De um editor de blog do Google: você já se perguntou como os engenheiros do Google Cloud Technical Solutions (TSE) lidam com suas chamadas de suporte técnico? A responsabilidade dos engenheiros de suporte técnico do TSE é detectar e resolver as fontes de problemas identificados pelos usuários. Alguns desses problemas são bastante simples, mas às vezes você encontra um recurso que requer a atenção de vários engenheiros de uma só vez. Neste artigo, um dos funcionários do TSE nos falará sobre um problema muito complicado de sua prática recente - o caso de pacotes DNS ausentes. No decorrer desta história, veremos como os engenheiros conseguiram resolver a situação e que coisas novas eles aprenderam no curso de eliminar o erro. Esperamos que esta história não apenas conte sobre um erro profundamente enraizado, mas também forneça uma compreensão dos processos que ocorrem ao enviar uma solicitação para dar suporte ao Google Cloud. A solução de problemas é uma ciência e uma arte. Tudo começa com a construção de uma hipótese sobre a causa do comportamento não-padrão do sistema, após o qual é testado quanto à força. No entanto, antes de formular uma hipótese, devemos identificar claramente e formular com precisão o problema. Se a pergunta parecer vaga demais, você precisará analisar tudo corretamente; essa é a "arte" da solução de problemas.No contexto do Google Cloud, esses processos são complicados às vezes, pois o Google Cloud está lutando para garantir a privacidade de seus usuários. Por esse motivo, os engenheiros do TSE não têm acesso para editar seus sistemas, nem a capacidade de visualizar configurações tão amplamente quanto os usuários. Portanto, para testar qualquer uma de nossas hipóteses, nós (engenheiros) não podemos modificar rapidamente o sistema.Alguns usuários acreditam que vamos consertar tudo como se a mecânica do serviço de carro e simplesmente nos enviar o ID da máquina virtual, enquanto que, na realidade, o processo prossegue no formato de uma conversa: coletando informações, gerando e confirmando (ou refutando) hipóteses e, finalmente, resolvendo problemas são construídos na comunicação com o cliente.
A solução de problemas é uma ciência e uma arte. Tudo começa com a construção de uma hipótese sobre a causa do comportamento não-padrão do sistema, após o qual é testado quanto à força. No entanto, antes de formular uma hipótese, devemos identificar claramente e formular com precisão o problema. Se a pergunta parecer vaga demais, você precisará analisar tudo corretamente; essa é a "arte" da solução de problemas.No contexto do Google Cloud, esses processos são complicados às vezes, pois o Google Cloud está lutando para garantir a privacidade de seus usuários. Por esse motivo, os engenheiros do TSE não têm acesso para editar seus sistemas, nem a capacidade de visualizar configurações tão amplamente quanto os usuários. Portanto, para testar qualquer uma de nossas hipóteses, nós (engenheiros) não podemos modificar rapidamente o sistema.Alguns usuários acreditam que vamos consertar tudo como se a mecânica do serviço de carro e simplesmente nos enviar o ID da máquina virtual, enquanto que, na realidade, o processo prossegue no formato de uma conversa: coletando informações, gerando e confirmando (ou refutando) hipóteses e, finalmente, resolvendo problemas são construídos na comunicação com o cliente.Problema em consideração
Hoje temos uma história com um bom final. Uma das razões para a solução bem-sucedida do caso proposto é uma descrição muito detalhada e precisa do problema. Abaixo, você pode ver uma cópia do primeiro ticket (editado, a fim de ocultar informações confidenciais): Esta mensagem possui muitas informações úteis para nós:
Esta mensagem possui muitas informações úteis para nós:- VM especificada
- O problema está indicado - o DNS não funciona
- É indicado onde o problema se manifesta - VM e contêiner
- As etapas que o usuário executou para identificar o problema são indicadas.
O recurso foi registrado como "P1: Impacto Crítico - Serviço Inutilizável na Produção", o que significa monitoramento constante da situação 24 horas por dia, 7 dias por semana, de acordo com o esquema "Siga o Sol" (o link pode ser lido em mais detalhes sobre as prioridades das chamadas dos usuários ), com a transferência de uma equipe de suporte técnico para o outro em cada turno de fuso horário. De fato, quando o problema chegou à nossa equipe em Zurique, ela conseguiu circunavegar o mundo. Nesse momento, o usuário tomou medidas para reduzir as consequências, no entanto, tinha medo de repetir a situação na produção, pois o principal motivo ainda não foi encontrado.Quando o bilhete chegou a Zurique, já tínhamos as seguintes informações em mãos:- Conteúdo
/etc/hosts - Conteúdo
/etc/resolv.conf - Conclusão
iptables-save - O
ngreparquivo pcap compilado pelo comando
Com esses dados, estávamos prontos para iniciar a fase de “investigação” e solução de problemas.Nossos primeiros passos
Primeiro, verificamos os logs e o status do servidor de metadados e garantimos que funcione corretamente. O servidor de metadados responde com o endereço IP 169.254.169.254 e, entre outras coisas, é responsável por controlar os nomes de domínio. Também verificamos duas vezes se o firewall funciona corretamente com a VM e não bloqueia pacotes.Foi um problema estranho: o teste nmap refutou nossa principal hipótese sobre a perda de pacotes UDP, portanto deduzimos mentalmente várias outras opções e maneiras de verificá-las:- Os pacotes desaparecem seletivamente? => Verifique as regras do iptables
- O MTU é muito pequeno ? => Verificar saída
ip a show - O problema afeta apenas pacotes UDP ou TCP? => Afaste-se
dig +tcp - Os pacotes de escavação gerados são retornados? => Afaste-se
tcpdump - O libdns funciona corretamente? => Afaste-se
stracepara verificar a transferência de pacotes nas duas direções
Aqui decidimos telefonar para o usuário para solucionar problemas ao vivo.Durante a chamada, conseguimos verificar várias coisas:- Após várias verificações, excluímos as regras do iptables da lista de motivos.
- Verificamos interfaces de rede e tabelas de roteamento e verificamos novamente o MTU
- Nós achamos que
dig +tcp google.com(TCP) está funcionando como deveria, mas dig google.com(UDP) não está funcionando - Tendo
tcpdumpexecutado enquanto trabalha dig, descobrimos que os pacotes UDP estão sendo retornados - Corremos
strace dig google.come vemos como o dig chama corretamente sendmsg()e recvms(), no entanto, o segundo é interrompido pelo tempo limite
Infelizmente, a mudança está prestes a terminar e somos forçados a transferir o problema para o próximo fuso horário. O apelo, no entanto, despertou interesse em nossa equipe, e um colega sugere a criação do pacote DNS de origem com o módulo Python fragmentado.from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())
Este fragmento cria um pacote DNS e envia a solicitação ao servidor de metadados.O usuário executa o código, a resposta DNS é retornada e o aplicativo o recebe, o que confirma a ausência de um problema no nível da rede.Após a próxima "viagem de volta ao mundo", o apelo retorna à nossa equipe e eu o traduzo completamente para mim, acreditando que será mais conveniente para o usuário se o apelo parar de circular de um lugar para outro.Enquanto isso, o usuário concorda em fornecer um instantâneo da imagem do sistema. Esta é uma notícia muito boa: a capacidade de testar o sistema você mesmo acelera significativamente a solução de problemas, porque você não precisa mais pedir ao usuário para executar comandos, me enviar resultados e analisá-los, eu posso fazer tudo sozinho!Os colegas estão começando a me invejar um pouco. No almoço, discutimos o apelo, mas ninguém tem idéia do que está acontecendo. Felizmente, o próprio usuário já tomou medidas de mitigação e não tem pressa, portanto, temos tempo para preparar o problema. E como temos uma imagem, podemos realizar quaisquer testes que nos interessem. Bem!Voltando um passo
Uma das perguntas mais populares em uma entrevista para um engenheiro de sistemas é: "O que acontece quando você faz ping em www.google.com ?" A questão é elegante, porque o candidato precisa ser descrito do shell ao espaço do usuário, ao núcleo do sistema e à rede. Eu sorrio: às vezes as perguntas da entrevista também são úteis na vida real ...Eu decido aplicar essa pergunta do eychar ao problema atual. Grosso modo, quando você tenta determinar o nome DNS, acontece o seguinte:- O aplicativo chama a biblioteca do sistema, por exemplo libdns
- libdns verifica a configuração do sistema que servidor DNS ele deve usar (no diagrama, é 169.254.169.254, servidor de metadados)
- libdns usa chamadas de sistema para criar um soquete UDP (SOKET_DGRAM) e enviar pacotes UDP com uma solicitação DNS nas duas direções
- Usando a interface sysctl, você pode configurar a pilha UDP no nível do kernel
- O kernel interage com o hardware para transmitir pacotes pela rede através de uma interface de rede
- O hipervisor captura e passa o pacote para o servidor de metadados quando entra em contato com ele
- O servidor de metadados determina o nome DNS por sua bruxaria e retorna a resposta da mesma maneira
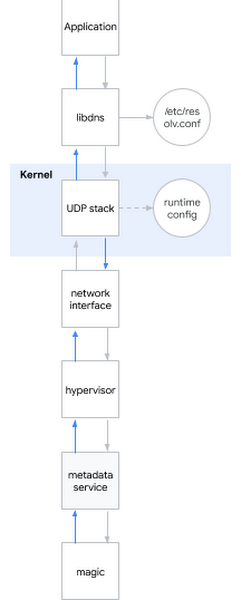 Deixe-me lembrá-lo de quais hipóteses já conseguimos considerar:Hipótese: Bibliotecas quebradas
Deixe-me lembrá-lo de quais hipóteses já conseguimos considerar:Hipótese: Bibliotecas quebradas- Teste 1: execute strace no sistema, verifique se dig faz com que as chamadas de sistema corretas
- Resultado: as chamadas corretas do sistema são chamadas
- Teste 2: através de srapy para verificar se podemos determinar os nomes ignorando as bibliotecas do sistema
- Resultado: podemos
- Teste 3: execute rpm –V nos arquivos da biblioteca libdns package e md5sum
- Resultado: o código da biblioteca é completamente idêntico ao código no sistema operacional em funcionamento
- Teste 4: monte a imagem do sistema raiz do usuário na VM sem esse comportamento, execute chroot, veja se o DNS funciona
- Resultado: o DNS está funcionando corretamente
Conclusão baseada em testes: o problema não está nas bibliotecasHipótese: Há um erro nas configurações de DNS- Teste 1: verifique o tcpdump e verifique se os pacotes DNS foram enviados e retornados corretamente após a execução do dig
- Resultado: os pacotes são transmitidos corretamente
- Teste 2: verifique novamente no servidor
/etc/nsswitch.confe/etc/resolv.conf - Resultado: tudo está correto
Conclusão baseada em teste: o problema não está na hipótese de configuração do DNS: Kernel danificado- Teste: instale um novo kernel, verifique a assinatura, reinicie
- Resultado: comportamento semelhante
Conclusão baseada em testes: o kernel não está danificado.Hipótese: comportamento incorreto da rede do usuário (ou da interface de rede do hipervisor)- Teste 1: verifique as configurações do firewall
- Resultado: o firewall passa pacotes DNS no host e no GCP
- Teste 2: interceptar tráfego e rastrear a correção da transferência e retorno de consultas DNS
- Resultado: tcpdump confirma o recebimento de pacotes de retorno pelo host
Conclusão baseada em teste: o problema não está na redeHipótese: o servidor de metadados não funciona- Teste 1: verifique se há anomalias nos logs do servidor de metadados
- Resultado: não há anomalias nos logs
- Teste 2: ignore o servidor de metadados por
dig @8.8.8.8 - Resultado: a permissão é violada mesmo sem o uso de um servidor de metadados
Conclusão baseada em teste: o problema não está no servidor de metadadosConclusão: testamos todos os subsistemas, exceto as configurações de tempo de execução!Mergulhando nas configurações de tempo de execução do kernel
Para configurar o tempo de execução do kernel, você pode usar as opções de linha de comando (grub) ou a interface sysctl. Eu olhei /etc/sysctl.confe só pensei, encontrei algumas configurações personalizadas. Sentindo como se tivesse me agarrado a algo, rejeitei todas as configurações que não são de rede ou não-TCP, permanecendo fora das configurações de montanha net.core. Depois, virei para o local em que a VM tem permissões de host e comecei a aplicar uma após a outra, uma após a outra, configurações com uma VM quebrada, até chegar ao criminoso:net.core.rmem_default = 2147483647
Aqui está, uma configuração de quebra de DNS! Eu encontrei um instrumento de crime. Mas por que isso está acontecendo? Eu ainda precisava de um motivo.A configuração do tamanho base do buffer do pacote DNS ocorre net.core.rmem_default. Um valor típico varia em algum lugar dentro de 200KiB; no entanto, se o servidor receber muitos pacotes DNS, você poderá aumentar o tamanho do buffer. Se o buffer estiver cheio no momento em que um novo pacote chegar, por exemplo, porque o aplicativo não o processa com rapidez suficiente, você começará a perder pacotes. Nosso cliente aumentou corretamente o tamanho do buffer porque tinha medo de perda de dados, porque usou o aplicativo para coletar métricas através de pacotes DNS. O valor que ele definiu foi o máximo possível: 2 31 -1 (se você definir 2 31 , o kernel retornará "ARGUMENTO INVÁLIDO").De repente, percebi por que o nmap e o scapy funcionavam corretamente: eles usavam soquetes brutos! Soquetes brutos são diferentes dos soquetes regulares: eles funcionam ignorando o iptables e não são armazenados em buffer!Mas por que "um buffer muito grande" está causando problemas? Obviamente, não funciona como pretendido.Neste ponto, eu poderia reproduzir o problema em vários núcleos e distribuições múltiplas. O problema já se manifestou no kernel 3.x e agora também se manifestou no kernel 5.x.De fato, na inicializaçãosysctl -w net.core.rmem_default=$((2**31-1))
O DNS parou de funcionar.Comecei a procurar valores funcionais por meio de um algoritmo de busca binária simples e descobri que o sistema funciona com o 2147481343, mas esse número era um conjunto de números sem sentido para mim. Convidei o cliente para experimentar esse número, e ele respondeu que o sistema funcionava com o google.com, mas ainda assim deu um erro em outros domínios, então continuei minha investigação.Eu instalei o dropwatch , uma ferramenta que eu deveria ter usado antes: mostra onde exatamente o pacote entra no kernel. A função era culpada udp_queue_rcv_skb. Eu baixei as fontes do kernel e adicionei várias funções printk para rastrear onde o pacote fica especificamente. Encontrei rapidamente a condição certaif, e por algum tempo simplesmente o encarou, porque foi então que tudo finalmente se juntou em um quadro inteiro: 2 31 -1, um número sem sentido, um domínio ocioso ... Era um pedaço de código em __udp_enqueue_schedule_skb:if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;
Nota:rmem tem o tipo intsize é do tipo u16 (sem assinatura de dezesseis bits int) e armazena o tamanho do pacotesk->sk_rcybuf é do tipo int e armazena o tamanho do buffer, que por definição é igual ao valor em net.core.rmem_default
Ao se sk_rcvbufaproximar de 2 31 , a soma do tamanho do pacote pode levar ao estouro inteiro . E como é um int, seu valor se torna negativo; portanto, a condição se torna verdadeira quando deveria ser falsa (mais sobre isso pode ser encontrado por referência ).O erro é corrigido de uma maneira trivial: convertendo para unsigned int. Apliquei o patch e reiniciei o sistema, após o qual o DNS voltou a funcionar.Gosto da vitória
Encaminhei minhas descobertas para o cliente e enviei o patch do kernel LKML . Estou satisfeito: cada peça do quebra-cabeça se juntou em um único todo, posso explicar com precisão por que observamos o que observamos e, o mais importante, conseguimos encontrar uma solução para o problema trabalhando juntos!Vale a pena reconhecer que o caso acabou sendo raro e, felizmente, essas chamadas complexas raramente são recebidas de nossos usuários.
