O NiFi está ganhando cada vez mais popularidade e, a cada nova versão, recebe mais e mais ferramentas para trabalhar com dados. No entanto, pode ser necessário ter sua própria ferramenta para resolver um problema específico. O Apache Nifi possui mais de 300 processadores em seu pacote base. Processador Nifi É o principal componente básico para a criação de fluxo de dados no ecossistema NiFi. Os processadores fornecem uma interface através da qual o NiFi fornece acesso ao arquivo de fluxo, seus atributos e conteúdo. Um processador personalizado economiza energia, tempo e atenção do usuário, porque, em vez de muitos elementos simples do processador, apenas um será exibido na interface e apenas um será executado (bem, ou quanto você escreve). Como os processadores padrão, um processador personalizado permite executar várias operações e processar o conteúdo de um arquivo de fluxo. Hoje falaremos sobre ferramentas padrão para expandir a funcionalidade.
É o principal componente básico para a criação de fluxo de dados no ecossistema NiFi. Os processadores fornecem uma interface através da qual o NiFi fornece acesso ao arquivo de fluxo, seus atributos e conteúdo. Um processador personalizado economiza energia, tempo e atenção do usuário, porque, em vez de muitos elementos simples do processador, apenas um será exibido na interface e apenas um será executado (bem, ou quanto você escreve). Como os processadores padrão, um processador personalizado permite executar várias operações e processar o conteúdo de um arquivo de fluxo. Hoje falaremos sobre ferramentas padrão para expandir a funcionalidade.ExecuteScript
O ExecuteScript é um processador universal projetado para implementar a lógica de negócios em uma linguagem de programação (Groovy, Jython, Javascript, JRuby). Essa abordagem permite que você obtenha rapidamente a funcionalidade desejada. Para fornecer acesso aos componentes NiFi em um script, é possível usar as seguintes variáveis:Sessão : uma variável do tipo org.apache.nifi.processor.ProcessSession. A variável permite executar operações com o arquivo de fluxo, como create (), putAttribute () e Transfer (), além de read () e write ().Contexto : org.apache.nifi.processor.ProcessContext. Ele pode ser usado para obter propriedades, relacionamentos, serviços do controlador e StateManager do processador.REL_SUCCESS : relacionamento "sucesso".REL_FAILURE : Relacionamento com falhaPropriedades dinâmicas : as propriedades dinâmicas definidas no ExecuteScript são passadas para o mecanismo de script como variáveis, definidas como um PropertyValue. Isso permite que você obtenha o valor da propriedade, converta o valor no tipo de dados apropriado, por exemplo, lógico, etc.Para uso, basta selecionar Script Enginee especificar o local do arquivo Script Filecom nosso script ou com o próprio script Script Body.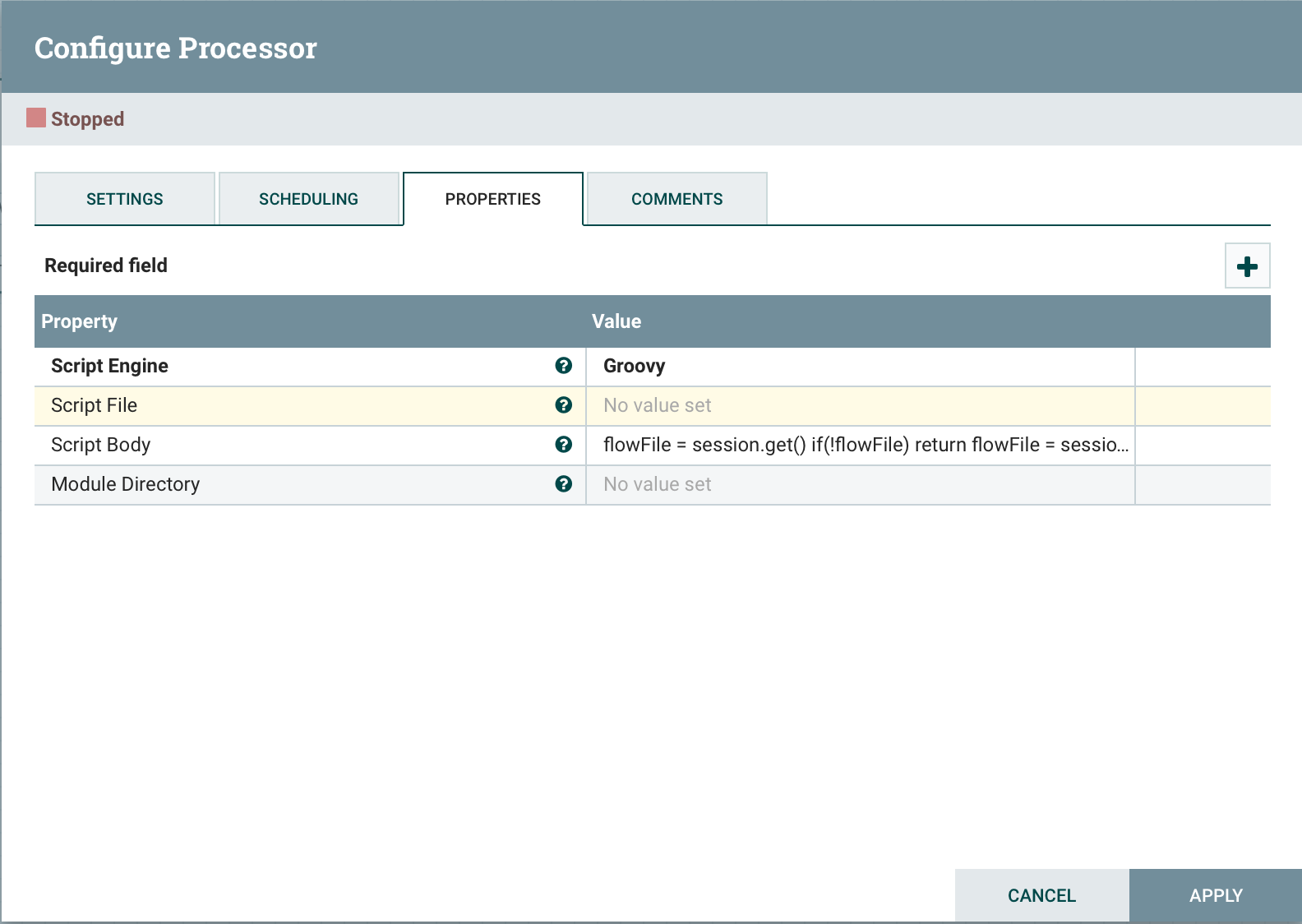 Vejamos alguns exemplos:obtenha um arquivo de fluxo da fila
Vejamos alguns exemplos:obtenha um arquivo de fluxo da filaflowFile = session.get()
if(!flowFile) return
Gere um novo FlowFileflowFile = session.create()
// Additional processing here
Adicionar atributo ao FlowFileflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Extraia e processe todos os atributos.flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Loggerlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
Você pode usar recursos avançados no ExecuteScript. Mais informações sobre isso podem ser encontradas no artigo ExecuteScript Cookbook.ExecuteGroovyScript
O ExecuteGroovyScript possui a mesma funcionalidade que o ExecuteScript, mas, em vez de um zoológico de linguagens válidas, você pode usar apenas um groovy. A principal vantagem desse processador é o uso mais conveniente dos serviços de serviço. Além do conjunto padrão de variáveis Sessão, Contexto, etc. Você pode definir propriedades dinâmicas com o prefixo CTL e SQL. A partir da versão 1.11, o suporte ao RecordReader e Record Writer apareceu. Todas as propriedades são HashMap, que usa o "Nome do serviço" como chave e o valor é um objeto específico, dependendo da propriedade:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
Esta informação já facilita a vida. podemos procurar nas fontes ou encontrar documentação para uma classe específica.Trabalhando com o banco de dadosSe definirmos a propriedade SQL.DB e vincularmos o DBCPService, acessaremos a propriedade a SQL.DB.rows('select * from table') partir do código.O processador aceita automaticamente uma conexão do serviço dbcp antes da execução e processa a transação. As transações do banco de dados são revertidas automaticamente quando ocorre um erro e são confirmadas se forem bem-sucedidas. No ExecuteGroovyScript, você pode interceptar eventos de início e parada implementando os métodos estáticos apropriados.
partir do código.O processador aceita automaticamente uma conexão do serviço dbcp antes da execução e processa a transação. As transações do banco de dados são revertidas automaticamente quando ocorre um erro e são confirmadas se forem bem-sucedidas. No ExecuteGroovyScript, você pode interceptar eventos de início e parada implementando os métodos estáticos apropriados.import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
Outro processador interessante. Para usá-lo, você precisa declarar uma classe que implementa a interface dos implementos e definir uma variável do processador. Você pode definir qualquer PropertyDescriptor ou Relationship, também acessar o pai ComponentLog e definir os métodos void onScheduled (contexto ProcessContext) e void onStopped (contexto ProcessContext). Esses métodos serão chamados quando um evento de início agendado ocorrer no NiFi (onScheduled) e quando ele parar (onScheduled).class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
A lógica deve ser implementada no método void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
Não é necessário descrever todos os métodos declarados na interface; portanto, vamos contornar uma classe abstrata na qual declaramos o seguinte método:abstract void executeScript(ProcessContext context, ProcessSession session)
O método que chamaremosvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Agora declaramos uma classe sucessora BaseGroovyProcessore descrevemos nosso executeScript, também adicionamos Relationship RELSUCCESS e RELFAILURE.import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
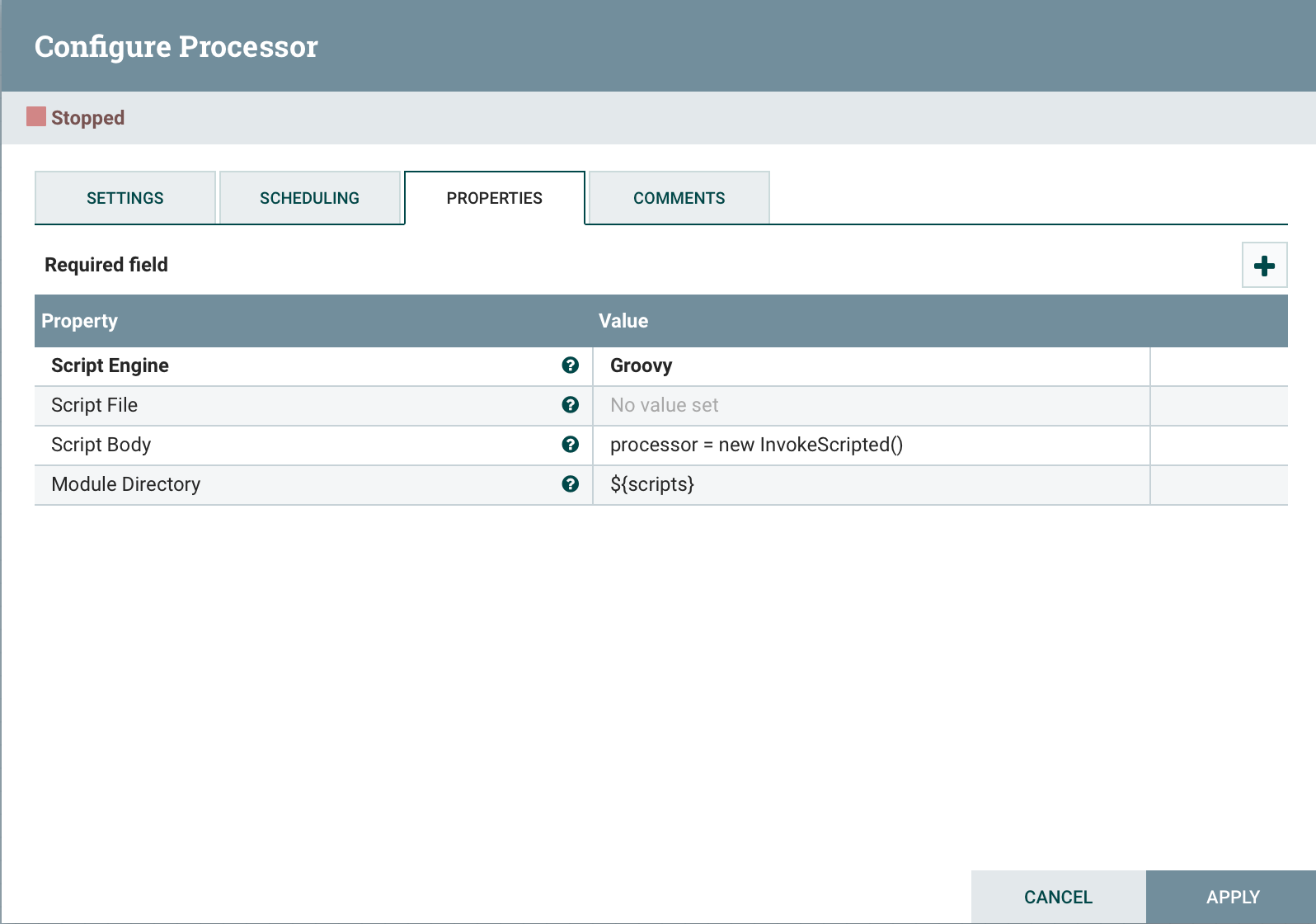 Adicione ao final do código.Esta
Adicione ao final do código.Esta processor = new InvokeScripted()abordagem é semelhante à criação de um processador personalizado.Conclusão
Criar um processador personalizado não é a coisa mais fácil - pela primeira vez, você precisa trabalhar duro para descobrir, mas os benefícios dessa ação são inegáveis.Post preparado pela equipe de gerenciamento de dados da Rostelecom