多年以来,C ++专家一直在讨论值的语义,不变性和通过通信进行资源共享。关于一个没有互斥和种族,没有命令和观察者模式的新世界。实际上,一切都不是那么简单。主要问题仍然在我们的数据结构中。 不变的数据结构不会更改其值。要对它们进行处理,您需要创建新的值。旧值保留在同一位置,因此可以从不同流中读取它们而不会出现问题和锁定。结果,资源可以更合理和有序地共享,因为新旧价值可以使用公共数据。因此,它们之间的比较速度更快,并且可以紧凑地存储操作历史记录,并且有可能被取消。所有这些都非常适合多线程和交互式系统:此类数据结构简化了桌面应用程序的体系结构,并允许服务更好地扩展。不可变的结构是Clojure和Scala成功的秘诀,甚至JavaScript社区现在也可以利用它们,因为它们具有Immutable.js库,写在公司Facebook的肠子里。根据剪辑- 来自C ++ Russia 2019莫斯科会议的Juan Puente报告的视频和翻译。Juan谈到了Immer,它是C ++不变结构的库。在文中:
不变的数据结构不会更改其值。要对它们进行处理,您需要创建新的值。旧值保留在同一位置,因此可以从不同流中读取它们而不会出现问题和锁定。结果,资源可以更合理和有序地共享,因为新旧价值可以使用公共数据。因此,它们之间的比较速度更快,并且可以紧凑地存储操作历史记录,并且有可能被取消。所有这些都非常适合多线程和交互式系统:此类数据结构简化了桌面应用程序的体系结构,并允许服务更好地扩展。不可变的结构是Clojure和Scala成功的秘诀,甚至JavaScript社区现在也可以利用它们,因为它们具有Immutable.js库,写在公司Facebook的肠子里。根据剪辑- 来自C ++ Russia 2019莫斯科会议的Juan Puente报告的视频和翻译。Juan谈到了Immer,它是C ++不变结构的库。在文中:- 免疫的结构优势;
- 基于RRB树创建有效的持久矢量类型;
- 一个简单的文本编辑器示例分析架构。
基于价值的架构的悲剧
为了理解不变数据结构的重要性,我们讨论了值的语义。这是C ++的一个非常重要的功能,我认为它是该语言的主要优点之一。尽管如此,很难像我们想要的那样使用值的语义。我相信这是基于价值的体系结构的悲剧,通往这种悲剧的道路是有良好意图的。假设我们需要基于带有用户可编辑文档表示的数据模型编写交互式软件。当基于这个模型的心脏值架构使用简单方便类型的值已经存在的语言:vector,map,tuple,struct。应用程序逻辑是通过按值获取文档并按值返回文档的新版本的函数创建的。该文档可能会在函数内部进行更改(如下所述),但是C ++中值的语义(按值应用于参数并按值返回类型)确保没有副作用。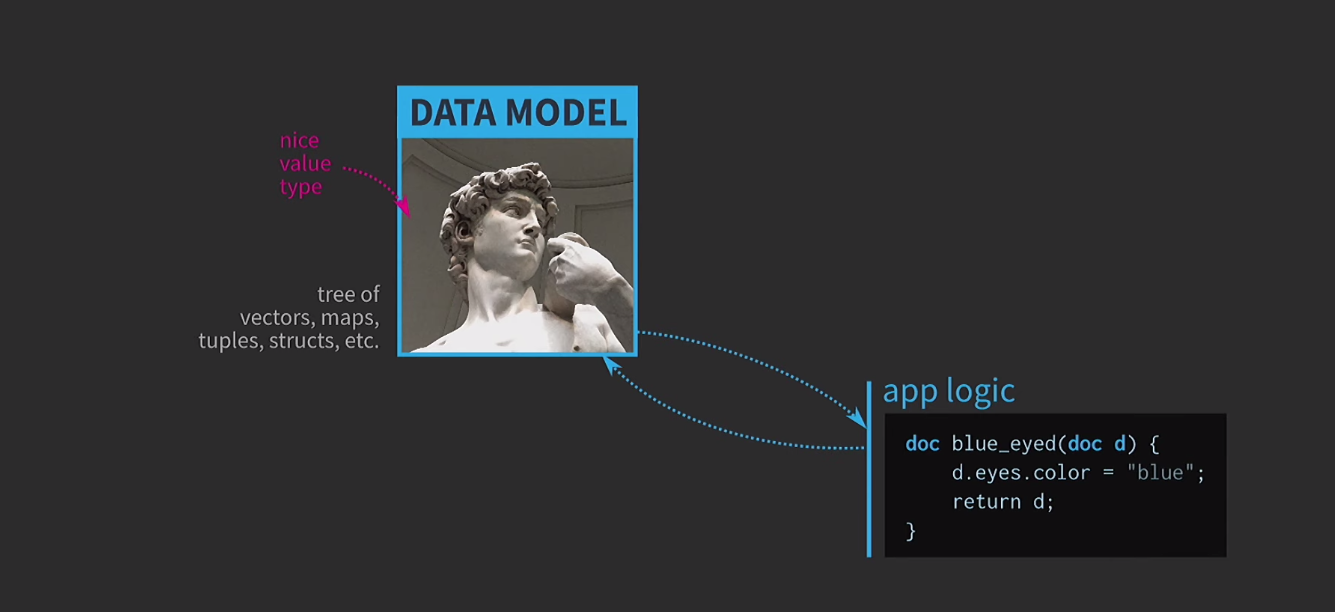 此功能非常易于分析和测试。
此功能非常易于分析和测试。 由于我们正在使用值,因此我们将尝试实施该操作的撤消操作。这可能很困难,但是采用我们的方法,这是一项琐碎的任务:我们在
由于我们正在使用值,因此我们将尝试实施该操作的撤消操作。这可能很困难,但是采用我们的方法,这是一项琐碎的任务:我们在std::vector不同状态下拥有文档的各种副本。 假设我们也有一个UI,并且为了确保其响应性,UI的映射需要在单独的线程中完成。该文档通过消息发送到另一个流,并且交互也基于消息进行,而不是通过使用状态共享进行
假设我们也有一个UI,并且为了确保其响应性,UI的映射需要在单独的线程中完成。该文档通过消息发送到另一个流,并且交互也基于消息进行,而不是通过使用状态共享进行mutexes。当第二个流接收到副本时,您可以在其中执行所有必要的操作。 将文档保存到磁盘通常很慢,尤其是在文档较大的情况下。因此,使用
将文档保存到磁盘通常很慢,尤其是在文档较大的情况下。因此,使用std::async此操作是异步执行的。我们使用lambda,在其中放一个等号以获得副本,现在您可以保存而无需其他原始类型的同步。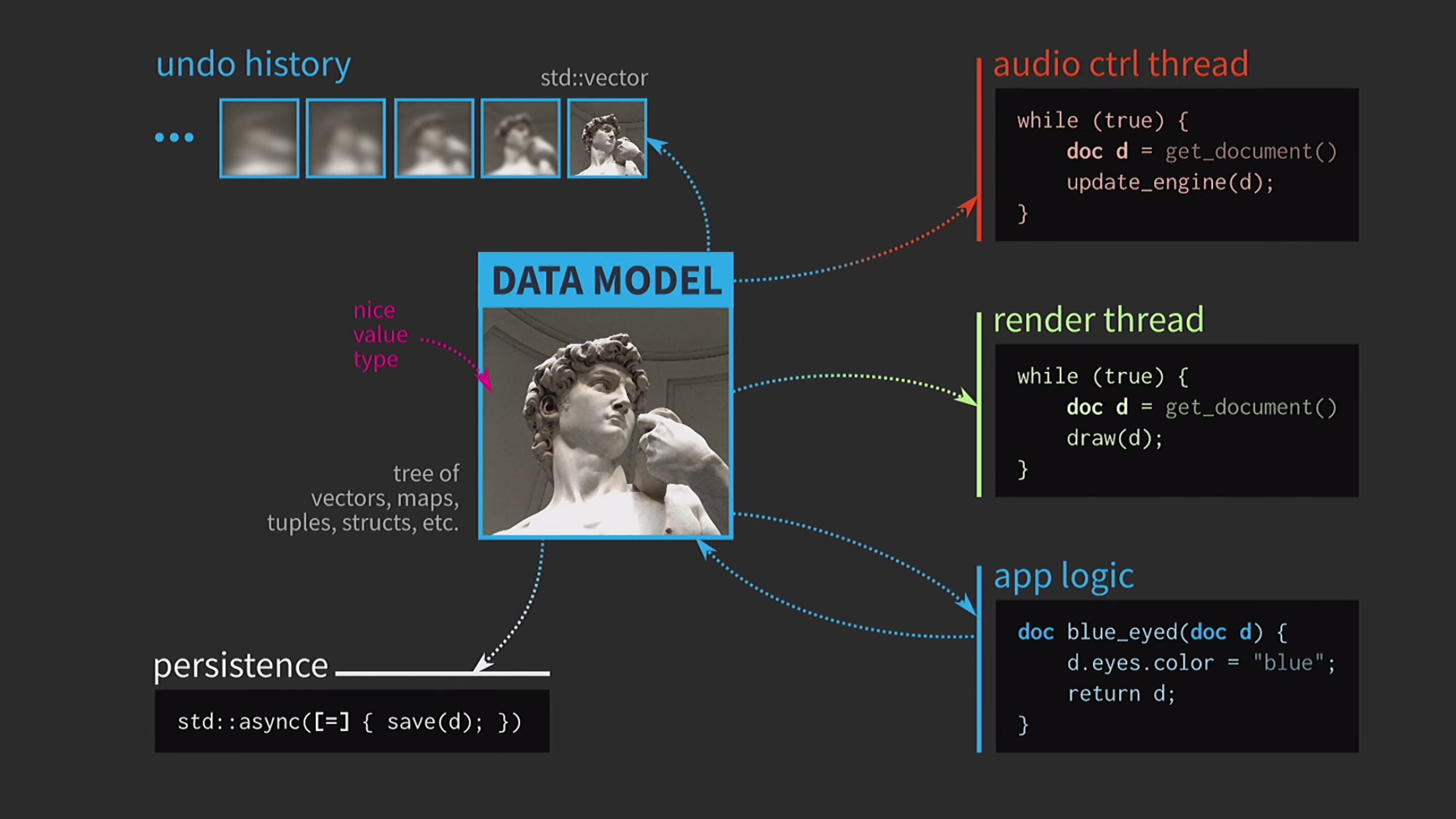 此外,假设我们还有一个声音控制流程。正如我所说,我在音乐软件上做了很多工作,声音是文档的另一种表示形式,它必须放在单独的流中。因此,此流也需要文档的副本。结果,我们得到了一个非常漂亮但不太现实的方案。
此外,假设我们还有一个声音控制流程。正如我所说,我在音乐软件上做了很多工作,声音是文档的另一种表示形式,它必须放在单独的流中。因此,此流也需要文档的副本。结果,我们得到了一个非常漂亮但不太现实的方案。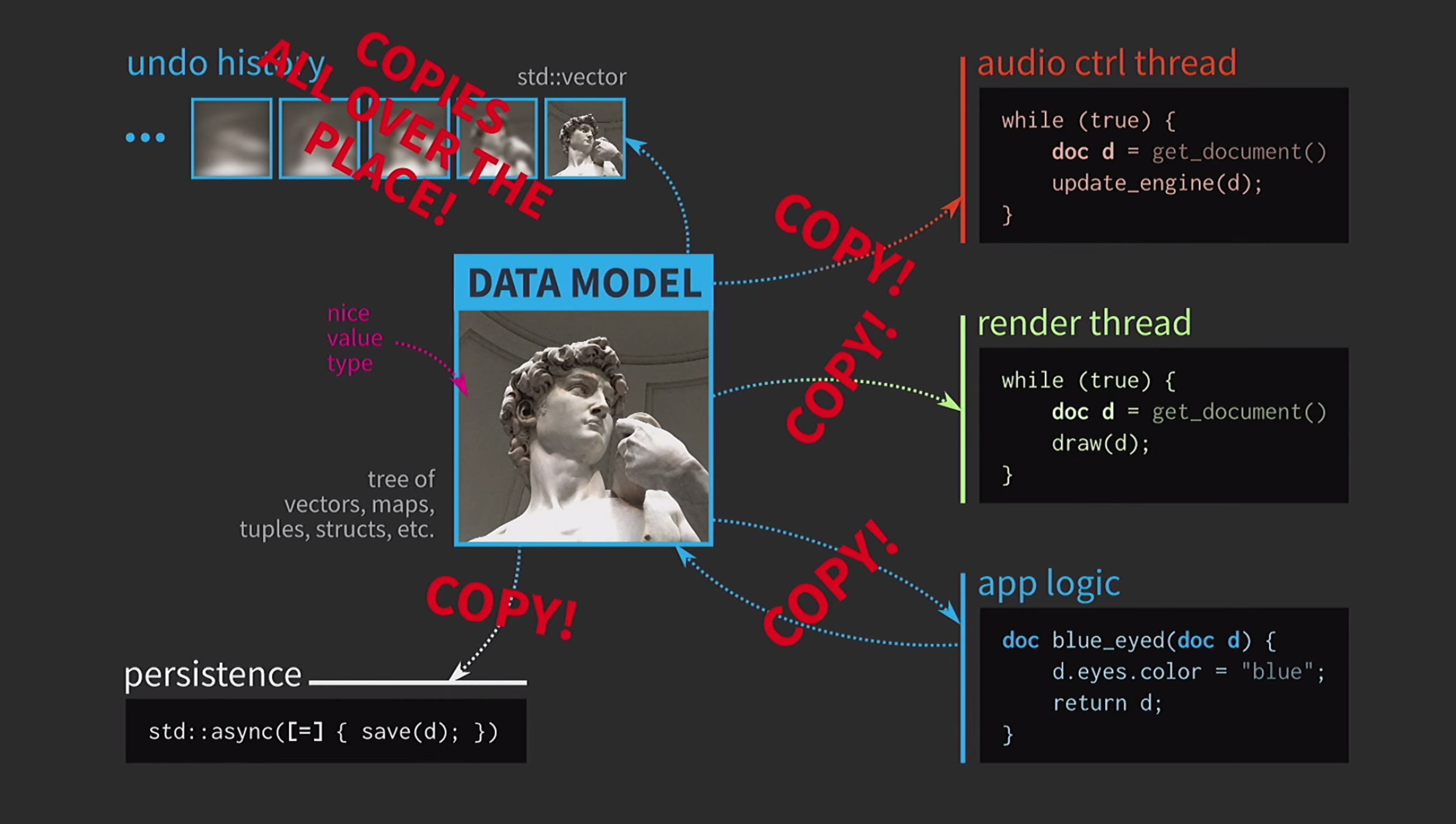 它经常需要复制文档,取消的操作历史记录需要千兆字节,并且对于UI的每个呈现,都需要制作文档的深层副本。通常,所有交互的成本都很高。
它经常需要复制文档,取消的操作历史记录需要千兆字节,并且对于UI的每个呈现,都需要制作文档的深层副本。通常,所有交互的成本都很高。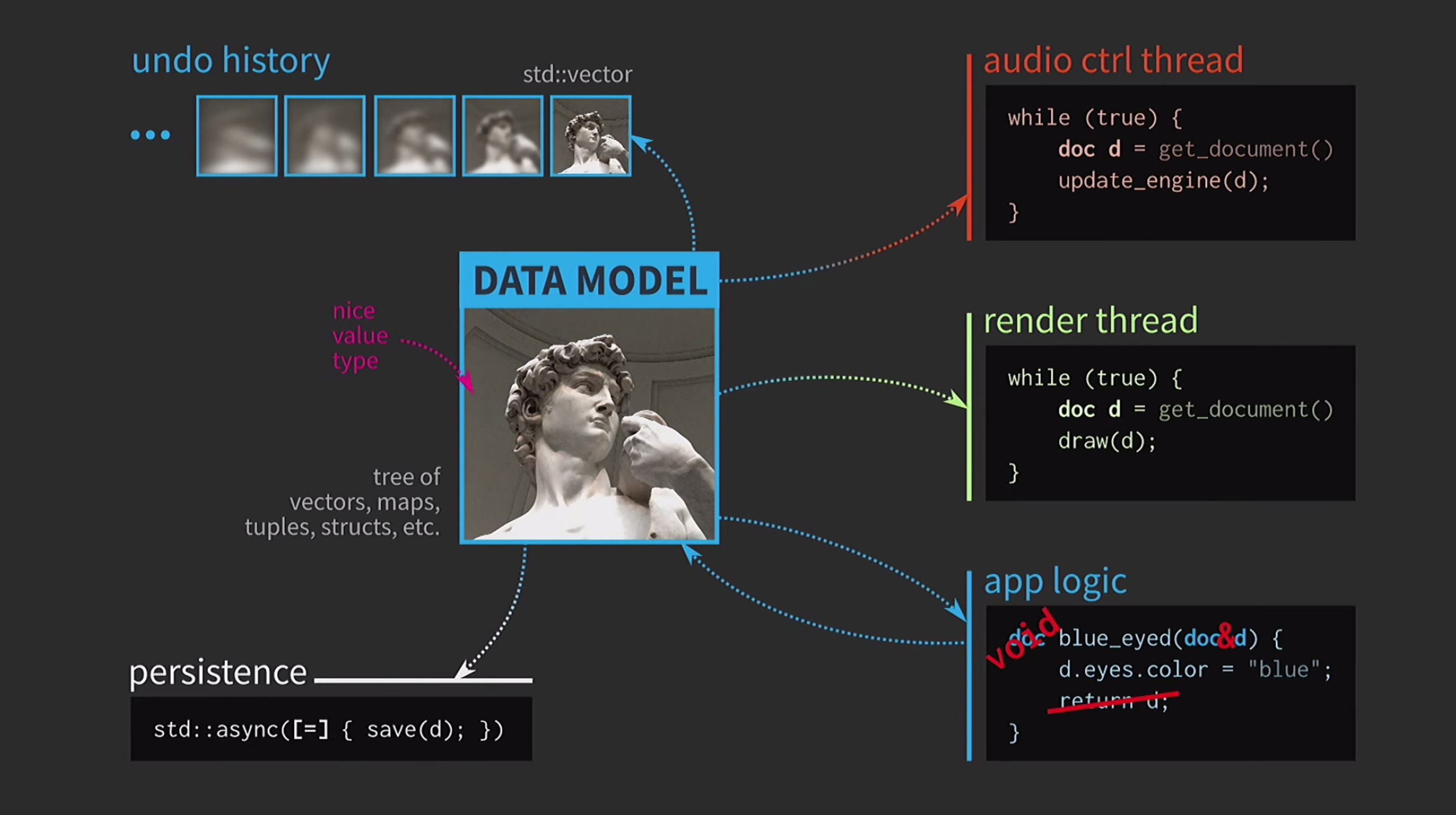 在这种情况下,C ++开发人员正在做什么?现在,应用程序逻辑不再接受按值接受文档的方式,而是接受指向文档的链接并在必要时对其进行更新。在这种情况下,您无需返回任何内容。但是现在我们不是在处理价值,而是在处理对象和位置。这就带来了新的问题:如果存在具有共享访问权限的状态的链接,则需要它
在这种情况下,C ++开发人员正在做什么?现在,应用程序逻辑不再接受按值接受文档的方式,而是接受指向文档的链接并在必要时对其进行更新。在这种情况下,您无需返回任何内容。但是现在我们不是在处理价值,而是在处理对象和位置。这就带来了新的问题:如果存在具有共享访问权限的状态的链接,则需要它mutex。这是非常昂贵的,因此会以来自各种小部件的极其复杂的树的形式来表示我们的UI。当文档更改时,所有这些元素都应接收更新,因此更改信号需要某种排队机制。此外,文档的历史记录不再是一组状态;它将是团队模式的实现。该操作必须在一个方向和另一个方向上执行两次,并确保所有内容对称。保存在单独的线程中已经太困难了,因此必须放弃它。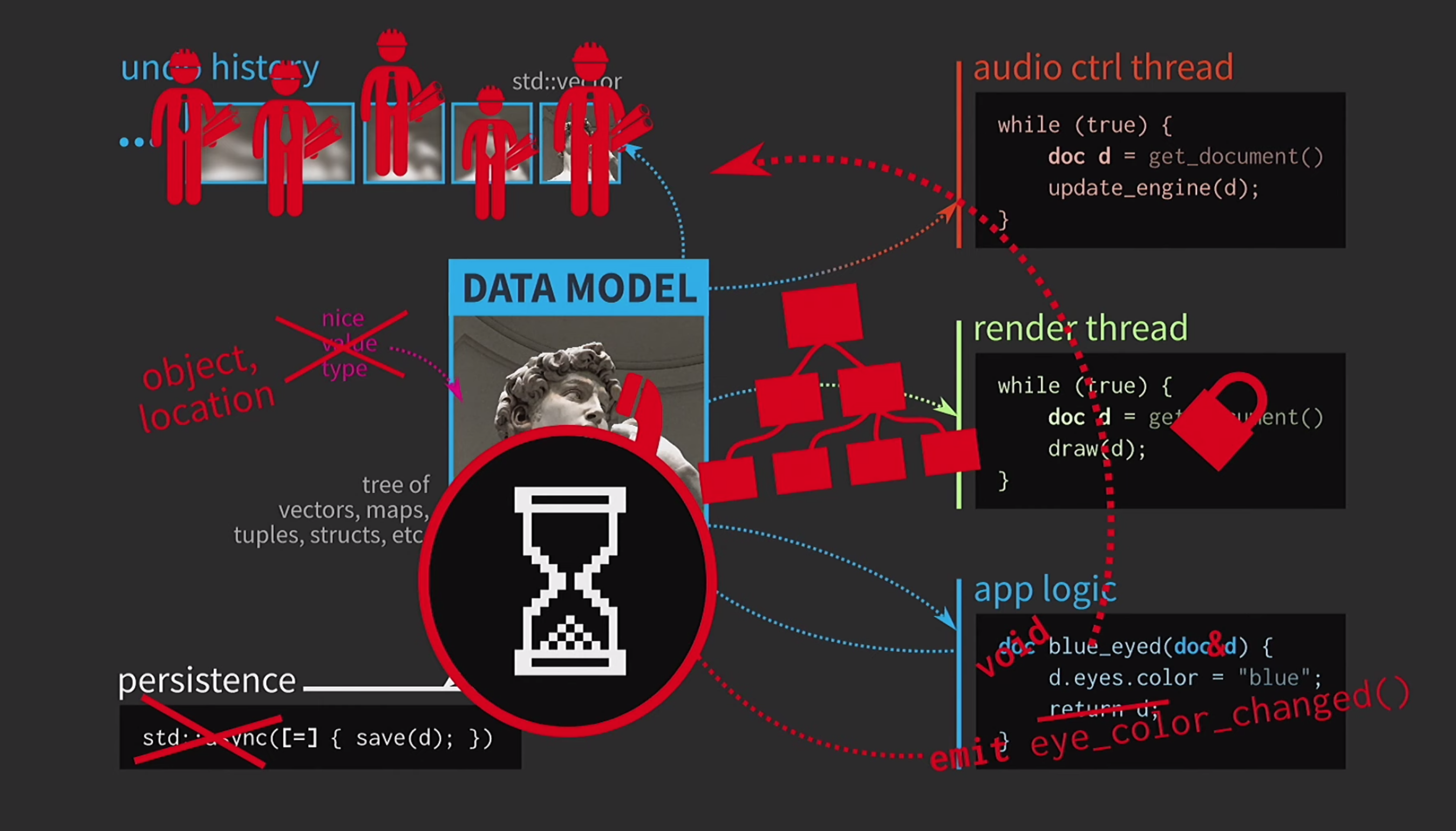 用户已经习惯了沙漏画面,因此稍等片刻也可以。另一件事令人恐惧-面食怪物现在控制着我们的代码。在什么时候一切顺利?我们对代码进行了很好的设计,然后由于复制而不得不妥协。但是在C ++中,仅对于可变数据,复制才需要按值传递。如果对象是不可变的,则可以实现赋值运算符,以便它仅复制指向内部表示的指针,仅此而已。
用户已经习惯了沙漏画面,因此稍等片刻也可以。另一件事令人恐惧-面食怪物现在控制着我们的代码。在什么时候一切顺利?我们对代码进行了很好的设计,然后由于复制而不得不妥协。但是在C ++中,仅对于可变数据,复制才需要按值传递。如果对象是不可变的,则可以实现赋值运算符,以便它仅复制指向内部表示的指针,仅此而已。const auto v0 = vector<int>{};
考虑一个可以帮助我们的数据结构。在下面的向量中,所有方法都标记为const,因此它是不可变的。在执行时.push_back,向量不会更新;相反,将返回一个新向量,向该向量中添加已传输的数据。不幸的是,由于方括号的定义方式,我们无法在方括号中使用此方法。相反,您可以使用该功能.set它返回带有更新项目的新版本。现在,我们的数据结构具有称为函数编程中的持久性的属性。这意味着我们并不是将数据结构保存到硬盘驱动器,而是在更新数据时不会删除旧内容,而是创建了我们这个世界的新分支,即结构。因此,我们可以与过去比较过去的价值-这是在两个帮助下完成的assert。const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
现在可以直接检查更改,它们不再是数据结构的隐藏属性。此功能在交互式系统中特别有价值,在交互式系统中我们经常需要更改数据。另一个重要属性是结构共享。现在,我们不为每个新版本的数据结构复制所有数据。即使.push_back和.set并非所有数据都被复制,而只是其中的一小部分。我们所有的fork都可以访问一个紧凑的视图,该视图与更改的数量成正比,而不是副本的数量。同样,比较也非常快:如果所有内容都存储在一个内存块中的一个指针中,那么您可以简单地比较指针,如果它们相等,则不检查它们内部的元素。因为在我看来,这样的向量非常有用,所以我在一个单独的库中实现了它:这是沉浸式的 -一个不变结构的库,一个开源项目。编写它时,我希望C ++开发人员熟悉它的用法。有许多库在C ++中实现了函数式编程的概念,但是给人的印象是开发人员是为Haskell而不是C ++编写的。这带来了不便。另外,我取得了不错的成绩。当可用资源有限时,人们会使用C ++。最后,我希望该库是可定制的。此要求与性能要求有关。寻找神奇的载体
在报告的第二部分中,我们将考虑该不可变向量的结构。理解这种数据结构原理的最简单方法是从常规列表开始。如果您对函数式编程有点熟悉(以Lisp或Haskell为例),您会知道列表是最常见的不可变数据结构。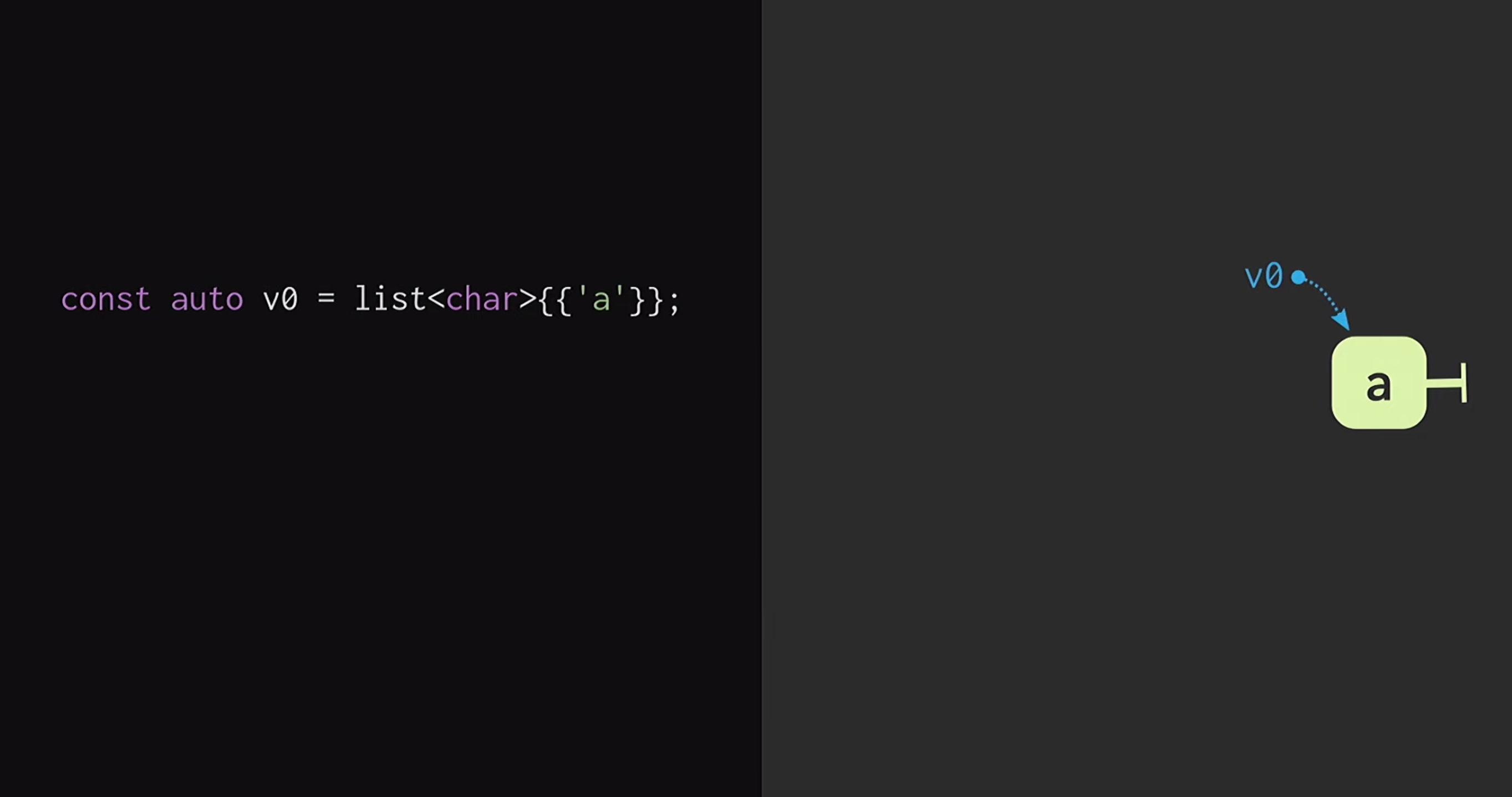 首先,让我们假设我们有一个带有单个节点的列表
首先,让我们假设我们有一个带有单个节点的列表v1它们v0表示不同的元素。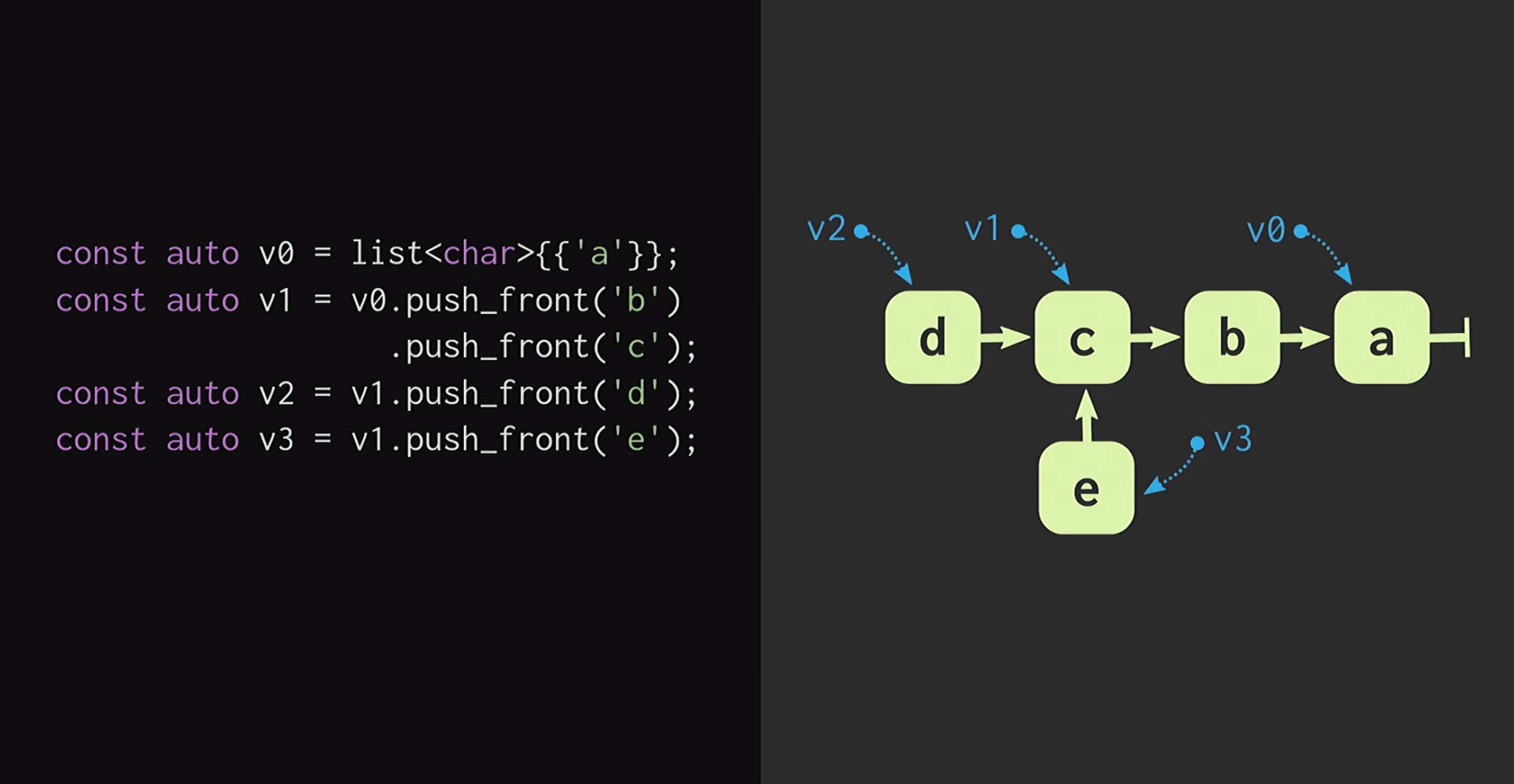 我们还可以创建一个现实的分支,即创建一个具有相同结尾但具有不同开始的新列表。这种数据结构已经研究了很长时间:Chris Okasaki撰写了Pure Functional Functional Data Structures的基础著作。此外,Ralf Hinze和Ross Paterson提出的Finger Tree数据结构非常有趣。但是对于C ++,这样的数据结构不能很好地工作。他们使用小节点,并且我们知道在C ++中,小节点意味着缺乏缓存效率。此外,它们通常依赖C ++没有的属性,例如惰性。因此,Phil Bagwell在不可变数据结构方面的工作对我们来说更有用- 2000年代初期写的链接,以及Rich Hickey的工作- 链接,Clojure的作者。 Rich Hickey创建了一个列表,该列表实际上不是列表,而是基于现代数据结构:向量和哈希图。这些数据结构具有缓存效率,并且可以与现代处理器良好地交互,因此,不希望使用小型节点。这样的结构可以在C ++中使用。如何建立免疫载体?在任何结构的核心,甚至是远程类似于矢量的结构,都必须有一个数组。但是数组没有结构共享。要更改数组的任何元素而又不丢失持久性属性,必须复制整个数组。为了不这样做,可以将数组拆分为单独的部分。现在,在更新向量元素时,我们只需要复制一件,而不是整个向量。但是,这些部分本身不是数据结构;它们必须以一种或另一种方式组合。将它们放在另一个数组中。再次出现的问题是数组可能非常大,然后再次复制将花费太多时间。我们将此数组分为多个部分,将它们再次放置在单独的数组中,然后重复此过程,直到只有一个根数组为止。所得的结构称为残差树。该树由常数M = 2B(即分支因子)描述。该分支指标应为2的幂,我们将很快找出原因。在幻灯片的示例中,使用了四个字符的块,但实际上,使用了32个字符的块。有一些实验可以帮助您找到特定体系结构的最佳块大小。这使您可以实现结构化共享访问与访问时间的最佳比率:树越低,访问时间越短。读了这篇文章,用C ++编写的开发人员可能会想到:但是任何基于树的结构都非常慢!树木随着其中元素数量的增加而增长,因此,访问时间会缩短。这就是为什么程序员更喜欢
我们还可以创建一个现实的分支,即创建一个具有相同结尾但具有不同开始的新列表。这种数据结构已经研究了很长时间:Chris Okasaki撰写了Pure Functional Functional Data Structures的基础著作。此外,Ralf Hinze和Ross Paterson提出的Finger Tree数据结构非常有趣。但是对于C ++,这样的数据结构不能很好地工作。他们使用小节点,并且我们知道在C ++中,小节点意味着缺乏缓存效率。此外,它们通常依赖C ++没有的属性,例如惰性。因此,Phil Bagwell在不可变数据结构方面的工作对我们来说更有用- 2000年代初期写的链接,以及Rich Hickey的工作- 链接,Clojure的作者。 Rich Hickey创建了一个列表,该列表实际上不是列表,而是基于现代数据结构:向量和哈希图。这些数据结构具有缓存效率,并且可以与现代处理器良好地交互,因此,不希望使用小型节点。这样的结构可以在C ++中使用。如何建立免疫载体?在任何结构的核心,甚至是远程类似于矢量的结构,都必须有一个数组。但是数组没有结构共享。要更改数组的任何元素而又不丢失持久性属性,必须复制整个数组。为了不这样做,可以将数组拆分为单独的部分。现在,在更新向量元素时,我们只需要复制一件,而不是整个向量。但是,这些部分本身不是数据结构;它们必须以一种或另一种方式组合。将它们放在另一个数组中。再次出现的问题是数组可能非常大,然后再次复制将花费太多时间。我们将此数组分为多个部分,将它们再次放置在单独的数组中,然后重复此过程,直到只有一个根数组为止。所得的结构称为残差树。该树由常数M = 2B(即分支因子)描述。该分支指标应为2的幂,我们将很快找出原因。在幻灯片的示例中,使用了四个字符的块,但实际上,使用了32个字符的块。有一些实验可以帮助您找到特定体系结构的最佳块大小。这使您可以实现结构化共享访问与访问时间的最佳比率:树越低,访问时间越短。读了这篇文章,用C ++编写的开发人员可能会想到:但是任何基于树的结构都非常慢!树木随着其中元素数量的增加而增长,因此,访问时间会缩短。这就是为什么程序员更喜欢std::unordered_map而不是std::map。我赶紧向你保证:我们的树长得很慢。包含32位int的所有可能值的向量仅高7级。可以通过实验证明,在这种数据大小的情况下,缓存与负载量的比率比树的深度显着影响性能。让我们看看如何执行对树元素的访问。假设您需要转到元素17。我们采用索引的二进制表示形式并将其分为分支因子大小的组。 在每个组中,我们使用相应的二进制值,然后沿树下移。接下来,假设我们需要对该数据结构进行更改,即执行method
在每个组中,我们使用相应的二进制值,然后沿树下移。接下来,假设我们需要对该数据结构进行更改,即执行method .set。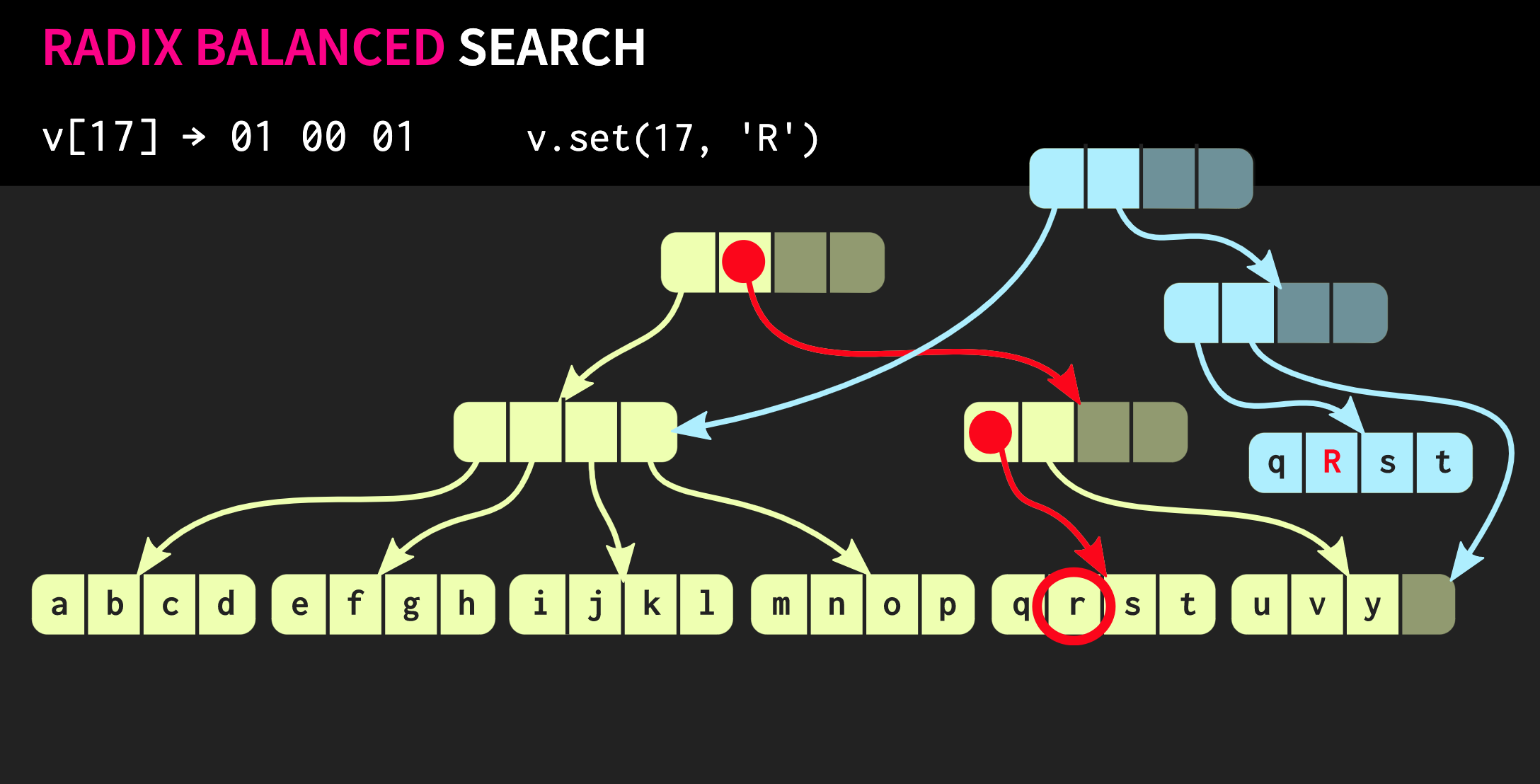 为此,首先需要复制元素所在的块,然后将路径上的每个内部节点复制到该元素。一方面,必须复制很多数据,但与此同时,这些数据的很大一部分是通用的,这补偿了它们的容量。顺便说一句,有一个非常老的数据结构与我描述的数据结构非常相似。这些是带有页表树的内存页。她的管理也可以通过电话进行
为此,首先需要复制元素所在的块,然后将路径上的每个内部节点复制到该元素。一方面,必须复制很多数据,但与此同时,这些数据的很大一部分是通用的,这补偿了它们的容量。顺便说一句,有一个非常老的数据结构与我描述的数据结构非常相似。这些是带有页表树的内存页。她的管理也可以通过电话进行fork。让我们尝试改善我们的数据结构。假设我们需要连接两个向量。到目前为止描述的数据结构具有相同的局限性,std::vector:因为它的最右边部分具有空单元格。由于结构完全平衡,因此这些空单元格不能位于树的中间。因此,如果有第二个向量要与第一个向量结合,则需要将元素复制到空单元格,这将在第二个向量中创建空单元格,最后,我们必须复制整个第二个向量。这样的运算具有计算复杂度O(n),其中n是第二向量的大小。我们将努力取得更好的结果。我们的数据结构有一个修改后的版本,称为松弛基数平衡树。在这种结构中,不在最左侧路径上的节点可能具有空单元格。因此,在这种不完整(或松弛)的节点中,有必要计算子树的大小。现在,您可以执行复杂但对数的联接操作。此时间复杂度恒定的操作为O(log(32))。由于树木很浅,因此进入时间虽然相对较长,但却是恒定的。由于我们具有这样的联合操作,因此该数据结构的宽松版本称为合流:除了可以持久化(可以派生)之外,还可以将两个这样的结构组合为一个。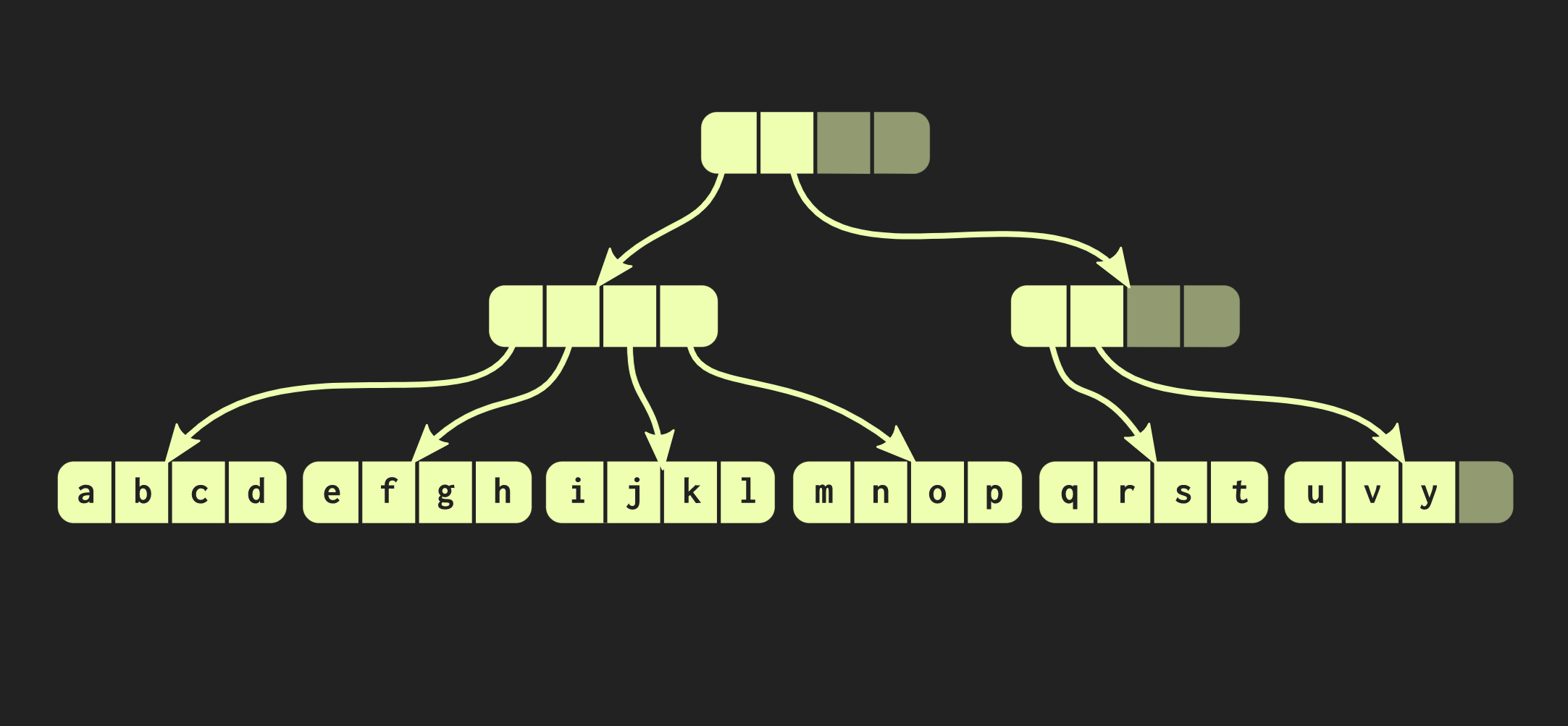 在到目前为止我们使用的示例中,数据结构非常整洁,但是在实践中,Clojure和其他功能语言的实现看起来有所不同。它们为每个值创建容器,也就是说,向量中的每个元素都在单独的单元格中,并且叶节点包含指向这些元素的指针。但是这种方法效率极低,在C ++中通常不会将每个值都放在容器中。因此,最好将这些元素直接位于节点中。然后出现另一个问题:不同的元素具有不同的大小。如果元素的大小与指针的大小相同,则我们的结构将如下所示:
在到目前为止我们使用的示例中,数据结构非常整洁,但是在实践中,Clojure和其他功能语言的实现看起来有所不同。它们为每个值创建容器,也就是说,向量中的每个元素都在单独的单元格中,并且叶节点包含指向这些元素的指针。但是这种方法效率极低,在C ++中通常不会将每个值都放在容器中。因此,最好将这些元素直接位于节点中。然后出现另一个问题:不同的元素具有不同的大小。如果元素的大小与指针的大小相同,则我们的结构将如下所示: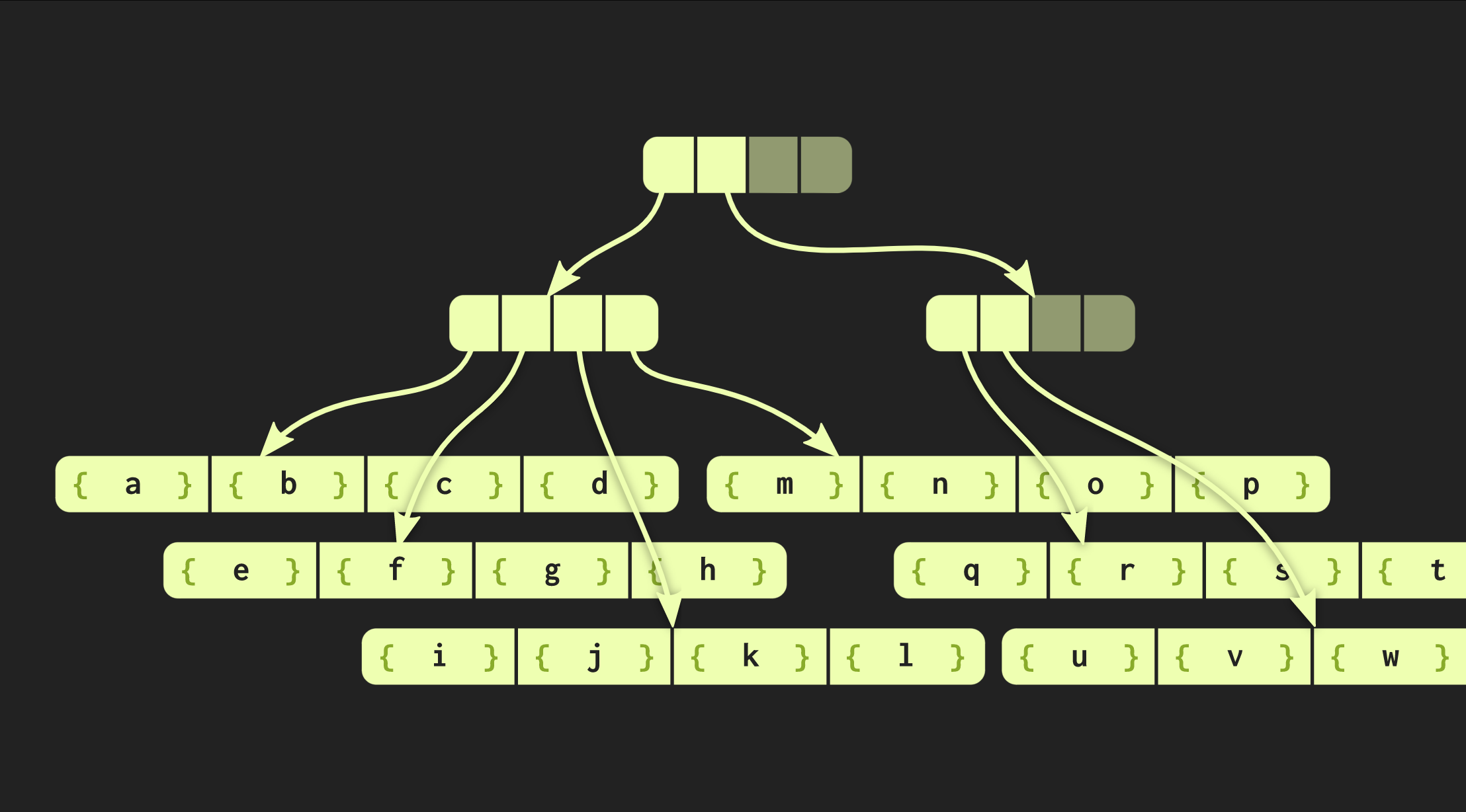 但是,如果元素很大,则数据结构将丢失我们测量的属性(访问时间O(log(32)())),因为现在复制一张纸需要更长的时间,因此,我更改了此数据结构,以便随着大小的增加而改变树中包含的元素数量减少了叶节点中这些元素的数量;相反,如果元素较小,则现在可以容纳更多的树。树的新版本称为嵌入基数平衡树,它不是用一个常量描述的,而是用两个常量描述的:其中一个描述内部节点,以及第二个叶子的.. C ++中树的实现可以根据指针和元素本身的大小来计算leaf元素的最佳大小。我们的树已经可以很好地工作了,但是仍然可以改进。看一下一个类似于函数的函数
但是,如果元素很大,则数据结构将丢失我们测量的属性(访问时间O(log(32)())),因为现在复制一张纸需要更长的时间,因此,我更改了此数据结构,以便随着大小的增加而改变树中包含的元素数量减少了叶节点中这些元素的数量;相反,如果元素较小,则现在可以容纳更多的树。树的新版本称为嵌入基数平衡树,它不是用一个常量描述的,而是用两个常量描述的:其中一个描述内部节点,以及第二个叶子的.. C ++中树的实现可以根据指针和元素本身的大小来计算leaf元素的最佳大小。我们的树已经可以很好地工作了,但是仍然可以改进。看一下一个类似于函数的函数iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
它接受一个输入vector,push_back在向量的末尾对first和之间的每个整数执行last,然后返回发生的情况。一切都与该功能的正确性有关,但它的效率很低。每个调用push_back不必要地复制最左边的块:下一个调用将推入另一个元素,然后再次重复该复制,并且删除通过前一个方法复制的数据。您可以尝试该功能的另一种实现,其中我们放弃了该功能的持久性。可以transient vector与与常规API兼容的可变API一起使用vector。在这样的函数中,每个调用都会push_back更改数据结构。vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
此实现效率更高,并且允许您在正确的路径上重用新元素。在该函数的末尾,将.persistent()进行一个返回不可变的调用vector。从功能外部看不到可能的副作用。原始的vector过去是并且仍然是不变的,只有函数内部创建的数据才被更改。就像我说的那样,这种方法的一个重要优点是您可以使用std::back_inserter需要可变API的标准算法。考虑另一个例子。vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
该函数不接受并返回vector,但在内部执行调用链push_back。在此,如前面的示例一样,可能会在呼叫内部发生不必要的复制push_back。请注意,执行的第一个值是push_back命名值,其余的是r值,即匿名链接。如果使用引用计数,则该方法push_back可以引用树中为其分配内存的节点的引用计数器。对于r值,如果链接数为1,则很明显程序的其他部分都无法访问这些节点。此处的性能与的情况完全相同transient。vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
此外,为了帮助编译器,我们可以执行它move(v),因为v该函数在其他任何地方都没有使用。我们有一个重要的优势,它不在transient变量中:如果将另一个say_hi的返回值传递给say_hi函数,那么将不会有多余的副本。在c的情况下,transient存在可能发生过度复制的边界。换句话说,我们有一个持久的,不变的数据结构,其性能取决于运行时共享访问的实际数量。如果没有共享,那么性能将与可变数据结构相同。这是一个非常重要的属性。我上面已经向您展示的示例可以用方法重写move(v)。vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
到目前为止,我们已经讨论了向量,除了它们之外,还存在哈希映射。他们致力于Phil Nash的非常有用的报告:圣杯。用于C ++的哈希数组映射的特里。它描述了基于我刚才谈到的相同原理实现的哈希表。我敢肯定,你们中的许多人对这种结构的性能有疑问。他们在实践中工作很快吗?我已经做了很多测试,总之我的回答是。如果您想了解有关测试结果的更多信息,它们将发布在我的函数式编程国际会议2017上。现在,我认为最好讨论的不是绝对值,而是这种数据结构对整个系统的影响。当然,更新向量的速度较慢,因为您需要复制多个数据块并为其他数据分配内存。但是绕过我们的向量的速度几乎与正常速度相同。对我而言,实现这一点非常重要,因为读取数据的频率要比更改数据的频率高得多。此外,由于更新速度较慢,因此无需复制任何内容,只需复制数据结构即可。因此,对于系统中执行的所有副本,摊销了更新向量所花费的时间。因此,如果您以与我在报告开头所述的架构类似的方式来应用此数据结构,则性能将大大提高。假发
我不会毫无根据,并通过示例演示我的数据结构。我写了一个小的文本编辑器。这是一个称为ewig的交互式工具,其中的文档由不可变的矢量表示。我的磁盘上有整个世界语维基百科的副本,它的重量为1 GB(起初我想下载英文版本,但太大了)。无论您使用哪种文本编辑器,我都可以肯定他不会喜欢此文件的。在ewig中下载该文件时,由于下载是异步的,因此可以立即对其进行编辑。文件导航有效,没有挂起,没有mutex,没有同步。如您所见,下载的文件需要2000万行代码。在考虑此工具的最重要属性之前,让我们注意一个有趣的细节。 在该行的开头(在图像底部以白色突出显示),您看到两个连字符。这个用户界面很可能是emacs用户所熟悉的;那里的连字符表示该文档没有进行任何修改。如果进行任何更改,则会显示星号而不是连字符。但是,与其他编辑器不同,如果您在ewig中删除这些更改(不要撤消它,只需将其删除),则连字符将再次出现而不是星号,因为所有以前的文本版本都保存在ewig中。因此,不需要特殊标志来显示文档是否已更改:更改的存在是通过与原始文档进行比较来确定的。考虑一下该工具的另一个有趣的属性:复制整个文本并将其粘贴几次到现有文本的中间。如您所见,这是立即发生的。在这里将向量连接起来是对数运算,几百万的对数并不是那么长的运算。如果尝试将这个巨大的文档保存到硬盘驱动器,则将需要更长的时间,因为文本不再显示为从该矢量的先前版本获得的矢量。保存到磁盘时,会发生序列化,因此会丢失持久性。
在该行的开头(在图像底部以白色突出显示),您看到两个连字符。这个用户界面很可能是emacs用户所熟悉的;那里的连字符表示该文档没有进行任何修改。如果进行任何更改,则会显示星号而不是连字符。但是,与其他编辑器不同,如果您在ewig中删除这些更改(不要撤消它,只需将其删除),则连字符将再次出现而不是星号,因为所有以前的文本版本都保存在ewig中。因此,不需要特殊标志来显示文档是否已更改:更改的存在是通过与原始文档进行比较来确定的。考虑一下该工具的另一个有趣的属性:复制整个文本并将其粘贴几次到现有文本的中间。如您所见,这是立即发生的。在这里将向量连接起来是对数运算,几百万的对数并不是那么长的运算。如果尝试将这个巨大的文档保存到硬盘驱动器,则将需要更长的时间,因为文本不再显示为从该矢量的先前版本获得的矢量。保存到磁盘时,会发生序列化,因此会丢失持久性。返回基于价值的架构
 让我们从如何回到这种架构开始:使用通常的Java风格的Controller,Model和View,它们最常用于C ++的交互式应用程序。它们没有错,但是它们不适合我们的问题。一方面,Model-View-Controller模式允许分离任务,但另一方面,从面向对象的角度和C ++的角度来看,每个元素都是一个对象,也就是说,这些是可变的内存区域健康)状况。视图了解模型;更糟糕的是-Model间接了解View,因为几乎可以肯定有一个回调,当Model更改时,通过该回调会通知View。即使使用面向对象原理的最佳实现,我们也会得到很多相互依赖。
让我们从如何回到这种架构开始:使用通常的Java风格的Controller,Model和View,它们最常用于C ++的交互式应用程序。它们没有错,但是它们不适合我们的问题。一方面,Model-View-Controller模式允许分离任务,但另一方面,从面向对象的角度和C ++的角度来看,每个元素都是一个对象,也就是说,这些是可变的内存区域健康)状况。视图了解模型;更糟糕的是-Model间接了解View,因为几乎可以肯定有一个回调,当Model更改时,通过该回调会通知View。即使使用面向对象原理的最佳实现,我们也会得到很多相互依赖。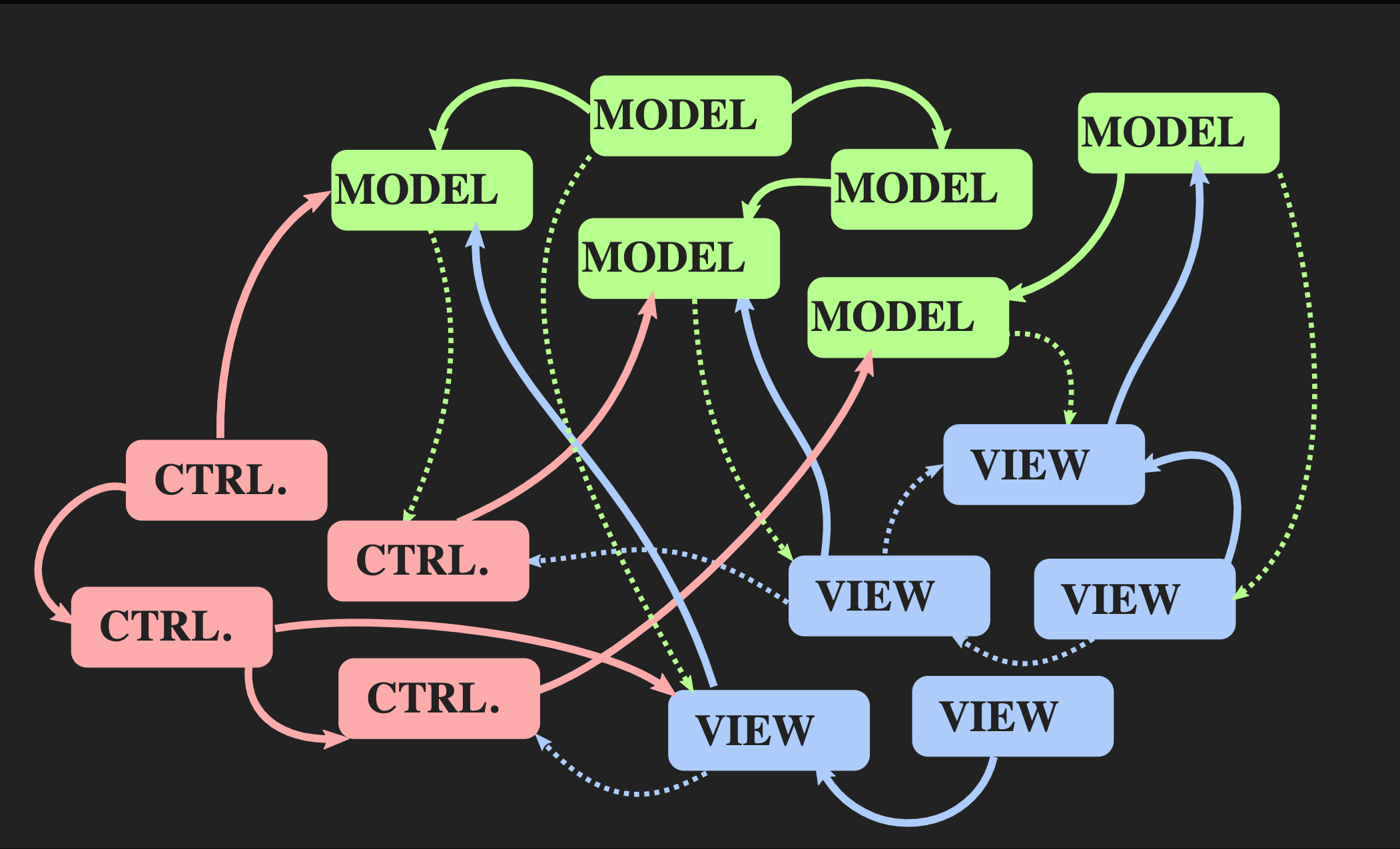 随着应用程序的增长和新的Model,Controller和View的添加,出现一种情况是,为了更改程序的某个部分,您需要了解与它相关联的所有部分,通过接收警报的所有View
随着应用程序的增长和新的Model,Controller和View的添加,出现一种情况是,为了更改程序的某个部分,您需要了解与它相关联的所有部分,通过接收警报的所有View callback等。因此,每个人熟悉的面食怪物开始通过这些依赖项窥视。是否可以使用其他架构?对于模型-视图-控制器模式,有另一种方法称为“单向数据流体系结构”。这个概念不是我发明的,它在Web开发中经常使用。在Facebook上,这称为Flux架构,但在C ++中尚未应用。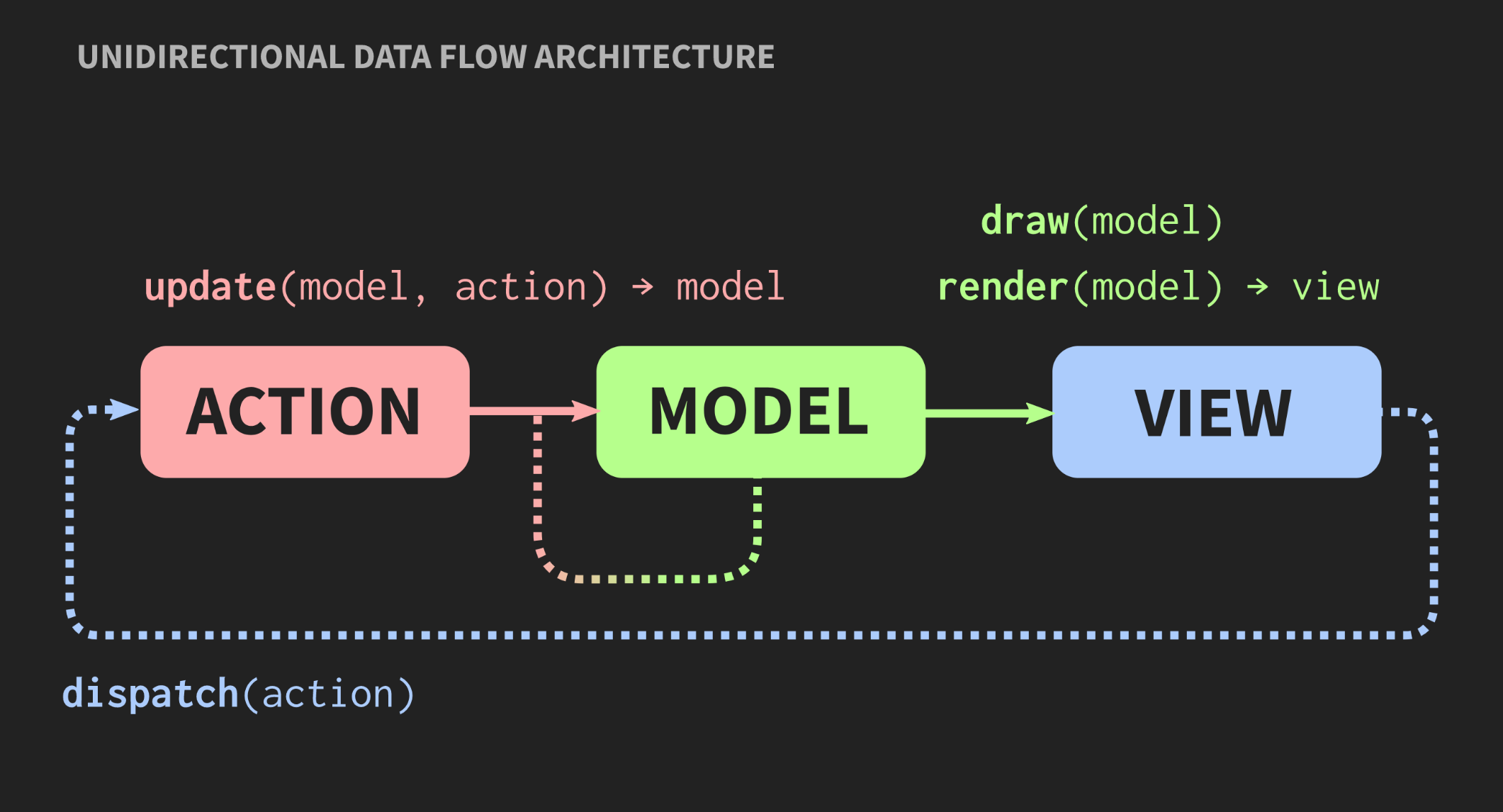 这种架构的元素已经为我们所熟悉:动作,模型和视图,但是方框和箭头的含义不同。块是值,不是对象,也不是具有可变状态的区域。这甚至适用于View。此外,箭头不是链接,因为没有对象就不可能有链接。这里的箭头是功能。在动作和模型之间,有一个更新函数可以接受当前的模型(即世界的当前状态)和动作(Action),它表示事件的表示(例如,单击鼠标或抽象级别的事件,例如将元素或符号插入文档)。更新功能更新文档并返回新的状态。模型连接到View函数渲染器,后者使用Model并返回视图。这需要一个可以将View表示为值的框架。在Web开发中,React会这样做,但是在C ++中,还没有类似的东西,尽管谁知道,如果有人愿意付钱给我写这样的东西,它可能很快就会出现。同时,您可以使用即时模式API,在该模式中,绘图功能可让您创建一个副作用值。最后,视图应具有允许用户或其他事件源发送Action的机制。有一个简单的方法可以实现,如下所示:
这种架构的元素已经为我们所熟悉:动作,模型和视图,但是方框和箭头的含义不同。块是值,不是对象,也不是具有可变状态的区域。这甚至适用于View。此外,箭头不是链接,因为没有对象就不可能有链接。这里的箭头是功能。在动作和模型之间,有一个更新函数可以接受当前的模型(即世界的当前状态)和动作(Action),它表示事件的表示(例如,单击鼠标或抽象级别的事件,例如将元素或符号插入文档)。更新功能更新文档并返回新的状态。模型连接到View函数渲染器,后者使用Model并返回视图。这需要一个可以将View表示为值的框架。在Web开发中,React会这样做,但是在C ++中,还没有类似的东西,尽管谁知道,如果有人愿意付钱给我写这样的东西,它可能很快就会出现。同时,您可以使用即时模式API,在该模式中,绘图功能可让您创建一个副作用值。最后,视图应具有允许用户或其他事件源发送Action的机制。有一个简单的方法可以实现,如下所示:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
除了异步保存和加载外,这是刚刚介绍的编辑器中使用的代码。这里有一个对象terminal,允许您从命令行读取和写入。此外,application这是Model的值,它存储了应用程序的整个状态。如您在屏幕顶部所见,有一个函数可以返回新版本application。该函数内部的循环一直执行到应用程序需要关闭为止,即直到!state.done。在循环中,绘制了一个新状态,然后请求下一个事件。最后,状态存储在局部变量中state,循环再次开始。这段代码有一个非常重要的优点:在程序执行过程中仅存在一个可变变量,它是一个对象state。Clojure开发人员称之为单原子体系结构:在整个应用程序中只有一个单一点,可以通过它进行所有更改。应用程序逻辑不以任何方式参与更新此点;为此,进行了专门设计的循环。因此,应用程序逻辑完全由纯函数(例如functions)组成update。通过这种编写应用程序的方法,关于软件的思考方式正在发生变化。现在的工作不是从接口和操作的UML图开始,而是从数据本身开始。面向数据的设计有一些相似之处。真实的,面向数据的设计通常用于获得最佳性能,在这里,除了速度之外,我们还追求简单性和正确性。重点稍有不同,但是在方法上有重要的相似之处。using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
以上是我们应用程序的主要数据类型。该应用程序的主体由组成line,它是flex_vector,而flex_vector是vector可以对其执行联接操作的主体。接下来text是存储它的向量line。如您所见,这是文本的非常简单的表示形式。Text在其帮助file下存储的具有名称,即文件系统中的地址,实际上text。作为file另一种类型,一个简单但非常有用的:box。这是一个单元素容器。它允许您放入堆中并移动对象,进行复制可能会占用大量资源。另一个重要类型:snapshot。基于此类型,取消功能处于活动状态。它包含一个文档(格式为text)和光标位置(坐标)。这使您可以将光标返回到编辑过程中的位置。下一个类型是buffer。这是vim和emacs的术语,因为在那里称为开放文档。在buffer其中有一个文件,可从中下载文本以及文本的内容-这使您可以检查文档中的更改。为了突出显示文本的一部分,有一个可选变量selection_start指示选择的开始。来自的向量snapshot是文本的故事。请注意,我们不使用团队模式;历史记录仅由状态组成。最后,如果取消刚刚完成,则需要状态历史记录中的位置索引history_pos。下一个类型:application。它包含一个打开的文档(缓冲区),key_map以及key_seq用于键盘快捷键,以及来自text剪贴板的矢量,以及用于显示在屏幕底部的消息的另一个矢量。到目前为止,在该应用程序的首个版本中,将只有一个线程和一种类型的操作需要输入key_code和coord。你们中的大多数人很可能已经在考虑如何实施这些操作。如果按值取值并按值返回,那么在大多数情况下,操作非常简单。我的文本编辑器的代码发布在github上,因此您可以看到它的实际外观。现在,我将仅详细介绍实现取消功能的代码。取消
在没有适当基础架构的情况下正确编写取消记录并不是那么简单。在我的编辑器中,我按照emacs的方式实现了它,因此首先要介绍一下其基本原理。 return命令在此处丢失,因此,您不能丢掉工作。如果需要返回,则对文本进行任何更改,然后所有取消动作再次成为取消历史的一部分。 上面描述了该原理。这里的红色菱形显示了历史上的位置:如果取消尚未完成,则红色菱形总是在最后。如果取消,菱形将向后移一个状态,但同时,另一状态将被添加到队列的末尾-与用户当前看到的状态相同(S3)。如果再次取消并返回到状态S2,则将状态S2添加到队列的末尾。如果现在用户进行了某种更改,它将作为新的S5状态添加到队列的末尾,并且将菱形移动到该队列。现在,撤消过去的动作时,先前的撤消动作将首先滚动。要实现这种取消系统,以下代码就足够了:
上面描述了该原理。这里的红色菱形显示了历史上的位置:如果取消尚未完成,则红色菱形总是在最后。如果取消,菱形将向后移一个状态,但同时,另一状态将被添加到队列的末尾-与用户当前看到的状态相同(S3)。如果再次取消并返回到状态S2,则将状态S2添加到队列的末尾。如果现在用户进行了某种更改,它将作为新的S5状态添加到队列的末尾,并且将菱形移动到该队列。现在,撤消过去的动作时,先前的撤消动作将首先滚动。要实现这种取消系统,以下代码就足够了:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
有两个动作,record和undo。Record在任何操作期间执行。这非常方便,因为我们不需要知道是否对文档进行过任何编辑。该功能对应用程序逻辑是透明的。执行任何操作后,该功能将检查文档是否已更改。如果发生更改push_back,则执行的内容和光标位置history。如果该动作没有导致更改history_pos(即,接收到的输入buffer不是由cancel动作引起的),则history_pos分配一个值null。如有必要undo,我们进行检查history_pos。如果没有意义,我们认为它history_pos只是故事的结尾。如果取消历史记录不为空(即history_pos而不是故事的开始),则执行取消。当前的内容和光标将被替换和更改history_pos。撤消操作的不可撤消性是通过函数来实现的,该函数record在撤消操作期间也被调用。因此,我们有一个undo占用10行代码的操作,并且无需更改(或更改很少)即可在几乎所有其他应用程序中使用。时间旅行
关于时间旅行。正如我们现在将看到的,这是与取消有关的主题。我将演示框架的工作,该框架将为具有类似体系结构的任何应用程序添加有用的功能。这里的框架称为ewig-debug。此版本的ewig包含一些调试功能。现在,可以从浏览器中打开调试器,在其中可以检查应用程序的状态。 我们看到最后一个动作是调整大小,因为我打开了一个新窗口,并且窗口管理器自动调整了已经打开的窗口的大小。当然,对于JSON中的自动序列化,我必须从特殊的反射库中为struct添加注释。但是系统的其余部分相当通用,可以连接到任何类似的应用程序。现在,在浏览器中,您可以看到所有完成的操作。当然,有一个初始状态不起作用。这是下载之前的状态。此外,通过双击,我可以将应用程序恢复到之前的状态。这是一个非常有用的调试工具,可让您跟踪应用程序中故障的发生。如果您有兴趣,可以收听我在CPPCON 19上的报告,“最有价值的价值”,在那里我将详细检查该调试器。此外,基于价值的体系结构在此进行了更详细的讨论。在其中,我还告诉您如何实施操作并进行分层组织。这样可以确保系统的模块化,并允许您不要将所有内容都保留在一项重要的更新功能中。此外,该报告还讨论了异步和多线程文件下载。该报告还有另一个版本,其中半小时的附加材料是后现代不变数据结构。
我们看到最后一个动作是调整大小,因为我打开了一个新窗口,并且窗口管理器自动调整了已经打开的窗口的大小。当然,对于JSON中的自动序列化,我必须从特殊的反射库中为struct添加注释。但是系统的其余部分相当通用,可以连接到任何类似的应用程序。现在,在浏览器中,您可以看到所有完成的操作。当然,有一个初始状态不起作用。这是下载之前的状态。此外,通过双击,我可以将应用程序恢复到之前的状态。这是一个非常有用的调试工具,可让您跟踪应用程序中故障的发生。如果您有兴趣,可以收听我在CPPCON 19上的报告,“最有价值的价值”,在那里我将详细检查该调试器。此外,基于价值的体系结构在此进行了更详细的讨论。在其中,我还告诉您如何实施操作并进行分层组织。这样可以确保系统的模块化,并允许您不要将所有内容都保留在一项重要的更新功能中。此外,该报告还讨论了异步和多线程文件下载。该报告还有另一个版本,其中半小时的附加材料是后现代不变数据结构。总结一下
我认为是时候盘点了。我将引用安迪·温戈(Andy Wingo)-他是一位出色的开发人员,他花了很多时间从事V8和一般的编译器的工作,最后他致力于支持Guile,为GNU实施Scheme。最近,他在Twitter上写道:“为了略微加快程序的速度,我们会衡量每一个小的变化,只留下那些能带来积极结果的变化。我们确实付出了很大的努力,盲目地投入了大量的精力,没有100%的信心,仅凭直觉进行了指导。多么奇怪的二分法。”在我看来,C ++开发人员在第一类游戏中取得了成功。给我们一个封闭的系统,我们将凭借我们的工具,从中挤出一切可能的东西。但是在第二种类型中,我们不习惯工作。当然,第二种方法风险更大,并且常常导致浪费大量精力。另一方面,通过完全重写程序,通常可以使程序更容易,更快捷。我希望我能说服您至少尝试第二种方法。胡安·普恩特(Juan Puente)在C ++ Russia 2019莫斯科会议上发表讲话,并谈到了允许您做有趣事情的数据结构。这些结构的魔力部分在于复制省略-这就是安东·波卢欣(Anton Polukhin)和罗曼·鲁西耶夫(Roman Rusyaev)在即将举行的会议上将谈到的内容。在网站上关注程序更新。