哈Ha我叫Misha Butrimov,我想谈谈Cassandra。我的故事对从未接触过NoSQL数据库的人很有用-它具有许多实现功能和您需要了解的陷阱。而且,如果除了Oracle或任何其他关系基础之外,您什么都没看过,那么这些事情将挽救您的生命。卡桑德拉(Cassandra)有什么好处?这是一个设计成无单点故障的NoSQL数据库,可以很好地扩展。如果您需要为任何基础添加几个TB,只需将节点添加到环中即可。扩展到另一个数据中心?将节点添加到集群。增加处理的RPS?将节点添加到集群。另一种方法也可以。 她还擅长什么?它要处理很多请求。但是多少是多少?每秒10、20、30、4万个请求-这不多。每秒也有10万个录制请求。有公司说他们每秒处理200万个请求。他们可能在这里必须相信。原则上,Cassandra与关系数据有很大的不同-它看起来根本不像它们。要记住这一点非常重要。
她还擅长什么?它要处理很多请求。但是多少是多少?每秒10、20、30、4万个请求-这不多。每秒也有10万个录制请求。有公司说他们每秒处理200万个请求。他们可能在这里必须相信。原则上,Cassandra与关系数据有很大的不同-它看起来根本不像它们。要记住这一点非常重要。并非所有看起来相同的东西都一样
一位同事来找我问:“这是CQL Cassandra查询语言,它有一个select语句,它在何处,它具有and。我写信,但没有用。为什么?”。如果将Cassandra视为关系数据库,那么这是通过残酷的自杀来结束生命的理想方式。而且我不主张,这在俄罗斯是被禁止的。您只是在设计错误。例如,有一位客户来找我们说:“让我们建立一个电视节目数据库,或一个食谱目录数据库。我们将在那里准备美食,或者在其中列出一系列的剧集和演员。”我们高兴地说:“加油!”。这是要发送的两个字节,几个板,一切就绪,一切将非常快速,可靠地工作。一切都很好,直到客户说主妇也正在解决相反的问题:他们有产品清单,并且想知道自己想煮什么菜。你死了。这是因为Cassandra是一个混合数据库:它既是键值,又将数据存储在宽列中。用Java或Kotlin讲,可以这样描述:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>即,在其中还存在排序的地图的地图。该映射的第一个键是行键或分区键-分区键。第二个键是聚类键,它是已排序映射的键。为了说明数据库的分布,我们绘制了三个节点。现在,您需要了解如何将数据分解为节点。因为如果我们将所有内容都归为一类(顺便说一句,可能是一千,两千,五-随便你多),这实际上与发行无关。因此,我们需要一个可以返回数字的数学函数。只是一个数字,一个长整数将落入某个范围。我们有一个节点负责一个范围,第二个节点负责第二个范围,第n个负责第n个范围。 该数字是使用哈希函数获取的,该哈希函数仅适用于我们所谓的分区键。这是在主键指令中指定的列,并且这是将成为第一个也是最基本的映射键的列。它确定哪个节点获取哪个数据。在Cassandra中创建的表的语法几乎与SQL中的语法相同:
该数字是使用哈希函数获取的,该哈希函数仅适用于我们所谓的分区键。这是在主键指令中指定的列,并且这是将成为第一个也是最基本的映射键的列。它确定哪个节点获取哪个数据。在Cassandra中创建的表的语法几乎与SQL中的语法相同:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
在这种情况下,主键由一列组成,并且它也是一个分区键。用户将如何喜欢我们?一部分会落在一个音符上,一部分会落在另一个音符上,另一半会落在三分之一上。事实证明,它是一个普通的哈希表,它也是一个映射,它也是Python中的字典,它还是一个简单的Key值结构,从中我们可以读取所有值,并通过key进行读写。
选择:何时允许过滤变为完全扫描,或不执行该操作
让我们写一些语句中的选择:select * from users where, userid = 。事实证明,就像在Oracle中一样:我们编写select,指定条件,一切正常,用户得到它。但是,例如,如果您选择某个具有特定出生年份的用户,则Cassandra发誓她无法满足该请求。因为她对我们如何分配出生年份的数据一无所知-她只指定了一个列作为键。然后她说:“好的,我仍然可以满足这个要求。添加允许过滤。”我们添加了一条指令,一切正常。在那一刻,发生了一件可怕的事情。当我们使用测试数据时,一切都很好。而当您满足生产要求时(例如,我们有400万条记录),那么对我们来说一切都不好。因为允许过滤是一条指令,它允许Cassandra从所有节点,所有数据中心(如果此群集中有很多数据中心)从该表收集所有数据,然后才对其进行过滤。这是全扫描的模拟,几乎没有人对此感到满意。如果我们只需要标识符用户,那么这将适合我们。但是有时我们需要编写其他查询并对选择施加其他限制。因此,我们回想一下:我们都有一个映射,该映射具有一个分区键,但是在其内部是一个排序的映射。她还有一个密钥,我们称它为集群密钥。该密钥又由我们选择的列组成,Cassandra通过该列了解如何对她的数据进行物理排序并将其放置在每个节点上。也就是说,对于某些“分区”键,“群集”键将确切告诉您如何将数据推送到该树中,它们将放置在何处。这是一棵真正的树,在这里简单地称为一个比较器,以对象的形式将一组特定的列传递到该比较器中,并且还以列的枚举形式对其进行设置。CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
注意主键指令,它的第一个参数(在我们的例子中是年份)始终是分区键。它可以由一列或几列组成,没关系。如果有几列,则需要再次用括号将其删除,以便语言预处理器可以理解这是主键,而在其后的所有其他列是“聚簇”键。在这种情况下,它们将按照进行的顺序在比较器中发送。也就是说,第一列的重要性更高,第二列的重要性更低,依此类推。例如,当我们为数据类编写时,等于字段:我们列出字段,并为它们编写哪些更大,哪些更小。在Cassandra中,相对而言,这是将应用等于的数据类字段。我们设置排序,施加限制
必须记住,排序顺序(降序,递增,无关紧要)是在创建键的同时设置的,之后便无法更改。它从物理上确定如何对数据进行排序以及如何定位。如果您需要更改聚簇键或排序顺序,则必须创建一个新表并将数据倒入其中。对于现有的服务器,这将无法正常工作。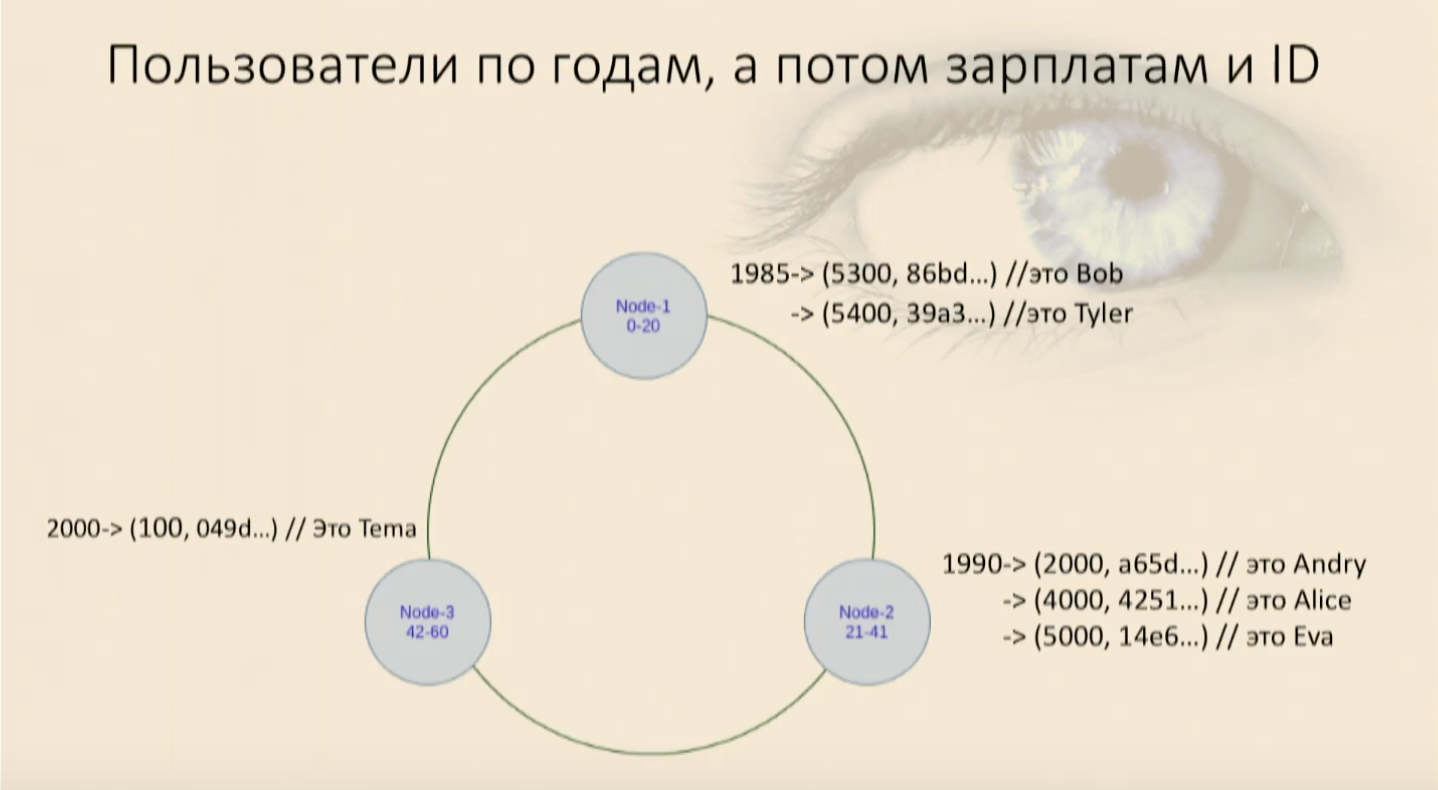 我们在表中填充了用户,然后看到他们陷入了麻烦,首先是按出生年份,然后是按工资和用户ID在每个节点上。现在我们可以选择,施加限制。我们的工作再次出现
我们在表中填充了用户,然后看到他们陷入了麻烦,首先是按出生年份,然后是按工资和用户ID在每个节点上。现在我们可以选择,施加限制。我们的工作再次出现where, and,然后用户找到我们,一切都很好。但是,如果我们尝试仅使用“聚类”关键部分,而不是重要部分,那么Cassandra将立即发誓,我们在地图中找不到该对象具有用于比较器null的这些字段的字段,但该字段刚刚设置-它在哪里。我将不得不再次从该节点拾取所有数据并进行过滤。而且这类似于节点内的完全扫描,这很糟糕。在任何无法理解的情况下,创建一个新表
如果我们希望能够通过ID,年龄或薪水获得用户,该怎么办?没有。只需使用两个表。如果您需要以三种不同的方式吸引用户-将有三个表。节省螺丝钉空间的日子已经一去不复返了。这是最便宜的资源。它花费的时间远远少于响应时间,这对用户可能是致命的。与10分钟之内相比,用户在一秒钟之内得到的东西要好得多。我们交换了过多的空间,非规范化的数据,以实现良好的扩展能力,可靠地工作。实际上,实际上,由三个数据中心组成的集群(每个集群有五个节点)具有可接受的数据存储级别(肯定不会丢失任何数据),该集群能够完全幸免一个数据中心的崩溃。在剩下的两个中,每个都有两个以上的节点。而且只有在那之后问题才开始。这是一个相当不错的冗余,它花费了一些不必要的ssd驱动器和处理器。因此,为了使用Cassandra(永远不会使用SQL),没有关系,没有外键,您需要了解简单的规则。我们根据要求设计一切。最主要的不是数据,而是应用程序将如何使用它们。如果他需要以不同的方式接收不同的数据或以不同的方式接收相同的数据,我们必须以一种方便应用程序的方式来放置它们。否则,我们将无法进行全面扫描,而Cassandra不会给我们带来任何优势。规范化数据是常态。忘了普通形式,我们不再有关系数据库。我们放东西100次,它会撒谎100次。比停止它便宜。我们选择要分区的键,以便它们可以正态分布。我们不需要密钥中的哈希值落入一个狭窄的范围。也就是说,上面示例中的出生年份是一个不好的示例。相反,如果我们的用户按出生年份正常分布是一件好事,而如果我们谈论的是5年级的学生,那是不好的-在那儿划分不是很好。在创建聚类键期间选择一次排序。如果您需要更改它,那么您将不得不用另一个键来填充我们的表。最重要的是:如果我们需要以100种不同的方式收集相同的数据,那么我们将有100种不同的表。