Olá a todos! Como você já sabe, nós da SE estamos envolvidos no reconhecimento de texto (e não apenas) em diferentes documentos. Hoje, gostaríamos de falar sobre outro problema ao reconhecer texto em fundos complexos - sobre reconhecer espaços. Em geral, falaremos sobre o nome nos cartões bancários, mas, primeiro, um exemplo com um "fantasma" da letra.Como você pode ver, aqui, à direita de D, as distorções e o fundo formaram um valor bastante claro Moreover. Além disso, se você mostrar essa célula separadamente de todo o resto, a pessoa (ou rede neural) certamente dirá que há uma carta.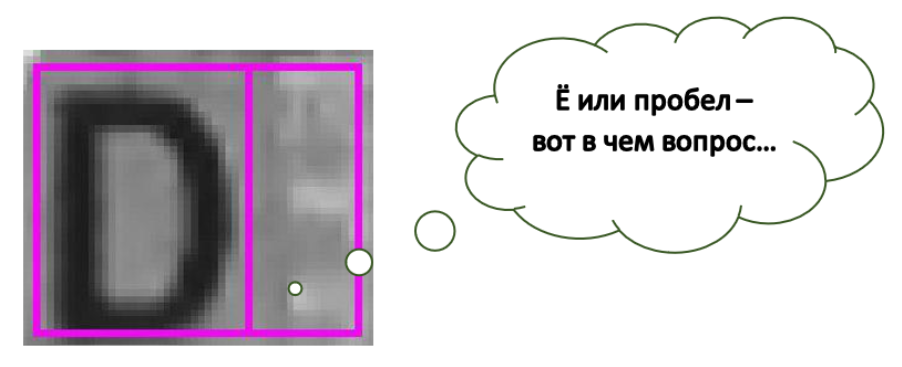 Como você pode ver na imagem, estamos trabalhando na imagem original com planos de fundo complexos, portanto nossos espaços são muito diversos. Eles vêm em padrões, logotipos e, às vezes, em texto. Por exemplo, VISA ou MAESTRO em cartões. E estamos interessados apenas nesses "espaços complexos", e não apenas em retângulos brancos. E em nossos sistemas, consideramos retângulos de símbolos precisamente cortados separadamente [1].
Como você pode ver na imagem, estamos trabalhando na imagem original com planos de fundo complexos, portanto nossos espaços são muito diversos. Eles vêm em padrões, logotipos e, às vezes, em texto. Por exemplo, VISA ou MAESTRO em cartões. E estamos interessados apenas nesses "espaços complexos", e não apenas em retângulos brancos. E em nossos sistemas, consideramos retângulos de símbolos precisamente cortados separadamente [1].E qual é a dificuldade?
Um espaço é um símbolo sem sinais especiais. Em fundos complexos, como em uma imagem, pode ser difícil distinguir um espaço de corte separado, mesmo para uma pessoa.Por outro lado, em essência, um espaço é diferente de outros personagens. Se ABIA for reconhecido no nome em vez de ASIA, haverá uma chance de corrigi-lo com o pós-processamento. Mas, se um IA surgir lá, é improvável que algo ajude.Métodos não utilizados por nós
Geralmente, os espaços são filtrados usando estatísticas calculadas a partir da imagem. Por exemplo, eles consideram o valor absoluto médio do gradiente na imagem ou a variação das intensidades de pixels e dividem as imagens em espaços e letras pelo valor limite. No entanto, como pode ser visto nos gráficos, esses métodos não são adequados para imagens em cinza com fundos complexos. E devido à correlação explícita de valores, mesmo uma combinação desses métodos não funcionará.A binarização favorita de todos também não ajudará aqui. Por exemplo, nesta figura:Então, como o reconhecimento pode ser melhorado?
Como uma pessoa precisa de um ambiente de espaço para vê-la, é lógico que a rede mostre pelo menos dois caracteres vizinhos. Não queremos aumentar a entrada da rede de reconhecimento, que, em geral, funciona bem (e reconhece muitas lacunas). Então, teremos outra rede - mais simples. A nova rede irá prever o que está na imagem: dois espaços, duas letras, um espaço e uma letra ou uma letra e um espaço. Por conseguinte, essa rede é usada em conjunto com uma rede de reconhecimento. A imagem mostra as arquiteturas utilizadas: à esquerda, a arquitetura da rede de reconhecimento, à direita, a arquitetura da rede proposta. A rede de reconhecimento opera em uma imagem com um caractere, e a nova funciona em uma imagem de largura dupla contendo dois caracteres adjacentes.Um teste?
Para o teste, tivemos 4320 linhas com nomes contendo 130.149 caracteres, dos quais 68.246 espaços. Para iniciantes, temos dois métodos. O método básico: cortamos uma string em caracteres e reconhecemos cada caracter individualmente. Novo método: também cortamos uma sequência de caracteres, localizamos todos os espaços com uma nova rede e reconhecemos os caracteres restantes como normais. A tabela mostra que a qualidade do reconhecimento de espaços, bem como a qualidade geral, está aumentando, mas a qualidade do reconhecimento de letras está um pouco diminuída.No entanto, nossa rede principal também reconhece espaços (embora piores do que gostaríamos). E podemos tentar tirar proveito disso. Vejamos os erros dos dois métodos. E também - na qualidade do novo método baseado em erros básicos e vice-versa.Para o método base:Para o novo método:Nas três últimas tabelas, é possível observar que, para melhorar o sistema, vale a pena usar uma combinação equilibrada de classificações de rede. Ao mesmo tempo, a qualidade caractere por caractere é interessante, mas linha por linha é mais interessante.Conclusão
Espaço - um grande problema no caminho para 100% de qualidade de reconhecimento de documentos =) No exemplo de espaços, é visto claramente como é importante olhar não apenas para caracteres individuais, mas também para suas combinações. No entanto, não pegue imediatamente artilharia pesada e aprenda redes gigantes que processam cordas inteiras. Às vezes, apenas outra pequena rede é suficiente.Esta publicação foi feita com materiais de um relatório da conferência europeia de modelagem do ECMS 2015 (Bulgária, Varna): Sheshkus, A. & Arlazarov, VL (2015). Detecção de símbolo de espaço em plano de fundo complexo usando contexto visual.Lista de fontes utilizadas1. YS Chernyshova, AV Sheshkus e VV Arlazarov, “Estrutura CNN em duas etapas para reconhecimento de linha de texto em imagens capturadas por câmera”, IEEE Access, vol. 8, pp. 32587-32600, 2020, DOI: 10.1109 / ACCESS.2020.2974051.