”的组织。我们为自己确定了三个关键点:- 谁发送了这个请求,
也就是说,他从哪个应用程序“飞行”:Web界面,后端,支付系统或其他东西。 - 哪里会出现这种情况
在这特定的服务器。因为如果在一个应用程序下有多台服务器,而突然有一个服务器“变钝”(因为“磁盘已烂”,“内存泄漏”,以及其他一些麻烦),那么您需要专门解决该服务器。 - 问题如何以一种或另一种方式表现出来
要了解“谁”向我们发送了请求,我们使用常规工具-设置会话变量:SET application_name = '{bl-host}:{bl-method}';-发送从中发送请求的业务逻辑的主机名,以及发起请求的方法或应用程序的名称。传递请求的“所有者”后,必须将其显示在日志中-为此,我们配置了变量log_line_prefix = ' %m [%p:%v] [%d] %r %a'。任何感兴趣的人都可以在手册中看到这一切的含义。事实证明,我们在日志中看到:- 时间
- 流程和交易标识符
- 基本名称
- 发送此请求的人的IP
- 和方法名称
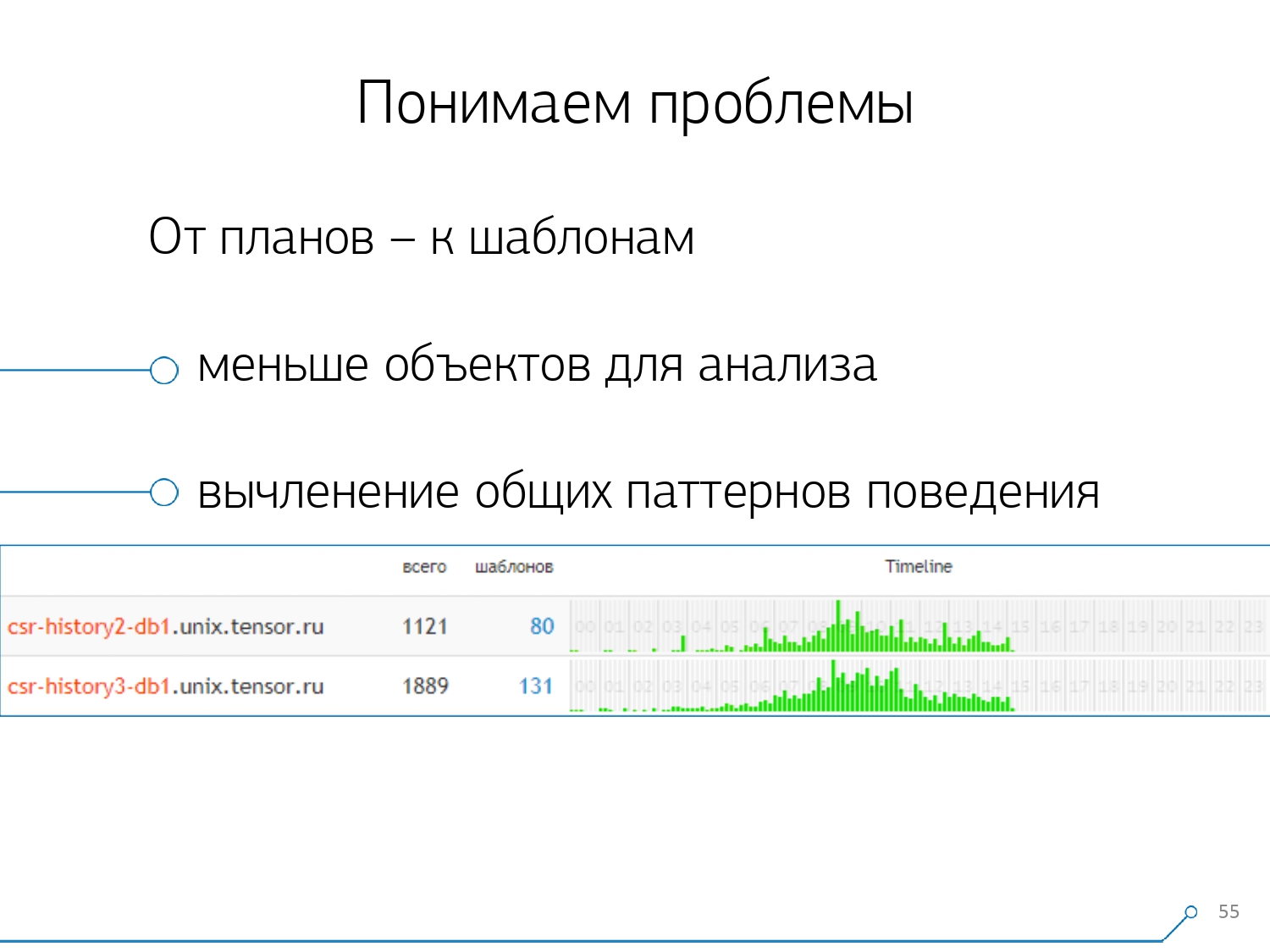 然后我们意识到,查看不同服务器之间的一个请求的相关性并不是很有趣。当您的某个应用程序到处都是同样的情况时,这种情况很少发生。但是,即使相同,也请看这些服务器中的任何一个。因此,“一台服务器-一天”部分足以进行任何分析。第一个分析部分是非常“模板” -计划表示的缩写形式,清除了所有数字指标。第二部分是应用程序或方法,第三部分是导致我们出现问题的计划的特定节点。当我们从特定实例转移到模板时,我们立即获得了两个好处:
然后我们意识到,查看不同服务器之间的一个请求的相关性并不是很有趣。当您的某个应用程序到处都是同样的情况时,这种情况很少发生。但是,即使相同,也请看这些服务器中的任何一个。因此,“一台服务器-一天”部分足以进行任何分析。第一个分析部分是非常“模板” -计划表示的缩写形式,清除了所有数字指标。第二部分是应用程序或方法,第三部分是导致我们出现问题的计划的特定节点。当我们从特定实例转移到模板时,我们立即获得了两个好处:
, .
, «» - , . , - , , , — , , — , , . , , .
 其余方法基于我们从计划中提取的指标:发生了这样的模板多少次,总和平均时间,从磁盘读取了多少数据以及从内存中读取了多少数据……例如,由于您是按主机访问分析页面的,请参阅-磁盘上有太多东西,无法读取开头。服务器上的磁盘无法应付-谁从中读取数据?您可以按任何列进行排序,并决定您现在将要处理的内容-处理器或磁盘上的负载,或请求的总数...排序,看起来“最高”,已修复-推出了该应用程序的新版本。[视频讲座]并且您马上可以从请求中看到带有相同模板的不同应用程序,例如
其余方法基于我们从计划中提取的指标:发生了这样的模板多少次,总和平均时间,从磁盘读取了多少数据以及从内存中读取了多少数据……例如,由于您是按主机访问分析页面的,请参阅-磁盘上有太多东西,无法读取开头。服务器上的磁盘无法应付-谁从中读取数据?您可以按任何列进行排序,并决定您现在将要处理的内容-处理器或磁盘上的负载,或请求的总数...排序,看起来“最高”,已修复-推出了该应用程序的新版本。[视频讲座]并且您马上可以从请求中看到带有相同模板的不同应用程序,例如SELECT * FROM users WHERE login = 'Vasya'。前端,后端,处理...而且您想知道如果用户不与用户交互,为什么应该阅读处理。相反的方法是立即从应用程序中看到它在做什么。例如,每小时一次,一次,一次,一次是一个前端(只是时间轴有帮助)。立刻出现了问题-每小时做一次某事似乎不是前端事务... 一段时间后,我们意识到我们缺乏关于计划节点的汇总统计信息。我们仅从计划中分离出那些对表本身进行某些操作的节点(无论是否通过索引对其进行读/写)。实际上,相对于上一张图片,仅添加了一个方面- 该节点为我们带来了多少条记录,以及删除了多少条(“行被过滤器删除”)。您在印版上没有合适的索引,您向它发出请求,它飞过索引,落入Seq Scan ...您已滤除除一个以外的所有记录。为什么每天需要100M过滤记录,滚动索引是否更好?
一段时间后,我们意识到我们缺乏关于计划节点的汇总统计信息。我们仅从计划中分离出那些对表本身进行某些操作的节点(无论是否通过索引对其进行读/写)。实际上,相对于上一张图片,仅添加了一个方面- 该节点为我们带来了多少条记录,以及删除了多少条(“行被过滤器删除”)。您在印版上没有合适的索引,您向它发出请求,它飞过索引,落入Seq Scan ...您已滤除除一个以外的所有记录。为什么每天需要100M过滤记录,滚动索引是否更好? 在按节点检查了所有计划之后,我们意识到计划中有些典型的结构看起来很可疑。最好告诉开发人员:“朋友,在这里,您首先按索引阅读,然后进行排序,然后剪切”-通常,只有一条记录。使用这种模式编写查询的每个人都可能会遇到:“给我Vasya的最后订单,他的日期”。如果您没有按日期创建索引,或者所使用的索引没有日期,那么就按这样的“耙”行进吧。但是我们知道这是一个“耙子”-为什么不立即告诉开发人员他应该做什么。因此,现在打开计划,我们的开发人员会立即看到一幅美丽的提示,并立即告诉他:“您在这里和这里都遇到了问题,但是这些问题都是通过这种方式解决的。”结果,从一开始到现在解决问题所需的经验大大减少了。这里我们有这样的工具。
在按节点检查了所有计划之后,我们意识到计划中有些典型的结构看起来很可疑。最好告诉开发人员:“朋友,在这里,您首先按索引阅读,然后进行排序,然后剪切”-通常,只有一条记录。使用这种模式编写查询的每个人都可能会遇到:“给我Vasya的最后订单,他的日期”。如果您没有按日期创建索引,或者所使用的索引没有日期,那么就按这样的“耙”行进吧。但是我们知道这是一个“耙子”-为什么不立即告诉开发人员他应该做什么。因此,现在打开计划,我们的开发人员会立即看到一幅美丽的提示,并立即告诉他:“您在这里和这里都遇到了问题,但是这些问题都是通过这种方式解决的。”结果,从一开始到现在解决问题所需的经验大大减少了。这里我们有这样的工具。
Source: https://habr.com/ru/post/undefined/
All Articles