Em um artigo anterior, onde falei sobre o monitoramento de um banco de dados PostgreSQL , havia uma frase:Crescer wait- o aplicativo "descansou" nos bloqueios de alguém . Se esta é uma anomalia única no passado - uma ocasião para entender o motivo original.
Essa situação é uma das mais desagradáveis para o DBA:- à primeira vista, a base está funcionando
- nenhum recurso do servidor está esgotado
- ... mas alguns dos pedidos "abrandam"
 As chances de capturar os bloqueios “no momento” são extremamente pequenas e podem durar apenas alguns segundos, mas piorando o tempo de execução planejado da solicitação dezenas de vezes. Mas você não quer ficar sentado vendo o que está acontecendo on-line, mas em um ambiente calmo para descobrir depois do fato de
As chances de capturar os bloqueios “no momento” são extremamente pequenas e podem durar apenas alguns segundos, mas piorando o tempo de execução planejado da solicitação dezenas de vezes. Mas você não quer ficar sentado vendo o que está acontecendo on-line, mas em um ambiente calmo para descobrir depois do fato de quais desenvolvedores punir qual exatamente era o problema - quem, com quem e por qual recurso do banco de dados entrou em conflito.Mas como? De fato, diferentemente da solicitação com seu plano, que permite entender em detalhes o que os recursos levaram e quanto tempo levou, a trava não deixa rastros tão óbvios ...A menos que uma pequena entrada de log: mas vamos tentar pegá-la!process ... still waiting for ...
Pegamos a fechadura no log
Mas mesmo para que pelo menos essa linha apareça no log, o servidor deve estar configurado corretamente:log_lock_waits = 'on'
... e defina uma borda mínima para nossa análise:deadlock_timeout = '100ms'
Quando o parâmetro está ativado log_lock_waits, este parâmetro também determina após o horário em que as mensagens sobre a espera pelo bloqueio serão gravadas no log do servidor. Se você está tentando investigar os atrasos causados pelos bloqueios, faz sentido reduzi-lo em comparação com o valor usual deadlock_timeout.
Todos os impasses que não tiverem tempo para "desatar" durante esse período serão rasgados. E aqui estão os bloqueios "usuais" - despejados no log por várias entradas:2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest DETAIL: Process holding the lock: 38154. Wait queue: 38162.
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest CONTEXT: SQL statement "SELECT pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer )"
PL/pgSQL function inline_code_block line 2 at PERFORM
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest STATEMENT: DO $$ BEGIN
PERFORM pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer );
EXCEPTION
WHEN query_canceled THEN RETURN;
END; $$;
…
2019-03-27 00:06:46.077 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms
Este exemplo mostra que tínhamos apenas 50ms desde o momento em que o bloqueio apareceu no log até o momento de sua resolução. Somente nesse intervalo podemos obter pelo menos algumas informações sobre o assunto, e quanto mais rápido formos capazes de fazer isso, mais bloqueios poderemos analisar.Aqui, a informação mais importante para nós é o PID do processo que está aguardando o bloqueio. É nele que podemos comparar as informações entre o log e o estado do banco de dados. E, ao mesmo tempo, para descobrir o quão problemático era um bloqueio específico - ou seja, quanto tempo "travou".Para fazer isso, precisamos apenas de alguns RegExp no LOGregistro de conteúdo :const RE_lock_detect = /^process (\d+) still waiting for (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
const RE_lock_acquire = /^process (\d+) acquired (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
Chegamos ao log
Na verdade, resta um pouco - pegar o log, aprender a monitorá-lo e responder de acordo.Já temos tudo para isso - um analisador de log on-line e uma conexão de banco de dados pré-ativada, sobre a qual falei em um artigo sobre o nosso sistema de monitoramento PostgreSQL :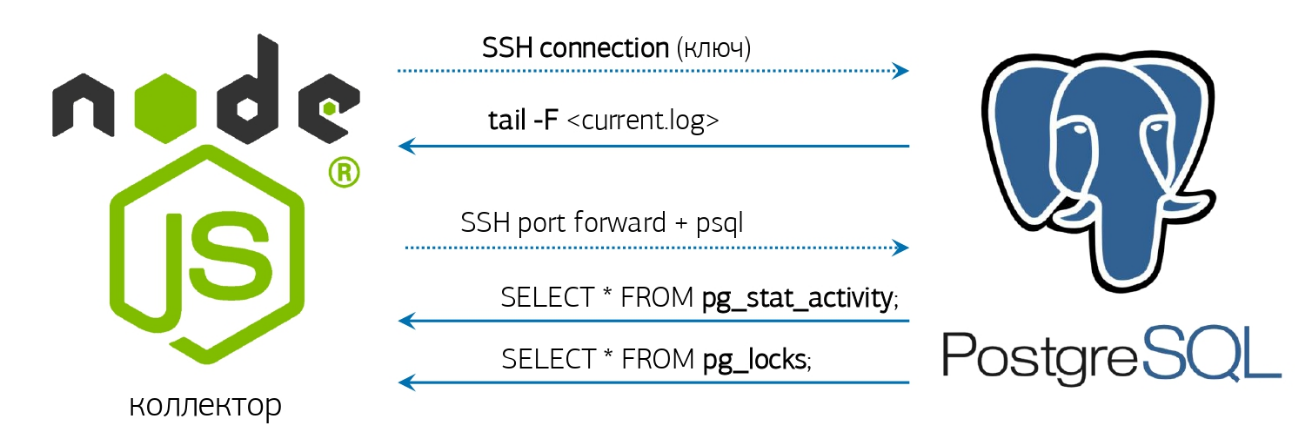 mas se você não tiver um sistema semelhante implantado, tudo bem, faremos tudo "Desde o console"!Se a versão instalada do PostgreSQL 10 e superior tiver sorte, porque apareceu a função pg_current_logfile () , que explicitamente fornece o nome do arquivo de log atual. Obtê-lo no console será fácil:
mas se você não tiver um sistema semelhante implantado, tudo bem, faremos tudo "Desde o console"!Se a versão instalada do PostgreSQL 10 e superior tiver sorte, porque apareceu a função pg_current_logfile () , que explicitamente fornece o nome do arquivo de log atual. Obtê-lo no console será fácil:psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) <> '/' THEN current_setting('data_directory') ELSE '' END || '/' || pg_current_logfile()"
Se a versão for subitamente mais jovem - tudo vai acabar, mas um pouco mais complicado:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}'
Nós tail -fobtemos o nome completo do arquivo, que cedemos e apresentará a aparência lá 'still waiting for'.Bem, assim que algo surgiu nesta discussão, chamamos ...Pedido de análise
Infelizmente, o objetivo de bloquear o log não é de forma alguma o recurso que causou o conflito. Por exemplo, se você tentar criar um índice com o mesmo nome em paralelo, haverá apenas algo assim no log still waiting for ExclusiveLock on transaction 12345.Portanto, teremos que remover o estado de todos os bloqueios do banco de dados para o processo de seu interesse. E informações apenas sobre um par de processos (que bloqueiam / que esperam) não são suficientes, porque geralmente há uma "cadeia" de expectativas de diferentes recursos entre transações:tx1 [resA] -> tx2 [resA]
tx2 [resB] -> tx3 [resB]
...
Clássico: “Avô por nabo, avó por avô, neta por avó, ...”Portanto, escreveremos uma solicitação que nos dirá exatamente quem se tornou a causa raiz dos problemas em toda a cadeia de bloqueios para um PID específico:WITH RECURSIVE lm AS (
SELECT
rn
, CASE
WHEN lm <> 'Share' THEN row_number() OVER(PARTITION BY lm <> 'Share' ORDER BY rn)
END rx
, lm || 'Lock' lm
FROM (
SELECT
row_number() OVER() rn
, lm
FROM
unnest(
ARRAY[
'AccessShare'
, 'RowShare'
, 'RowExclusive'
, 'ShareUpdateExclusive'
, 'Share'
, 'ShareRowExclusive'
, 'Exclusive'
, 'AccessExclusive'
]
) T(lm)
) T
)
, lt AS (
SELECT
row_number() OVER() rn
, lt
FROM
unnest(
ARRAY[
'relation'
, 'extend'
, 'page'
, 'tuple'
, 'transactionid'
, 'virtualxid'
, 'object'
, 'userlock'
, 'advisory'
, ''
]
) T(lt)
)
, lmx AS (
SELECT
lr.rn lrn
, lr.rx lrx
, lr.lm lr
, ld.rn ldn
, ld.rx ldx
, ld.lm ld
FROM
lm lr
JOIN
lm ld ON
ld.rx > (SELECT max(rx) FROM lm) - lr.rx OR
(
(lr.rx = ld.rx) IS NULL AND
(lr.rx, ld.rx) IS DISTINCT FROM (NULL, NULL) AND
ld.rn >= (SELECT max(rn) FROM lm) - lr.rn
)
)
, lcx AS (
SELECT DISTINCT
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
pg_locks ld
JOIN
pg_locks lr ON
lr.pid <> ld.pid AND
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) IS NOT DISTINCT FROM (ld.locktype, ld.database, ld.relation, ld.page, ld.tuple, ld.virtualxid, ld.transactionid::text::bigint, ld.classid, ld.objid, ld.objsubid) AND
(lr.granted, ld.granted) = (TRUE, FALSE)
JOIN
lmx ON
(lmx.lr, lmx.ld) = (lr.mode, ld.mode)
WHERE
(ld.pid, ld.granted) = ($1::integer, FALSE)
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN ARRAY[relation::text]
WHEN 'extend' THEN ARRAY[relation::text]
WHEN 'page' THEN ARRAY[relation, page]::text[]
WHEN 'tuple' THEN ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN ARRAY[transactionid::text]
WHEN 'virtualxid' THEN regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN ARRAY[classid::text]
WHEN 'advisory' THEN ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp "locked"
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, (lc.locktype, lc.database, lc.relation, lc.page, lc.tuple, lc.virtualxid, lc.transactionid::text::bigint, lc.classid, lc.objid, lc.objsubid) IS NOT DISTINCT FROM lcx.target "conflict"
FROM
lcx
JOIN
pg_locks lc ON
lc.pid IN (lcx.ldp, lcx.lrp);
Problema # 1 - Início lento
Como você pode ver no exemplo do log, ao lado da linha que sinaliza a ocorrência de um bloqueio ( LOG), há mais 3 linhas ( DETAIL, CONTEXT, STATEMENT) relatando informações estendidas.Primeiro, esperamos a formação de um "pacote" completo de todas as 4 entradas e somente depois voltamos ao banco de dados. Porém, podemos concluir a formação do pacote somente quando o próximo registro (já em 5º!) Chegar, com os detalhes de outro processo ou por tempo limite. É claro que ambas as opções provocam espera desnecessária.Para se livrar desses atrasos, passamos a processar o fluxo de registros de bloqueio. Ou seja, agora voltamos para o banco de dados de destino assim que classificamos o primeiro registro e percebemos que era o bloqueio descrito lá.Problema # 2 - solicitação lenta
Mas, ainda assim, alguns dos bloqueios não tiveram tempo para serem analisados. Eles começaram a ir mais fundo - e descobriram que em alguns servidores nossa solicitação de análise é executada por 15 a 20 ms !O motivo acabou sendo comum - o número total de bloqueios ativos na base, chegando a vários milhares: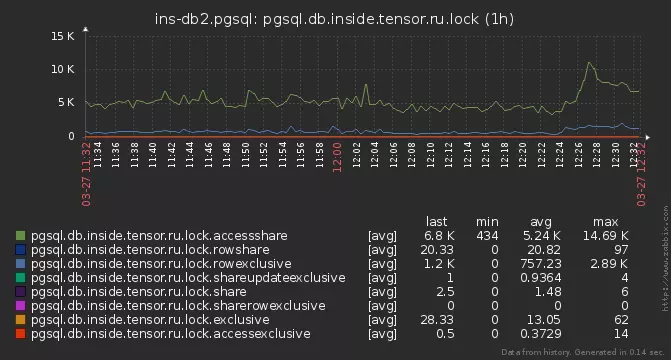
pg_locks
Aqui deve-se notar que os bloqueios no PostgreSQL não são "armazenados" em lugar algum, mas são apresentados apenas na visualização do sistema pg_locks , que é um reflexo direto da função pg_lock_status. E em nosso pedido , lemos três vezes ! Enquanto isso, lemos esses milhares de instâncias de bloqueios e descartamos aqueles que não estão relacionados ao nosso PID, o próprio bloqueio conseguiu "resolver" ... Asolução foi "materializar" o estado de pg_locks no CTE - depois disso, você pode executá-lo quantas vezes quiser, já não muda. Além disso, depois de se sentar no algoritmo, era possível reduzir tudo para apenas duas de suas varreduras.Dinâmica Excessiva
E se mesmo um olhar mais de perto a consulta acima, podemos ver que o CTE lme lmxnão de qualquer maneira vinculada aos dados, mas simplesmente calcular sempre a mesma definição de matriz "estático" de conflito entre os modos de bloqueio . Então, vamos defini-lo como uma qualidade VALUES.Problema # 3 - vizinhos
Mas parte das fechaduras ainda foram puladas. Geralmente, isso acontecia de acordo com o esquema a seguir - alguém bloqueou um recurso popular e vários processos foram rapidamente encontrados rapidamente ou ao longo de uma cadeia .Como resultado, pegamos o primeiro PID, fomos para a base de destino (e, para não sobrecarregá-lo, mantemos apenas uma conexão), fizemos a análise, retornamos com o resultado, pegamos o próximo PID ... Mas a vida não vale a pena na base e o PID trava # 2 já se foi!Na verdade, por que precisamos ir ao banco de dados para cada PID separadamente, se ainda filtramos os bloqueios da lista geral na solicitação? Vamos pegar imediatamente toda a lista de processos conflitantes diretamente do banco de dados e distribuir seus bloqueios por todos os PIDs que caíram durante a execução da solicitação:WITH lm(ld, lr) AS (
VALUES
('AccessShareLock', '{AccessExclusiveLock}'::text[])
, ('RowShareLock', '{ExclusiveLock,AccessExclusiveLock}'::text[])
, ('RowExclusiveLock', '{ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareUpdateExclusiveLock', '{ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareRowExclusiveLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ExclusiveLock', '{RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('AccessExclusiveLock', '{AccessShareLock,RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
)
, locks AS (
SELECT
(
locktype
, database
, relation
, page
, tuple
, virtualxid
, transactionid::text::bigint
, classid
, objid
, objsubid
) target
, *
FROM
pg_locks
)
, ld AS (
SELECT
*
FROM
locks
WHERE
NOT granted
)
, lr AS (
SELECT
*
FROM
locks
WHERE
target::text = ANY(ARRAY(
SELECT DISTINCT
target::text
FROM
ld
)) AND
granted
)
, lcx AS (
SELECT DISTINCT
lr.target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
ld
JOIN
lr
ON lr.pid <> ld.pid AND
lr.target IS NOT DISTINCT FROM ld.target
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN
ARRAY[relation::text]
WHEN 'extend' THEN
ARRAY[relation::text]
WHEN 'page' THEN
ARRAY[relation, page]::text[]
WHEN 'tuple' THEN
ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN
ARRAY[transactionid::text]
WHEN 'virtualxid' THEN
regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN
ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN
ARRAY[classid::text]
WHEN 'advisory' THEN
ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp as locked
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, lc.target IS NOT DISTINCT FROM lcx.target as conflict
FROM
lcx
JOIN
locks lc
ON lc.pid IN (lcx.ldp, lcx.lrp);
Agora temos tempo para analisar até os bloqueios que existem apenas 1 a 2 ms depois de entrar no log.Analise isso
Na verdade, por que tentamos tanto tempo? O que isso nos dá como resultado? ..type | target | locked | pid | mode | granted | conflict
---------------------------------------------------------------------------------------
relation | {225388639} | f | 216547 | AccessShare | t | f
relation | {423576026} | f | 216547 | AccessShare | t | f
advisory | {225386226,194303167,2} | t | 24964 | Exclusive | f | t
relation | {341894815} | t | 24964 | AccessShare | t | f
relation | {416441672} | f | 216547 | AccessShare | t | f
relation | {225964322} | f | 216547 | AccessShare | t | f
...
Nesta placa, valores targetcom um tipo são úteis para nós relation, porque cada um desses valores é um OID de uma tabela ou índice . Agora, resta muito pouco - aprender como interrogar o banco de dados para OIDs ainda desconhecidos para nós, a fim de traduzi-los para uma forma legível por humanos:SELECT $1::oid::regclass;
Agora, conhecendo a “matriz” completa de bloqueios e todos os objetos nos quais eles foram sobrepostos por cada uma das transações, podemos concluir “o que aconteceu” e qual recurso causou o conflito, mesmo que a solicitação tenha sido bloqueada, não éramos conhecidos. Isso pode acontecer facilmente, por exemplo, quando o tempo de execução de uma solicitação de bloqueio não é longo o suficiente para acessar o log, mas a transação estava ativa após sua conclusão e criava problemas por um longo tempo.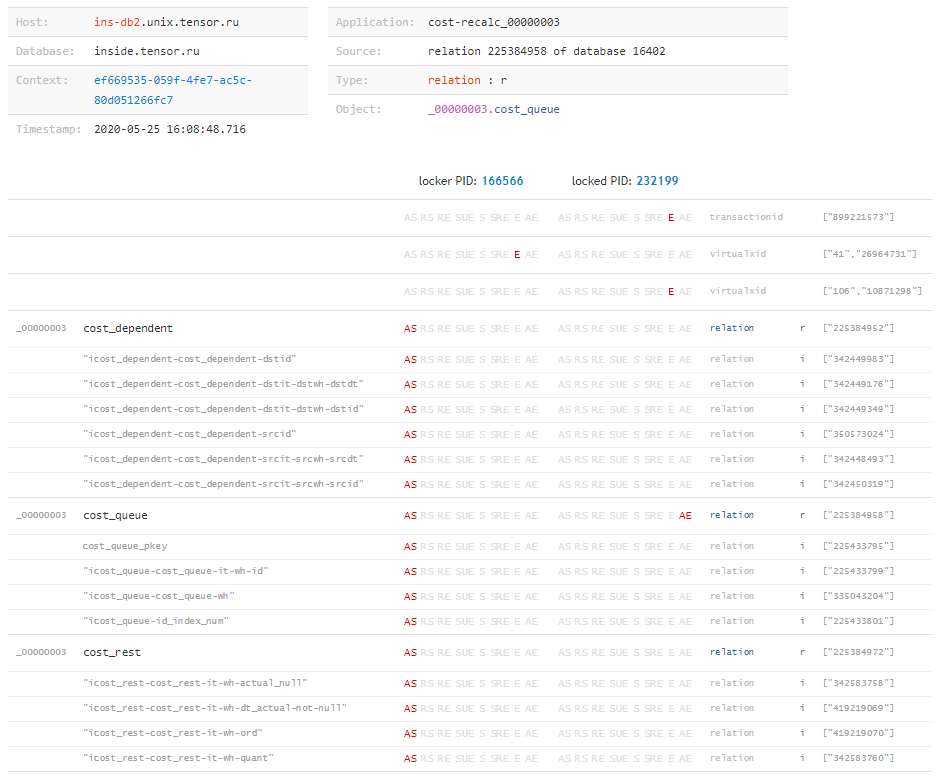 Mas sobre isso - em outro artigo.
Mas sobre isso - em outro artigo."Sozinho"
Enquanto isso, coletaremos a versão completa do "monitoramento", que removerá automaticamente o status dos bloqueios do nosso arquivo assim que algo suspeito aparecer no log:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}' \
| xargs -l -I{} tail -f {} \
| stdbuf -o0 grep 'still waiting for' \
| xargs -l -I{} date '+%Y%m%d-%H%M%S.%N' \
| xargs -l -I{} psql -U postgres postgres -f detect-lock.sql -o {}-lock.log
E próximo a detect-lock.sqlcolocar o último pedido. Execute - e obtenha vários arquivos com o conteúdo desejado:# cat 20200526-181433.331839375-lock.log
type | target | locked | pid | mode | granted | conflict
---------------+----------------+--------+--------+--------------+---------+----------
relation | {279588430} | t | 136325 | RowExclusive | t | f
relation | {279588422} | t | 136325 | RowExclusive | t | f
relation | {17157} | t | 136325 | RowExclusive | t | f
virtualxid | {110,12171420} | t | 136325 | Exclusive | t | f
relation | {279588430} | f | 39339 | RowExclusive | t | f
relation | {279588422} | f | 39339 | RowExclusive | t | f
relation | {17157} | f | 39339 | RowExclusive | t | f
virtualxid | {360,11744113} | f | 39339 | Exclusive | t | f
virtualxid | {638,4806358} | t | 80553 | Exclusive | t | f
advisory | {1,1,2} | t | 80553 | Exclusive | f | t
advisory | {1,1,2} | f | 80258 | Exclusive | t | t
transactionid | {3852607686} | t | 136325 | Exclusive | t | f
extend | {279588422} | t | 136325 | Exclusive | f | t
extend | {279588422} | f | 39339 | Exclusive | t | t
transactionid | {3852607712} | f | 39339 | Exclusive | t | f
(15 rows)
Bem, então - sente-se e analise ...