Olá de novo. Hoje continuamos a série de traduções em antecipação ao início do curso básico "Matemática para Ciência de Dados" .
Em um artigo recente , falamos sobre como criar um detector de anomalia no Power BI, integrando o PyCaret a ele, e ajudar analistas e analistas de dados a adicionar aprendizado de máquina a relatórios e painéis sem muito esforço.Neste artigo, veremos como executar a análise de cluster usando o PyCaret e o Power BI. Se você nunca ouviu falar sobre o PyCaret antes, pode começar a se familiarizar com ele aqui .O que discutiremos no guia de hoje:- O que é clustering? Tipos de cluster.
- Aprendendo sem um professor e implementando um modelo de cluster no Power BI.
- Análise dos resultados e visualização de informações no painel.
- Como implantar um modelo de cluster na produção no Power BI?
Antes de começarmos ...
Se você já usou o Python antes, provavelmente já possui o Anaconda no seu computador. Caso contrário, você pode baixar a distribuição Anaconda do Python 3.7 ou superior a partir daqui .Configuração do ambiente
Antes de começar a usar os recursos de aprendizado de máquina PyCaret no Power BI, você precisa criar um ambiente virtual e instalá-lo nele pycaret. Para fazer isso, precisamos executar três etapas:Etapa 1 - Criar um ambiente virtualAbra o prompt de comando do Anaconda e digite o seguinte:conda create --name myenv python=3.7
Etapa 2 - Instalar o PyCaretExecute o seguinte comando no prompt de comando do Anaconda:pip install pycaret
A instalação pode levar de 15 a 20 minutos. Se você encontrar algum problema durante a instalação, poderá se familiarizar com a solução deles em nossa página no GitHub .Etapa 3 - Indique no Power BI onde o Python está instalado.Oambiente virtual criado deve estar associado ao Power BI. Você pode fazer isso usando Configurações globais no Power BI Desktop (Arquivo -> Opções -> Global -> script Python). O ambiente Anaconda é colocado no diretório por padrão:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
O que é clustering?
O clustering é um método de dividir dados em grupos de acordo com características semelhantes. Esses grupos podem ser úteis para estudar dados, identificar padrões e analisar subconjuntos de dados. O agrupamento de dados ajuda a identificar estruturas de dados subjacentes, o que é útil em muitos setores. Aqui estão alguns usos comuns para clustering nos negócios:- Segmentação de clientes de marketing.
- Análise do comportamento do consumidor para promoções e descontos.
- Identificação de geoclusters durante um surto, como, por exemplo, COVID-19.
Tipos de cluster
Dada a natureza subjetiva das tarefas de agrupamento, existem vários algoritmos que são mais adequados para resolver certos tipos de tarefas. Cada algoritmo tem suas próprias características e justificativa matemática, subjacentes à distribuição de clusters.No tutorial de hoje, estamos falando sobre análise de cluster no Power BI usando uma biblioteca Python chamada PyCaret e não iremos aprofundar a matemática. Hoje vamos usar o método k-means - um dos métodos de ensino mais simples e populares sem um professor. Você pode encontrar mais informações sobre o método k-means aqui .
Hoje vamos usar o método k-means - um dos métodos de ensino mais simples e populares sem um professor. Você pode encontrar mais informações sobre o método k-means aqui .Contexto empresarial
Neste guia, usaremos um conjunto de dados pré-fabricados do banco de dados de Despesas Globais de Saúde da Organização Mundial da Saúde. Ele contém gastos com saúde como uma porcentagem do PIB nacional para mais de 200 países entre 2000 e 2017.Nossa tarefa é encontrar padrões e grupos nesses dados usando o método k-means.Os dados podem ser encontrados aqui .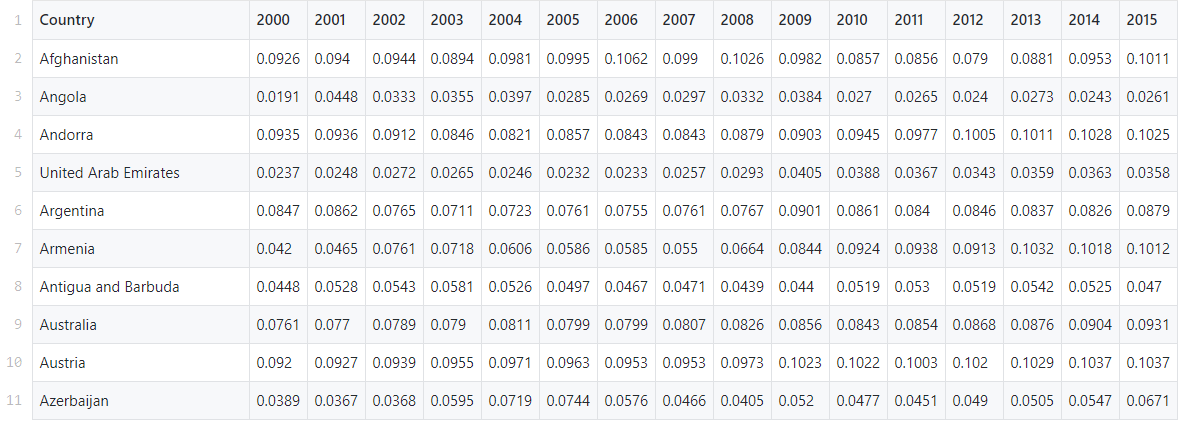
Então vamos começar
Agora que você configurou o ambiente Anaconda, instalou o PyCaret, entendeu o básico da análise de cluster e o contexto de negócios, é hora de começar a trabalhar.1. Aquisição de dados
A primeira etapa é importar o conjunto de dados para o Power BI Desktop. Você pode baixar dados usando o conector da web. (Power BI Desktop → Obter dados → Da Web ). Link para o arquivo csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .
Link para o arquivo csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .2. Modelo de treinamento
Para aprender o modelo de cluster no Power BI, precisamos executar um script Python no Power Query Editor ( Power Query Editor → Transformar → Executar python script ). Use o seguinte código como um script:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 Nós ignorou o “País” coluna do conjunto usando o parâmetro
Nós ignorou o “País” coluna do conjunto usando o parâmetro ignore_features. Há muitas razões pelas quais você pode precisar excluir determinadas colunas para treinar melhor o modelo de aprendizado de máquina.O PyCaret permite ocultar colunas desnecessárias em vez de excluí-las, porque você poderá precisar delas no futuro para análises adicionais. Por exemplo, no momento não queríamos usar "País" para treinamento e passamos essa coluna para ignore_features.Existem 8 algoritmos de aprendizado de máquina prontos para uso no PyCaret. Por padrão, o PyCaret treina o modelo de cluster k-means em quatro clusters. Mas os valores padrão podem ser facilmente alterados:
Por padrão, o PyCaret treina o modelo de cluster k-means em quatro clusters. Mas os valores padrão podem ser facilmente alterados:- Para alterar o tipo de modelo, use o modelo de parâmetro em
get_clusters(). - Para alterar o número de clusters, use a opção
num_clusters.
Por exemplo, é assim que você pode fazer o k-means em cluster em 6 clusters.from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
Conclusão:
 Outra coluna com um rótulo de cluster é adicionada ao conjunto de dados original. Todos os valores da coluna ano são usados para normalizar os dados e visualizar ainda mais no Power BI.É assim que o resultado final será exibido no Power BI.
Outra coluna com um rótulo de cluster é adicionada ao conjunto de dados original. Todos os valores da coluna ano são usados para normalizar os dados e visualizar ainda mais no Power BI.É assim que o resultado final será exibido no Power BI.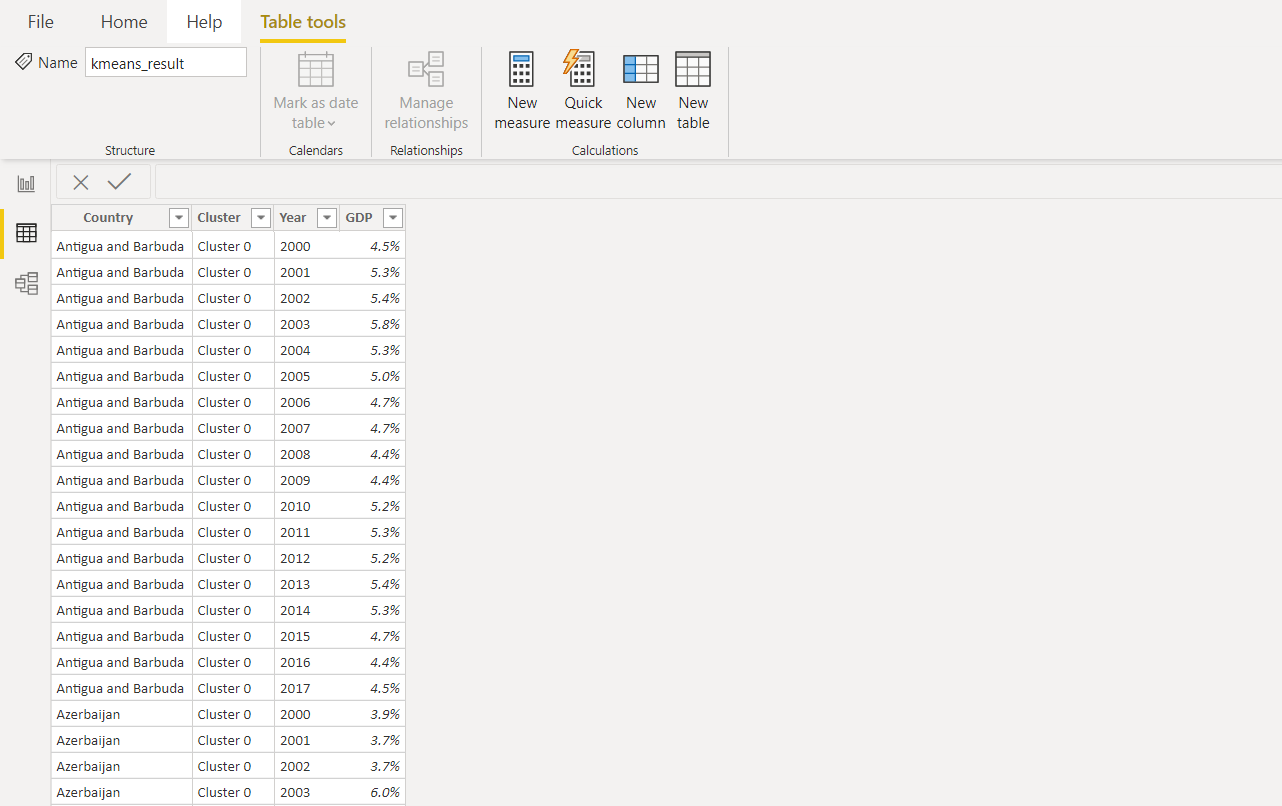
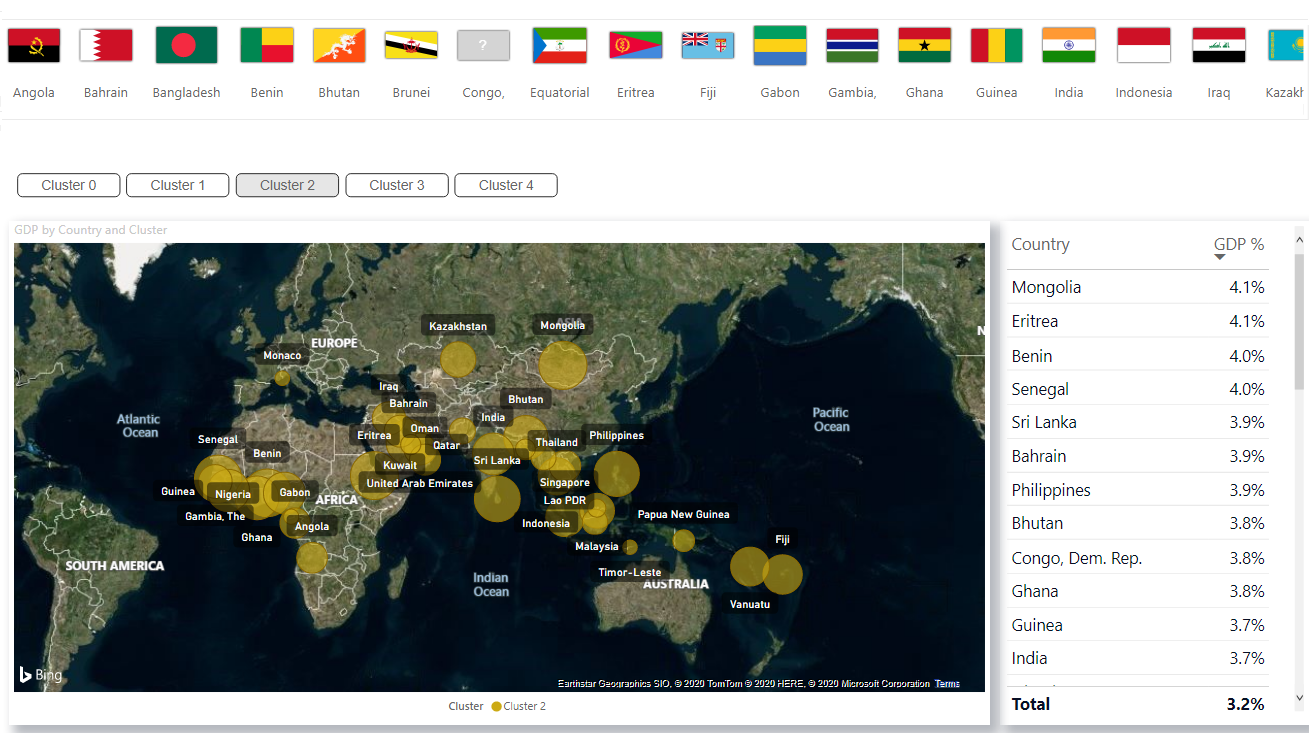
3. Painel
Quando você adquiriu rótulos de cluster no Power BI, é possível visualizá-los no painel do Power BI para análise: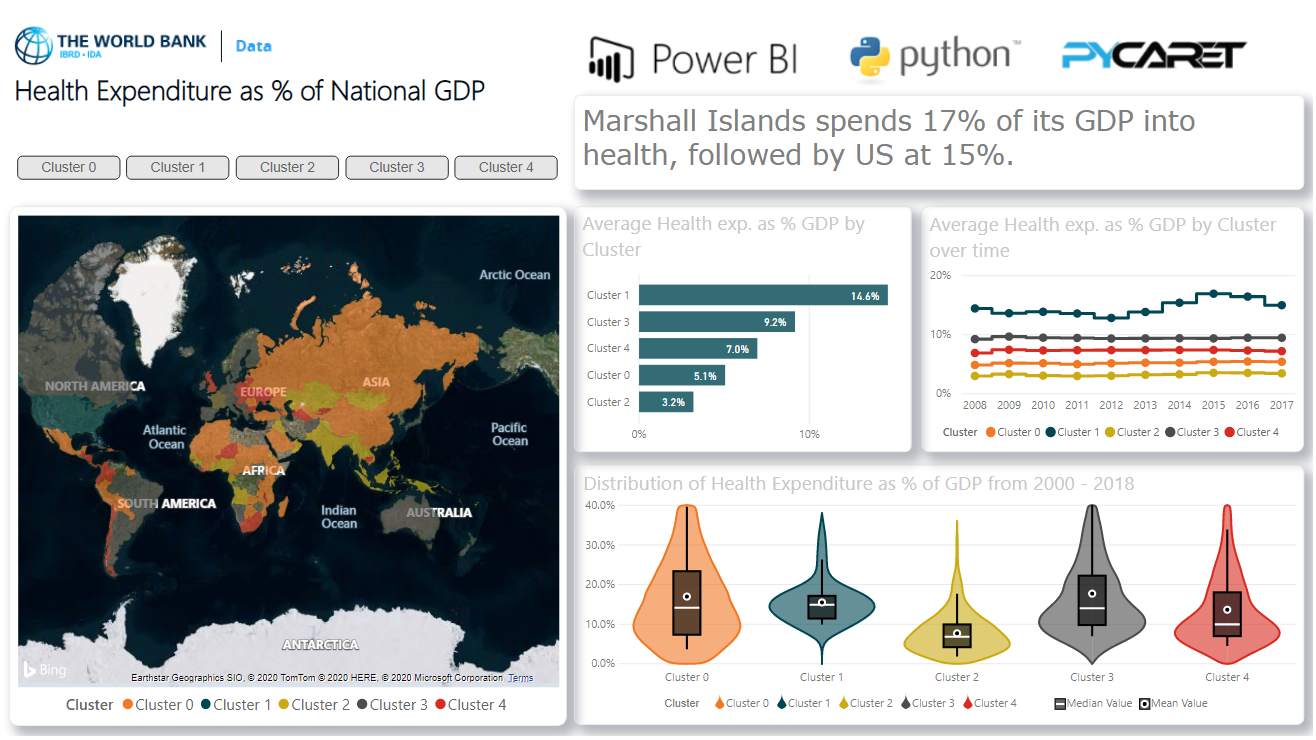
 você pode baixar o arquivo PBIX e o conjunto de dados do GitHub .
você pode baixar o arquivo PBIX e o conjunto de dados do GitHub .Implementação de Cluster
Acima, demonstramos a implementação de cluster mais simples no Power BI. Observo que esse método treina o modelo de clustering sempre que um conjunto de dados é atualizado no Power BI. Isso pode ser um problema pelos seguintes motivos:- Quando o modelo é treinado novamente nos novos dados, os rótulos do cluster podem mudar (ou seja, se alguns pontos de dados foram atribuídos anteriormente ao primeiro cluster, e quando treinados novamente, eles podem ser designados ao segundo cluster);
- Você não vai querer passar várias horas cada vez treinando novamente o modelo.
Uma maneira mais eficaz de implementar o clustering no Power BI em vez de reaprender repetidamente é usar um modelo pré-treinado para criar rótulos de cluster.Treinamento inicial do modelo
Você pode usar qualquer ambiente de desenvolvimento integrado (IDE) ou Notebook para treinar o modelo. Neste exemplo, treinamos o modelo de cluster no Visual Studio Code.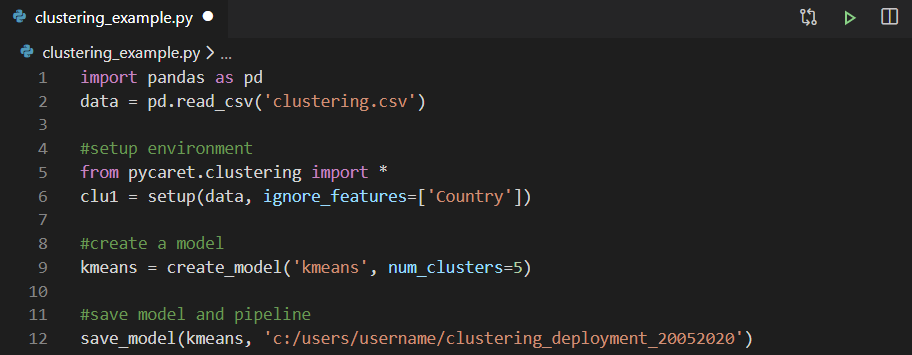 Em seguida, o modelo treinado é salvo como um arquivo de pickle e importado para o Power Query para gerar rótulos de cluster.
Em seguida, o modelo treinado é salvo como um arquivo de pickle e importado para o Power Query para gerar rótulos de cluster. Se você quiser saber mais sobre como implementar a análise de cluster no bloco de anotações Jupyter com PyCaret, assista a este vídeo de dois minutos.
Se você quiser saber mais sobre como implementar a análise de cluster no bloco de anotações Jupyter com PyCaret, assista a este vídeo de dois minutos.Usando o modelo pré-treinado
Execute o código abaixo para gerar tags do modelo pré-treinado:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
O resultado será o mesmo que observamos anteriormente. A única diferença é que, ao usar o modelo pré-treinado, as tags serão geradas com base no novo conjunto de dados usando o modelo antigo, e não no modelo que foi treinado novamente.Trabalhar com o serviço do Power BI
Depois de fazer o upload do arquivo .pbix no serviço do Power BI, você precisará seguir mais algumas etapas para garantir uma integração suave do pipeline de aprendizado de máquina no pipeline de dados. Os passos serão os seguintes:- Ative a atualização agendada do conjunto de dados - isso permitirá que você agende a pasta de trabalho com o conjunto de dados a ser atualizado usando um script Python; consulte a seção Configurando atualização agendada , que também contém informações sobre o Personal Gateway.
- Instale o Gateway pessoal - você precisará de um Gateway pessoal, que deve ser instalado no mesmo diretório em que o Python está instalado. O serviço do Power BI deve ter acesso ao ambiente Python. Aqui você pode aprender mais sobre como instalar e configurar o Personal Gateway.
Se você quiser saber mais sobre a análise de cluster, familiarize-se com o nosso guia neste caderno .
Entre no curso.