在上一篇文章中,我们研究了注意力机制,这是现代深度学习模型中一种极为常见的方法,可以改善神经机器翻译应用程序的性能指标。在本文中,我们将介绍Transformer,该模型使用注意力机制来提高学习速度。此外,在许多任务上,变形金刚优于Google的神经机器翻译模型。但是,变压器的最大优点是在并行化条件下具有很高的效率。甚至Google Cloud也建议在Cloud TPU上使用Transformer作为模型。让我们尝试找出模型的组成及其执行的功能。
“ 注意就是您所需要的”一文中首先提出了Transformer模型。Tensor2Tensor软件包中包含TensorFlow的实现,此外,来自哈佛大学的一组NLP研究人员使用PyTorch的实现创建了本文的指南注释。在同一指南中,我们将尝试以最简单,一致的方式概述主要思想和概念,以帮助那些对主题领域没有深入了解的人们理解该模型。
高层审查
让我们将模型视为一种黑匣子。在机器翻译应用程序中,它接受一种语言的句子作为输入,并显示另一种语言的句子。

, , , .
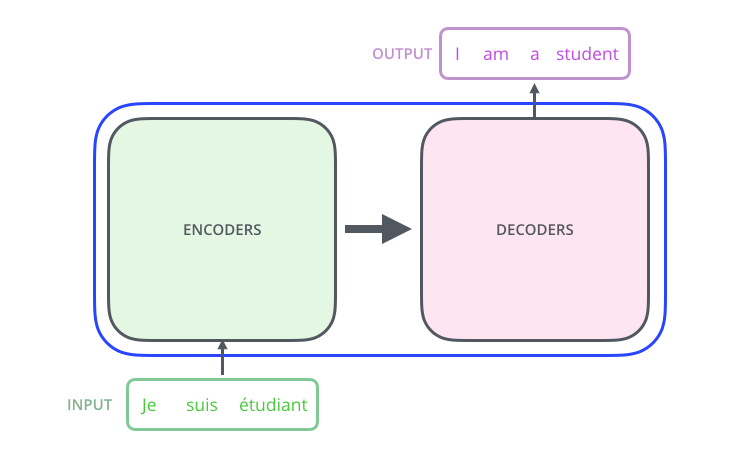
– ; 6 , ( 6 , ). – , .
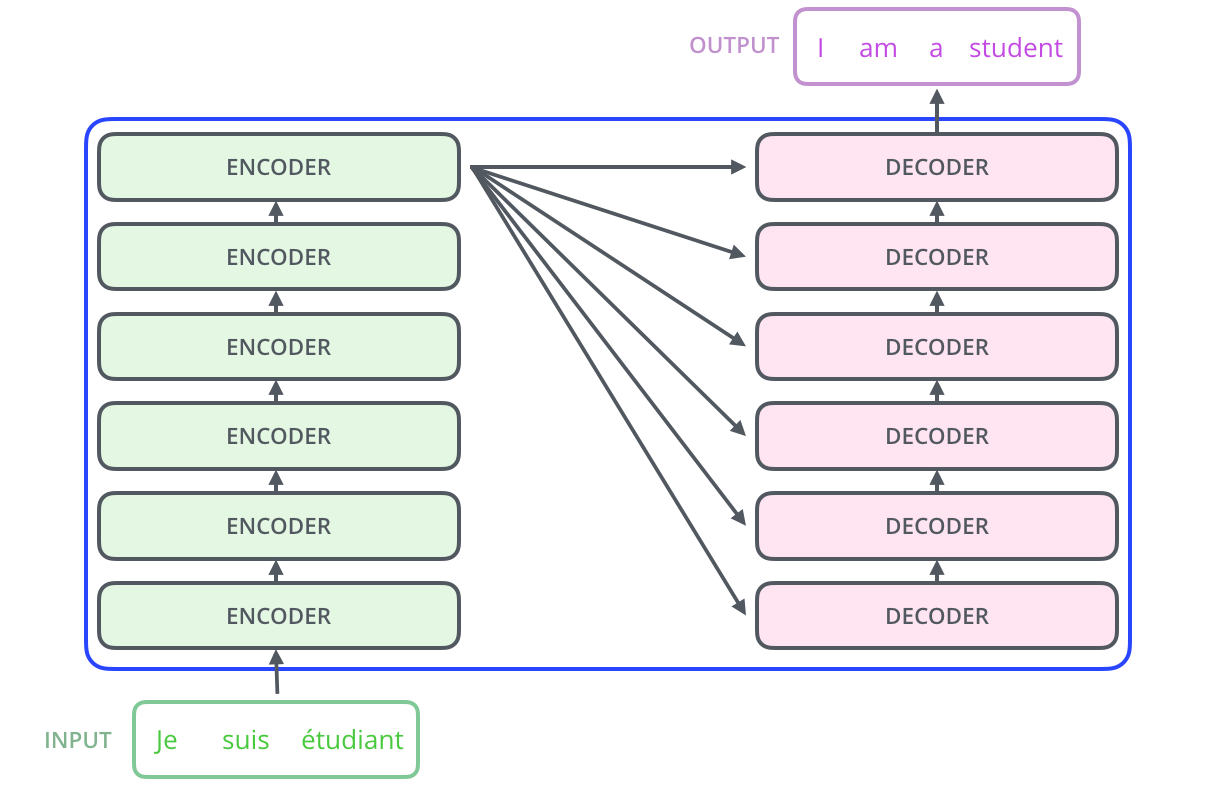
, . :
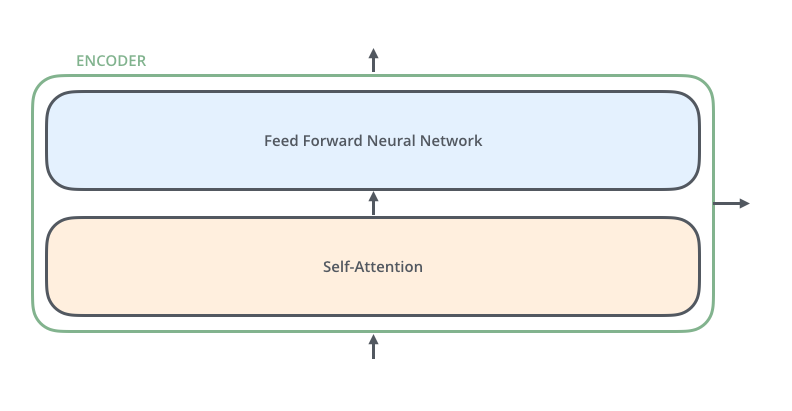
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
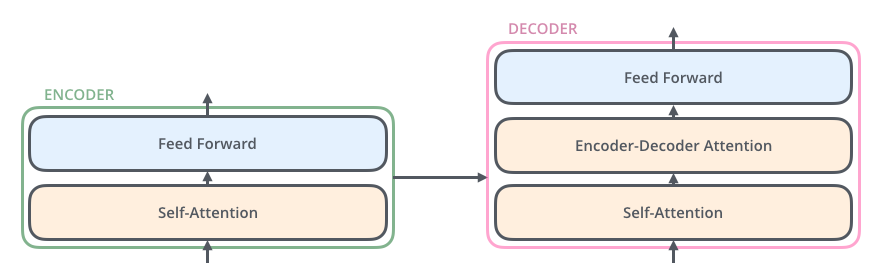
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
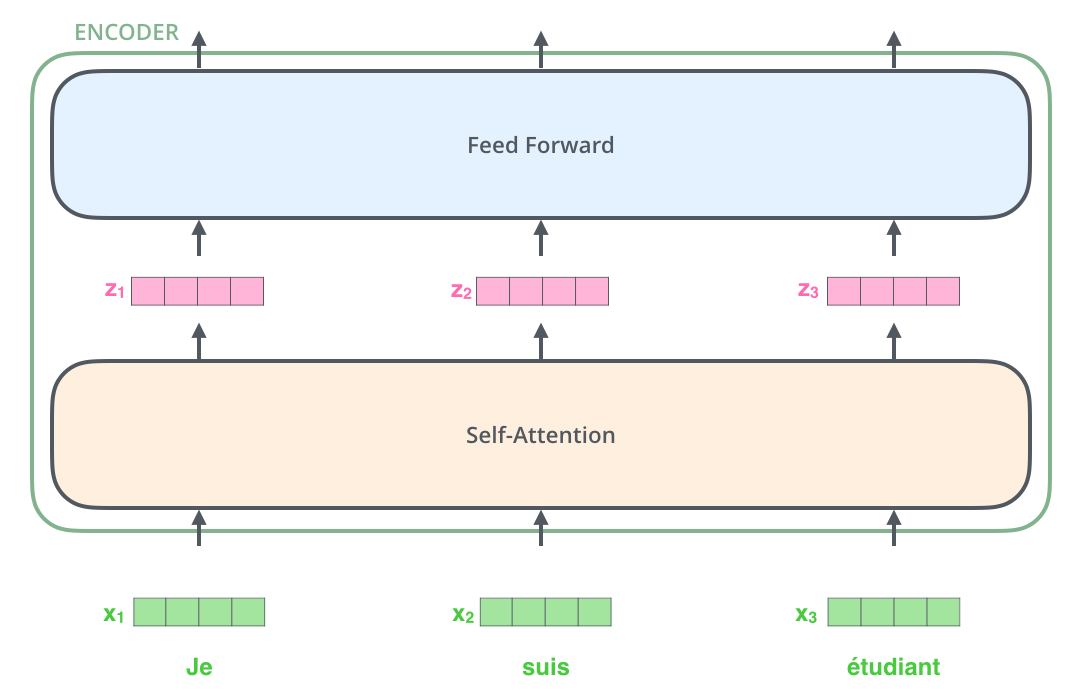
: . , , , .
, .
!
, , – , , , .
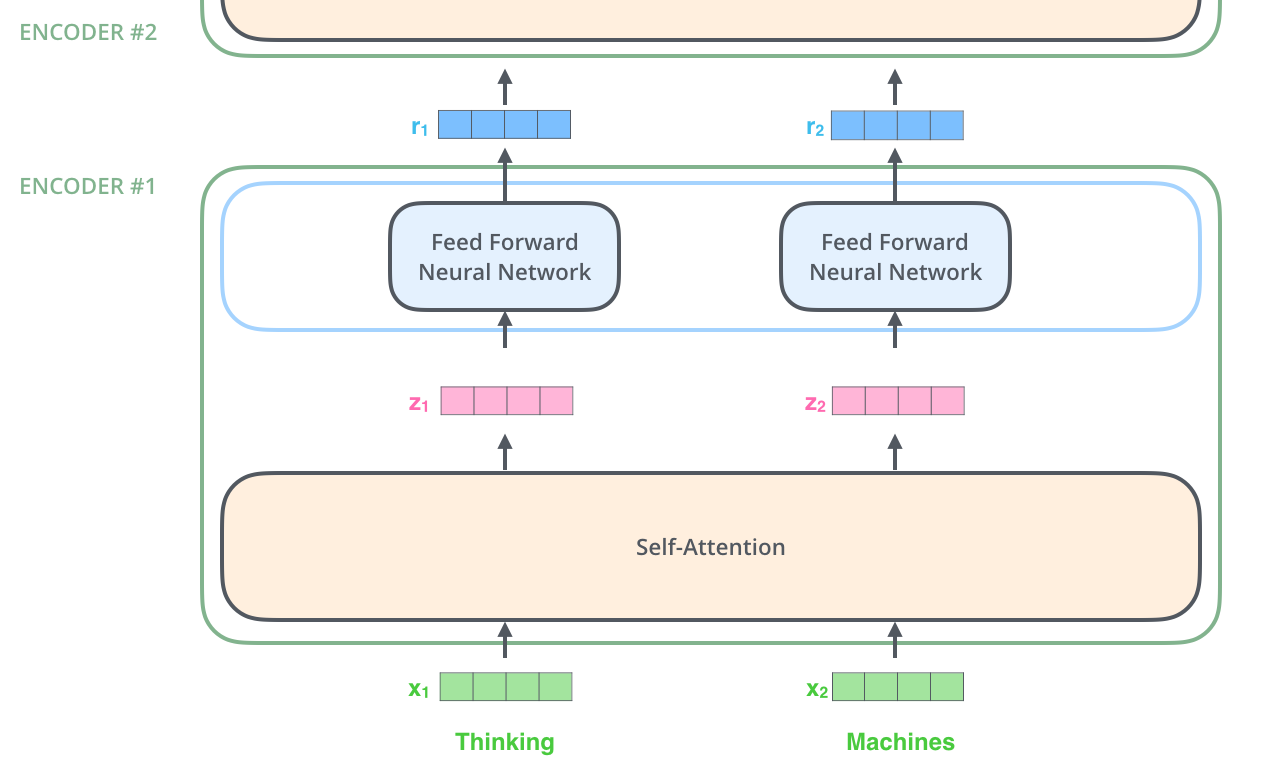
. , .
, « » -, . , «Attention is All You Need». , .
– , :
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
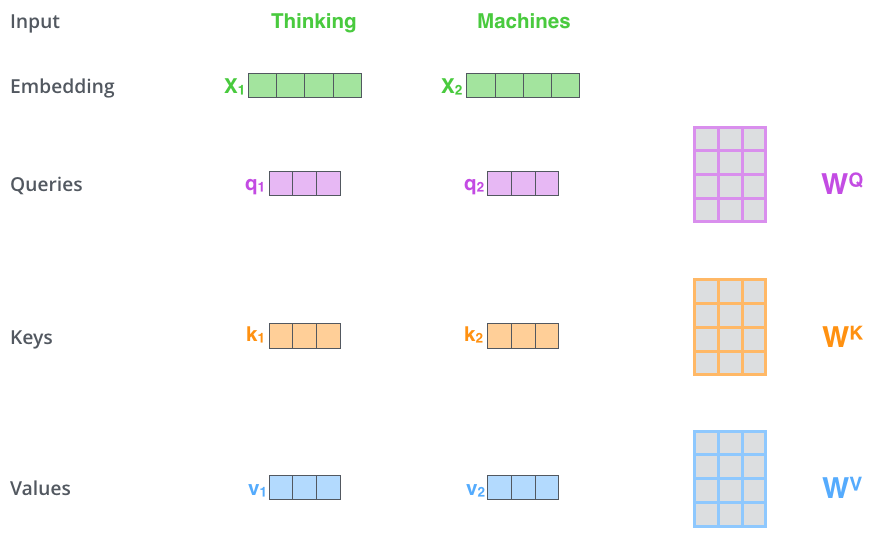
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
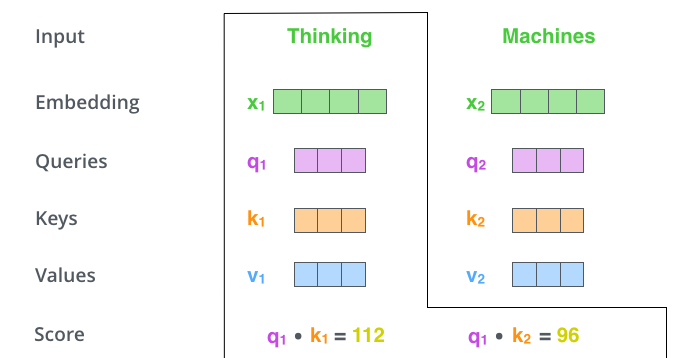
– 8 ( , – 64; , ), (softmax). , 1.
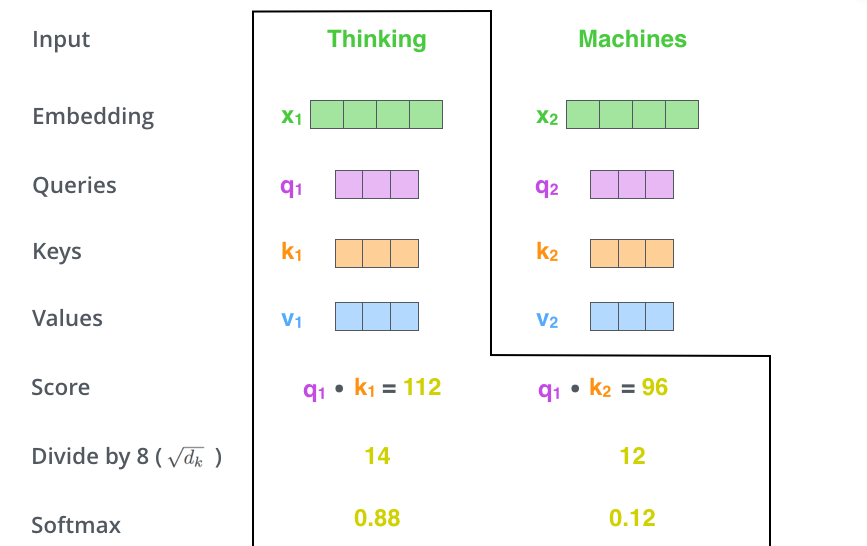
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
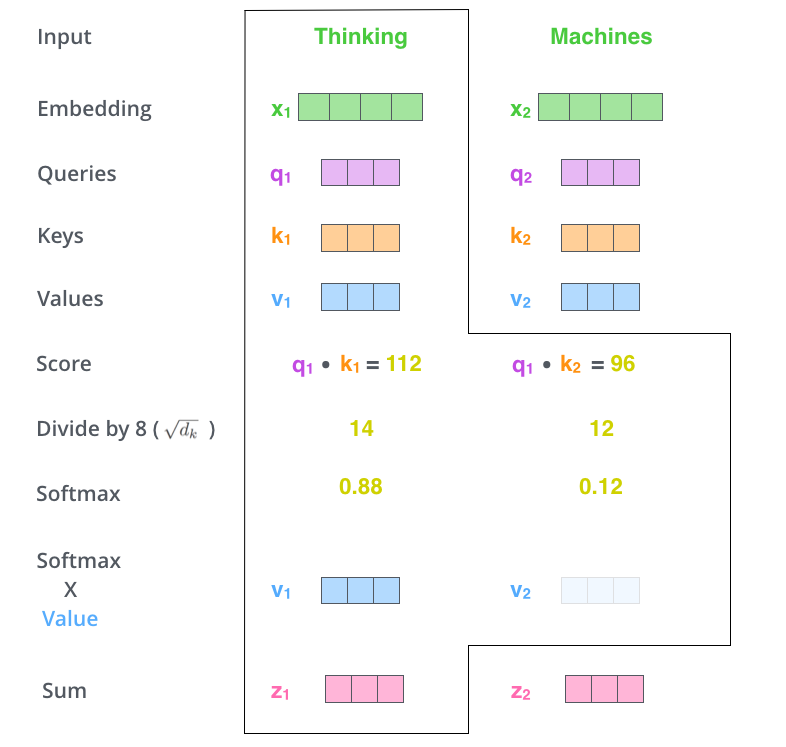
. , . , , . , , .
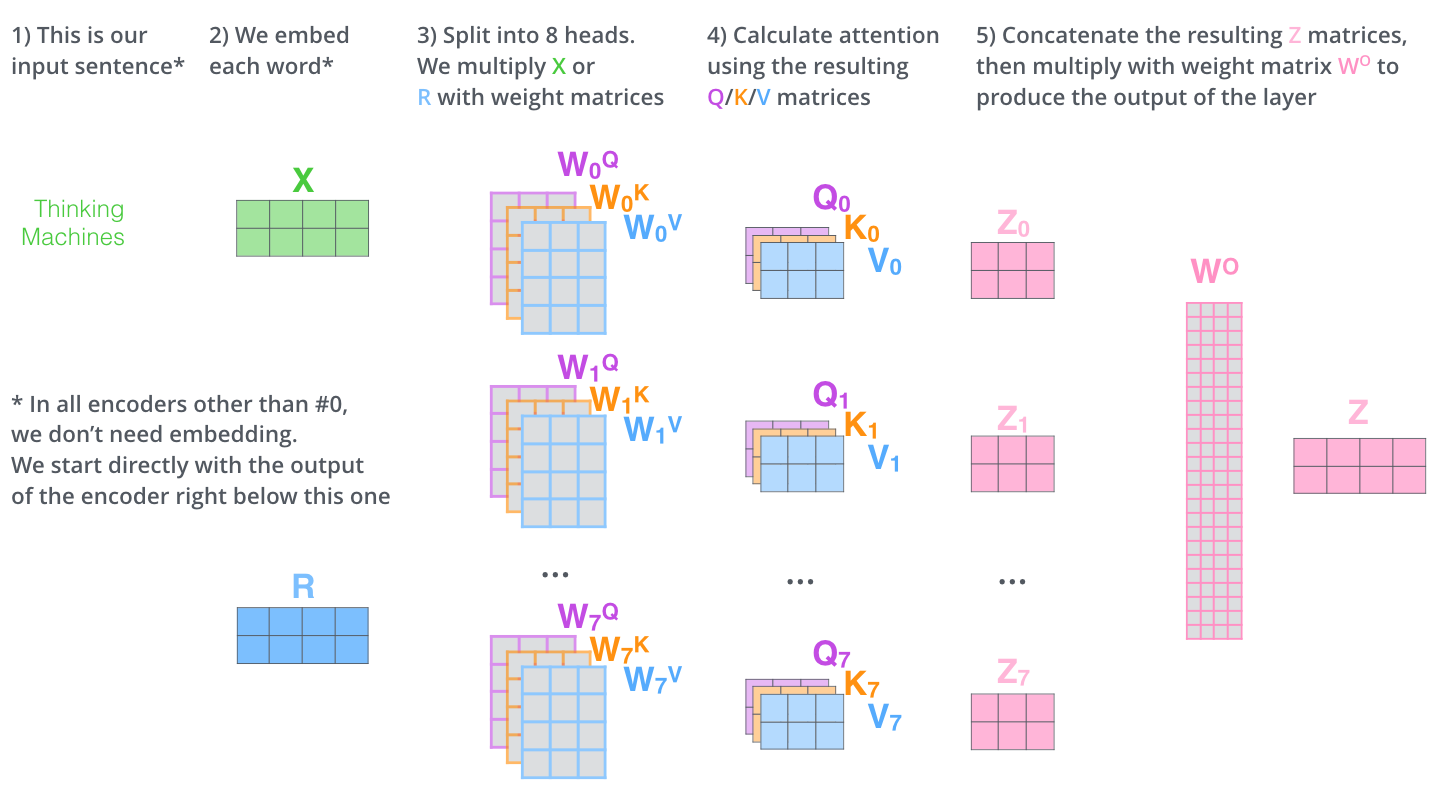
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
, , 2-6 .
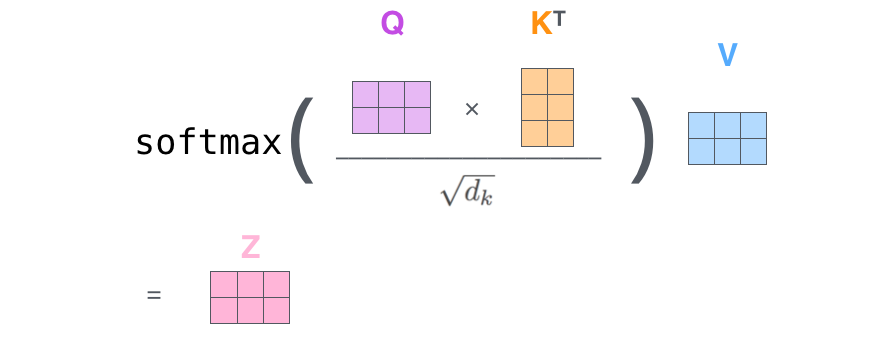
.
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
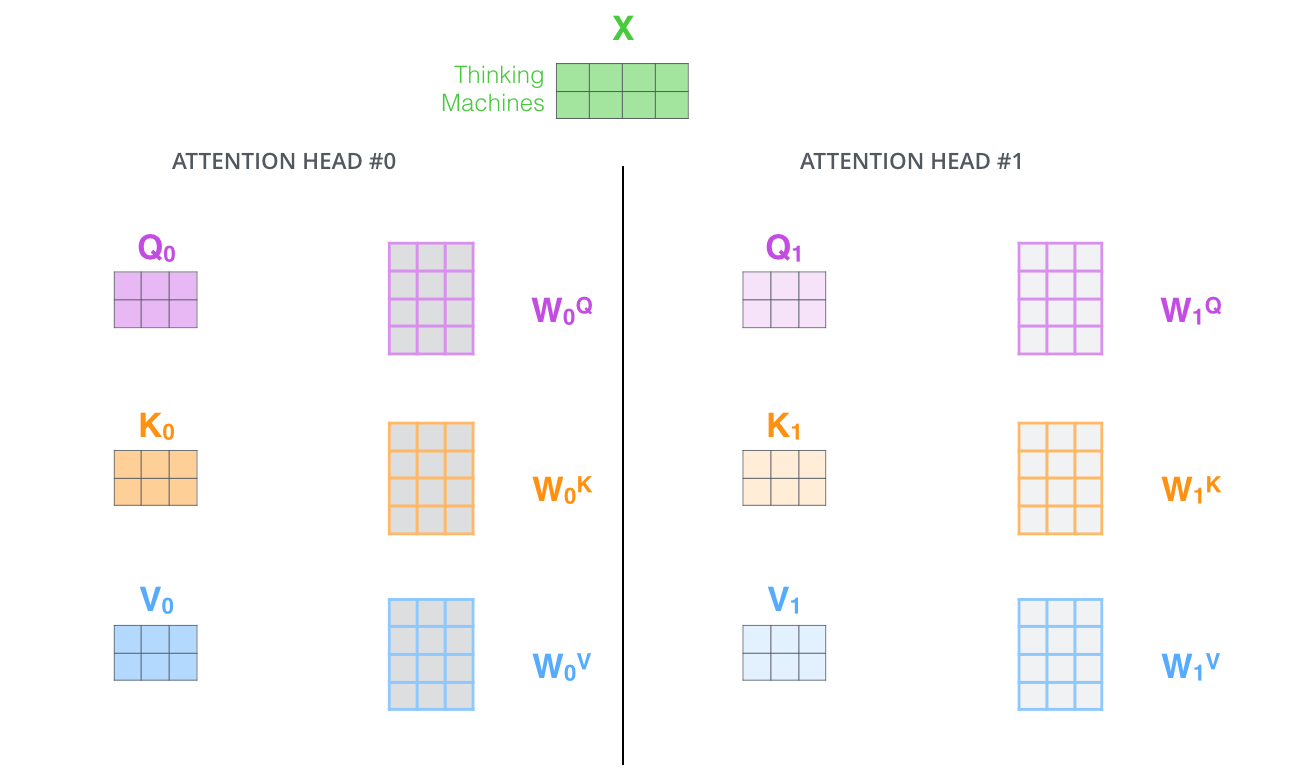
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
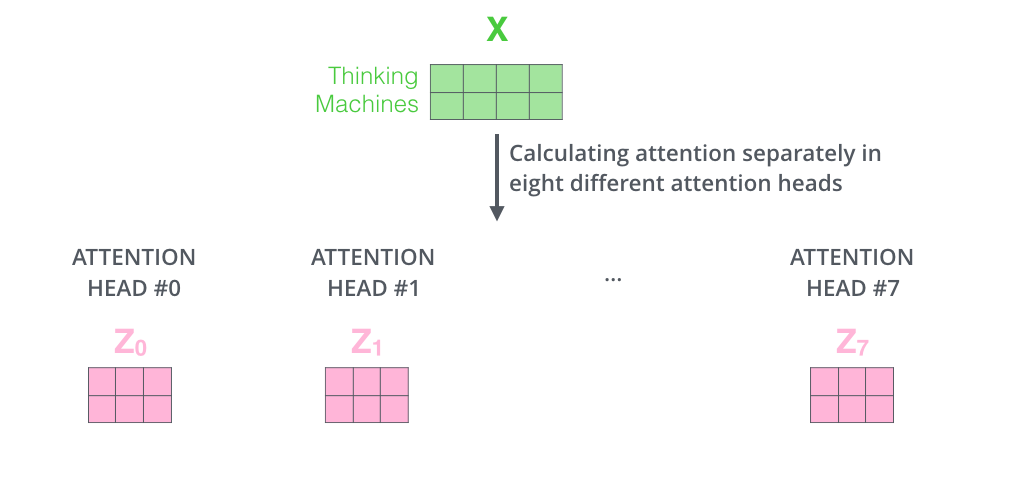
. , 8 – ( ), Z .
? WO.
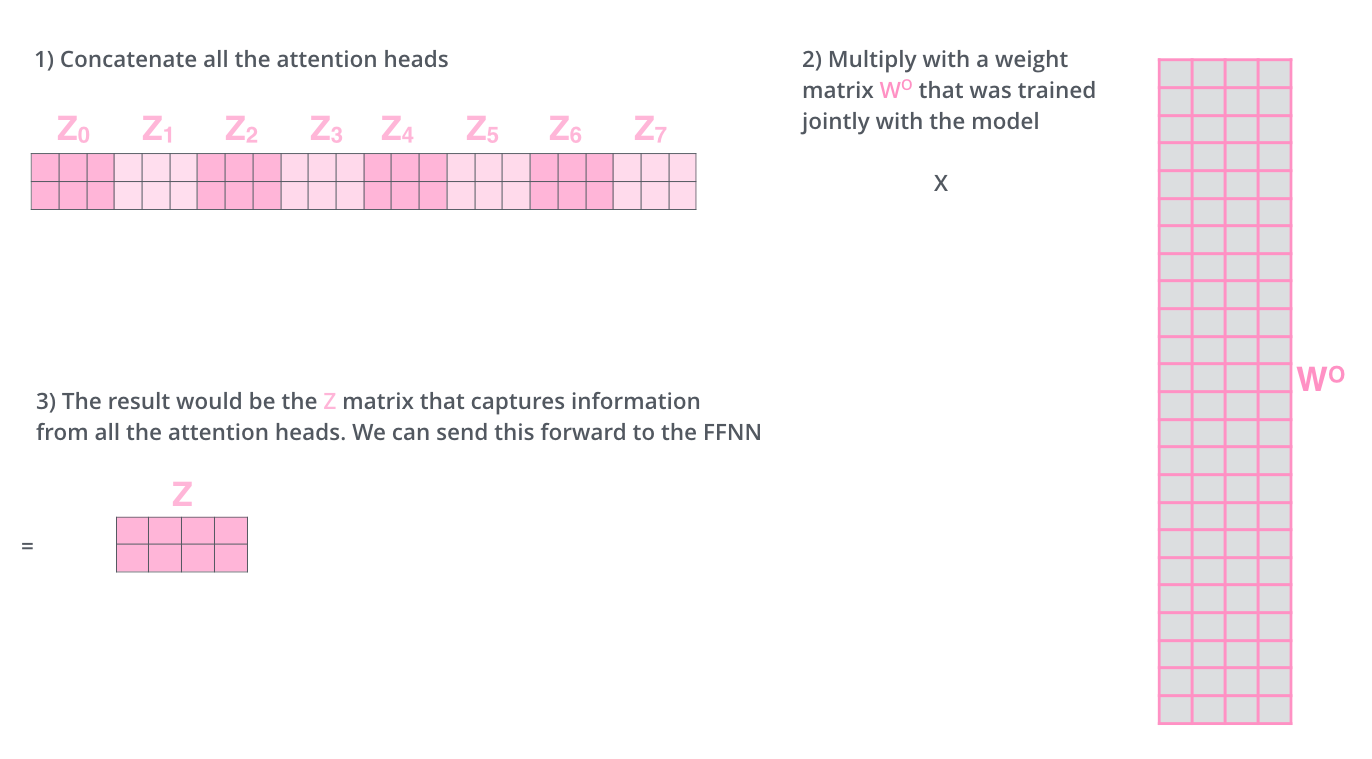
, , . , . , .
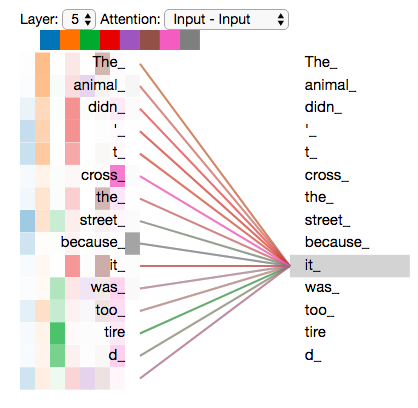
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
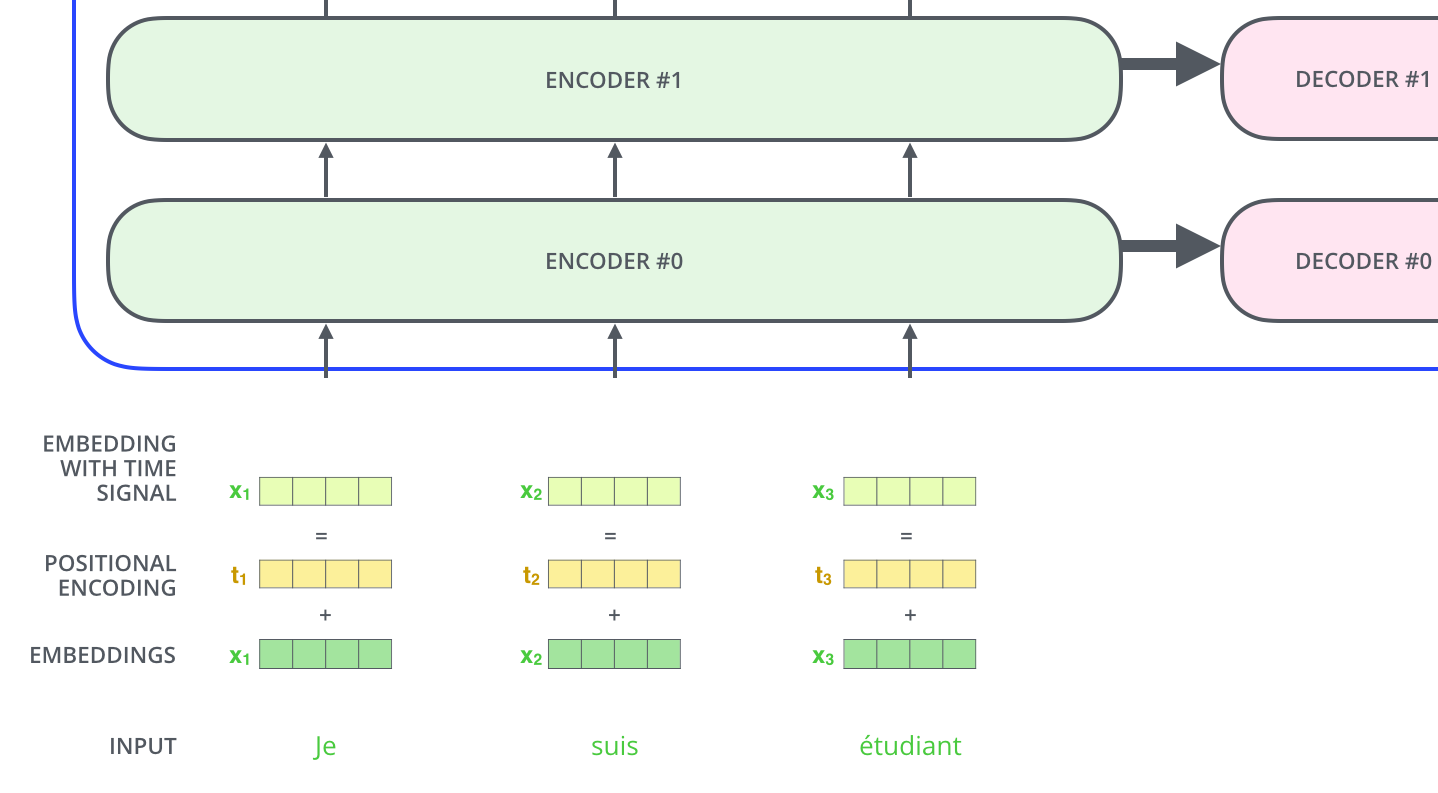
, , , .
, 4, :
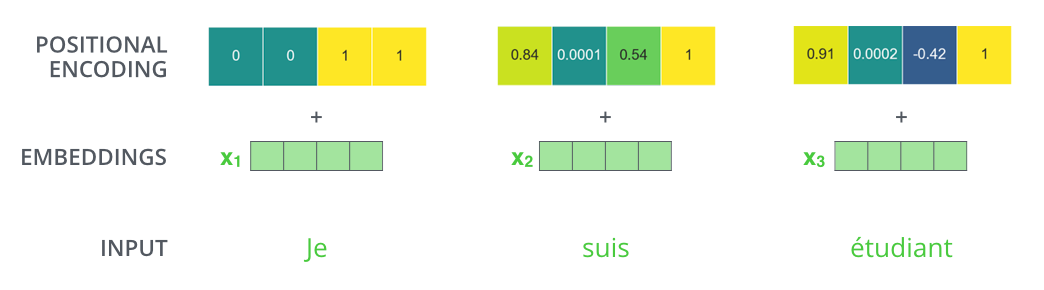
?
: , , , — .. 512 -1 1. , .
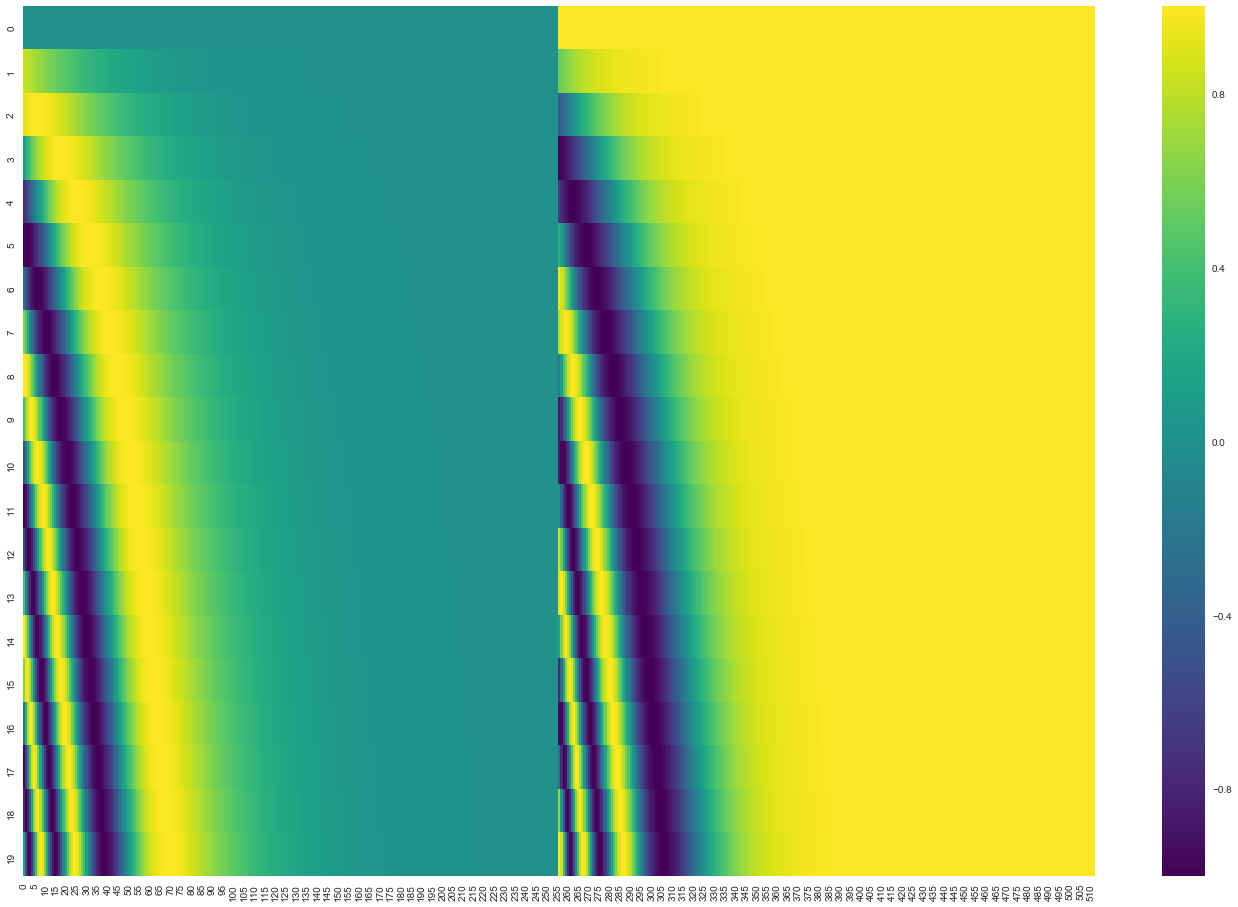
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
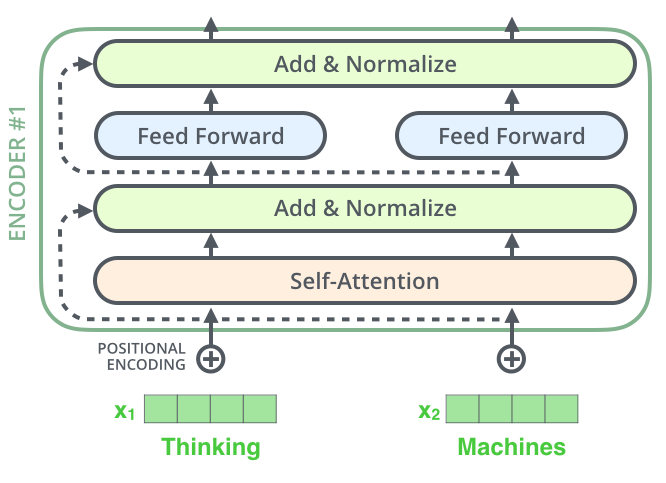
, , :
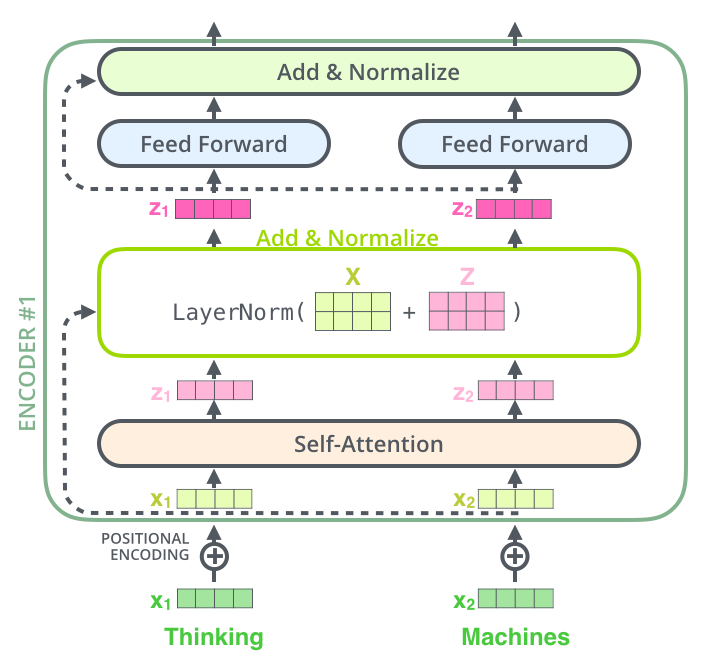
. , :
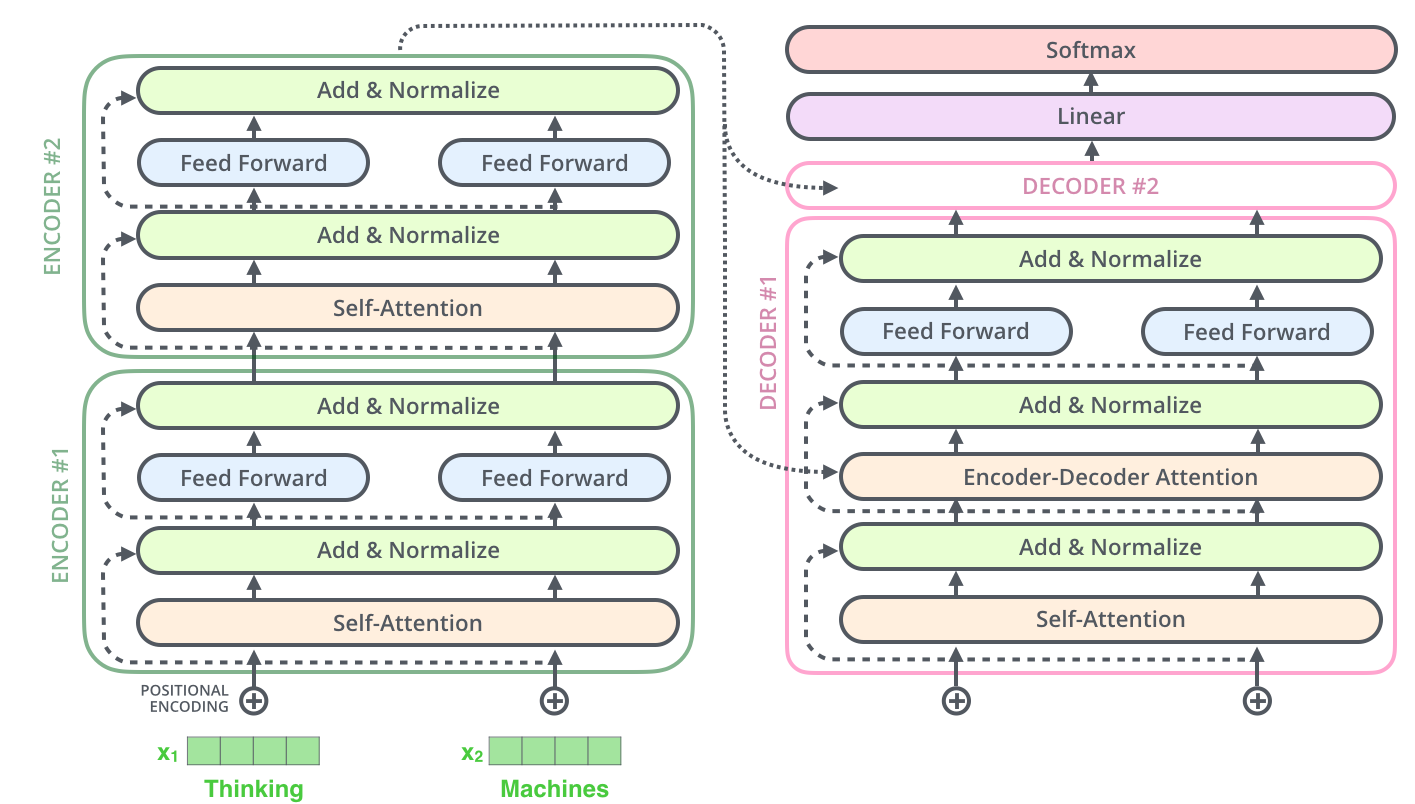
, , , . , .
. K V. «-» , :
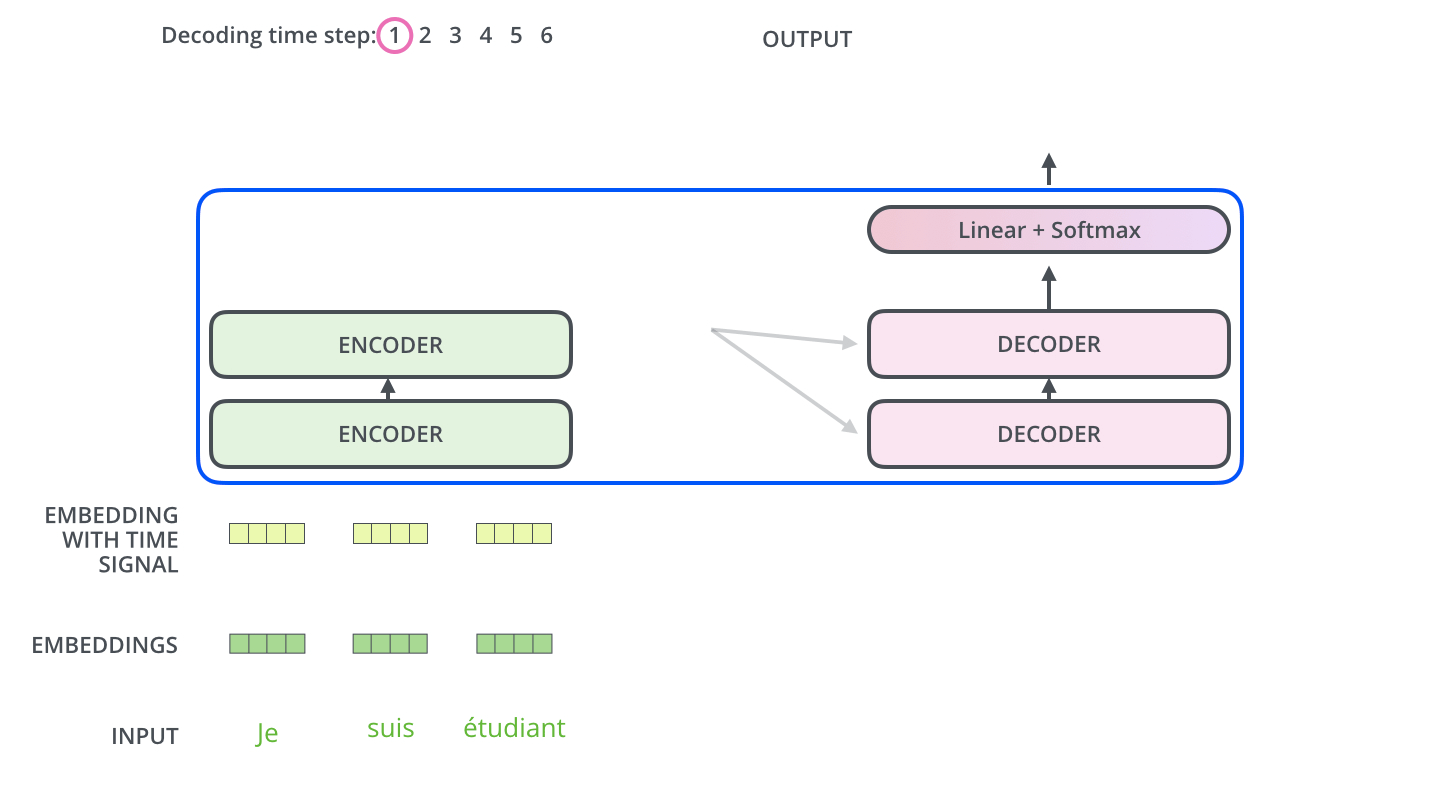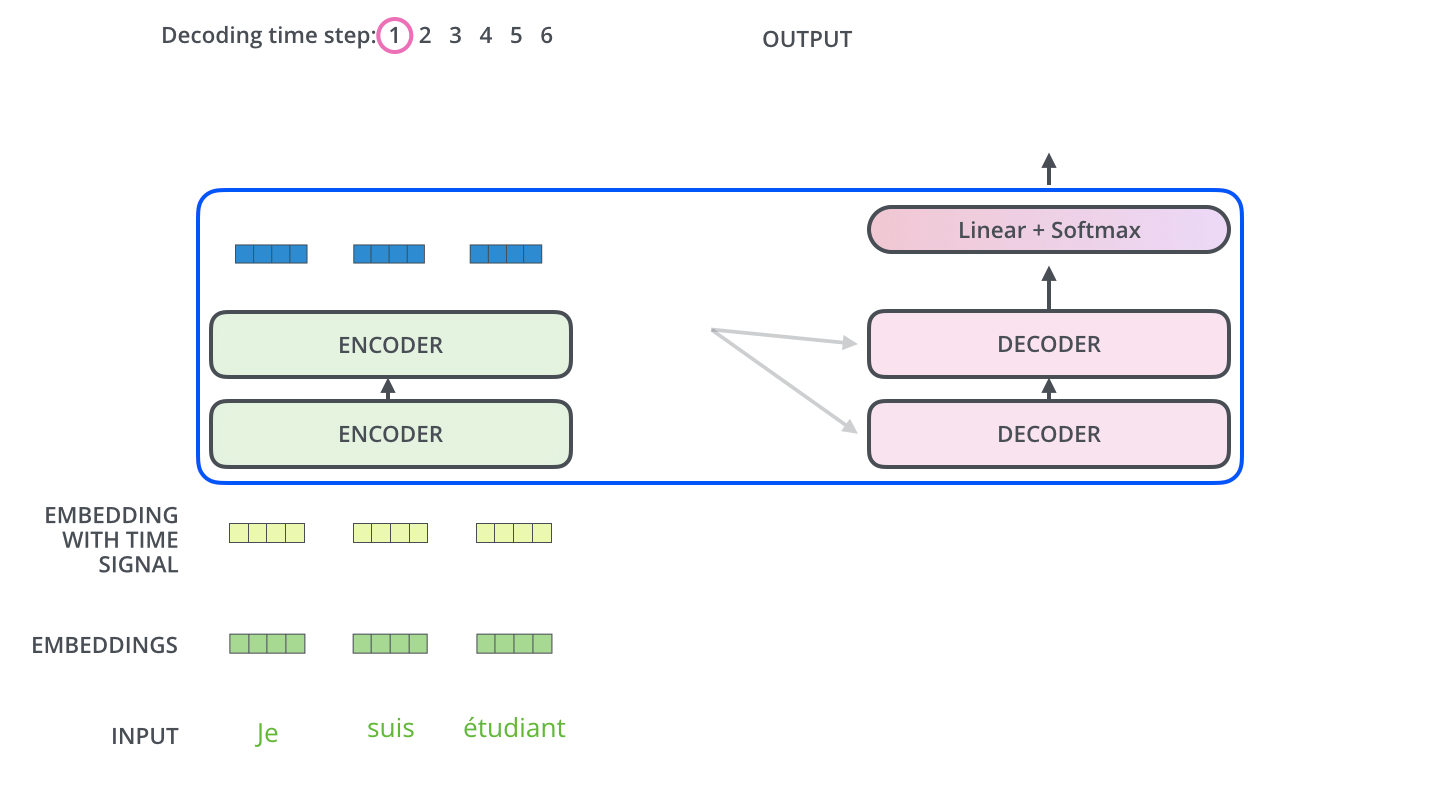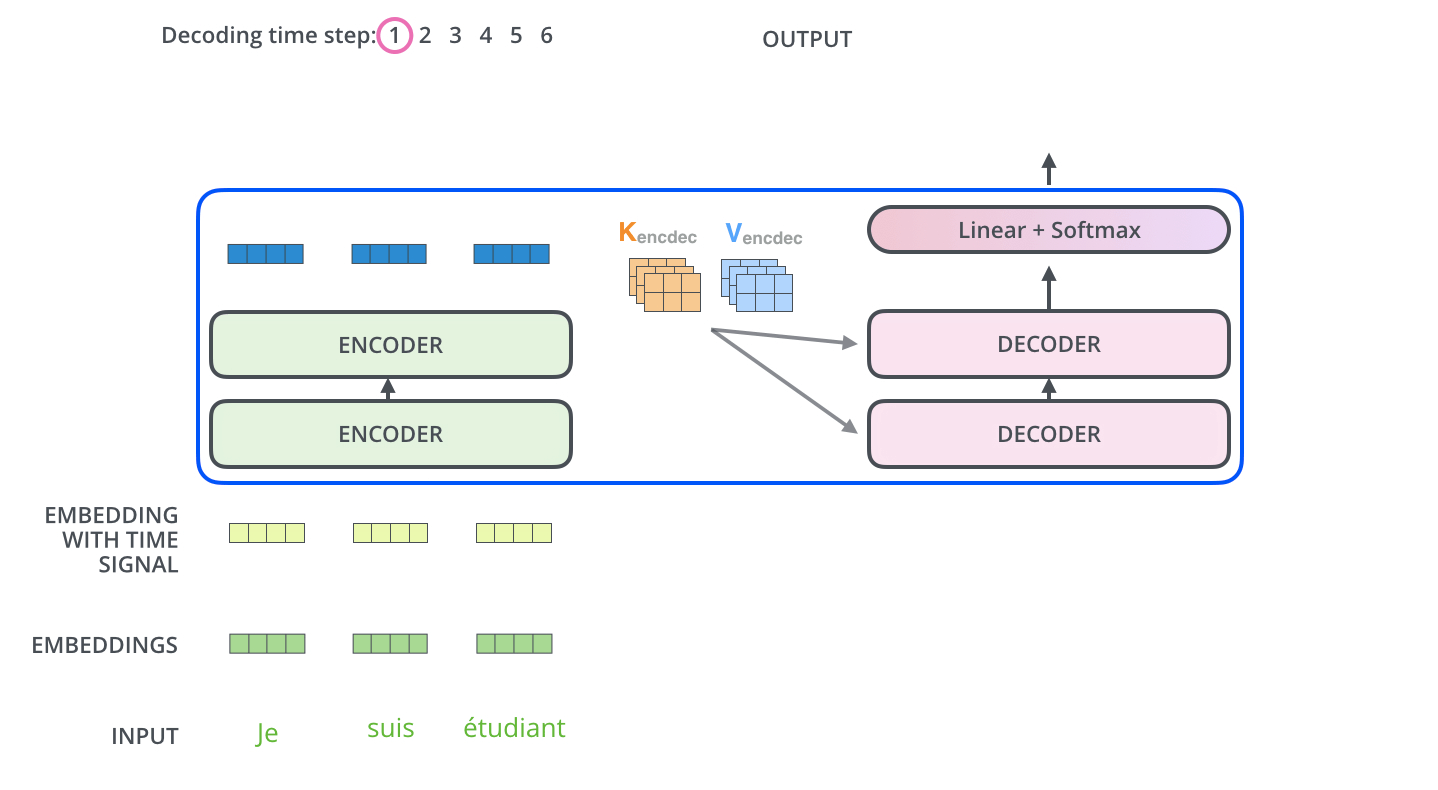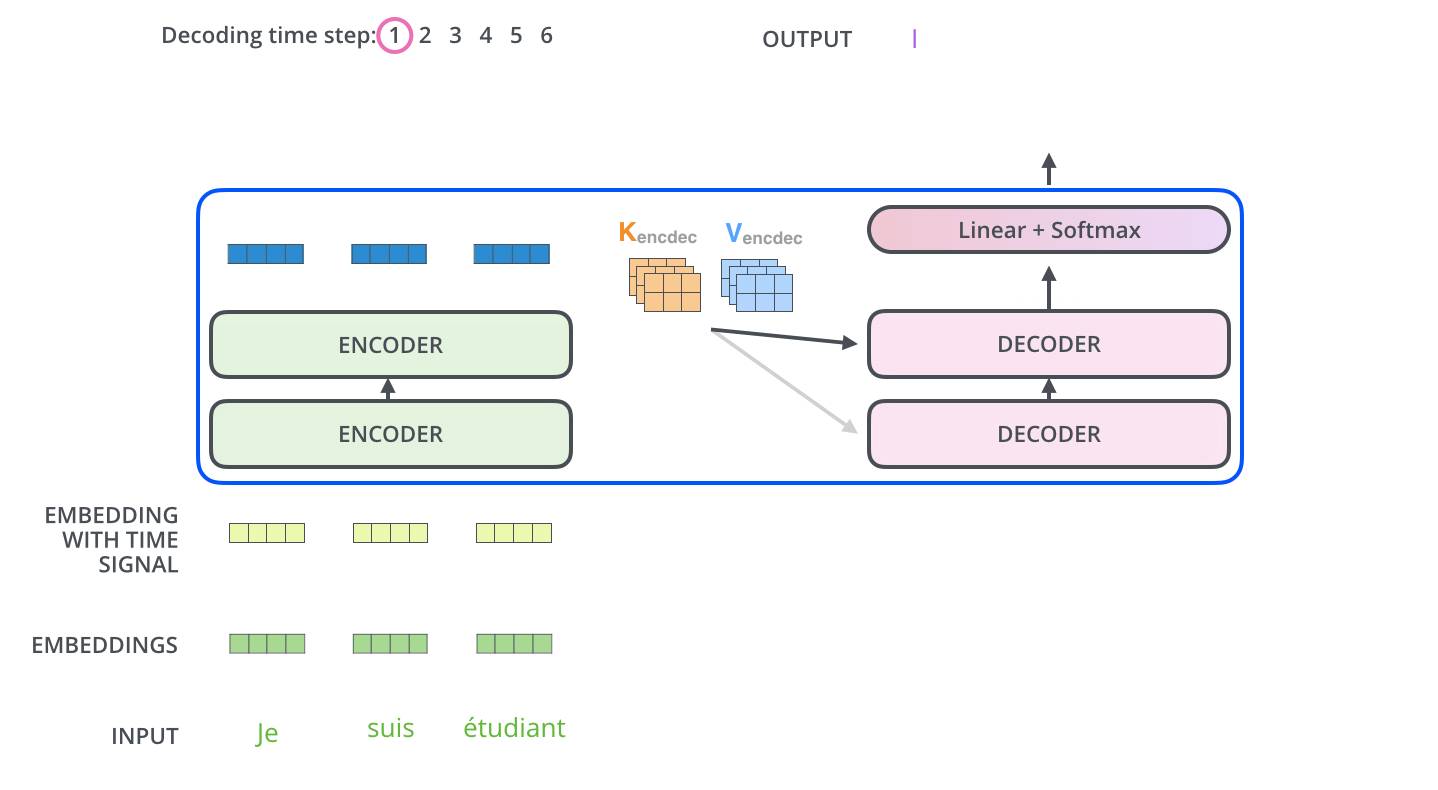
. ( – ).
, , . , , . , , , .
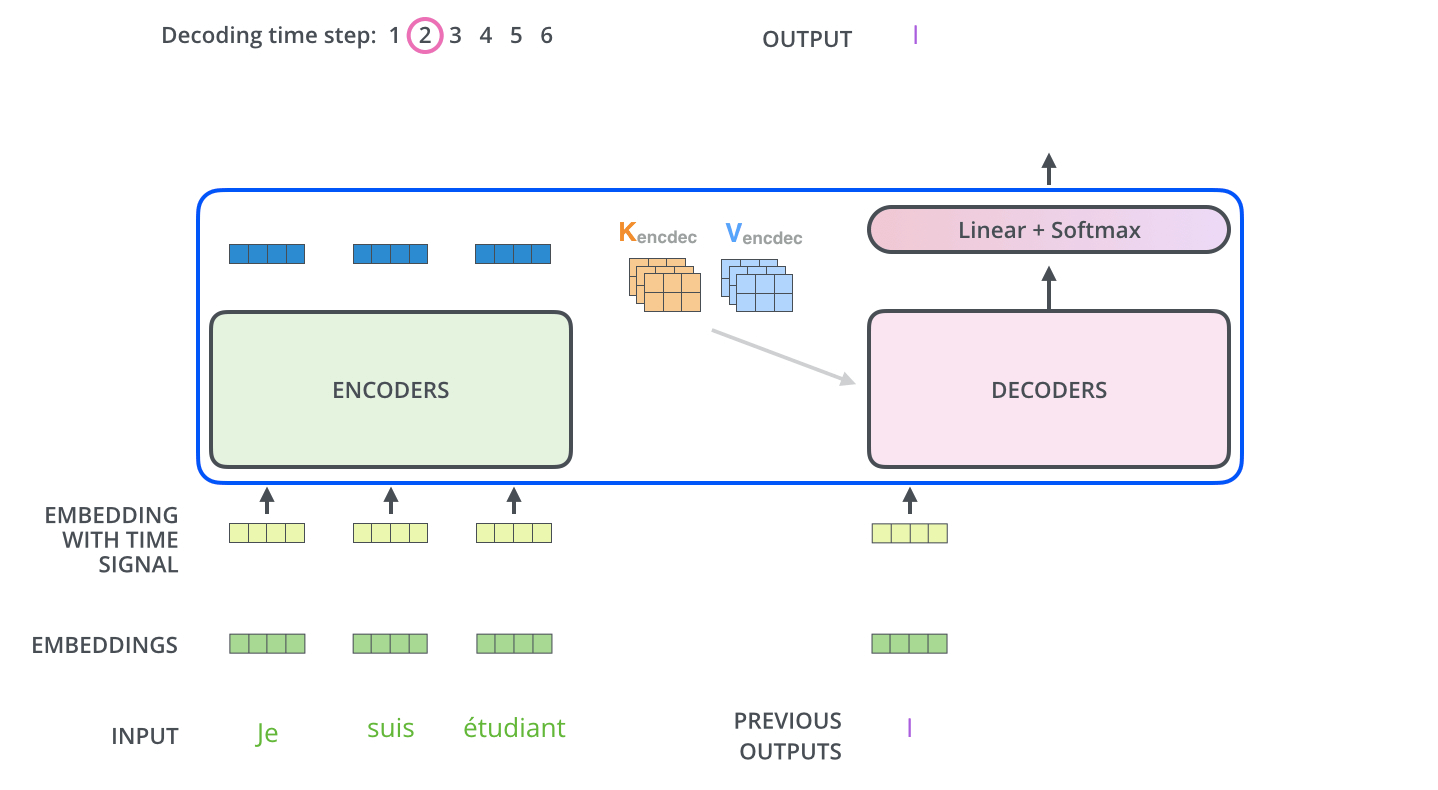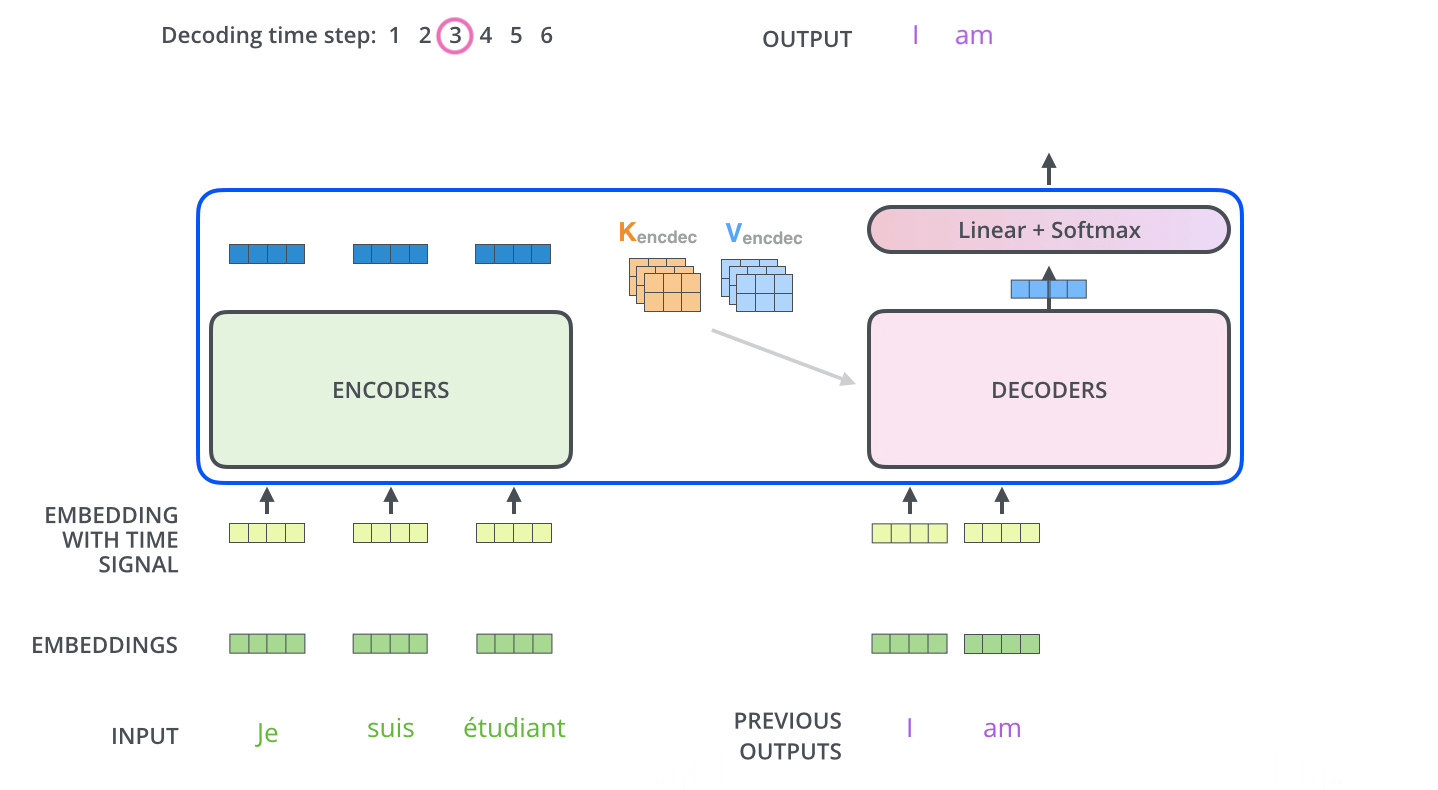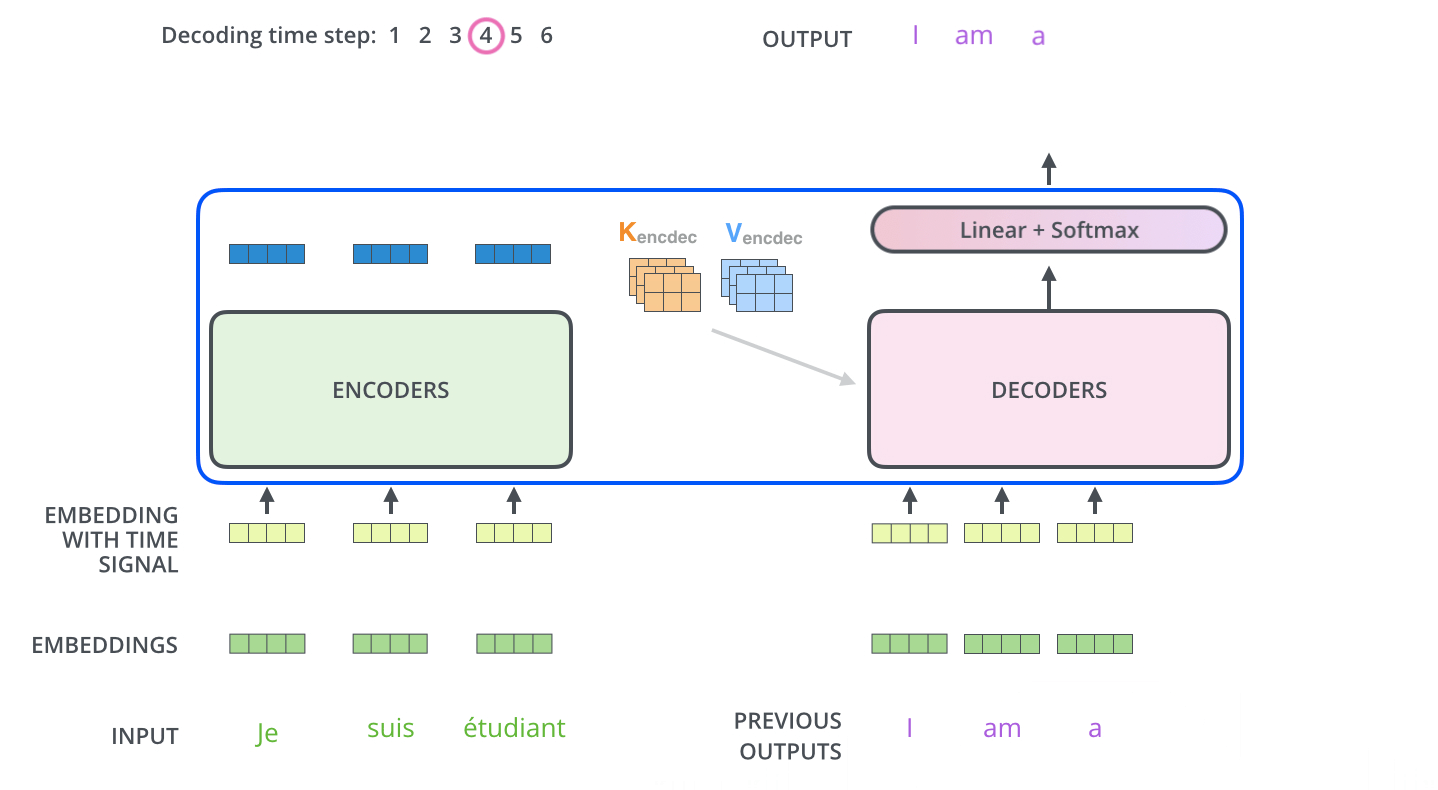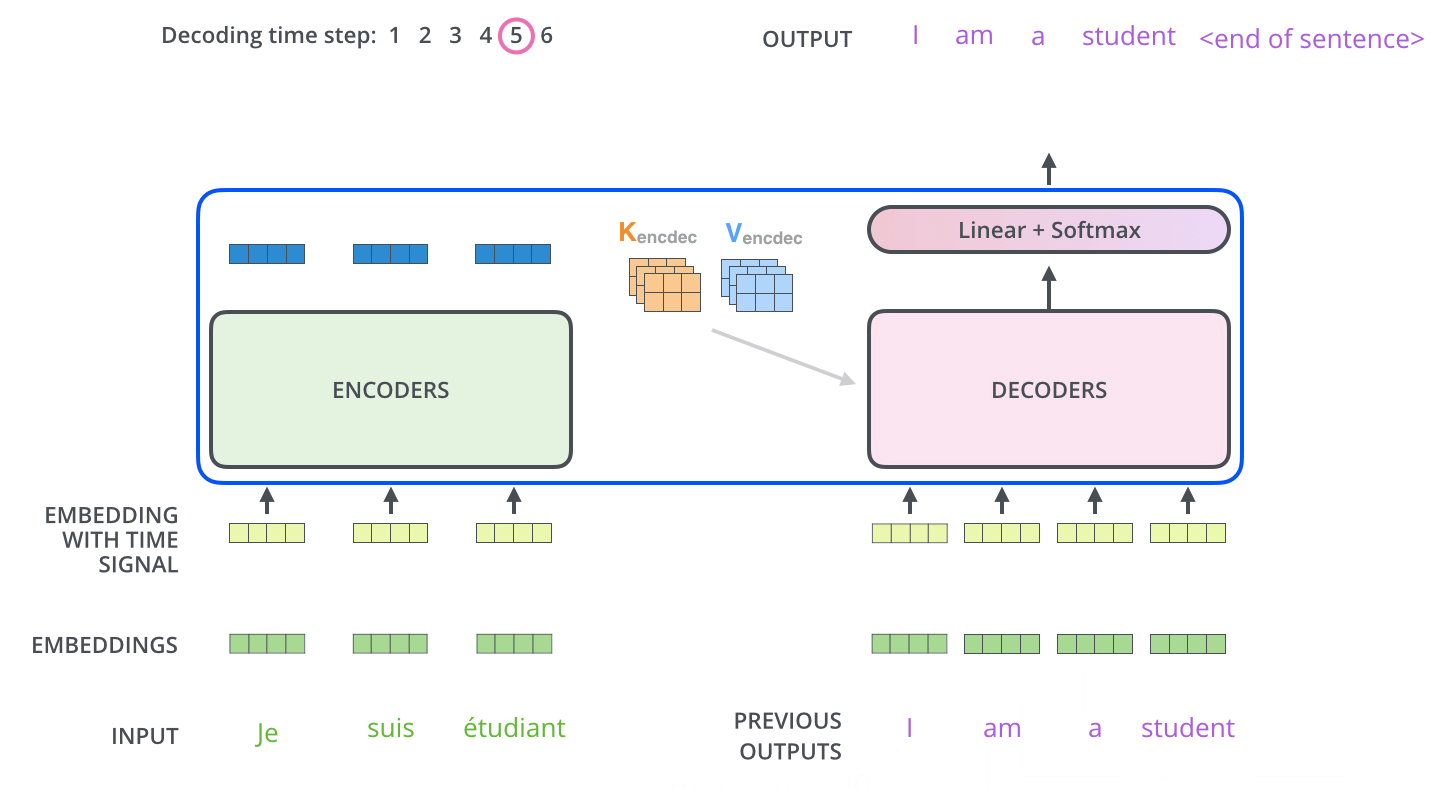
.
. ( –inf) .
«-» , , , , .
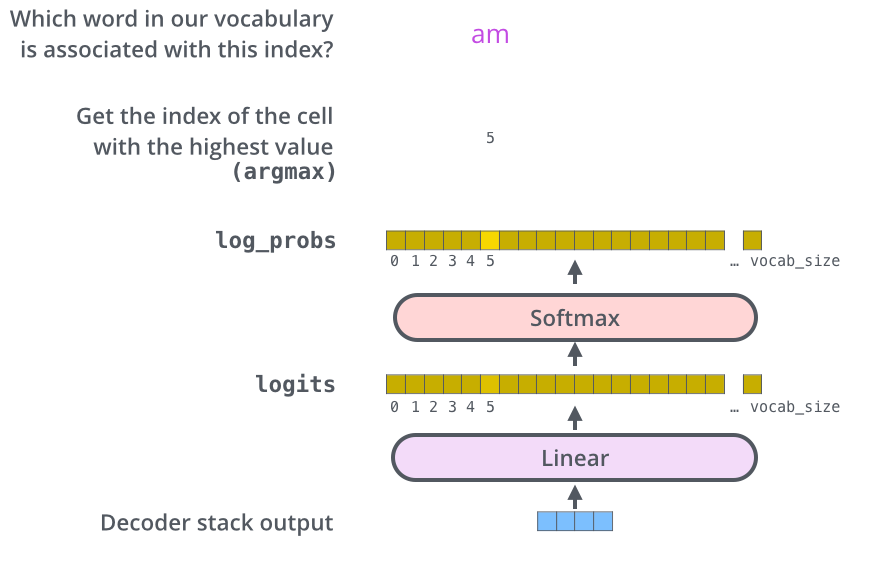
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
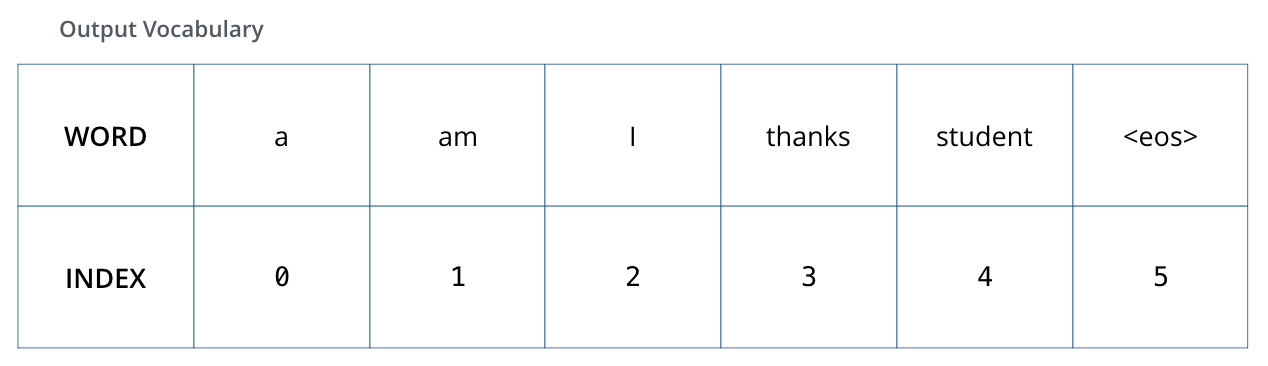
.
, (, one-hot-). , «am», :
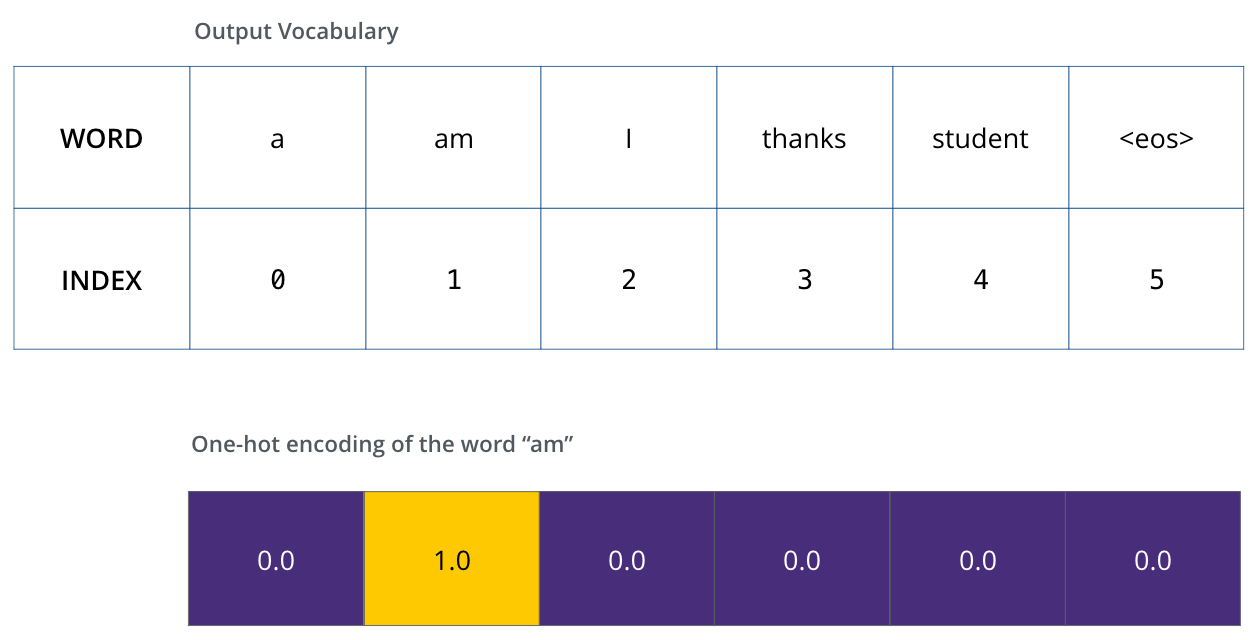
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
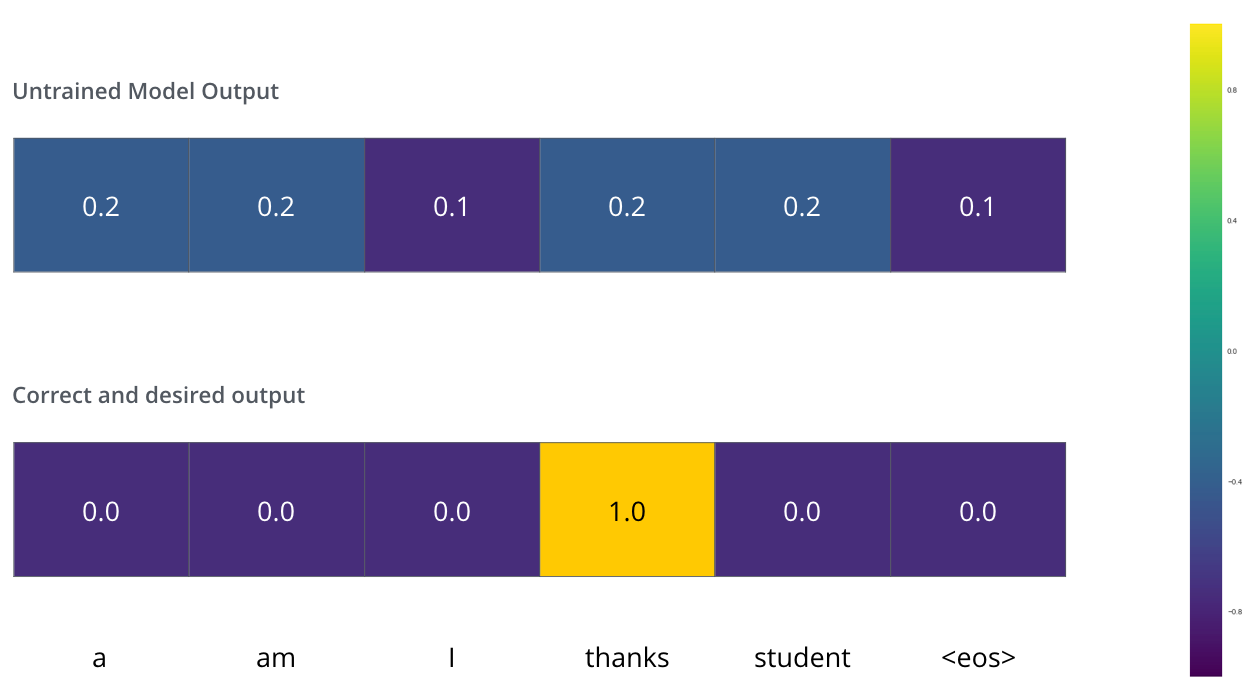
() , /. , , , .
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
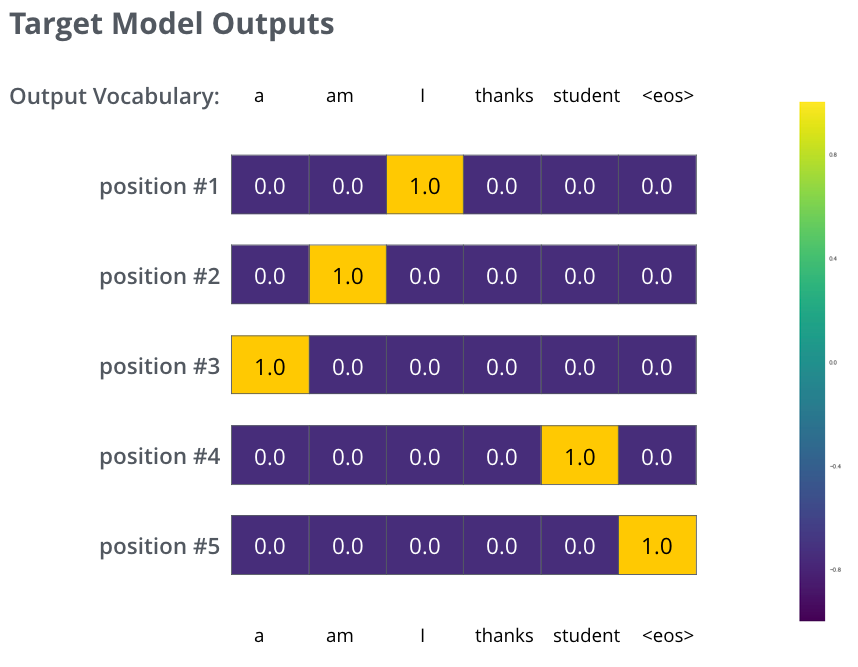
, :
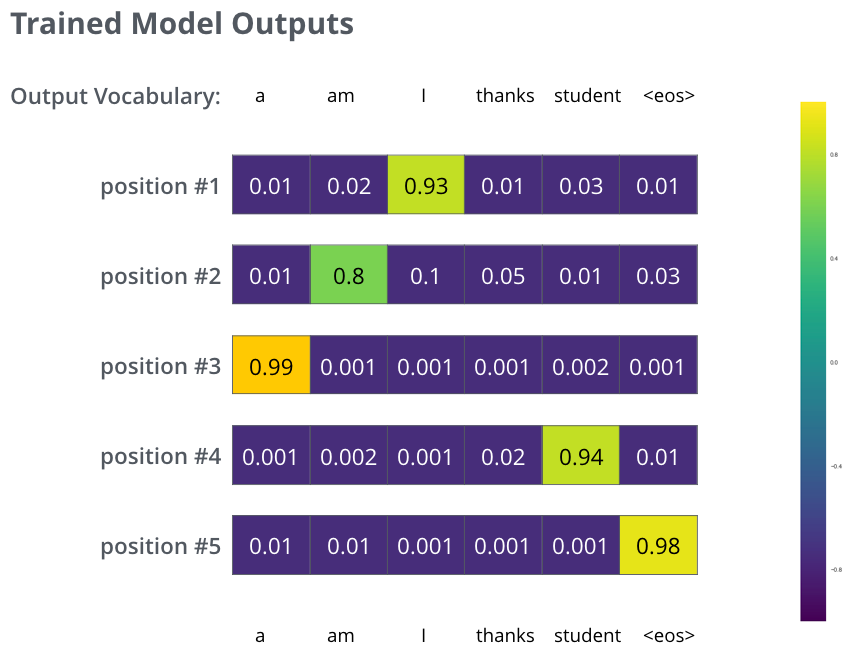
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
s