Continuação da primeira parte do artigo “IoT onde você não esperou. Desenvolvimento e teste (parte 1) ” não demorou a chegar. Desta vez, vou lhe dizer qual era a arquitetura do projeto e que tipo de rake pisamos quando começamos a testar nossa solução.Isenção de responsabilidade: nem uma única lixeira foi atingida com força.
Arquitetura do projeto
Temos um projeto típico de microsserviço. A camada de microsserviços do "nível inferior" recebe dados de dispositivos e sensores e os armazena em Kafka, após o que os microsserviços orientados a negócios podem trabalhar com dados recebidos da Kafka para mostrar o estado atual dos dispositivos, criar análises e ajustar seus modelos.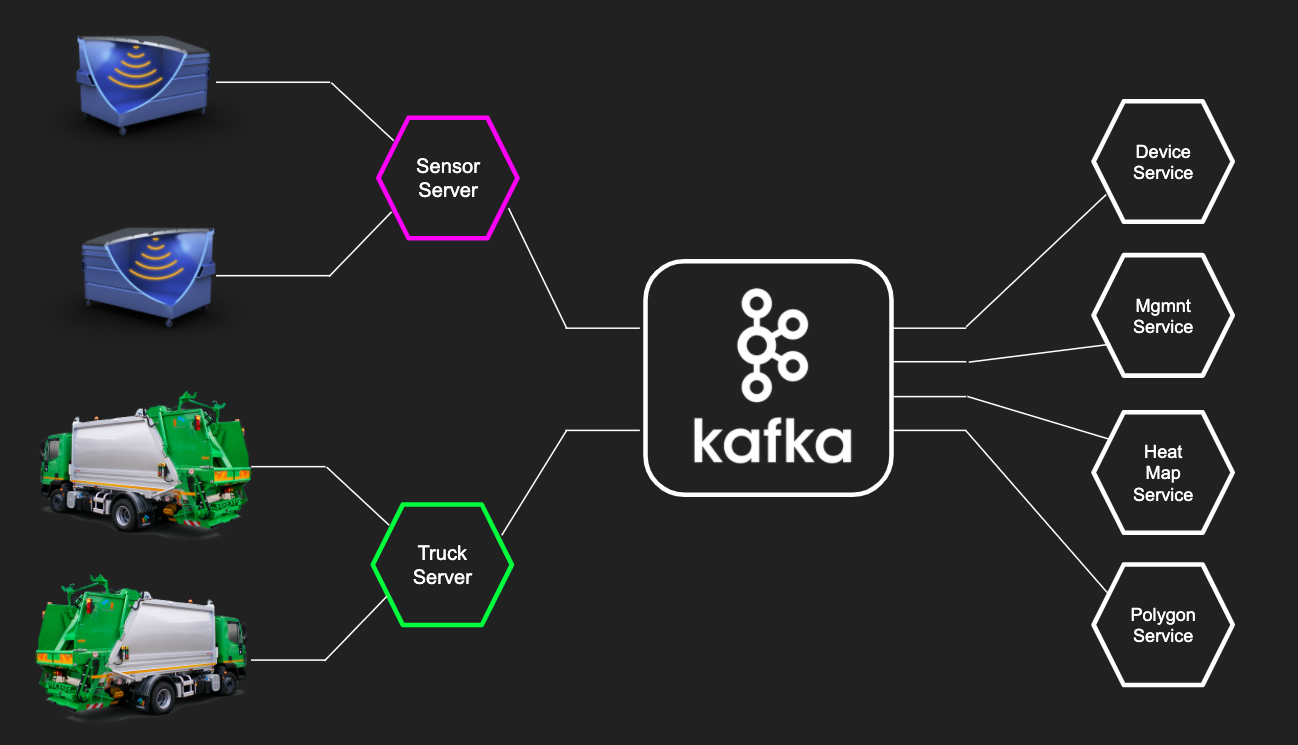 Kafka no projeto de IoT foi muito legal. Comparado a outros sistemas como o RabbitMQ, o Kafka tem várias vantagens:
Kafka no projeto de IoT foi muito legal. Comparado a outros sistemas como o RabbitMQ, o Kafka tem várias vantagens:- Trabalhar com fluxos : os dados brutos dos sensores podem ser processados para obter um fluxo. E com os fluxos, você pode configurar de maneira flexível o que deseja filtrar neles, e é fácil fazer streaming (criar novos fluxos de dados)
- : Kafka , , , . - , - , . , Kafka , . , , , .
Backend
Primeiro, vamos dar uma olhada no backend que é familiar para nós, toda a camada de negócios do aplicativo é construída na mesma pilha Java e Spring. Para testar aplicativos de microsserviço em um ambiente real, usamos a biblioteca de contêineres de teste. Ele permite implantar facilmente ligações externas (Kafka, PostgreSQL, MongoDB etc.) no Docker.Primeiro, aumentamos o contêiner necessário no Docker, iniciamos o aplicativo e, na instância real, já estamos executando os dados de teste.Sobre exatamente como fazemos isso, falei em detalhes no Heisenbug 2019 Piter no relatório “Microservice Wars: JUnit Episode 5 - TestContainers Strikes Back”:Vejamos um pequeno exemplo de como era. O serviço de nível inferior pega os dados dos dispositivos e os lança para Kafka. E o serviço Mapa de Calor da parte de negócios pega os dados do kafka e cria um mapa de calor. Vamos testar o recebimento de dados com o serviço Heat Map (via Kafka)
Vamos testar o recebimento de dados com o serviço Heat Map (via Kafka)@KafkaTestContainer
@SpringBootTest
class KafkaIntegrationTest {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
void sendTest() {
kafkaTemplate.send(TOPIC_NAME, MEASSAGE_BODY)
}
}
Estamos escrevendo um teste SpringBoot de integração regular, no entanto, ele difere no estilo de configuração de ambiente de teste baseado em anotações. É @KafkaTestContainernecessária uma anotação para elevar Kafka. Para usá-lo, você precisa conectar a biblioteca:spring-test-kafkaQuando o aplicativo é iniciado, o Spring é iniciado e o contêiner Kafka é iniciado no Docker. Em seguida, no teste, usamos kafkaTemplate, injeta-o no caso de teste e envia os dados ao Kafka para testar a lógica do processamento de novos dados do tópico.Tudo isso acontece em uma instância Kafka normal, sem opções incorporadas, mas apenas a versão que gira em produção. O serviço Heat Map usa o MongoDB como armazenamento e o teste para o MongoDB é semelhante:
O serviço Heat Map usa o MongoDB como armazenamento e o teste para o MongoDB é semelhante:@MongoDbDataTest
class SensorDataRecordServiceTest {
@Autowired
private SensorDataRecordRepository repository;
@Test
@MongoDataSet(value ="sensor_data.json")
void findSingle() {
var log = repository.findAllByDeviceId("001");
assertThat(log).hasSize(1);
...
}
}
A anotação @MongoDbDataTestinicia o MongoDB no Docker da mesma forma que o Kafka. Após o lançamento do aplicativo, podemos usar o repositório para trabalhar com o MongoDB.Para usar essa funcionalidade em seus testes, tudo o que você precisa é conectar a biblioteca:spring-test-mongoAliás, existem muitas outras utilidades, por exemplo, você pode carregar o banco de dados no banco de dados através da anotação antes de executar o teste, @MongoDataSetcomo no exemplo acima, ou usando a anotação, @ExpectedMongoDataSetverifique se , após a conclusão do caso de teste no banco de dados, o conjunto de dados exato que esperamos tenha aparecido.Falarei mais sobre como trabalhar com dados de teste no Heisenbug 2020 Piter , que será realizado on-line de 15 a 18 de junho.
Testando coisas específicas da IoT
Se a parte de negócios é um back-end típico, o trabalho com dados de dispositivos continha muitos riscos e detalhes relacionados ao hardware.Você tem um dispositivo e precisa emparelhá-lo. Para isso, você precisará de documentação. É bom quando você tem um pedaço de ferro e docas nele. No entanto, tudo começou de uma maneira diferente: havia apenas documentação e o dispositivo ainda estava a caminho. Filmamos um pequeno aplicativo, que em teoria deveria ter funcionado, mas assim que dispositivos reais chegaram, nossas expectativas foram confrontadas com a realidade.Nós pensamos que a entrada seria um formato binário e o dispositivo começou a lançar algum arquivo XML para nós. E de uma forma tão difícil, nasceu a primeira regra para o projeto de IoT:Nunca acredite na documentação!
Em princípio, os dados recebidos do dispositivo eram mais ou menos claros: Time- este é o registro de data e hora, DevEUI- o identificador do dispositivo LrrLATe LrrLON- as coordenadas. Mas o que é isso
Mas o que é isso payload_hex? Vemos 8 dígitos, o que pode estar neles? É a distância para o lixo, a tensão do sensor, o nível do sinal, o ângulo de inclinação, a temperatura ou todos juntos? Em algum momento, pensamos que os fabricantes chineses desses dispositivos conheciam algum tipo de arquivamento do Feng Shui e foram capazes de empacotar tudo o que era possível em 8 dígitos. Mas se você olhar acima, poderá ver que a hora é escrita em uma linha regular e contém 3 vezes mais bits, ou seja, bytes obviamente ninguém salvou. Como resultado, verificou-se que, especificamente neste firmware, metade dos sensores no dispositivo são simplesmente desligados e é necessário aguardar um novo firmware.Enquanto esperavam, fizemos uma bancada de testes no escritório, que na verdade era uma caixa de papelão comum. Colocamos o dispositivo na tampa e jogamos qualquer material de escritório na caixa. Também precisávamos de uma cópia de teste do carro da transportadora e seu papel foi desempenhado pela máquina de um dos desenvolvedores do projeto.Agora vimos no mapa onde ficavam as caixas de papelão e sabíamos para onde o desenvolvedor estava viajando (spoiler: casa de trabalho e ninguém cancelou o bar nas noites de sexta-feira). No entanto, o sistema com bancos de teste não durou muito, porque existem grandes diferenças em relação aos contêineres reais. Por exemplo, se falamos sobre o acelerômetro, viramos a caixa de um lado para o outro e recebemos leituras do sensor, e tudo parecia funcionar. Mas, na realidade, existem algumas limitações.
No entanto, o sistema com bancos de teste não durou muito, porque existem grandes diferenças em relação aos contêineres reais. Por exemplo, se falamos sobre o acelerômetro, viramos a caixa de um lado para o outro e recebemos leituras do sensor, e tudo parecia funcionar. Mas, na realidade, existem algumas limitações. Nas primeiras versões do dispositivo, o ângulo não foi medido em valores absolutos, mas em valores relativos. E quando a caixa foi inclinada mais do que o delta fixado no firmware, o sensor começou a funcionar incorretamente ou nem conseguiu consertar a curva.
Nas primeiras versões do dispositivo, o ângulo não foi medido em valores absolutos, mas em valores relativos. E quando a caixa foi inclinada mais do que o delta fixado no firmware, o sensor começou a funcionar incorretamente ou nem conseguiu consertar a curva. Obviamente, todos esses erros foram corrigidos no processo, mas no início as diferenças entre a caixa e o contêiner trouxeram muitos problemas. E perfuramos o tanque de todos os lados, enquanto decidimos como colocar o sensor no contêiner, de modo que, ao levantar o tanque com o carro da transportadora, registramos com precisão que o lixo foi descarregado.Além do problema com o ângulo de inclinação, a princípio não levamos em conta qual seria o verdadeiro lixo no contêiner. E se jogássemos poliestireno e travesseiros nessa caixa, na verdade as pessoas colocariam tudo em um recipiente, até cimento e areia. E, como resultado, uma vez que o sensor mostrou que o recipiente estava vazio, embora na verdade estivesse cheio. Como se viu, alguém durante o reparo lançou um material absorvente de som, que amorteceu os sinais do sensor.Nesse ponto, decidimos concordar com o proprietário do centro de negócios onde o escritório está localizado para instalar sensores em seus contêineres de lixo. Equipamos o site em frente ao escritório e, a partir desse momento, a vida e a vida cotidiana dos desenvolvedores do projeto mudaram drasticamente. Normalmente, no início do dia útil, você quer tomar café, ler as notícias e aqui você tem toda a fita cheia de lixo, literalmente:
Obviamente, todos esses erros foram corrigidos no processo, mas no início as diferenças entre a caixa e o contêiner trouxeram muitos problemas. E perfuramos o tanque de todos os lados, enquanto decidimos como colocar o sensor no contêiner, de modo que, ao levantar o tanque com o carro da transportadora, registramos com precisão que o lixo foi descarregado.Além do problema com o ângulo de inclinação, a princípio não levamos em conta qual seria o verdadeiro lixo no contêiner. E se jogássemos poliestireno e travesseiros nessa caixa, na verdade as pessoas colocariam tudo em um recipiente, até cimento e areia. E, como resultado, uma vez que o sensor mostrou que o recipiente estava vazio, embora na verdade estivesse cheio. Como se viu, alguém durante o reparo lançou um material absorvente de som, que amorteceu os sinais do sensor.Nesse ponto, decidimos concordar com o proprietário do centro de negócios onde o escritório está localizado para instalar sensores em seus contêineres de lixo. Equipamos o site em frente ao escritório e, a partir desse momento, a vida e a vida cotidiana dos desenvolvedores do projeto mudaram drasticamente. Normalmente, no início do dia útil, você quer tomar café, ler as notícias e aqui você tem toda a fita cheia de lixo, literalmente: Ao testar o sensor de temperatura, como no caso do acelerômetro, a realidade apresentou novos cenários. O valor limite da temperatura é bastante difícil de escolher, para que saibamos a tempo que o sensor está ligado e não lhe digamos adeus. Por exemplo, no verão, os contêineres esquentam muito sob o sol e definir uma temperatura limite muito baixa é repleto de notificações constantes do sensor. E se o dispositivo realmente queimar e alguém começar a apagá-lo, você precisa se preparar para o tanque ser enchido com água até o topo, alguém o derrubará e o fogo já estará apagado. Nesse cenário, o sensor obviamente não sobreviverá.Em algum momento, um novo firmware chegou até nós (você se lembra que estávamos esperando por ele?). Colocamos nos sensores e o protocolo de comunicação com o sensor quebrou novamente. Adeus XML, e viva o formato binário novamente. Gostaria de esperar neste momento que agora corresponda à documentação, mas ... não!
Ao testar o sensor de temperatura, como no caso do acelerômetro, a realidade apresentou novos cenários. O valor limite da temperatura é bastante difícil de escolher, para que saibamos a tempo que o sensor está ligado e não lhe digamos adeus. Por exemplo, no verão, os contêineres esquentam muito sob o sol e definir uma temperatura limite muito baixa é repleto de notificações constantes do sensor. E se o dispositivo realmente queimar e alguém começar a apagá-lo, você precisa se preparar para o tanque ser enchido com água até o topo, alguém o derrubará e o fogo já estará apagado. Nesse cenário, o sensor obviamente não sobreviverá.Em algum momento, um novo firmware chegou até nós (você se lembra que estávamos esperando por ele?). Colocamos nos sensores e o protocolo de comunicação com o sensor quebrou novamente. Adeus XML, e viva o formato binário novamente. Gostaria de esperar neste momento que agora corresponda à documentação, mas ... não!Portanto, a segunda regra: leia a primeira regra. Ou seja - nunca confie na documentação.
O que pode ser feito? Por exemplo, faça engenharia reversa: nos sentamos com o console, coletamos dados, giramos o sensor, colocamos algo na frente dele, tentamos identificar padrões. Assim, você pode isolar a distância, o status do contêiner e a soma de verificação. No entanto, alguns dados foram difíceis de interpretar, porque nossos fabricantes de dispositivos chineses aparentemente adoram bicicletas. E, a fim de compactar um número de ponto flutuante em formato binário para interpretar o ângulo de inclinação, eles decidiram usar dois bytes e dividir por 35. E em toda essa história, nos ajudou bastante que a camada inferior de serviços trabalhando com dispositivos estivesse isolada da parte superior e todos os dados foram derramados através do kafka, contratos para os quais foram acordados e garantidos.Isso ajudou muito em termos de desenvolvimento, porque se o nível mais baixo quebrasse, vimos silenciosamente os serviços comerciais, porque o contrato é rigidamente fixo neles. Portanto, essa segunda regra para o desenvolvimento de projetos de IoT é isolar serviços e usar contratos.
E em toda essa história, nos ajudou bastante que a camada inferior de serviços trabalhando com dispositivos estivesse isolada da parte superior e todos os dados foram derramados através do kafka, contratos para os quais foram acordados e garantidos.Isso ajudou muito em termos de desenvolvimento, porque se o nível mais baixo quebrasse, vimos silenciosamente os serviços comerciais, porque o contrato é rigidamente fixo neles. Portanto, essa segunda regra para o desenvolvimento de projetos de IoT é isolar serviços e usar contratos.O relatório ainda era muito mais interessante: simulação, teste de carga e, em geral, aconselho você a ver este relatório.
Na terceira parte , falarei sobre um modelo de simulação, fique atento!