Olá pessoal, meu nome é Fedor Indukaev, trabalho como analista na Yandex.Routing. Hoje, quero falar sobre a tarefa de visualizar conjuntos que se cruzam e sobre o pacote Python de código aberto que criei para resolvê-lo. No processo, aprenderemos como os diagramas de Venn e Euler diferem, familiarizar-se com o serviço de distribuição de pedidos e tocar tangencialmente um campo da ciência como a bioinformática. Passaremos do simples para o mais complexo. Vai!Do que se trata e por que é necessário?
Quase todos os envolvidos na análise exploratória de dados tiveram que procurar uma resposta para perguntas desse tipo pelo menos uma vez:- Há um conjunto de dados com várias variáveis binárias independentes. Quais deles são frequentemente encontrados juntos?
- Existem várias tabelas com objetos da mesma natureza que possuem IDs. Como os conjuntos de IDs de tabelas diferentes se relacionam - cada tabela possui seu próprio ID ou o mesmo em todas as tabelas ou os conjuntos diferem, mas apenas um pouco?
- Existem várias espécies. Quais organismos têm conjuntos semelhantes de genes ou proteínas?
- Como plotar como um gráfico de pizza se as categorias se sobrepõem? (É verdade, isso não está se tornando um problema para todos: veja porcentagens na figura abaixo.)
Todas essas questões podem ser reduzidas para a mesma redação. Parece assim: alguns conjuntos finitos são dados, possivelmente se cruzando, e precisamos avaliar sua posição relativa - isto é, para entender exatamente como eles se cruzam.Vamos nos concentrar em visualizações e ferramentas de software para ajudar a resolver esse problema.Diagramas venn
Esses desenhos com dois ou três círculos, eu acho, são familiares a todos e não exigem explicações:Uma característica do diagrama de Venn é que ele é estático. Os números são iguais e estão localizados simetricamente. A figura mostra todas as interseções possíveis, mesmo que a maioria esteja realmente vazia. Esses diagramas são adequados para ilustrar conceitos ou conjuntos abstratos cujas dimensões exatas são desconhecidas ou sem importância. As informações básicas aqui estão contidas não na programação, mas nas assinaturas.
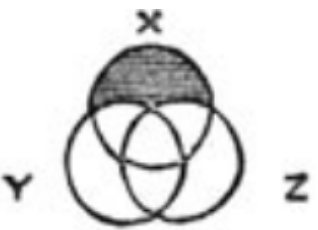 Foi assim que eles foram concebidos por John Venn, matemático e filósofo inglês. Em seu artigo de 1880ele propôs diagramas para exibição gráfica de proposições lógicas. Por exemplo, a declaração “qualquer X é Y ou Z” fornece um diagrama à direita (ilustração tirada do artigo original). A área que não satisfaz a afirmação é sombreada com preto: aqueles X que não são Y nem Z. A principal mensagem do artigo é que desenhos estáticos sem variar a forma e o arranjo das figuras são mais adequados para os propósitos da lógica do que os diagramas dinâmicos de Euler, discutidos vai abaixo.É claro que, na análise dos dados, o escopo dos diagramas de Venn é limitado. Eles fornecem apenas informações qualitativas, mas não quantitativas e não refletem o tamanho ou mesmo o vazio das interseções. Se isso não o impedir, você terá à sua disposição o pacote venn , que cria esses diagramas para conjuntos. Para cada existem uma ou duas imagens típicas e apenas as assinaturas diferem:Se queremos algo mais dinamicamente dependente dos dados, você deve prestar atenção a outra abordagem: diagramas de Euler.
Foi assim que eles foram concebidos por John Venn, matemático e filósofo inglês. Em seu artigo de 1880ele propôs diagramas para exibição gráfica de proposições lógicas. Por exemplo, a declaração “qualquer X é Y ou Z” fornece um diagrama à direita (ilustração tirada do artigo original). A área que não satisfaz a afirmação é sombreada com preto: aqueles X que não são Y nem Z. A principal mensagem do artigo é que desenhos estáticos sem variar a forma e o arranjo das figuras são mais adequados para os propósitos da lógica do que os diagramas dinâmicos de Euler, discutidos vai abaixo.É claro que, na análise dos dados, o escopo dos diagramas de Venn é limitado. Eles fornecem apenas informações qualitativas, mas não quantitativas e não refletem o tamanho ou mesmo o vazio das interseções. Se isso não o impedir, você terá à sua disposição o pacote venn , que cria esses diagramas para conjuntos. Para cada existem uma ou duas imagens típicas e apenas as assinaturas diferem:Se queremos algo mais dinamicamente dependente dos dados, você deve prestar atenção a outra abordagem: diagramas de Euler.Gráficos de Euler
Diferentemente dos diagramas de Venn, a forma e a posição das figuras no plano aqui são escolhidas para mostrar a relação de conjuntos ou conceitos. Se alguma interseção estiver vazia, as figuras também não se sobrepõem sempre que possível, como na figura sobre plantas e animais.Observe que o desenho sobre a pergunta na palestra é diferente dos outros dois. É importante não apenas a posição das figuras, mas também o tamanho das interseções - todo o humor está incluído nelas.Essa ideia pode ser usada para a nossa tarefa. Pegue dois ou três conjuntos e desenhe círculos com áreas proporcionais ao tamanho desses conjuntos. E então tentaremos organizar os círculos no plano para que as áreas de sobreposição também sejam proporcionais ao tamanho das interseções.É exatamente isso que o pacote faz (apesar do nome)matplotlib-venn : é fácil desenhar dois conjuntos com proporções exatas. Mas já às três, o método pode falhar. Seja, por exemplo, um dos três conjuntos exatamente a interseção dos outros dois:A imagem não parece boa, uma área estranha apareceu com o número 0. Mas não há nada para se surpreender, porque a interseção de dois círculos não pode ser representada como um círculo.E aqui está um exemplo ainda mais deprimente: dois conjuntos e sua diferença simétrica (união menos interseção):Acabou sendo algo completamente estranho: preste atenção em quantos zeros existem!O primeiro exemplo ainda pode ser salvo se usarmos retângulos em vez de círculos (a interseção de retângulos também é um retângulo), enquanto o segundo requer pelo menos formas não convexas. Bem, mais de três conjuntos, este pacote não suporta em princípio.Não conheço outras ferramentas públicas para Python que desenvolvam a abordagem de Euler-Venn e a história de meus próprios experimentos irá além. Mas antes de continuar, farei uma pequena digressão para explicar por que até assumi a tarefa de visualizar conjuntos.
é fácil desenhar dois conjuntos com proporções exatas. Mas já às três, o método pode falhar. Seja, por exemplo, um dos três conjuntos exatamente a interseção dos outros dois:A imagem não parece boa, uma área estranha apareceu com o número 0. Mas não há nada para se surpreender, porque a interseção de dois círculos não pode ser representada como um círculo.E aqui está um exemplo ainda mais deprimente: dois conjuntos e sua diferença simétrica (união menos interseção):Acabou sendo algo completamente estranho: preste atenção em quantos zeros existem!O primeiro exemplo ainda pode ser salvo se usarmos retângulos em vez de círculos (a interseção de retângulos também é um retângulo), enquanto o segundo requer pelo menos formas não convexas. Bem, mais de três conjuntos, este pacote não suporta em princípio.Não conheço outras ferramentas públicas para Python que desenvolvam a abordagem de Euler-Venn e a história de meus próprios experimentos irá além. Mas antes de continuar, farei uma pequena digressão para explicar por que até assumi a tarefa de visualizar conjuntos.Algumas palavras sobre a API para criar rotas ideais
Como eu disse, nosso departamento faz Yandex.routing. Um de nossos serviços ajuda lojas online, serviços de entrega e qualquer empresa cujo negócio inclua logística na construção de rotas ideais para o transporte.Os clientes interagem com o serviço enviando solicitações de API. Cada solicitação contém uma lista de pedidos (pontos de entrega) com coordenadas, intervalos de entrega, etc., bem como uma lista de máquinas que precisam entregar pedidos. Nosso algoritmo digere todos esses dados e produz rotas ideais, levando em consideração congestionamentos, capacidade do carro e muito mais.Temos centenas, não milhões de clientes, como os populares serviços Yandex B2C. Portanto, a felicidade de cada cliente é especialmente importante para nós; além disso, há a oportunidade de prestar mais atenção a ele e aprofundar suas tarefas. Para isso, em particular, é útil ter ferramentas para ajudá-lo a entender quais solicitações o cliente está nos enviando.Vou dar um exemplo. Suponha que, em um dia, 24 solicitações foram recebidas de Romashka. Isso pode significar que:- Eles trabalham em todo o país e construíram 24 conjuntos de rotas para 24 armazéns.
- Existe apenas um armazém, mas o cliente está constantemente recebendo novos pedidos. Para levá-los em consideração, você precisa atualizar as rotas a cada hora.
- As solicitações do cliente são formadas com um erro devido ao qual ele não conseguiu obter uma boa solução para uma única tarefa 24 vezes seguidas.
A priori, não está completamente claro o que realmente aconteceu. Mas se pudermos comparar rapidamente 24 conjuntos de IDs de pedidos, a situação ficará imediatamente clara. Se eles não se cruzam - este é o primeiro caso (24 armazéns). Se os conjuntos fluírem de um para o outro, o segundo (atualização agendada de rotas). Bem, 24 conjuntos quase idênticos são um possível sinal de que o cliente precisa de ajuda.Simplifique a tarefa: de círculos a listras
Por algum tempo, usei o pacote matplotlib-venn, mas a restrição de dois sets e meio, é claro, foi frustrante. Refletindo sobre diferentes abordagens para o problema, decidi tentar mudar de círculos e, geralmente, de primitivas bidimensionais para unidimensionais - listras horizontais. As interseções podem ser representadas sobrepostas verticalmente da seguinte maneira:As dimensões lineares são percebidas pelo olho melhor do que os quadrados, a trigonometria complexa não é necessária para a construção e o espaçamento dos conjuntos ao longo do eixo Y torna o gráfico menos sobrecarregado. Além disso, nosso primeiro exemplo malsucedido (dois conjuntos e sua interseção como terceiro) melhora por si só:O problema com a diferença simétrica ainda está aqui. Mas trataremos disso como Alexandre, o Grande, com o nó górdio: se necessário, cortemos um dos conjuntos em duas partes:O conjunto vermelho é representado em duas faixas em vez de uma, mas não há nada de errado nisso. Ambos estão na mesma altura e têm a mesma cor, para que sua unidade seja visualmente bem lida.É fácil verificar que dessa maneira, com a exata observação das proporções, quaisquer três conjuntos podem ser representados. Assim, o problema para igual a 2 ou 3 pode ser considerado resolvido.Outra vantagem dessa abordagem é que é fácil aplicar a qualquer número de conjuntos, o que faremos muito em breve. Tudo o que é necessário é resolver não um, mas um número arbitrário de quebras de linha. Mas primeiro, um pouco de combinatória simples.Um pouco de aritmética
Vamos examinar o diagrama de Venn com três círculos e calcular quantas áreas os círculos se dividem:Cada área é determinada se ela fica dentro ou fora de cada um dos três círculos, mas a área externa é supérflua. Total que obtemos . Outros locais dos três círculos podem fornecer menos áreas até 1, quando todos os círculos coincidem.Transferindo esse argumento de círculos para conjuntos, obtemos que qualquer conjuntos se quebram não mais do que dessas partes elementares. É importante que cada uma dessas partes seja totalmente incluída ou não esteja totalmente incluída em nenhum desses conjuntos. Em nossos novos diagramas, as colunas são partes tão elementares.Mais conjuntos!
Então, queremos generalizar esses esquemas para o caso :Para define que temos uma grade com linhas e colunas, como acabamos de calcular. Resta passar por cada linha e preencher as células correspondentes às partes elementares incluídas neste conjunto.Para ilustrar, dê um exemplo de modelo de cinco conjuntos:programming_languages = {'python', 'r', 'c', 'c++', 'java', 'julia'}
geographic_places = {'java', 'buffalo', 'turkey', 'moscow'}
letters = {'a', 'r', 'c', 'i', 'z'}
human_names = {'robin', 'julia', 'alice', 'bob', 'conrad'}
animals = {'python', 'buffalo', 'turkey', 'cat', 'dog', 'robin'}
Agindo como descrito acima, obtemos a seguinte figura:A leitura é ruim: há muitas lacunas nas linhas, todos os conjuntos são cortados em repolho. Mas como não gostamos de pausas, por que não definir diretamente a tarefa de minimizá-las? Afinal, a ordem das colunas é insignificante, nada nos impede de reorganizá-las como queremos. Chegamos a esse problema: encontre uma permutação das colunas de uma determinada matriz de zeros e aquelas com um número mínimo de lacunas entre as unidades nas linhas.Como me disseram mais tarde, essa é praticamente a tarefa de um vendedor ambulante na métrica Hamming : é NP-completo . Se houver poucas colunas (digamos, não mais que 12), você poderá encontrar a permutação necessária por pesquisa exaustiva; caso contrário, precisará recorrer a certas heurísticas.Aplicamos um algoritmo simples e ganancioso. Vamos chamar a semelhança de duas colunas o número de posições nas quais os valores nessas colunas coincidem. Pegue as duas colunas mais semelhantes e junte-as. A seguir, construiremos ansiosamente a sequência nos dois lados deste par. Entre as colunas restantes, encontramos a que mais se assemelha a uma das duas, anexa-a - e assim por diante com o restante das colunas.Aqui estão as figuras antes e depois da aplicação do algoritmo:Tornou-se muito melhor. Foi nessa fase que senti que algo útil estava saindo. Tendo experimentado, notei que o algoritmo tende a permanecer nos mínimos locais. Conseguimos tratar isso bem com uma simples randomização: fazemos um pouco de barulho sobre a semelhança das colunas, executamos o algoritmo, repetimos 1000 vezes, escolhemos a melhor das 1000 soluções.O resultado já é uma ferramenta funcional, mas você pode adicionar mais informações úteis. Fiz dois gráficos adicionais: os tamanhos dos conjuntos originais são mostrados à direita e o topo de cada interseção mostra quantos de nossos conjuntos estão. De fato, isso nada mais é do que a soma de nossa matriz binária nas linhas (à direita) e nas colunas (na parte superior):Também adicionei a opção de ordenar os próprios conjuntos (ou seja, linhas) de acordo com o mesmo princípio das colunas: minimizando o número de quebras. Como resultado, conjuntos semelhantes são agrupados:Aplicação no trabalho
Naturalmente, antes de tudo, comecei a usar a nova ferramenta para a tarefa para a qual ela foi criada: examinar as solicitações dos clientes para a nossa API. Os resultados me agradaram. Assim, por exemplo, parecia o dia útil de um dos clientes. Cada linha é uma solicitação para a API (muitos IDs dos pedidos incluídos nela), e a assinatura no meio é o momento do envio de solicitações:Todo o dia em plena vista. Às 10:49, uma logística do cliente com um intervalo de 23 segundos enviou duas solicitações idênticas com 129 pedidos. De 11:25 a 15:53, houve três solicitações com um conjunto diferente de 152 pedidos. Às 16:43, um terceiro pedido único chegou com 114 pedidos. Para resolver essa solicitação, o logístico aplicou quatro edições manuais (isso pode ser feito através da nossa interface do usuário).E é assim que um dia ideal se parece: todas as tarefas independentes foram resolvidas uma vez, nenhuma correção ou seleção de parâmetros foi necessária:E aqui está um exemplo de um cliente que envia solicitações a cada 15 a 30 minutos para levar em conta os pedidos recebidos em tempo real:Mesmo em 50 conjuntos, o algoritmo revelou claramente a estrutura oculta nos dados. Você pode ver quantas ordens antigas foram removidas das solicitações e substituídas por novas à medida que foram executadas.Em uma palavra, consegui fechar completamente minha necessidade de trabalho com a ferramenta criada.Banana para escala (não realmente)
Enquanto estudava as abordagens existentes, me deparei com várias vezes um desenho da revista Nature , que compara os genomas de banana e cinco outras plantas:Observe como os tamanhos das regiões se relacionam com 13 e 149 elementos (indicados pelas setas): o segundo é várias vezes menor. Portanto, não há questão de proporcionalidade.Obviamente, eu queria tentar esses dados, mas o resultado não me agradou:O gráfico parece confuso. A razão é que, em primeiro lugar, quase todas as interseções (62 em 63 possíveis) são vazias e, em segundo lugar, seus tamanhos diferem em três ordens de magnitude. Como resultado, as anotações numéricas ficam muito cheias.Para tornar minha ferramenta conveniente para esses dados, adicionei vários parâmetros. Uma permite alinhar parcialmente as larguras da coluna, a outra oculta anotações se a largura da coluna for menor que um valor especificado.Essa opção é lida muito bem, mas por isso tive que sacrificar a proporcionalidade exata do tamanho.Como se viu, prestando atenção ao campo da bioinformática, eu estava certo. Publiquei um post sobre minha ferramenta no Reddit em r / visualização , r / ciência de dados e r / bioinformática ; foi neste último que foi melhor recebido, as críticas foram muito entusiasmadas.Conversão de produtos
No final, percebi que era uma boa ferramenta que pode ser útil para muitos. Portanto, nasceu a idéia de transformá-lo em um pacote completo de código aberto. É claro que era necessário o consentimento dos líderes, mas os caras não apenas não se importavam, mas também me apoiavam, pelos quais muitos agradecem a eles.Trabalhando principalmente nos fins de semana, comecei a gradualmente levar o código à comercialização, escrever testes e lidar com o sistema de pacotes em Python. Este é o meu primeiro projeto desse tipo, e levou vários meses.Criar um bom nome também foi uma tarefa difícil, e eu lidei mal com isso. Nome selecionado (super venn) não pode ser considerado bem-sucedido, porque todo o sal dos diagramas de Venn é de natureza estática, mas, pelo contrário, tentei mostrar com precisão as dimensões reais. Mas quando percebi isso, o projeto já estava publicado e era tarde demais para mudar o nome.Análogos
Obviamente, não fui o primeiro a usar essa abordagem para visualizar conjuntos: a ideia, em geral, está na superfície. Existem duas aplicações Web semelhantes em acesso aberto: RainBio e Linear Diagram Generator , o segundo usa exatamente o mesmo princípio que o meu. (Os autores também escreveram um artigo em 40 páginas , que comparou experimentalmente o que é melhor percebido - linhas horizontais ou verticais, finas ou espessas, etc. Até me pareceu que o artigo era o principal para eles, e a ferramenta em si era apenas uma adição a ele .)Para comparar esses dois aplicativos com o meu pacote, usamos novamente o exemplo com palavras. Você pode decidir por si mesmo qual opção é mais legível e informativa.RainbioGerador de Diagrama LinearsupervennOutras abordagens
Não se pode deixar de mencionar o projeto UpSet , que existe como um aplicativo da Web e pacotes para R e Python. O princípio básico pode ser entendido observando a exibição dos dados do genoma da banana. O gráfico é cortado à direita, apenas 30 interseções de 62 são mostradas:Curiosamente, se você usar supervenn para classificar as colunas por largura e torná-las iguais usando a opção de alinhamento de largura, obterá quase a mesma coisa, embora isso não seja imediatamente perceptível. Tudo o que falta são linhas verticais com tamanhos de interseção; em vez delas, existem apenas números na parte inferior do gráfico:Ao escrever este texto, tentei usar a versão Python do UpSet, mas descobri que o pacote não foi atualizado desde 2016, a documentação não descreve o formato de entrada de nenhuma maneira e o caso de teste falha com um erro. A versão web está funcionando, possui muitas funções auxiliares úteis, mas trabalhar com ela é bastante difícil devido à maneira complicada de inserir dados.Por fim, uma visão geral interessante das técnicas de visualização de conjuntos está disponível online . Nem todos eles são implementados como ferramentas de software. Aqui estão algumas fotos para chamar sua atenção:Eu estava particularmente interessado no método Conjuntos de bolhas (linha inferior), que permite exibir conjuntos pequenos em cima de um determinado arranjo de elementos em um plano. Isso pode ser conveniente, por exemplo, quando os elementos são anexados ao eixo do tempo (a) ou ao mapa (b). Até o momento, esse método foi implementado apenas em Java e JavaScript (os links estão na página dos autores), e seria ótimo se alguém se comprometesse a portá-lo para o Python.Enviei cartas com uma breve descrição do projeto para os autores da UpSet e a revisão e recebi boas críticas. Dois deles até prometeram incluir supervenn nas suas palestras sobre visualização de cenários.Conclusão
Se você deseja usar o pacote, ele está disponível no GitHub e no PyPI: pip install supervenn . Serei grato por quaisquer comentários sobre o código e uso do pacote, por idéias e críticas. Ficarei especialmente satisfeito em ler as recomendações sobre como melhorar o algoritmo de permutação de colunas para grandes e dicas sobre como escrever testes para funções de gráficos.Obrigado pela atenção!Referências
1. John Venn. Sobre a representação esquemática e mecânica de proposições e raciocínios . The London, Edinburgh and Dublin Philosophical Magazine, julho de 1880.2. J.-B. Lamy e R. Tsopra. RainBio: Visualização proporcional de grandes conjuntos em biologia . Transações IEEE em Visualização e Computação Gráfica, doi: 10.1109 / TVCG.2019.2921544.3. Peter Rodgers, Gem Stapleton e Peter Chapman. Visualizando conjuntos com diagramas lineares . Transações ACM na interação humana com computadores 22 (6) pp. 27: 1-27: 39 de setembro de 2015. doi: 10.1145 / 2810012.4. Alexander Lex, Nils Gehlenborg, Hendrik Strobelt, Romain Vuillemot, Hanspeter PfisterUpSet: Visualização de conjuntos de interseção. Transações do IEEE sobre visualização e computação gráfica (InfoVis'14), 2014.5. Bilal Alsallakh, Luana Micallef, Wolfgang Aigner, Helwig Hauser, Silvia Miksch e Peter Rodgers. O estado da arte da visualização de cenários . Fórum de computação gráfica. Volume 00 (2015), número 0 pp. 1–27 10.1111 / cgf.12722.6. Christopher Collins, Gerald Penn e Sheelagh Carpendale. Conjuntos de bolhas: revelando relações definidas com Isocontours sobre visualizações existentes . IEEE Trans. em Visualização e Computação Gráfica (Proc. da Conf. IEEE em Visualização de Informação), vol. 15, iss. 6, pp. 1009-1016, 2009.