Durante toda a minha curta vida como programador de c #, pensei que o LINQ não fosse principalmente sobre o desempenho do código, mas sobre o desempenho do programador, a rapidez com que ele escreve o código e não a rapidez com que o processador executa esse código. E os problemas de desempenho do código e do programador são resolvidos após a identificação dos gargalos. Portanto, costumo escrever var groupedByDate = lst.GroupBy(item => item.IssueTime.Date).Select(…).ToList()e fazer isso não por causa de danos ou intenção maliciosa, mas é mais fácil depurar o código. Para a lista, basta colocar o cursor do mouse sobre o texto da variável e você poderá ver imediatamente se há algo lá ou não.
Começar
Depois de ler o artigo “Artigo mal sucedido sobre acelerar a reflexão ” e acalmar as emoções sobre “alguém está errado na Internet”, perguntei-me se seria possível fazer com que o código “LINQ to Objects” se aproximasse do “manual”. Por que exatamente o LINQ to Objects? No meu trabalho, geralmente uso apenas os provedores LINQ to Objects e LINQ to Entities. O desempenho do LINQ to Entities não é crítico para mim; é fundamental a otimização da consulta SQL gerada para o servidor de banco de dados de destino e a rapidez com que o servidor a executará.
Como base, decidi usar o projeto do autor do artigo. Em contraste com os exemplos da Internet, onde um código é comparado principalmente como integerList.Where(item => item > 5).Sum()um código “manual” que contém foreach, ife assim por diante, o exemplo do artigo parecia interessante e vital para mim.
A primeira coisa que fiz foi usar uma função de comparação de string única. No código-fonte, nos métodos que executam a mesma função, mas localizados em cantos opostos do anel, métodos diferentes são usados, em um caso variable0.Equals(constant0, StringComparison.InvariantCultureIgnoreCase)e em outro variable0.ToUpperInvariant() ==constant0.ToUpperInvariant(). É especialmente irritante para a constante que cada chamada de método é convertida para maiúscula. Eu escolhi a terceira opção usando nos dois casos variable0.ToUpperInvariant() ==constant0InUpperCaseInvariant.
Todo o código que não estava diretamente relacionado à comparação do desempenho do LINQ e do código manual foi jogado fora. O primeiro a ser capturado foi o código que cria e inicializa o objeto de classe Mock<HabraDbContext>. Qual é o sentido de criar uma conexão com o banco de dados para cada teste, uma vez é suficiente? Foi além dos testes de desempenho.
IStorage _db;
[GlobalSetup]
public void Setup()
{
_db = MockHelper.InstanceDb();
}
private IStorage DBInstance => _db;
… — , ! Linq «» !
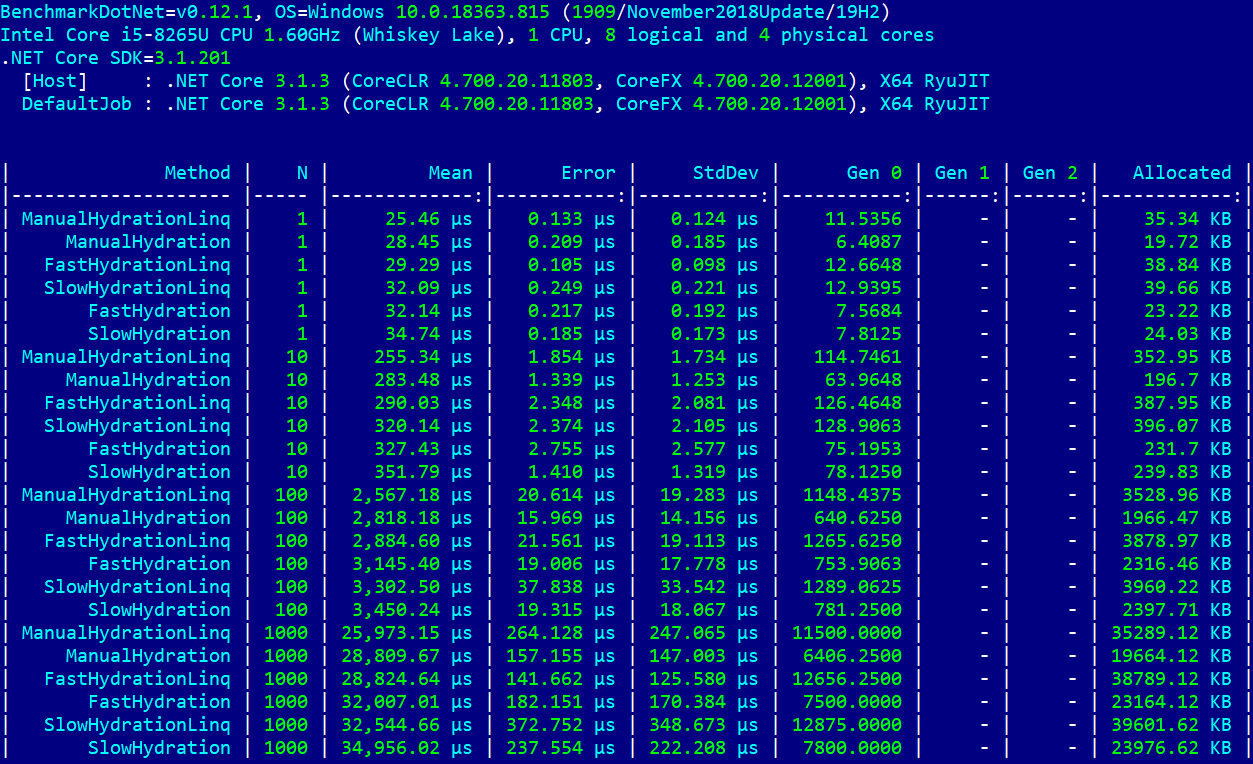
« - » . LINQ . , — .
, , LINQ vs «» . . . .
, , , ([Params(1, 10, 100, 1000)]). . . . StatisticColumnRelStdDev.
— FastHydrationLinq, ManualHydrationLinq — . , , (Fast)(Manual)(Slow)HydrationLinq vs (Fast)(Manual)(Slow)Hydration, ManualHydrationLinq. FastHydrationLinq - . .
ToArray, ToDictionary IEnumerable<T> . , FastContactHydrator2. - Action<Contact, string> c ConcurrentDictionary<string, Action<Contact, string>> IEnumerable<KeyValuePair<string, Action<Contact, string>>>. GetContact2, Sum, .
protected override Contact GetContact2(IEnumerable<PropertyToValueCorrelation> correlations)
{
var contact = new Contact();
int dummySum = _propertySettersArray.Join(correlations, propItem => propItem.Key, corrItem => corrItem.PropertyName, (prop, corr) => { prop.Value(contact, corr.Value); return 1; }).Sum();
return contact;
}
ParseWithLinq
public static IEnumerable<KeyValuePair<string, string>> ParseWithLinq2(string rawData, string keyValueDelimiter = ":", string pairDelimiter = ";")
=> rawData.Split(pairDelimiter)
.Select(x => x.Split(keyValueDelimiter, StringSplitOptions.RemoveEmptyEntries))
.Select(x => x.Length == 2 ? new KeyValuePair<string, string>(x[0].Trim(), x[1].Trim())
: new KeyValuePair<string, string>(_unrecognizedKey, x[0].Trim()));
.
FastContactHydrator2, , , , -, ( ParseWithLinq ParseWithoutLinq). . , , ToArray. 10 var result = new List<PropertyToValueCorrelation>(10). 10? 42 , 10 . Fair .
. . GetFakeData . , .
, , « » (RelStdDev). N=1000.
:
- `ManualHydration`, `SlowHydration`, `FastHydration`, `ManualHydrationLinq`, `SlowHydrationLinq`, `FastHydrationLinq` - , ;
ManualHydrationFair, ManualHydrationFairLinq, FastHydrationFairLinq — , ;FastHydrationLinq2 — , , - , LINQ;N , ;Ratio FastHydrationLinq2.
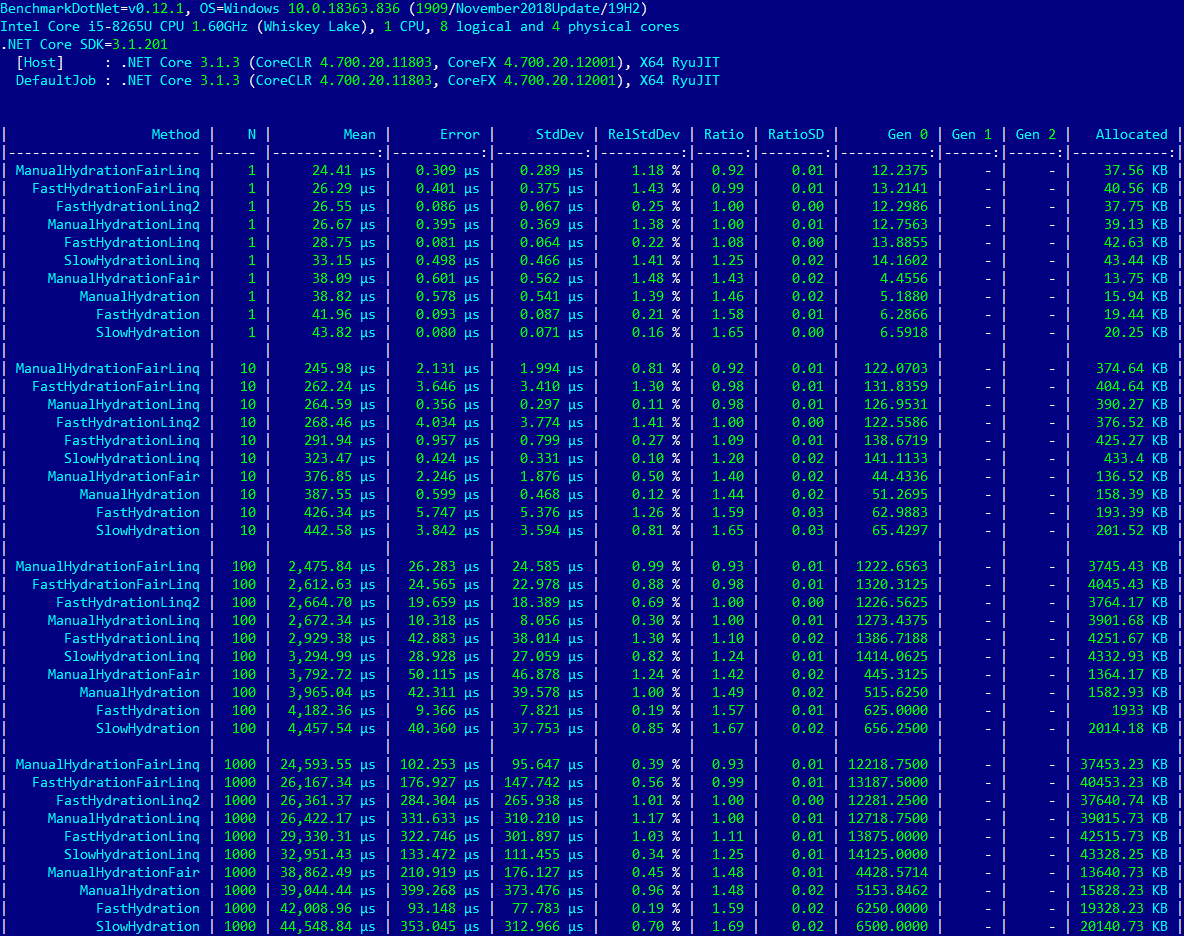
Linq-
? — FastHydrationLinq2 ManualHydrationLinq Ratio. 26,361.37 μs 26,422.17 μs N=1000. / N. ManualHydrationFairLinq, 8% , . FastHydrationFairLinq, 1% -.
Fair-. , ManualHydrationFairLinq 8% . FastHydrationFairLinq FastHydrationLinq 12%. Linq .
, . . , MockHelper.InstanceDb() Setup, . — , GetFakeData, . , — . MockHelper.InstanceDb() .
N, MakeGarbage. False , True — .
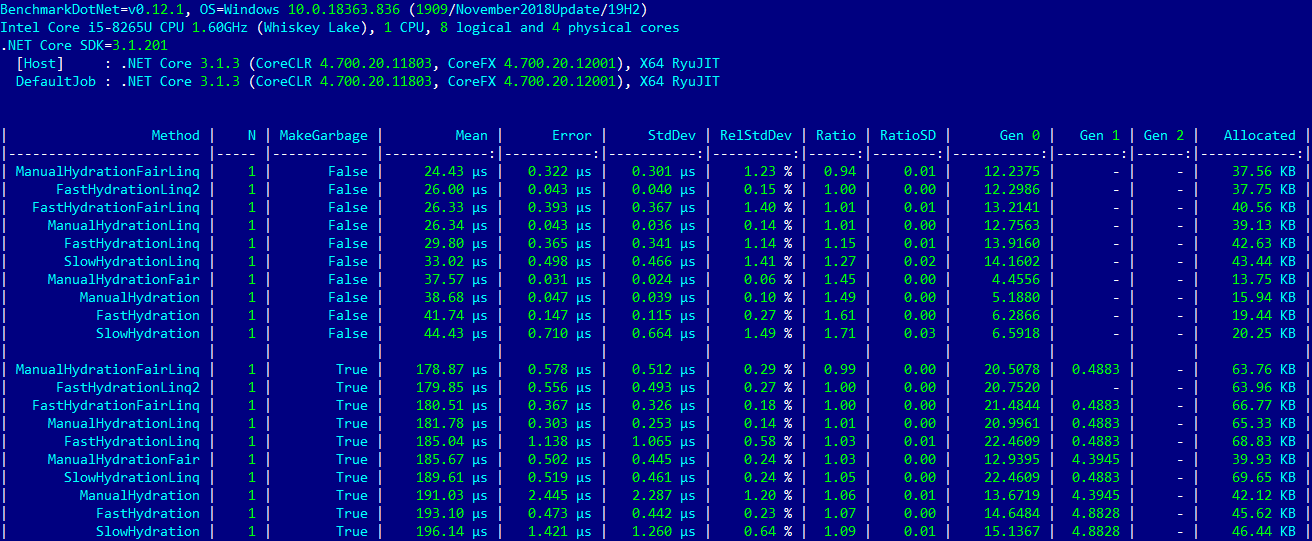
Voilà, , . — N=1. 10% 82% .
… .
, , «» — Linq-, :
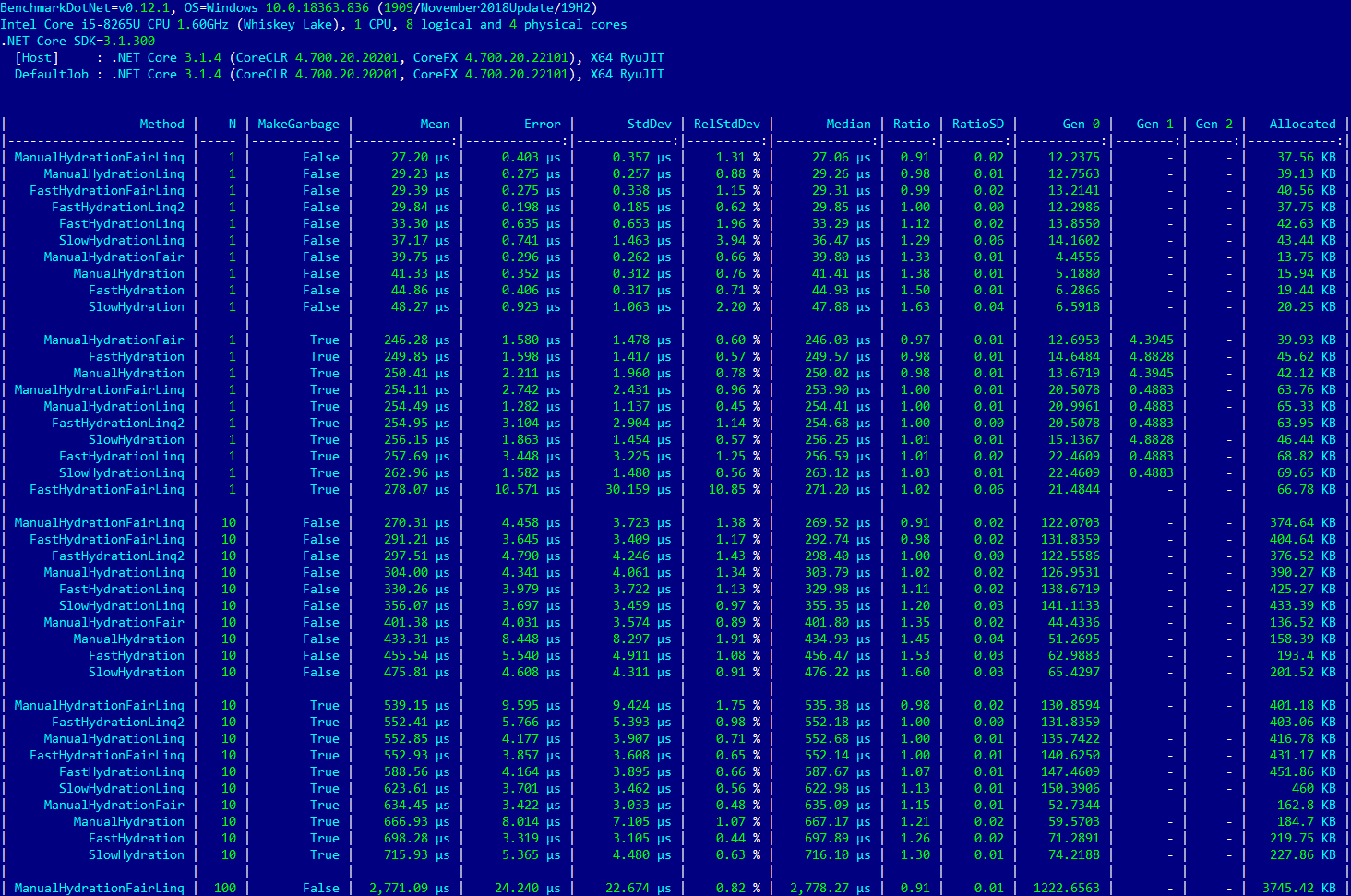
N=1 MakeGarbage=True «»
, , , LINQ .
«Gen X» «Allocated» N=1 MakeGarbage=True o , FastHydrationLinq2
| | Gen 0 | Gen 1 | Gen 2 | Allocated |
|«» | 20.5078 | 0.4883 | - | 63.95 KB |
|Linq- | 20.7520 | - | - | 63.69 KB |
ManualHydrationFairLinq .
. , , — .
, ? . , N [Params(1, 100)] MakeGargabe=True. «» — Linq-, . — , — Linq-, Linq — — — Linq. — . .
, , — Linq- . , . paint.net, . paint.net — paint.net . paint.net — «» , — Linq- .
— N 1, 10, 100, 1000 MakeGarbage [ParamsAllValues]. paint.net, — «» . — Linq- . paint.net Visual Studio — «» . , 80- . , Linq- 2%.
Depois de escrever os testes e analisar os resultados, minha opinião sobre o LINQ não mudou - usando-o, minha produtividade em escrever código é maior do que sem ele; O desempenho do LINQ to Objects está bom. Usar a execução atrasada do código LINQ como forma de melhorar o desempenho não faz muito sentido.
Se em um projeto houver problemas de desempenho devido ao coletor de lixo - a lesão de nascimento .net, provavelmente a escolha dessa tecnologia não seria a melhor solução.
Meu código de teste está disponível aqui .