了解打破CAPTCHA的机器学习模型
大家好!本月,OTUS将招募一个新的机器学习课程小组。按照既定传统,在课程开始前夕,我们将与您分享有关该主题的有趣材料的翻译。 计算机视觉是AI最相关和研究最多的主题之一[1],但是,由于卷积神经网络很容易被愚弄,因此目前使用卷积神经网络解决问题的方法受到严重批评。为了没有根据,我将向您介绍以下几个原因:对于以前没有正确分类的图像,对于不包含统计信号[2]的自然生成图像,这种类型的网络会给出高可信度的错误结果,[2]但是其中一个像素[3]或带有物理对象的图像已添加到场景但不必更改分类结果[4]。事实是,如果我们要创建真正的智能机器,对我们来说,投资于新观念的研究似乎是合理的。这些新想法之一是Vicarious在递归皮层网络(RCN)上的应用,它从神经科学中汲取了灵感。该模型声称在破解文本验证码方面非常有效,因此引起了很多讨论。因此,我决定写几篇文章,每篇文章都解释了该模型的某个方面。在本文中,我们将讨论其结构以及如何生成有关RCN [5]的主要文章中介绍的图像。本文假设您已经熟悉卷积神经网络,因此我将与它们进行许多类比。为了准备RCN意识,您需要了解RCN是基于将形状(对象的草图)与外观(其纹理)分离的思想,并且它是一种生成模型,而不是判别模型,因此我们可以使用它来生成图像,就像生成模型一样对抗网络。此外,类似于卷积神经网络的体系结构,使用了并行的分层结构,该结构从确定目标对象在较低层的形状的阶段开始,然后将其外观添加到较高层。与卷积神经网络不同,我们正在考虑的模型依赖于图形模型的丰富理论基础,而不是加权和和梯度下降。现在让我们深入研究RCN结构的功能。
计算机视觉是AI最相关和研究最多的主题之一[1],但是,由于卷积神经网络很容易被愚弄,因此目前使用卷积神经网络解决问题的方法受到严重批评。为了没有根据,我将向您介绍以下几个原因:对于以前没有正确分类的图像,对于不包含统计信号[2]的自然生成图像,这种类型的网络会给出高可信度的错误结果,[2]但是其中一个像素[3]或带有物理对象的图像已添加到场景但不必更改分类结果[4]。事实是,如果我们要创建真正的智能机器,对我们来说,投资于新观念的研究似乎是合理的。这些新想法之一是Vicarious在递归皮层网络(RCN)上的应用,它从神经科学中汲取了灵感。该模型声称在破解文本验证码方面非常有效,因此引起了很多讨论。因此,我决定写几篇文章,每篇文章都解释了该模型的某个方面。在本文中,我们将讨论其结构以及如何生成有关RCN [5]的主要文章中介绍的图像。本文假设您已经熟悉卷积神经网络,因此我将与它们进行许多类比。为了准备RCN意识,您需要了解RCN是基于将形状(对象的草图)与外观(其纹理)分离的思想,并且它是一种生成模型,而不是判别模型,因此我们可以使用它来生成图像,就像生成模型一样对抗网络。此外,类似于卷积神经网络的体系结构,使用了并行的分层结构,该结构从确定目标对象在较低层的形状的阶段开始,然后将其外观添加到较高层。与卷积神经网络不同,我们正在考虑的模型依赖于图形模型的丰富理论基础,而不是加权和和梯度下降。现在让我们深入研究RCN结构的功能。要素图层
RCN中第一种类型的图层称为要素图层。我们将逐步考虑模型,因此现在让我们假设模型的整个层次结构仅由这种类型的层堆叠而成。我们将从高级抽象概念过渡到较低层的更具体功能,如图1所示。这种类型的层由位于二维空间中的多个节点组成,类似于卷积神经网络中的特征图。 图1:几个要素层位于一个之上,另一个在二维空间中具有节点。从第四层到第一层的过渡意味着从一般层到特定层的过渡。每个节点由几个通道组成,每个通道代表一个单独的功能。通道是二进制变量,其值为True或False,指示与该通道相对应的对象是否存在于节点坐标(x,y)的最终生成图像中。在任何级别上,节点都具有相同类型的通道。作为示例,让我们以中间层为例,讨论其通道和上面的层以简化说明。该层上的通道列表将是一个双曲线,一个圆和一个抛物线。在生成图像时,一定程度上,上覆层的计算需要在坐标(1,1)中有一个圆。因此,节点(1、1)将具有与对象“圆”相对应的值True的通道。这将直接影响下一层中的某些节点,即,与邻域(1,1)中的圆关联的较低级要素将设置为True。这些较低级别的对象可以是例如具有不同方向的四个弧。激活较低层的功能后,它们将激活较低层上的通道,直到到达最后一层,图像生成。激活可视化显示在图2。您可能会问,如何清楚地表示一个圆是4个圆弧? RCN如何知道需要一个通道来表示圆?通道及其与其他层的绑定将在RCN培训阶段形成。
图1:几个要素层位于一个之上,另一个在二维空间中具有节点。从第四层到第一层的过渡意味着从一般层到特定层的过渡。每个节点由几个通道组成,每个通道代表一个单独的功能。通道是二进制变量,其值为True或False,指示与该通道相对应的对象是否存在于节点坐标(x,y)的最终生成图像中。在任何级别上,节点都具有相同类型的通道。作为示例,让我们以中间层为例,讨论其通道和上面的层以简化说明。该层上的通道列表将是一个双曲线,一个圆和一个抛物线。在生成图像时,一定程度上,上覆层的计算需要在坐标(1,1)中有一个圆。因此,节点(1、1)将具有与对象“圆”相对应的值True的通道。这将直接影响下一层中的某些节点,即,与邻域(1,1)中的圆关联的较低级要素将设置为True。这些较低级别的对象可以是例如具有不同方向的四个弧。激活较低层的功能后,它们将激活较低层上的通道,直到到达最后一层,图像生成。激活可视化显示在图2。您可能会问,如何清楚地表示一个圆是4个圆弧? RCN如何知道需要一个通道来表示圆?通道及其与其他层的绑定将在RCN培训阶段形成。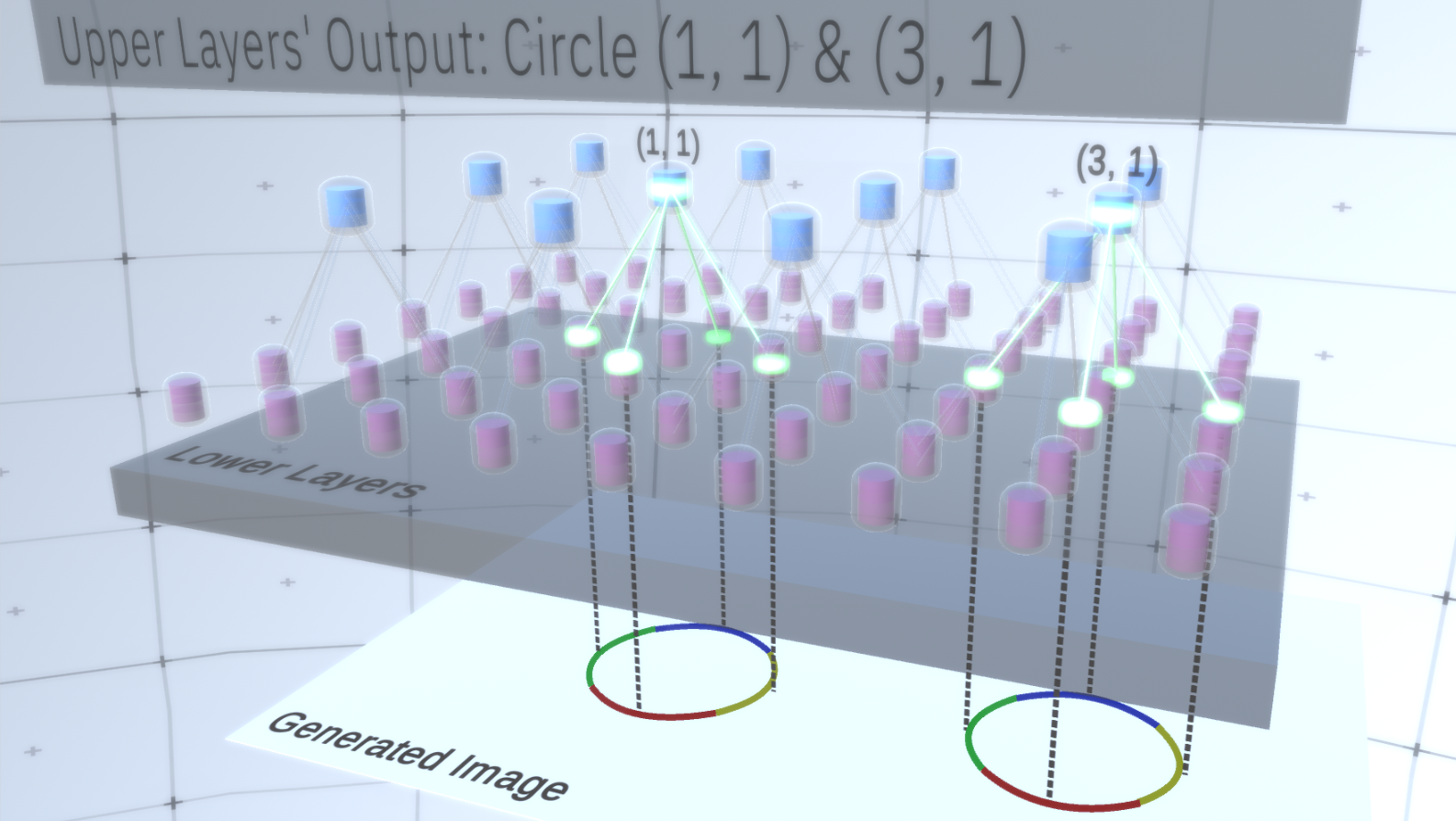 图2:要素图层中的信息流。标志的节点是包含代表通道的磁盘的胶囊。为了简单起见,一些上层和下层以平行六面体的形式呈现,但是,实际上,它们还包含要素节点作为中间层。请注意,上中间层包含3个通道,第二层包含4个通道。您可能会指出一种非常僵化和确定性的方法来生成采用的模型,但是对于人来说,圆的曲率的微小扰动仍然被认为是一个圆,如图3所示。
图2:要素图层中的信息流。标志的节点是包含代表通道的磁盘的胶囊。为了简单起见,一些上层和下层以平行六面体的形式呈现,但是,实际上,它们还包含要素节点作为中间层。请注意,上中间层包含3个通道,第二层包含4个通道。您可能会指出一种非常僵化和确定性的方法来生成采用的模型,但是对于人来说,圆的曲率的微小扰动仍然被认为是一个圆,如图3所示。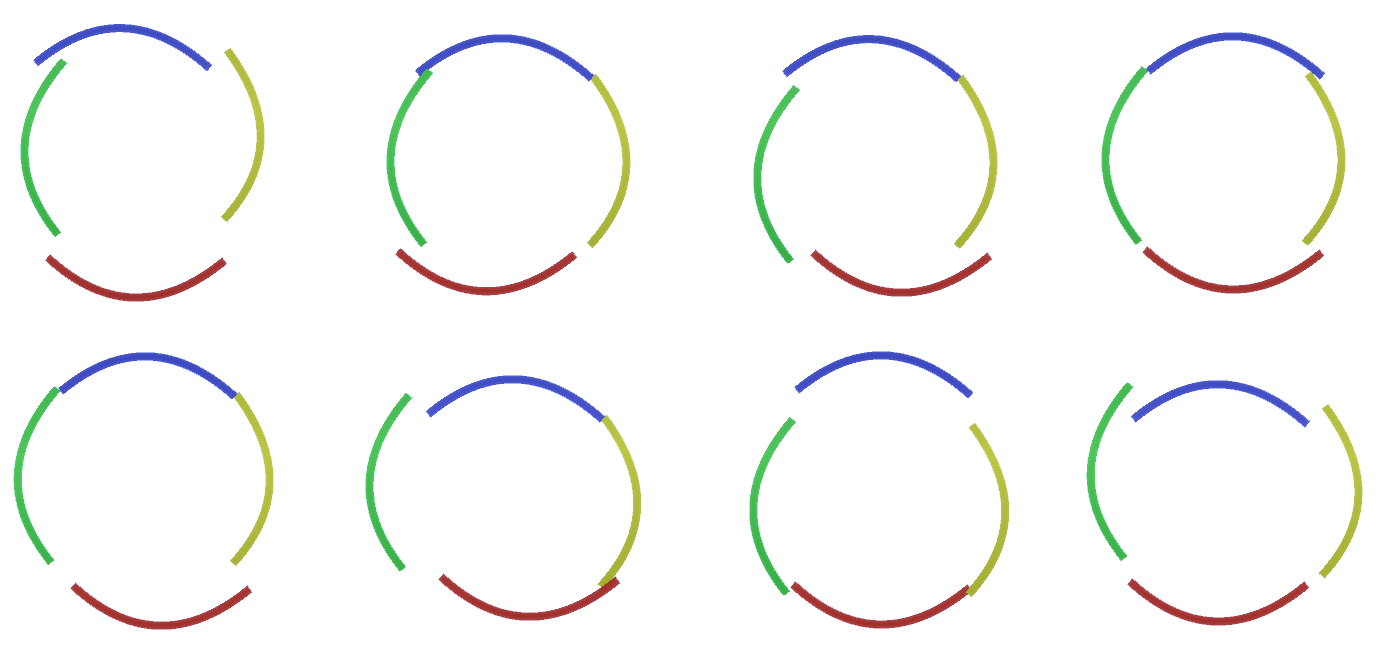 图3:图2中四个弯曲弧的圆的构造的许多变体。很难将这些变体中的每一个视为层中单独的新通道。同样,当我们将RCN调整为分类而不是稍后生成时,将变体分组到同一实体中将极大地促进将其推广到新变体中。但是我们如何改变RCN来获得这个机会?
图3:图2中四个弯曲弧的圆的构造的许多变体。很难将这些变体中的每一个视为层中单独的新通道。同样,当我们将RCN调整为分类而不是稍后生成时,将变体分组到同一实体中将极大地促进将其推广到新变体中。但是我们如何改变RCN来获得这个机会?二次采样层
为此,您需要一种新型的层-池化层。它位于任何两个标志层之间,并充当它们之间的中介。它还由通道组成,但是它们具有整数值,而不是二进制值。为了说明这些层是如何工作的,让我们回到圆形示例。不再需要从其上方的要素层将四个具有固定坐标的弧作为圆的要素,而是对子样本层执行搜索。然后,子样本层中的每个激活的通道将在其附近的基础层上选择一个节点,以允许特征稍有变形。因此,如果我们与子样本节点正下方的9个节点建立通信,则子样本通道在被激活时将均匀地选择这9个节点之一并激活它,所选节点的索引将是子样本通道的状态-整数。在图4中您会看到多个运行,其中每个运行分别使用一组不同的较低级别的节点,从而可以用各种方式创建一个圆。 图4:子采样层的操作。此GIF图片中的每个帧都是单独启动的。二次采样节点是多维数据集。在此图像中,子样本节点具有4个通道,这些通道等效于其下面的要素层的4个通道。上层和下层完全从图片中删除。尽管事实上我们需要模型的可变性,但是如果它仍然保持更多的约束性和集中性会更好。在前两个图中,由于圆弧没有互连,因此某些圆看起来实在太奇怪了,无法将它们真正解释为圆,如图5所示。。我们希望避免生成它们。因此,如果我们可以添加一种对通道进行二次采样的机制,以协调特征节点的选择并关注连续形式,那么我们的模型将更加准确。
图4:子采样层的操作。此GIF图片中的每个帧都是单独启动的。二次采样节点是多维数据集。在此图像中,子样本节点具有4个通道,这些通道等效于其下面的要素层的4个通道。上层和下层完全从图片中删除。尽管事实上我们需要模型的可变性,但是如果它仍然保持更多的约束性和集中性会更好。在前两个图中,由于圆弧没有互连,因此某些圆看起来实在太奇怪了,无法将它们真正解释为圆,如图5所示。。我们希望避免生成它们。因此,如果我们可以添加一种对通道进行二次采样的机制,以协调特征节点的选择并关注连续形式,那么我们的模型将更加准确。 图5:构建圆的许多选项。我们要删除的那些选项用红叉标记。为此,RCN作者在子采样层中使用了横向连接。本质上,子采样通道将与直接环境中的其他子采样通道链接,并且这些链接将不允许某些状态对同时在两个通道中共存。实际上,这两个通道的采样面积将受到限制。例如,在各种形式的圆中,这些连接将不允许两个相邻的弧彼此远离。此机制如图6所示。。同样,这些关系是在培训阶段建立的。应当指出的是,尽管现代香草人工神经网络确实存在于生物神经网络中,但它们的层中没有任何横向连接,并且假定它们在视觉皮层的轮廓整合中发挥了作用(但坦率地说,视觉皮层具有比以前的陈述看起来更复杂的设备)。
图5:构建圆的许多选项。我们要删除的那些选项用红叉标记。为此,RCN作者在子采样层中使用了横向连接。本质上,子采样通道将与直接环境中的其他子采样通道链接,并且这些链接将不允许某些状态对同时在两个通道中共存。实际上,这两个通道的采样面积将受到限制。例如,在各种形式的圆中,这些连接将不允许两个相邻的弧彼此远离。此机制如图6所示。。同样,这些关系是在培训阶段建立的。应当指出的是,尽管现代香草人工神经网络确实存在于生物神经网络中,但它们的层中没有任何横向连接,并且假定它们在视觉皮层的轮廓整合中发挥了作用(但坦率地说,视觉皮层具有比以前的陈述看起来更复杂的设备)。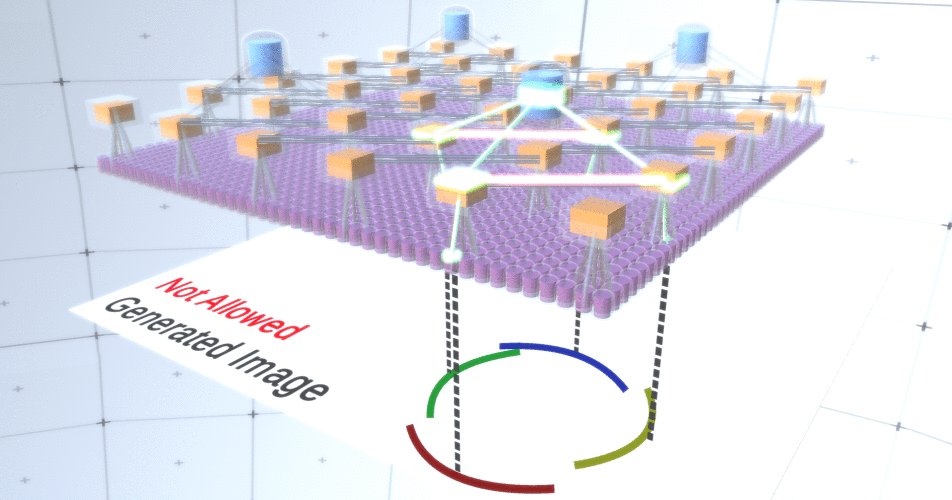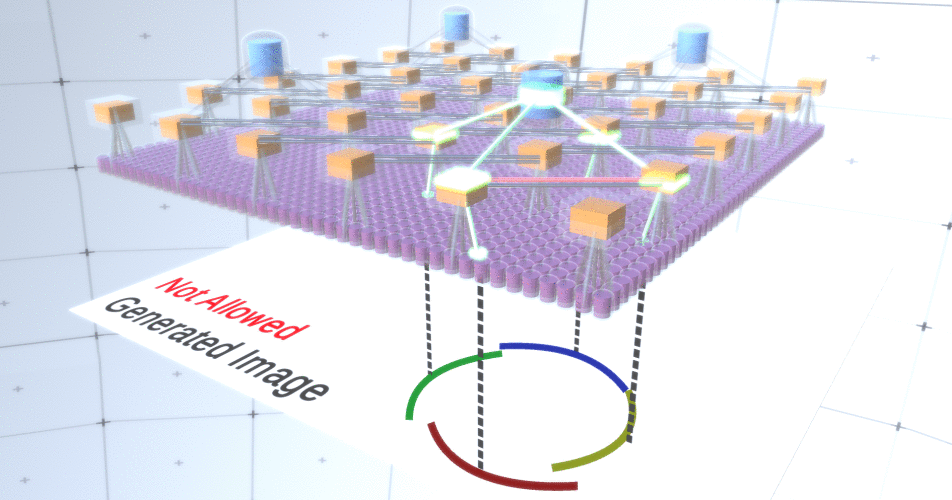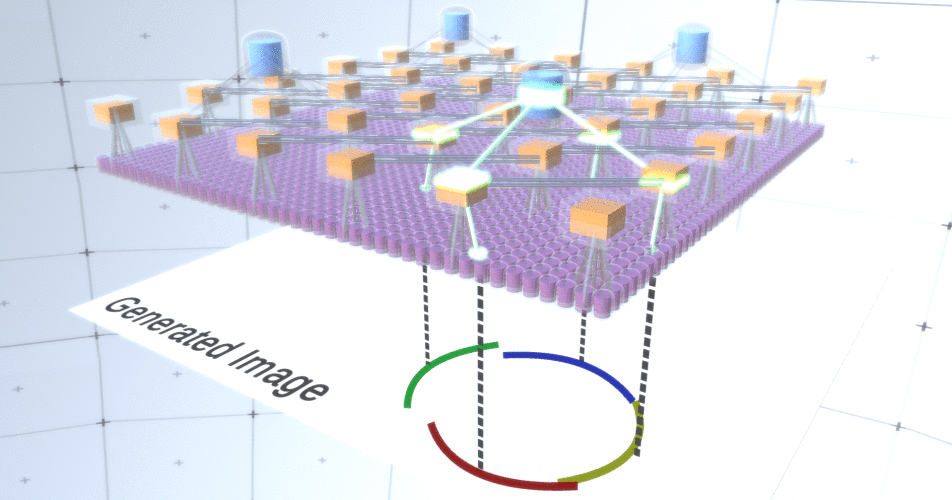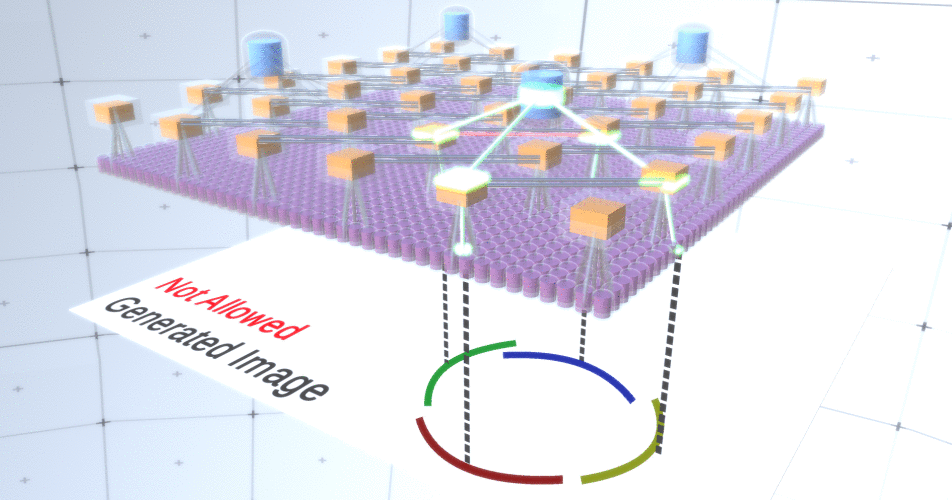 图6: GIF- RCN . , . , RCN , , . .到目前为止,我们讨论了RCN的中间层,只有最顶层和最底层与生成图像的像素进行交互。最顶层是常规要素层,其中每个节点的通道将成为我们标记的数据集的类。生成时,我们只需选择位置和要创建的类,然后转到具有指定位置的节点,并说它激活了所选类的通道。这将激活它下面的子样本层中的某些通道,然后激活下面的要素层,依此类推,直到我们到达最后一个要素层。根据对卷积神经网络的了解,您应该认为最顶层将具有单个节点,但事实并非如此,这是RCN的优势之一,但是有关此主题的讨论不在本文讨论范围之内。最后一个要素层将是唯一的。记住,我谈论过RCN如何将形式与外观分开?正是这一层将负责获得所生成对象的形状。因此,该层应具有非常低级的功能,即任何形状的最基本的构建基块,这将有助于我们生成所需的形状。以不同角度旋转的小边框非常适合,该技术的作者正是使用它们。作者选择了最后一级的属性来表示一个3x3的窗口,该窗口的边界带有一定的旋转角度,他们将其称为补丁描述符。他们选择的旋转角度数为16。此外,为了以后可以添加外观,每次旋转都需要两个方向,以便能够辨别背景是在左侧还是右侧,如果这些是外部边框,以及内部边界(即对象内部)的附加方向。在图7中示出的最后一个层的特性组件,以及图8示出了补丁的描述符是如何可以产生一定的形状。
图6: GIF- RCN . , . , RCN , , . .到目前为止,我们讨论了RCN的中间层,只有最顶层和最底层与生成图像的像素进行交互。最顶层是常规要素层,其中每个节点的通道将成为我们标记的数据集的类。生成时,我们只需选择位置和要创建的类,然后转到具有指定位置的节点,并说它激活了所选类的通道。这将激活它下面的子样本层中的某些通道,然后激活下面的要素层,依此类推,直到我们到达最后一个要素层。根据对卷积神经网络的了解,您应该认为最顶层将具有单个节点,但事实并非如此,这是RCN的优势之一,但是有关此主题的讨论不在本文讨论范围之内。最后一个要素层将是唯一的。记住,我谈论过RCN如何将形式与外观分开?正是这一层将负责获得所生成对象的形状。因此,该层应具有非常低级的功能,即任何形状的最基本的构建基块,这将有助于我们生成所需的形状。以不同角度旋转的小边框非常适合,该技术的作者正是使用它们。作者选择了最后一级的属性来表示一个3x3的窗口,该窗口的边界带有一定的旋转角度,他们将其称为补丁描述符。他们选择的旋转角度数为16。此外,为了以后可以添加外观,每次旋转都需要两个方向,以便能够辨别背景是在左侧还是右侧,如果这些是外部边框,以及内部边界(即对象内部)的附加方向。在图7中示出的最后一个层的特性组件,以及图8示出了补丁的描述符是如何可以产生一定的形状。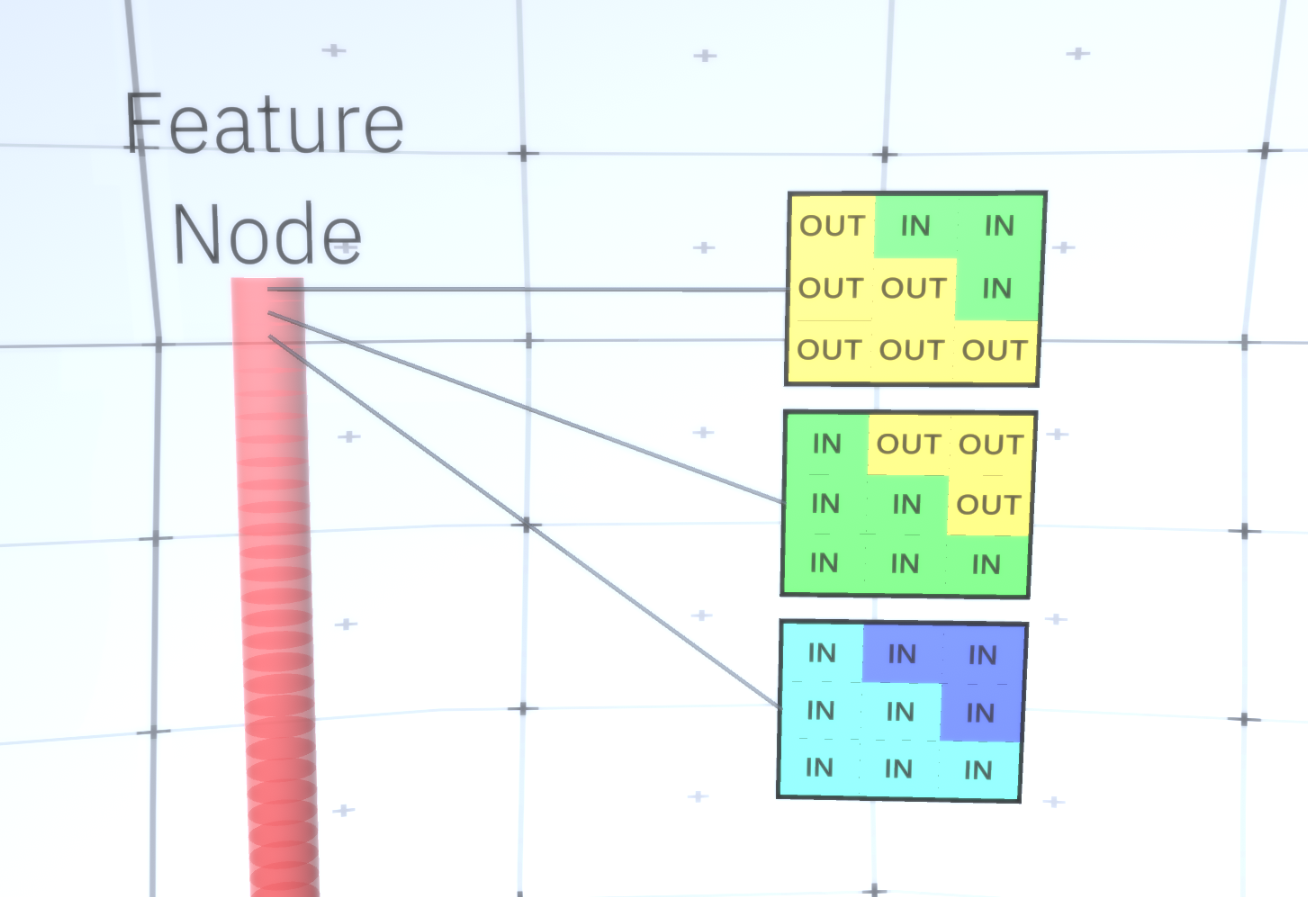 图7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — .
图7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — . 8: «i» .现在我们到达了标志的最后一层,我们有了一个图,在该图上可以确定对象的边界,并且对边界外部区域的了解是内部的还是外部的。剩下的就是添加外观,将图像中的每个剩余区域指定为IN或OUT,并在该区域上绘制。有条件的随机字段可能会有所帮助。在不涉及数学细节的情况下,我们只需按颜色和状态(IN或OUT)为最终图像中的每个像素分配概率分布即可。此分布将反映从地图边界获得的信息。例如,如果有两个相邻的像素,其中一个是IN,另一个是OUT,则它们具有不同颜色的可能性将大大增加。如果两个相邻像素位于内边界的相对两侧,则概率具有不同颜色的颜色也会增加。如果像素位于边界内并且没有被任何东西隔开,则它们具有相同颜色的可能性会增加,但是外部像素可能会彼此略有偏差,依此类推。要获得最终图像,只需从我们刚刚安装的联合概率分布中进行选择。为了使生成的图像更有趣,我们可以用纹理替换颜色。我们不会讨论这一层,因为RCN可以在不基于外观的情况下执行分类。要获得最终图像,只需从我们刚刚安装的联合概率分布中进行选择。为了使生成的图像更有趣,我们可以用纹理替换颜色。我们不会讨论这一层,因为RCN可以在不基于外观的情况下执行分类。要获得最终图像,只需从我们刚刚安装的联合概率分布中进行选择。为了使生成的图像更有趣,我们可以用纹理替换颜色。我们不会讨论这一层,因为RCN可以在不基于外观的情况下执行分类。好,今天我们就到这里结束。如果您想了解更多有关RCN的信息,请阅读本文[5]和附录以及其他材料,或者您可以阅读我的其他文章,以了解在各种数据集上使用RCN 的逻辑结论,训练和结果。
8: «i» .现在我们到达了标志的最后一层,我们有了一个图,在该图上可以确定对象的边界,并且对边界外部区域的了解是内部的还是外部的。剩下的就是添加外观,将图像中的每个剩余区域指定为IN或OUT,并在该区域上绘制。有条件的随机字段可能会有所帮助。在不涉及数学细节的情况下,我们只需按颜色和状态(IN或OUT)为最终图像中的每个像素分配概率分布即可。此分布将反映从地图边界获得的信息。例如,如果有两个相邻的像素,其中一个是IN,另一个是OUT,则它们具有不同颜色的可能性将大大增加。如果两个相邻像素位于内边界的相对两侧,则概率具有不同颜色的颜色也会增加。如果像素位于边界内并且没有被任何东西隔开,则它们具有相同颜色的可能性会增加,但是外部像素可能会彼此略有偏差,依此类推。要获得最终图像,只需从我们刚刚安装的联合概率分布中进行选择。为了使生成的图像更有趣,我们可以用纹理替换颜色。我们不会讨论这一层,因为RCN可以在不基于外观的情况下执行分类。要获得最终图像,只需从我们刚刚安装的联合概率分布中进行选择。为了使生成的图像更有趣,我们可以用纹理替换颜色。我们不会讨论这一层,因为RCN可以在不基于外观的情况下执行分类。要获得最终图像,只需从我们刚刚安装的联合概率分布中进行选择。为了使生成的图像更有趣,我们可以用纹理替换颜色。我们不会讨论这一层,因为RCN可以在不基于外观的情况下执行分类。好,今天我们就到这里结束。如果您想了解更多有关RCN的信息,请阅读本文[5]和附录以及其他材料,或者您可以阅读我的其他文章,以了解在各种数据集上使用RCN 的逻辑结论,训练和结果。资料来源:
- [1] R.Perrault,Y.Shoham,E.Brynjolfsson等人,斯坦福大学以人为中心的AI研究所的AI指数2019年度报告(2019)。
- [2] D. Hendrycks,K. Zhao,S.Basart等人,Natural Adversarial Examples(2019),arXiv:1907.07174。
- [3] Su J,D.Vasconcellos Vargas和S.Kouichi,愚弄深度神经网络的一次像素攻击(2017),arXiv:1710.08864。
- [4] M. Sharif,S。Bhagavatula,L。Bauer,《具有目标的对抗性例子的一般框架》(2017年),arXiv:1801.00349。
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
: « : ». Source: https://habr.com/ru/post/undefined/
All Articles