Neste artigo, mostrarei e mostrarei um exemplo de como uma pessoa com experiência mínima em Ciência de Dados foi capaz de coletar dados do fórum e fazer modelagem temática de postagens usando o modelo LDA, além de revelar tópicos dolorosos para pessoas com intolerância celíaca.No ano passado, eu precisava melhorar urgentemente meu conhecimento no campo de aprendizado de máquina. Sou gerente de produto de Ciência de Dados, Machine Learning e IA, ou de outra maneira Gerente Técnico de Produto AI / ML. As habilidades de negócios e a capacidade de desenvolver produtos, como geralmente ocorre em projetos voltados para usuários que não estão no campo técnico, não são suficientes. Você precisa entender os conceitos técnicos básicos da indústria de ML e, se necessário, poder escrever um exemplo para demonstrar o produto.Há cerca de 5 anos desenvolvo projetos Front-end, desenvolvendo aplicativos Web complexos em JS e React, mas nunca lidei com aprendizado de máquina, laptops e algoritmos. Portanto, quando vi a notícia da Otus de que eles estavam abrindo um curso experimental de cinco meses sobre Machine Learning , sem hesitação, decidi me submeter a testes experimentais e segui o curso.Durante cinco meses, toda semana havia palestras de duas horas e trabalhos de casa para eles. Lá eu aprendi sobre os conceitos básicos de ML: vários algoritmos de regressão, classificações, conjuntos de modelos, aumento de gradiente e até tecnologias de nuvem levemente afetadas. Em princípio, se você ouvir atentamente cada palestra, existem exemplos e explicações suficientes para a lição de casa. Mas ainda assim, às vezes, como em qualquer outro projeto de codificação, eu precisava recorrer à documentação. Dado meu emprego em período integral, era bastante conveniente estudar, pois eu sempre podia revisar o registro de uma palestra on-line.No final do treinamento deste curso, todos tiveram que fazer o projeto final. A idéia do projeto surgiu de maneira espontânea, quando comecei a treinar empreendedorismo em Stanford, onde entrei para a equipe que trabalhava no projeto para pessoas com intolerância celíaca. Durante a pesquisa de mercado, fiquei interessado em saber o que preocupa, o que eles estão falando, sobre o que as pessoas com esse recurso reclamam.À medida que o estudo progredia, encontrei um fórum no celiac.comcom uma enorme quantidade de material sobre a doença celíaca. Era óbvio que rolar manualmente e ler mais de 100 mil postagens era impraticável. Então surgiu a idéia de aplicar o conhecimento que recebi neste curso: coletar todas as perguntas e comentários do fórum de um tópico específico e fazer modelagem temática com as palavras mais comuns em cada uma delas.Etapa 1. Coleta de Dados do Fórum
O fórum consiste em muitos tópicos de vários tamanhos. No total, este fórum tem cerca de 115.000 tópicos e cerca de um milhão de posts, com comentários sobre eles. Eu estava interessado no subtópico específico "Lidar com a doença celíaca" , que literalmente significa "Lidar com a doença celíaca", se em russo significa mais "continuar a viver com um diagnóstico de doença celíaca e de alguma forma lidar com as dificuldades". Este subtópico contém cerca de 175.000 comentários.O download dos dados ocorreu em duas etapas. Para começar, eu tive que percorrer todas as páginas do tópico e coletar todos os links para todas as postagens, para que, na próxima etapa, eu já pudesse coletar um comentário.url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
Como o fórum era bastante antigo, tive muita sorte e o site não teve problemas de segurança; portanto, para coletar os dados, bastava usar a combinação Usuário-Agente da fake_useragent , biblioteca Beautiful Soup , para trabalhar com a marcação html e saber o número de páginas:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
Em seguida, faça o download do DOM HTML de cada página para extrair dados com facilidade e facilidade usando a biblioteca BeautifulSoup Python .
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
Para baixar os dados, eu precisava determinar os campos necessários para análise: encontre os valores desses campos no DOM e salve-os no dicionário. Eu próprio vim do fundo do Front-end, portanto, trabalhar com casa e objetos foi trivial para mim.def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
No total, coletei cerca de 15.450 postagens neste tópico.coping_posts_info = collect_post_info(coping_pages)
Agora eles podiam ser transferidos para o DataFrame para ficarem lindamente lidos e, ao mesmo tempo, salvá-los em um arquivo csv para que você não tivesse que esperar novamente quando os dados foram coletados no site se o notebook acidentalmente quebrar ou eu redefinir acidentalmente uma variável where.df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
Depois de coletar uma coleção de postagens, comecei a coletar os comentários.def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
PASSO 2 Análise de Dados e Modelagem Temática
Na etapa anterior, coletamos dados do fórum e recebemos os dados finais no formato de 153777 linhas de perguntas e comentários.Mas apenas os dados coletados não são interessantes; portanto, a primeira coisa que eu queria fazer era uma análise muito simples: derivava estatísticas para os 30 principais tópicos mais vistos e os 30 mais comentados.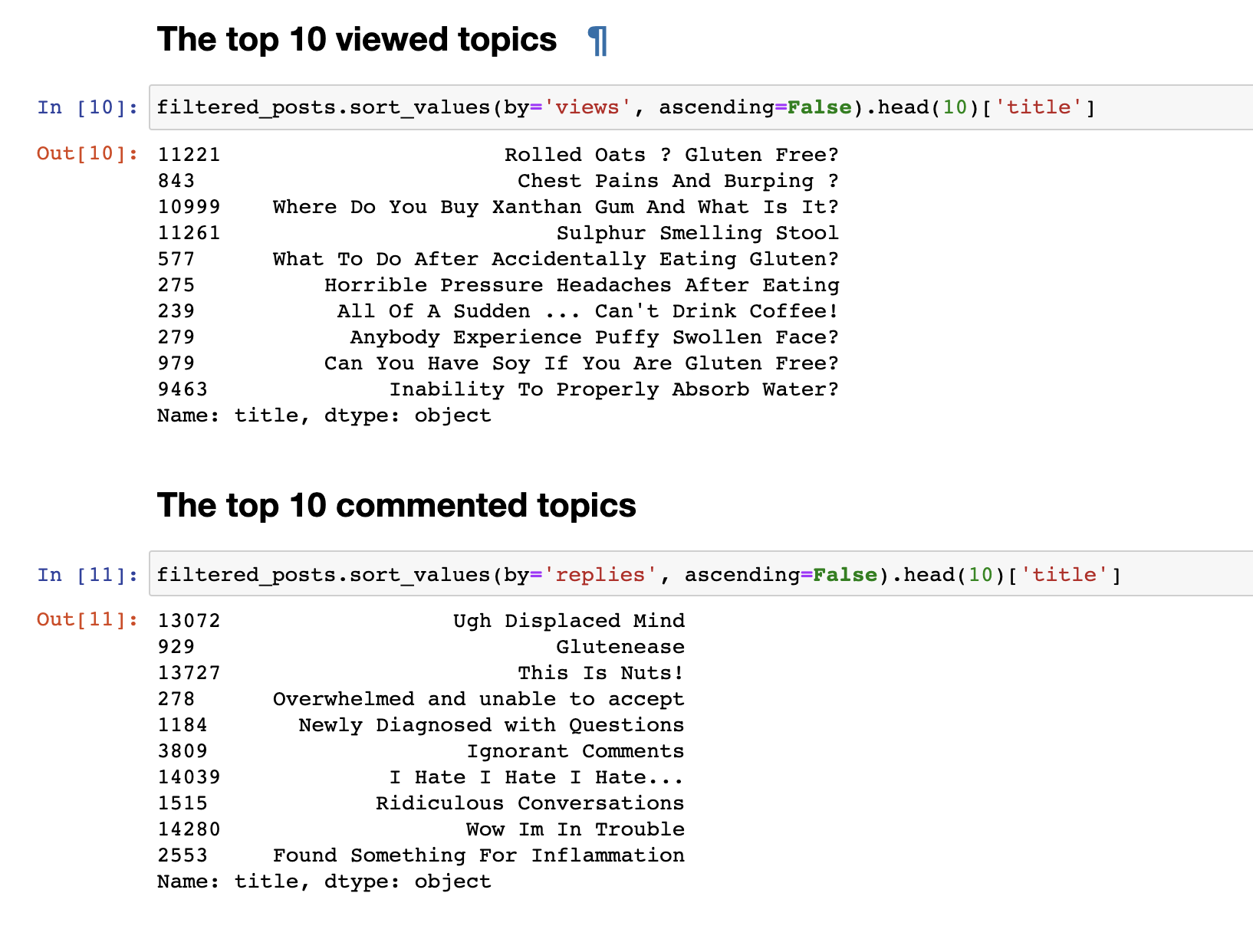 As postagens mais visualizadas não coincidem com as mais comentadas. Os títulos das postagens comentadas, mesmo à primeira vista, são perceptíveis. Os nomes deles são mais emocionais: "Eu odeio, odeio, odeio" ou " Comentários arrogantes" ou "Uau, estou com problemas" . E os mais assistidos têm um formato de pergunta: "Posso comer soja?", "Por que não consigo absorver água adequadamente?"de outros.Fizemos uma análise de texto simples. Para ir diretamente para uma análise mais complexa, é necessário preparar os dados antes de enviá-los à entrada do modelo LDA para uma análise por tópico. Para fazer isso, livre-se dos comentários que contenham menos de 30 palavras, para filtrar spam e comentários curtos sem sentido. Nós os trazemos para letras minúsculas.
As postagens mais visualizadas não coincidem com as mais comentadas. Os títulos das postagens comentadas, mesmo à primeira vista, são perceptíveis. Os nomes deles são mais emocionais: "Eu odeio, odeio, odeio" ou " Comentários arrogantes" ou "Uau, estou com problemas" . E os mais assistidos têm um formato de pergunta: "Posso comer soja?", "Por que não consigo absorver água adequadamente?"de outros.Fizemos uma análise de texto simples. Para ir diretamente para uma análise mais complexa, é necessário preparar os dados antes de enviá-los à entrada do modelo LDA para uma análise por tópico. Para fazer isso, livre-se dos comentários que contenham menos de 30 palavras, para filtrar spam e comentários curtos sem sentido. Nós os trazemos para letras minúsculas.
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
Exclua palavras de parada desnecessárias para limpar nossa seleção de textostop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
Também adicionamos bigrams e formamos um conjunto de palavras para destacar frases estáveis, por exemplo, como sem glúten, support_group e outras frases que, quando agrupadas, têm um certo significado.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Agora, finalmente, estamos prontos para treinar diretamente o próprio modelo de LDA.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
No final do treinamento, obtemos o resultado dos tópicos formados. Que eu anexei no final deste post.for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
Como pode ser notado, os tópicos acabaram apresentando conteúdo bastante distinto. Segundo eles, fica claro o que as pessoas estão falando com intolerância celíaca. Basicamente, sobre comida, ir a restaurantes, alimentos contaminados com glúten, dores terríveis, tratamento, ir a médicos, família, mal-entendidos e outras coisas com as quais as pessoas têm que lidar todos os dias em conexão com seu problema.Isso é tudo. Obrigado a todos pela atenção. Espero que você ache este material interessante e útil. E, no entanto, como não sou desenvolvedor do DS, não julgue rigorosamente. Se há algo a acrescentar ou melhorar, sempre recebo críticas construtivas, escreva.Para visualizar 30 tópicos