Nota perev. : Embora esta revisão não pretenda ser o status de uma comparação técnica cuidadosamente desenvolvida de soluções existentes para o armazenamento permanente de dados no Kubernetes, ela pode ser um bom ponto de partida para os administradores relevantes para esse problema. Foi dada mais atenção à solução Pireu, familiaridade com a qual beneficiará não apenas os amantes de Linstor, mas também aqueles que nunca ouviram falar desses projetos. Esta é uma visão geral não científica das soluções de armazenamento para o Kubernetes. Declaração do problema: requer a capacidade de criar um Volume Persistente nos discos do nó, cujos dados serão salvos em caso de dano ou reinicialização do nó.A motivação para essa comparação é a necessidade de migrar a frota de servidores da empresa de vários servidores bare metal dedicados para o cluster Kubernetes.Minha empresa é uma startup brasileira Escavador com enormes necessidades de computação (principalmente CPU) e um orçamento muito limitado. Desenvolvemos soluções de PNL para estruturar dados legais.
Esta é uma visão geral não científica das soluções de armazenamento para o Kubernetes. Declaração do problema: requer a capacidade de criar um Volume Persistente nos discos do nó, cujos dados serão salvos em caso de dano ou reinicialização do nó.A motivação para essa comparação é a necessidade de migrar a frota de servidores da empresa de vários servidores bare metal dedicados para o cluster Kubernetes.Minha empresa é uma startup brasileira Escavador com enormes necessidades de computação (principalmente CPU) e um orçamento muito limitado. Desenvolvemos soluções de PNL para estruturar dados legais.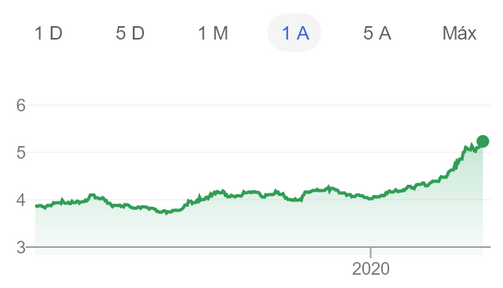 Devido à crise com o COVID-19, o real brasileiro caiu para um recorde em relação ao dólarNossa moeda nacional é realmente muito subestimada, portanto, o salário médio de um desenvolvedor sênior é de apenas 2000 USD por mês. Portanto, não podemos nos dar ao luxo de gastar quantias significativas em serviços em nuvem. Quando fiz os cálculos pela última vez, [graças ao uso de meus servidores], economizamos 75% em comparação com o que eu teria que pagar pela AWS. Em outras palavras, outro desenvolvedor pode ser contratado pelo dinheiro economizado - acho que esse é um uso muito mais racional dos fundos.Inspirado por uma série de publicações de Vito Botta, decidi criar um cluster K8s usando Rancher (e até agora tudo bem ...). Vito também realizou uma excelente análise de várias soluções de armazenamento. O vencedor claro foi Linstor (ele até o destacou emliga especial ). Spoiler: Eu concordo com ele.Há algum tempo que acompanho o tráfego em torno de Kubernetes, mas apenas recentemente decidi participar. Isso se deve principalmente ao fato de o provedor ter uma nova linha de processadores Ryzen. E fiquei muito surpreso ao ver que muitas soluções ainda estão em desenvolvimento ou em estado imaturo (especialmente para clusters de bare metal: virtualização de VM, MetalLB etc.). Os cofres do bare metal ainda estão em estágio maduro, embora sejam representados por uma infinidade de soluções comerciais e de código aberto. Decidi comparar as principais soluções promissoras e gratuitas (testando simultaneamente um produto comercial para entender o que estou perdendo). Gama de soluções de
Devido à crise com o COVID-19, o real brasileiro caiu para um recorde em relação ao dólarNossa moeda nacional é realmente muito subestimada, portanto, o salário médio de um desenvolvedor sênior é de apenas 2000 USD por mês. Portanto, não podemos nos dar ao luxo de gastar quantias significativas em serviços em nuvem. Quando fiz os cálculos pela última vez, [graças ao uso de meus servidores], economizamos 75% em comparação com o que eu teria que pagar pela AWS. Em outras palavras, outro desenvolvedor pode ser contratado pelo dinheiro economizado - acho que esse é um uso muito mais racional dos fundos.Inspirado por uma série de publicações de Vito Botta, decidi criar um cluster K8s usando Rancher (e até agora tudo bem ...). Vito também realizou uma excelente análise de várias soluções de armazenamento. O vencedor claro foi Linstor (ele até o destacou emliga especial ). Spoiler: Eu concordo com ele.Há algum tempo que acompanho o tráfego em torno de Kubernetes, mas apenas recentemente decidi participar. Isso se deve principalmente ao fato de o provedor ter uma nova linha de processadores Ryzen. E fiquei muito surpreso ao ver que muitas soluções ainda estão em desenvolvimento ou em estado imaturo (especialmente para clusters de bare metal: virtualização de VM, MetalLB etc.). Os cofres do bare metal ainda estão em estágio maduro, embora sejam representados por uma infinidade de soluções comerciais e de código aberto. Decidi comparar as principais soluções promissoras e gratuitas (testando simultaneamente um produto comercial para entender o que estou perdendo). Gama de soluções de armazenamento na CNCF LandscapeMas antes de tudo, quero avisar que sou novo nos K8s.Para experimentos, foram utilizados 4 trabalhadores com a seguinte configuração: processador Ryzen 3700X, memória ECC de 64 GB, tamanho NVMe 2 TB. Os benchmarks foram feitos usando a imagem
armazenamento na CNCF LandscapeMas antes de tudo, quero avisar que sou novo nos K8s.Para experimentos, foram utilizados 4 trabalhadores com a seguinte configuração: processador Ryzen 3700X, memória ECC de 64 GB, tamanho NVMe 2 TB. Os benchmarks foram feitos usando a imagem sotoaster/dbench:latest(em fio) com a bandeira O_DIRECT.Longhorn
Eu realmente gostei de Longhorn. É totalmente integrado ao Rancher e você pode instalá-lo através do Helm com um clique. Instalando o Longhorn a partir do RancherEsta é uma ferramenta de código aberto com o status de um projeto sandbox da Cloud Native Computing Foundation (CNCF). Seu desenvolvimento é financiado pela Rancher - uma empresa bastante bem-sucedida com um produto [homônimo] bem conhecido.
Instalando o Longhorn a partir do RancherEsta é uma ferramenta de código aberto com o status de um projeto sandbox da Cloud Native Computing Foundation (CNCF). Seu desenvolvimento é financiado pela Rancher - uma empresa bastante bem-sucedida com um produto [homônimo] bem conhecido. Uma excelente interface gráfica também está disponível - tudo pode ser feito a partir dela. Com desempenho, tudo está em ordem. O projeto ainda está na versão beta, o que é confirmado por problemas no GitHub.Ao testar, lancei uma referência usando duas réplicas e o Longhorn 0.8.0:
Uma excelente interface gráfica também está disponível - tudo pode ser feito a partir dela. Com desempenho, tudo está em ordem. O projeto ainda está na versão beta, o que é confirmado por problemas no GitHub.Ao testar, lancei uma referência usando duas réplicas e o Longhorn 0.8.0:- Leitura / gravação aleatória, IOPS: 28,2k / 16,2k;
- Largura de banda de leitura / gravação: 205 Mb / s / 108 Mb / s;
- Latência média de leitura / gravação (usec): 593,27 / 644,27;
- Leitura / gravação sequencial: 201 Mb / s / 108 Mb / s;
- Leitura / gravação aleatória mista, IOPS: 14,7k / 4904.
Openebs
Este projeto também possui o status da sandbox do CNCF. Com um grande número de estrelas no GitHub, parece uma solução muito promissora. Em sua análise, Vito Botta reclamou de desempenho insuficiente. Aqui está o que o CEO da Mayadata respondeu :As informações estão muito desatualizadas. O OpenEBS costumava oferecer suporte a 3, mas agora suporta 4 mecanismos, se você ativar o provisionamento dinâmico e a orquestração de PV local, que podem ser executadas na velocidade do NVMe. Além disso, o mecanismo MayaStor agora está aberto e já está recebendo críticas positivas (embora tenha status alfa).
Na página do projeto OpenEBS, existe uma explicação sobre seu status:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
Possui muitos mecanismos, e o último parece bastante promissor em termos de desempenho: “MayaStor - mecanismo alfa com NVMe sobre Fabrics”. Infelizmente, eu não testei por causa do status da versão alfa.Nos testes, a versão 1.8.0 foi usada no mecanismo jiva. Além disso, eu verifiquei anteriormente o cStor, mas não salvei os resultados, que, no entanto, acabaram sendo um pouco mais lentos que o jiva. Para o benchmark, um gráfico Helm foi instalado com todas as configurações padrão e a Classe de Armazenamento, criada padrão por Helm ( openebs-jiva-default), foi usada. O desempenho acabou sendo a pior de todas as soluções consideradas (eu agradeceria por conselhos sobre como aprimorá-lo).OpenEBS 1.8.0 com mecanismo jiva (3 réplicas?):- Leitura / gravação aleatória, IOPS: 2182/1527;
- Largura de banda de leitura / gravação: 65,0 Mb / s / 41,9 Mb / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
Esta é uma solução comercial gratuita ao usar até 110 GB de espaço. Uma licença de desenvolvedor gratuita pode ser obtida registrando-se através da interface do usuário do produto; Dá até 500 GB de espaço. No Rancher, ele é listado como parceiro, portanto, a instalação usando o Helm foi fácil e despreocupada.É oferecido ao usuário um painel de controle básico. Os testes deste produto foram limitados por serem comerciais e não nos atenderem em valor. Mas ainda queria ver do que os projetos comerciais são capazes.O teste usa a classe de armazenamento existente chamada "Rápida" (Modelo 0.2.19, 1 réplica mestre + 0?). Os resultados foram surpreendentes. Eles excederam significativamente as soluções anteriores.- Leitura / gravação aleatória, IOPS: 117k / 90.4k;
- Largura de banda de leitura / gravação: 2124 Mb / s / 457 Mb / s;
- Latência média de leitura / gravação (usec): 63,44 / 86,52;
- Leitura / gravação sequencial: 1907 Mb / s / 448 Mb / s;
- Leitura / gravação aleatória mista, IOPS: 81,9k / 27,3k.
Pireu (baseado em Linstor)
Licença: GPLv3O já mencionado Vito Botta acabou por se instalar no Linstor, que foi mais um motivo para tentar esta solução. À primeira vista, o projeto parece bastante estranho. Quase não há estrelas no GitHub, um nome incomum e ele nem existe no CNCF Landscape. Mas, após uma inspeção mais minuciosa, nem tudo é tão assustador, porque:- O DRBD é usado como o mecanismo básico de replicação (de fato, foi desenvolvido pelas mesmas pessoas). Ao mesmo tempo, o DRBD 8.x faz parte do kernel oficial do Linux há mais de 10 anos. E estamos falando de tecnologia aperfeiçoada há mais de 20 anos.
- A mídia é controlada pela LINSTOR, também uma tecnologia madura da mesma empresa. A primeira versão do Linstor-server apareceu no GitHub em fevereiro de 2018. É compatível com várias tecnologias / sistemas como Proxmox, OpenNebula e OpenStack.
- Aparentemente, a Linbit está desenvolvendo ativamente o projeto, constantemente introduzindo novos recursos e melhorias nele. A 10ª versão do DRBD ainda possui status alfa , mas já possui alguns recursos exclusivos, como codificação de apagamento (análoga à funcionalidade do RAID5 / 6 - aprox. Transl.) .
- A empresa toma certas medidas para se tornar um dos projetos da CNCF.
Ok, o projeto parece convincente o suficiente para confiar a ele seus dados preciosos. Mas ele é capaz de reproduzir alternativas? Vamos dar uma olhada.Instalação
Vito fala sobre a instalação do Linstor aqui . No entanto, nos comentários, um dos desenvolvedores do Linstor recomenda um novo projeto chamado Pireu. Pelo que entendi, o Pireu está se tornando o projeto Linbit Open Source, que combina tudo relacionado aos K8s. A equipe está trabalhando no operador apropriado , mas, por enquanto, o Piraeus pode ser instalado usando este arquivo YAML:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
Atenção! Você pega as configurações do meu repositório pessoal. Confira o repositório oficial! Atualizei a versão das imagens para resolver o erro que ocorre ao usar no Ubuntu.O repositório oficial do Pireu está disponível aqui .Você também pode usar o repositório kvaps (parece ainda mais dinâmico que o repositório oficial pireu): https://github.com/kvaps/kube-linstor (aproveite a oportunidade para dizer olá a Andreykvaps- Aproximadamente. perev.) . Todos os nós funcionam após a instalação
Todos os nós funcionam após a instalaçãoAdministração
A administração é realizada usando a linha de comando. O acesso a ele é possível a partir do shell de comando do nó piraeus-controller. O nó do controlador está executando o linstor-server. É uma camada de abstração sobre drbd, capaz de gerenciar toda a frota de nós. A captura de tela abaixo mostra alguns comandos úteis para as tarefas mais populares, por exemplo:
O nó do controlador está executando o linstor-server. É uma camada de abstração sobre drbd, capaz de gerenciar toda a frota de nós. A captura de tela abaixo mostra alguns comandos úteis para as tarefas mais populares, por exemplo:linstor node list - exibe uma lista de nós conectados e seu status;linstor volume list - mostra uma lista de volumes criados e sua localização;linstor node info - mostre os recursos de cada nó.
 Comandos do Linstor Umalista completa de comandos está disponível na documentação oficial: Guia do usuário LINSTOR .No caso de situações como cérebro dividido, o drbd pode ser acessado diretamente através dos nós.
Comandos do Linstor Umalista completa de comandos está disponível na documentação oficial: Guia do usuário LINSTOR .No caso de situações como cérebro dividido, o drbd pode ser acessado diretamente através dos nós.Recuperação de desastre
Fiz o meu melhor para eliminar meu cluster, incluindo redefinição física nos nós. Mas Linstor era surpreendentemente tenaz.Drbd reconhece perfeitamente um problema chamado cérebro dividido. Na minha situação, o nó secundário caiu da replicação.Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
Detalhes podem ser encontrados na documentação oficial do drbd . O nó secundário caiu de replicação.Nomeu caso, para resolver o problema, eu soltei os dados secundários e iniciei a sincronização com o nó principal. Como eu prefiro interfaces gráficas, usei o utilitário drbdtop para isso. Com sua ajuda, você pode monitorar visualmente o status e executar comandos nos nós.Eu precisava entrar no console nos piraues do nó com problema (era
O nó secundário caiu de replicação.Nomeu caso, para resolver o problema, eu soltei os dados secundários e iniciei a sincronização com o nó principal. Como eu prefiro interfaces gráficas, usei o utilitário drbdtop para isso. Com sua ajuda, você pode monitorar visualmente o status e executar comandos nos nós.Eu precisava entrar no console nos piraues do nó com problema (era worker2-gpu): Vá para o nóLá eu instalei o drdbtop. Faça o download deste utilitário aqui:
Vá para o nóLá eu instalei o drdbtop. Faça o download deste utilitário aqui:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 Executando o utilitário drbdtopDê uma olhada no painel inferior. Existem comandos nele que podem ser usados para corrigir o cérebro dividido:
Executando o utilitário drbdtopDê uma olhada no painel inferior. Existem comandos nele que podem ser usados para corrigir o cérebro dividido: depois disso, os nós são conectados e sincronizados automaticamente.
depois disso, os nós são conectados e sincronizados automaticamente.Como aumentar a velocidade?
Por padrão, o Piraeus / Linstor / drbd mostra um excelente desempenho (você pode ver isso abaixo). As configurações padrão são razoáveis e seguras. No entanto, a velocidade de gravação foi bastante fraca. Como os servidores no meu caso estão espalhados por diferentes datacenters (embora fisicamente estejam relativamente próximos), decidi tentar ajustar o desempenho deles.O ponto de partida para otimização é definir um protocolo de replicação. Por padrão, o Protocolo C é usado, que aguarda confirmação de gravação no nó secundário remoto. A seguir, é apresentada uma descrição dos possíveis protocolos:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
Por esse motivo, no Linstor, também uso o protocolo assíncrono (ele suporta replicação síncrona / semi-síncrona / assíncrona). Você pode habilitá-lo com o seguinte comando:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
O resultado de sua implementação será a ativação do protocolo assíncrono e um aumento no buffer de até 1 MB. É relativamente seguro. Ou você pode usar o seguinte comando (ele ignora as descargas de disco e aumenta significativamente o buffer):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
Observe que, se o nó principal falhar, uma pequena parte dos dados poderá não alcançar as réplicas.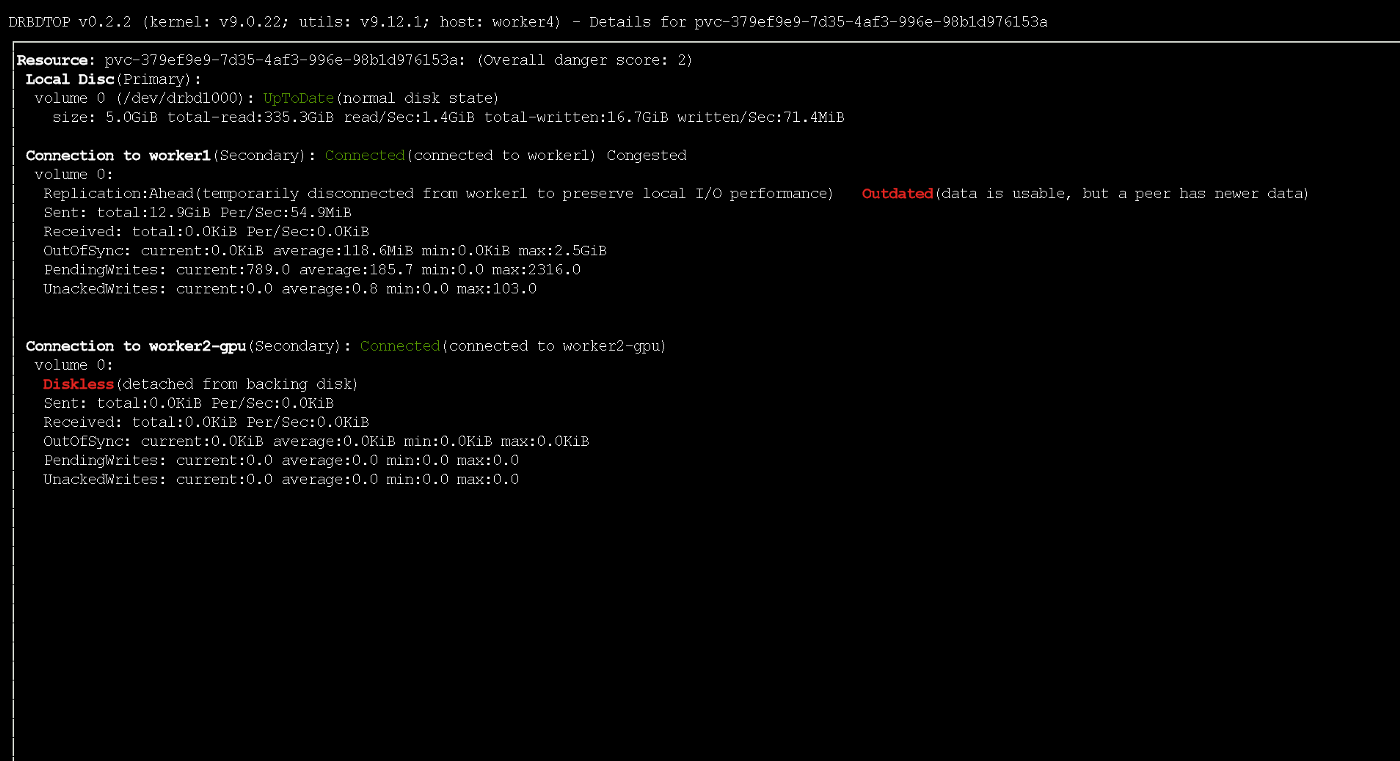 Durante a gravação ativa, o nó recebeu temporariamente o status desatualizado usando o protocolo ASYNC
Durante a gravação ativa, o nó recebeu temporariamente o status desatualizado usando o protocolo ASYNCTeste
Todos os benchmarks foram conduzidos usando o seguinte Job:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
O atraso entre as máquinas é a seguinte: ttl=61 time=0.211 ms. A taxa de transferência medida entre eles foi de 943 Mbps. Todos os nós estão executando o Ubuntu 18.04. Resultados ( tabela em sheetsu.com )
Como pode ser visto na tabela, o Piraeus e o StorageOS apresentaram os melhores resultados. O líder era Pireu com duas réplicas e um protocolo assíncrono.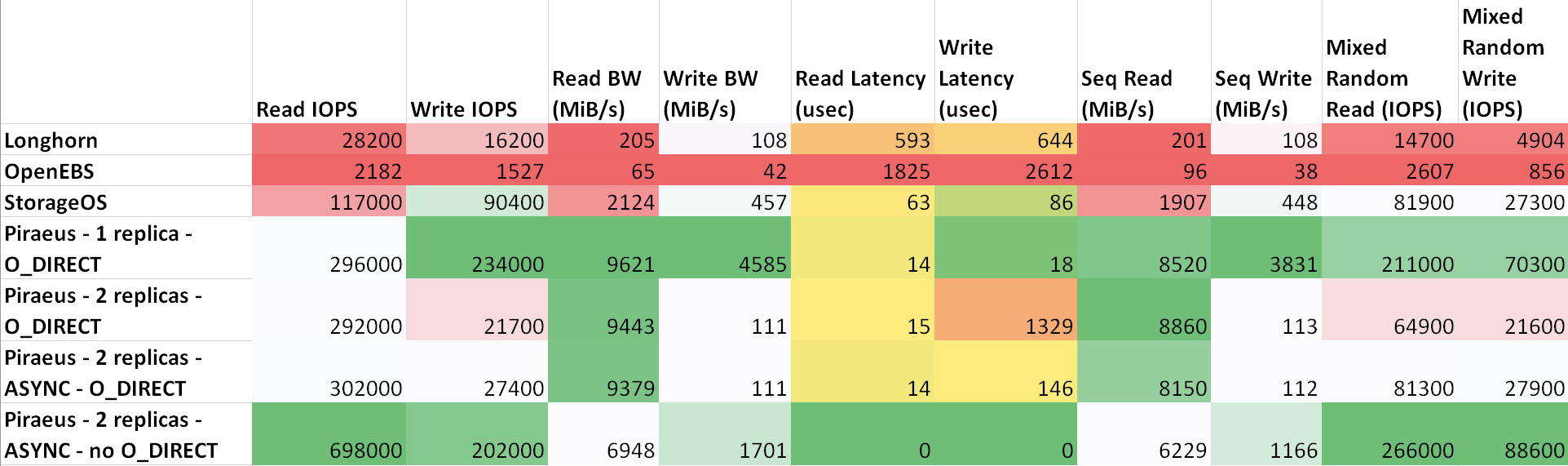
achados
Fiz uma comparação simples e talvez não muito correta de algumas soluções de armazenamento no Kubernetes.Acima de tudo, gostei do Longhorn por causa de sua boa interface gráfica e integração com o Rancher. No entanto, os resultados não são inspiradores. Obviamente, os desenvolvedores se concentram principalmente na segurança e correção, deixando a velocidade para mais tarde.Já faz algum tempo que uso o Linstor / Piraeus nos ambientes de produção de alguns projetos. Até agora, tudo estava bem: discos foram criados e excluídos, nós foram reiniciados sem tempo de inatividade ...Na minha opinião, o Pireu está pronto para uso na produção, mas precisa ser aprimorado. Eu escrevi sobre alguns bugs no canal do projeto no Slack, mas em resposta eles só me aconselharam a ensinar Kubernetes (e isso está correto, pois ainda não o entendo bem). Após uma pequena correspondência, eu ainda consegui convencer os autores de que havia um erro no script init. Ontem, após atualizar o kernel e reiniciar, o nó se recusou a inicializar. Aconteceu que a compilação do script que integra o módulo drbd ao kernel falhou . A reversão para a versão anterior do kernel resolveu o problema.Isso é tudo, em geral. Dado que eles o implementaram sobre o drbd, ele se mostrou uma solução muito confiável e com excelente desempenho. Em caso de problemas, você pode entrar em contato diretamente com o gerenciamento drbd e corrigi-lo. Na Internet, existem muitas perguntas e exemplos sobre esse tópico.Se fiz algo errado, se algo pode ser melhorado ou se você precisar de ajuda, entre em contato comigo no Twitter ou no GitHub .PS do tradutor
Leia também em nosso blog: