大家好!我想谈谈一个非常无聊的项目,其中机器人技术,机器学习(以下统称为机器人学习),虚拟现实和一些云技术相交。所有这些实际上都是有道理的。毕竟,移入机器人,演示操作并使用存储的数据在ML服务器上训练权重确实非常方便。在削减之后,我们将说明它现在如何工作,以及必须开发的各个方面的一些细节。
做什么的
对于初学者来说,值得一试。似乎配备了深度学习的机器人即将将人们从各地辞退。实际上,一切都不那么顺利。在严格重复执行动作的地方,流程已经真正实现了自动化。如果我们谈论的是“智能机器人”,那就是计算机视觉和算法已经足够的应用程序。但是,还有许多极其复杂的故事。机器人几乎无法应对各种必须处理的物体以及环境的多样性。关键点
在实现方面存在3项关键的东西,但到处都找不到:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
第二点也很重要,因为现在我们将观察到学习方法,算法,方法和计算工具的变化。感知和控制算法将变得更加灵活。机器人升级要花钱。如果一次为多个机器人提供服务,计算器将得到更有效的利用。这个概念称为“云机器人”。对于后者,一切都很简单-AI尚未得到充分开发,无法在业务所需的所有情况下提供100%的可靠性和准确性。因此,有时可以帮助守卫机器人的监督员操作人员不会受伤。方案
首先,介绍一个提供所有上述功能的软件/网络平台: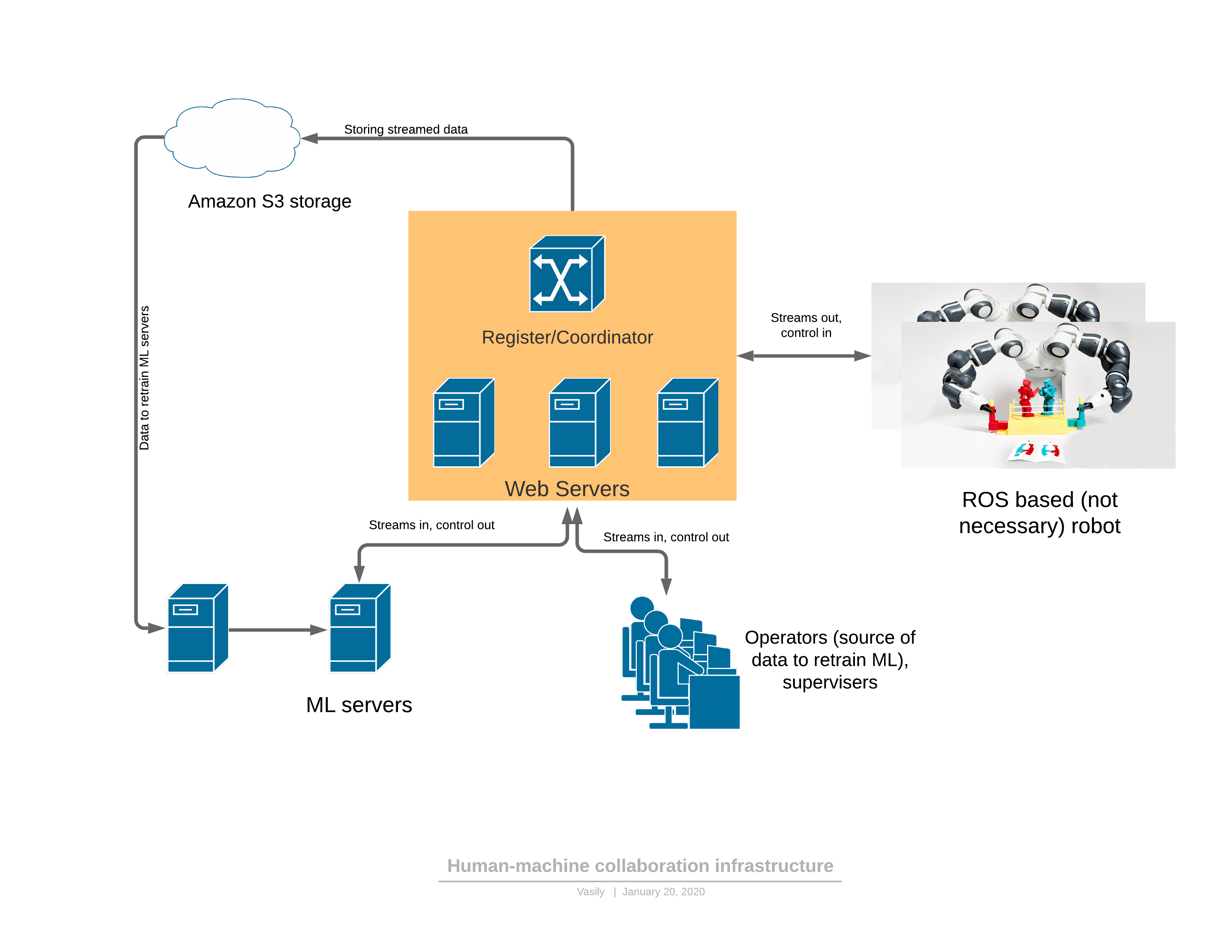 组件:
组件:- 机器人将3D视频流发送到服务器,并作为响应接收控制。
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
机器人有两种功能模式:自动和手动。在手动模式下,如果尚未训练ML服务,则机器人可以工作。然后,根据操作员的请求(我在观看机器人时看到了奇怪的行为),或者当ML服务本身检测到异常时,机器人从自动变为手动。关于异常的检测将在稍后-这是非常重要的部分,没有它,就不可能应用所提出的方法。控制的演变如下:- 机器人的任务以人类可读的形式形成,并描述了性能指标。
- 操作员连接到VR中的机器人并在现有工作流程中执行任务一段时间
- 机器学习零件在接收到的数据上进行训练
- , ML
3D
机器人通常会使用ROS(机器人操作系统)环境,该环境实际上是用于管理“节点”(节点)的框架,每个节点都提供了机器人功能的一部分。通常,这是对机器人进行编程的相对方便的方法,在某种程度上,其本质上类似于Web应用程序的微服务体系结构。 ROS的主要优点是行业标准,创建机器人已经需要大量模块。甚至工业机械手也可以具有ROS接口模块。最简单的事情是在服务器部分和ROS之间创建一个桥接模型。例如,这样。现在,我们的项目使用了更先进的ROS“节点”版本,该版本登录并轮询特定机械手可以连接到中继服务器的寄存器的微服务。给出的源代码仅作为安装ROS模块的说明示例。刚开始,当您掌握此框架(ROS)时,一切看起来都不太友好,但是文档非常好,几周后,开发人员就开始非常自信地使用其功能。有趣的是-3D数据流的压缩问题,必须直接在机器人上生成。压缩深度图不是那么容易。即使在对RGB流进行较小程度的压缩的情况下,也仍然允许边界或移动物体时像素中的真实值造成非常严重的局部亮度失真。眼睛几乎没有注意到这一点,但是在深度图中允许相同的扭曲时,渲染3D时,一切都会变得非常糟糕:( 来自本文)边缘的这些缺陷极大地破坏了3D场景,因为 空气中只有很多垃圾。我们开始使用逐帧压缩-JPEG用于RGB,PNG用于深度地图,并具有一些小技巧。此方法以25 Mbps的速度为640x480的3D扫描仪压缩30FPS流。如果流量对应用程序至关重要,则还可以提供更好的压缩。有商用3D流编解码器,也可用于压缩此流。
来自本文)边缘的这些缺陷极大地破坏了3D场景,因为 空气中只有很多垃圾。我们开始使用逐帧压缩-JPEG用于RGB,PNG用于深度地图,并具有一些小技巧。此方法以25 Mbps的速度为640x480的3D扫描仪压缩30FPS流。如果流量对应用程序至关重要,则还可以提供更好的压缩。有商用3D流编解码器,也可用于压缩此流。虚拟现实控制
在我们校准了相机和机器人的参考系之后(并且我们已经写了一篇有关校准的文章),可以在虚拟现实中控制机器人的手臂。控制器同时设置3D XYZ中的位置和方向。对于某些roboruk,仅3个坐标就足够了,但是在具有大量自由度的情况下,还必须传输控制器指定的刀具方向。此外,控制器上有足够的控件来执行机器人命令,例如打开/关闭泵,控制夹持器等。最初,决定基于WebVR引擎将JavaScript框架用于虚拟现实A框架。并在A框架上获得了第一个结果(本文末尾的四坐标臂视频演示)。实际上,事实证明WebVR(或A帧)是不成功的解决方案,原因有以下几个:- 兼容性主要与FireFox兼容,并且在FireFox中,直到内存消耗达到16GB时,A框架框架才释放纹理资源(其余浏览器可用)
- 与VR控制器和头盔的互动受限。因此,例如,不可能添加其他标记来设置操作员的肘部位置。
- 该应用程序需要多线程或多个进程。在一个线程/进程中,有必要拆开视频帧的包装,在另一个进程中-绘制。结果,一切都是通过工人来组织的,但是解包时间达到了30毫秒,在VR中的渲染应该以90FPS的频率进行。
所有这些缺点导致以下事实:帧的渲染在分配的10ms内没有时间,并且VR中存在非常令人不快的抽搐。可能可以克服所有问题,但是每个浏览器的身份都令人讨厌。现在,我们决定离开OpenVR库的C#,OpenTK和C#端口。还有另一种选择-Unity。他们写道Unity是适合初学者的,但是很困难。为了获得自由而必须找到并知道的最重要的事情是:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(这是用于向头盔的左眼和右眼发送两个纹理的代码),即 在不同的眼睛看到的纹理中绘制OpenGL,然后将其发送到眼镜。事实证明,Joy没有界限,它用红色填充了左眼,用蓝色填充了右眼。仅仅几天,现在通过webSocket传入的深度和RGB贴图在10ms内转移到了多边形模型,而不是JS上的30ms。然后只需询问控制器的坐标和按钮,输入按钮的事件系统,处理用户的单击,输入UI的状态机,现在就可以从浓缩咖啡中抢一杯了:现在,Realsense D435的质量有些令人沮丧,但只要我们至少安装了Microsoft这样有趣的3D扫描仪,它的点云就会更加准确,它就会通过。服务器端
中继服务器主要功能元素是服务器中继(中间的服务器),它从机器人接收具有3D图像和传感器读数以及机器人状态的视频流,并将其分配给消费者。输入数据-通过TCP / IP打包的帧和传感器读数。通过网络套接字(分发给消费者,包括浏览器的一种非常方便的机制)来分发给消费者。此外,登台服务器将数据流存储在S3云存储中,以便以后可以用于训练。每个中继服务器均支持http API,该API可让您查找其当前状态,从而便于监视当前连接。从计算的角度和从流量的角度来看,中继任务都非常困难。因此,这里我们遵循了将中继服务器部署在各种云服务器上的逻辑。这意味着您需要跟踪谁在哪里连接(尤其是如果机器人和操作员位于不同的区域)注册现在很难为每个机器人设置可以连接的服务器(冗余不会造成伤害)。 ML管理服务与该机器人相关联,它会轮询中继服务器以确定该机器人连接到哪个机器人并连接到相应的机器人,如果它当然对此具有足够的权限。运营商的应用程序以类似的方式工作。最愉快的!由于机器人培训是一项服务,因此该服务仅对我们内部可见。因此,它的前端可能对我们来说尽可能方便!那些。它是浏览器中的控制台(有一个terminalJS库,它的简洁性很漂亮,如果您需要其他功能(例如TAB自动完成或播放呼叫历史记录,则很容易修改),看起来像这样: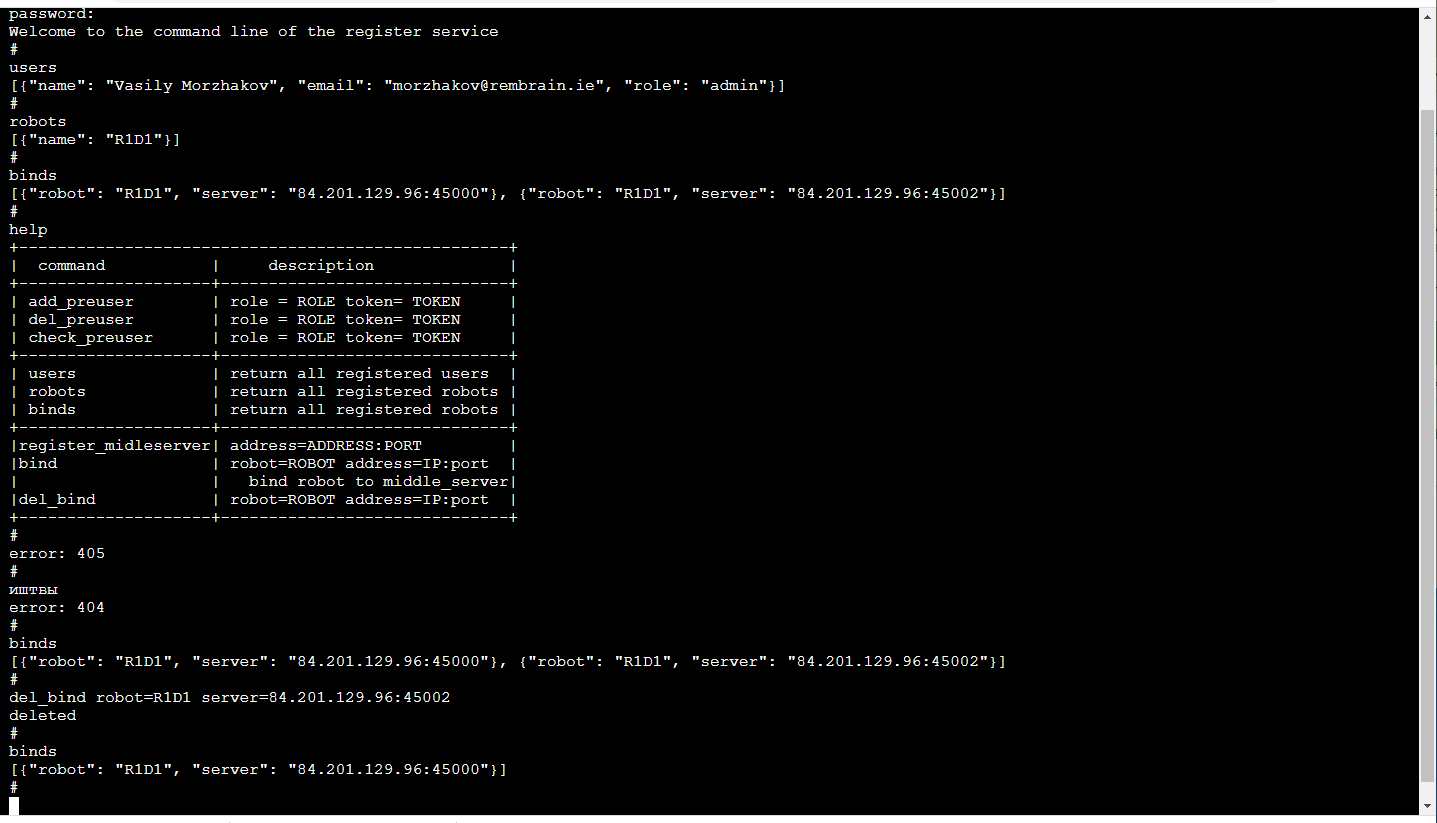 这当然是一个单独的讨论主题,为什么使用命令行好舒服顺便说一下,对这样的前端进行单元测试特别方便。除了http API之外,此服务还实现了一种机制,用于使用临时令牌,登录/注销操作员,管理员和机械手,会话支持以及用于中继服务器和机械手之间的流量加密的会话加密密钥来注册用户。所有这些都是通过Flask在Python中完成的-对于ML开发人员(即我们)而言,这是一个非常紧密的堆栈。是的,此外,现有的微服务CI / CD基础设施与Flask保持友好关系。
这当然是一个单独的讨论主题,为什么使用命令行好舒服顺便说一下,对这样的前端进行单元测试特别方便。除了http API之外,此服务还实现了一种机制,用于使用临时令牌,登录/注销操作员,管理员和机械手,会话支持以及用于中继服务器和机械手之间的流量加密的会话加密密钥来注册用户。所有这些都是通过Flask在Python中完成的-对于ML开发人员(即我们)而言,这是一个非常紧密的堆栈。是的,此外,现有的微服务CI / CD基础设施与Flask保持友好关系。延误问题
如果我们要实时控制操纵器,则最小延迟非常有用。如果延迟变得太大(超过300毫秒),则很难根据虚拟头盔中的图像来控制操纵器。在我们的解决方案中,由于逐帧压缩(即没有缓冲)并且未使用GStreamer之类的标准工具,因此即使将中间服务器考虑在内,延迟也约为150-200毫秒。它们在网络上的传输时间约为80毫秒。其余的延迟是由Realsense D435摄像机和有限的捕获频率引起的。当然,这是在“跟踪”模式下出现的全高问题,当操作员在现实中不断跟随虚拟现实中的操作员的控制器时。在移动到给定点XYZ的模式下,延迟不会对操作员造成任何问题。ML部分
服务分为2种:管理和培训。训练服务收集存储在S3存储中的数据,并开始对模型权重的重新训练。培训结束时,权重将发送到管理服务。管理服务在操作员应用程序的输入和输出数据方面没有什么不同。同样,输入RGBD(RGB +深度)流,传感器读数和机械手状态,输出-控制命令。由于这种身份,似乎有可能在“数据驱动培训”概念的框架内进行培训。机器人的状态(和传感器读数)是ML的关键故事。它定义了上下文。例如,机器人将具有状态机,该状态机是其操作的特征,它在很大程度上决定了需要哪种控制。这2个值随每个帧一起传输:机器人的操作模式和状态向量。关于培训的一些知识:在文章末尾的演示中,我们的任务是在3D场景中找到一个对象(一个儿童立方体)。这是拾取和放置应用程序的基本任务。训练基于一对“前后”帧和通过手动控制获得的目标指定: 由于存在两个深度图,因此很容易计算帧中移动对象的遮罩:
由于存在两个深度图,因此很容易计算帧中移动对象的遮罩: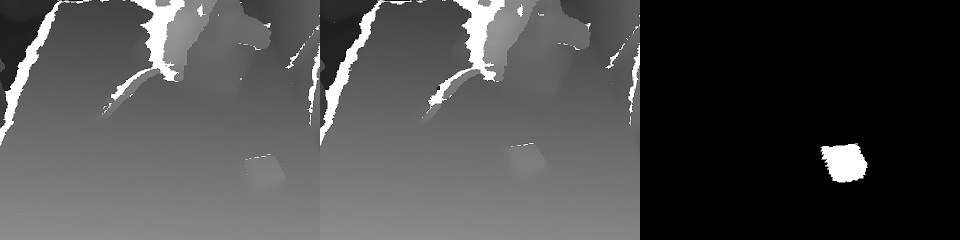 此外,xyz投影到摄像机平面上,您可以选择捕获对象的邻域:
此外,xyz投影到摄像机平面上,您可以选择捕获对象的邻域: 实际上与这个邻里并会工作。首先,我们通过训练卷积网络Unet进行多维数据集分割来获得XY。然后,我们需要确定深度并了解我们面前的图像是否异常。这是通过使用RGB自动编码器和有条件的深度自动编码器完成的。用于训练自动编码器的模型架构:
实际上与这个邻里并会工作。首先,我们通过训练卷积网络Unet进行多维数据集分割来获得XY。然后,我们需要确定深度并了解我们面前的图像是否异常。这是通过使用RGB自动编码器和有条件的深度自动编码器完成的。用于训练自动编码器的模型架构: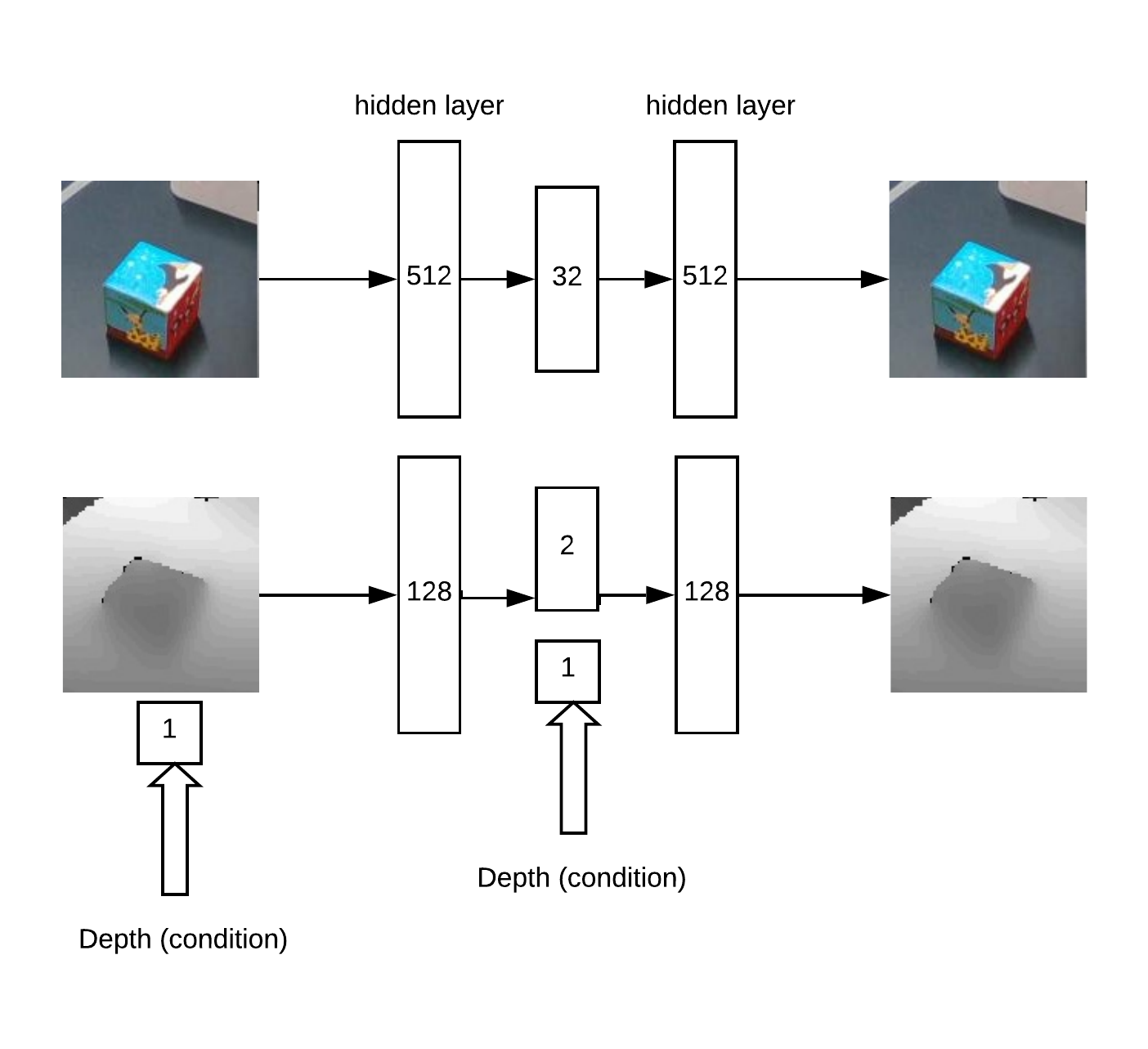 结果,工作逻辑:
结果,工作逻辑:- 在“热图”上搜索超过阈值的最大值(确定对象的角度u = x / zv = y / z坐标)
- 然后,自动编码器针对所有深度假设(从min_depth到max_depth的给定步骤)重建找到的点的邻域,并选择最小的深度,在该深度处重建和输入之间的差异最小
- 有了角坐标u,v和深度,您可以获得坐标x,y,z
具有正确定义的深度的立方体深度图的自动编码器重构示例: 部分而言,深度搜索方法的思想是基于有关自动编码器集的文章。这种方法适用于各种形状的对象。但是,通常,有很多不同的方法可以从RGBD图像中找到XYZ对象。当然,在实践中和大量数据上必须选择最准确的方法。还有一个检测异常的任务,为此,我们需要一个分段卷积网络以从可用的掩码中学习。然后,根据该遮罩,您可以在深度图和RGB中评估自动编码器重构的准确性。由于存在这种差异,因此可以确定是否存在异常。由于这种方法,有可能检测帧中先前未见对象的出现,但这些对象仍被主要搜索算法检测到。
部分而言,深度搜索方法的思想是基于有关自动编码器集的文章。这种方法适用于各种形状的对象。但是,通常,有很多不同的方法可以从RGBD图像中找到XYZ对象。当然,在实践中和大量数据上必须选择最准确的方法。还有一个检测异常的任务,为此,我们需要一个分段卷积网络以从可用的掩码中学习。然后,根据该遮罩,您可以在深度图和RGB中评估自动编码器重构的准确性。由于存在这种差异,因此可以确定是否存在异常。由于这种方法,有可能检测帧中先前未见对象的出现,但这些对象仍被主要搜索算法检测到。示范
在展台上对整个创建的软件平台进行检查和调试:- 3D相机Realsense D435
- 4个坐标的Dobot魔术师
- VR头盔HTC Vive
- Yandex Cloud上的服务器(与AWS云相比,减少了延迟)
在视频中,我们教了如何通过在VR拾取和放置中执行任务来在3D场景中找到立方体。大约50个示例足以在多维数据集上进行训练。然后对象发生变化,并显示了另外30个示例。重新训练后,机器人可以找到新对象。整个过程大约需要15分钟,其中大约一半是训练模型的权重。在此视频中,YuMi在VR中进行控制。要学习如何操作对象,您需要评估工具的方向和位置。数学是基于类似的原理构建的,但目前处于测试和开发阶段。结论
大数据和深度学习还不是全部。我们正在改变学习的方式,通过重复他们看到的东西,向人们学习新事物的方向发展。我们将在实际应用中开发的“幕后”数学设备旨在解决上下文相关的解释和控制问题。这里的上下文是可从机器人传感器获得的自然信息或有关当前过程的外部信息。而且,我们掌握的技术流程越多,“云端的大脑”的结构就将得到开发,并且其各个部分将得到培训。这种方法的优点:- 学习如何操作可变对象的可能性
- 在不断变化的环境中学习(例如,移动机器人)
- 结构不良的任务
- 上市时间短;您甚至可以使用操作员在手动模式下执行目标
局限性:- 需要可靠和良好的互联网
- 需要其他方法来实现高精度,例如,机械手本身中的摄像头
我们目前正在将我们的方法应用于各种物体的标准拾取和放置任务。但是在我们看来(自然!)他有能力做更多。有其他想法可以尝试吗?感谢您的关注!