Em sistemas ERP complexos, muitas entidades têm uma natureza hierárquica , quando objetos homogêneos se alinham em uma árvore de relacionamento ancestral-descendente - essa é a estrutura organizacional da empresa (todas essas filiais, departamentos e grupos de trabalho) e o catálogo de produtos, áreas de trabalho e geografia pontos de venda, ... De fato, não existe uma única esfera de automação comercial em que pelo menos alguma hierarquia não seja o resultado. Mas, mesmo que você não trabalhe "para negócios", ainda poderá encontrar facilmente relacionamentos hierárquicos. É banal, mesmo a árvore genealógica ou o esquema de andar das instalações do shopping center ter a mesma estrutura. Existem várias maneiras de armazenar essa árvore em um DBMS, mas hoje vamos nos concentrar em apenas uma opção:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
E enquanto você examina as profundezas da hierarquia, ele espera pacientemente o quão [ingênuo] seus modos "ingênuos" de trabalhar com essa estrutura acabarão.Vamos analisar as tarefas emergentes típicas, sua implementação no SQL e tentar melhorar seu desempenho.# 1 Qual a profundidade da toca do coelho?
Vamos considerar, por definição, que essa estrutura refletirá a subordinação de departamentos na estrutura da organização: departamentos, divisões, setores, filiais, grupos de trabalho ... como você os chama.Primeiro, geramos nossa 'árvore' de 10 mil elementosINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
Vamos começar com a tarefa mais simples - encontrar todos os funcionários que trabalham em um setor específico ou em termos de hierarquia - para encontrar todos os descendentes de um nó . Também seria bom obter a "profundidade" do descendente ... Tudo isso pode ser necessário, por exemplo, para criar algum tipo de seleção complexa a partir da lista de identificações desses funcionários .Tudo ficaria bem se houver apenas alguns níveis desses descendentes e quantitativamente dentro de uma dúzia, mas se houver mais de cinco níveis e já houver dezenas de descendentes, poderá haver problemas. Vamos ver como as opções tradicionais de pesquisa "abaixo da árvore" são escritas (e funcionam). Mas primeiro, determinamos qual dos nós será o mais interessante para a nossa pesquisa.As subárvores "mais profundas" :WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
As subárvores "mais largas" :...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Para essas consultas, usamos um JOIN recursivo típico :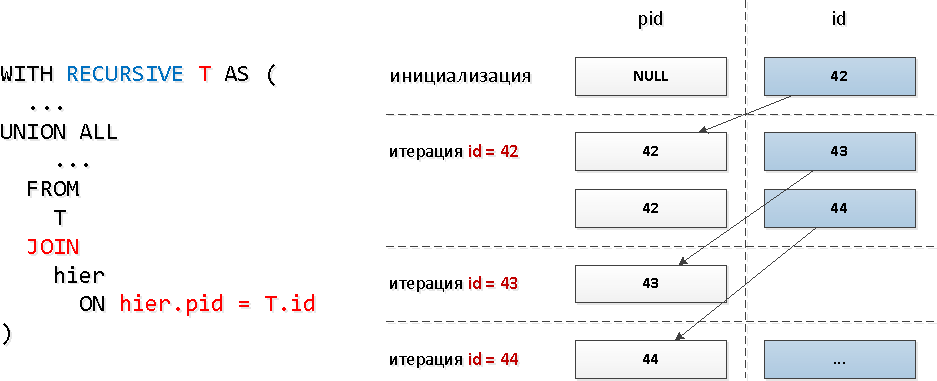 obviamente, com esse modelo de consulta, o número de iterações coincidirá com o número total de descendentes (e existem várias dezenas), e isso pode levar recursos bastante substanciais e, como resultado, tempo.Vamos verificar a subárvore "mais larga":
obviamente, com esse modelo de consulta, o número de iterações coincidirá com o número total de descendentes (e existem várias dezenas), e isso pode levar recursos bastante substanciais e, como resultado, tempo.Vamos verificar a subárvore "mais larga":WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
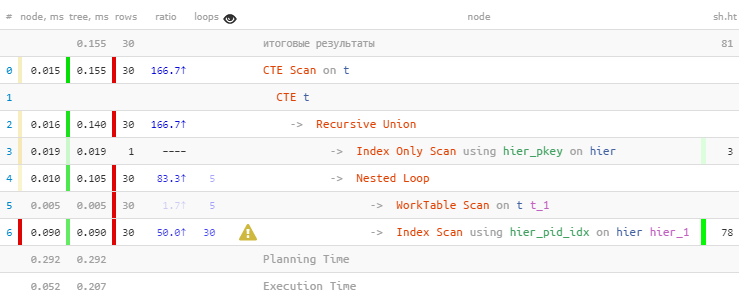 [veja explan.tensor.ru]Como esperado, encontramos todas as 30 entradas. Mas eles gastaram 60% do tempo todo nisso - porque fizeram 30 pesquisas no índice. E menos - você pode?
[veja explan.tensor.ru]Como esperado, encontramos todas as 30 entradas. Mas eles gastaram 60% do tempo todo nisso - porque fizeram 30 pesquisas no índice. E menos - você pode?Revisão em massa por índice
E para cada nó, precisamos fazer uma solicitação de índice separada? Acontece que não - podemos ler o índice em várias teclas ao mesmo tempo com uma chamada= ANY(array) .E em cada grupo de identificadores, podemos pegar todos os IDs encontrados na etapa anterior por "nós". Ou seja, em cada próximo passo, procuraremos imediatamente todos os descendentes de um determinado nível de uma só vez .Mas, é uma má sorte, em uma seleção recursiva, você não pode se referir a si mesmo em uma subconsulta , mas precisamos selecionar de alguma forma exatamente o que foi encontrado no nível anterior ... Acontece que você não pode fazer uma subconsulta para toda a amostra, mas para seu campo específico. lata. E esse campo também pode ser uma matriz - que é o que precisamos usarANY.Parece um pouco selvagem, mas no diagrama - tudo é simples.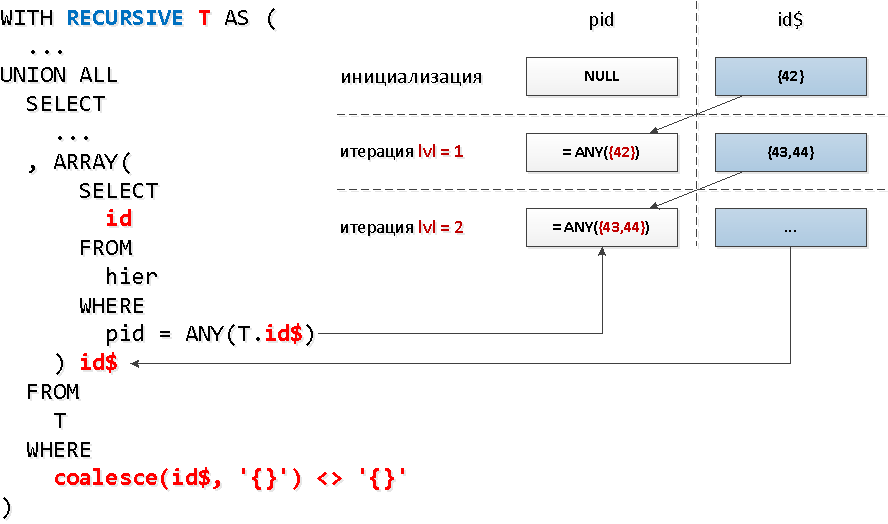
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [veja explan.tensor.ru]E aqui o mais importante nem é ganhar 1,5 vezes no tempo , mas subtraímos menos buffers, pois temos apenas 5 chamadas para o índice em vez de 30!Um bônus adicional é o fato de que, após os identificadores finais de ninhos permanecerem ordenados por "níveis".
[veja explan.tensor.ru]E aqui o mais importante nem é ganhar 1,5 vezes no tempo , mas subtraímos menos buffers, pois temos apenas 5 chamadas para o índice em vez de 30!Um bônus adicional é o fato de que, após os identificadores finais de ninhos permanecerem ordenados por "níveis".Tag do nó
A próxima consideração que ajudará a melhorar a produtividade é que "folhas" não podem ter filhos , ou seja, eles não precisam menosprezar nada. Na formulação de nossa tarefa, isso significa que, se seguimos a cadeia de departamentos e alcançamos o funcionário, não há necessidade de pesquisar mais nesse ramo.Vamos introduzir um campo adicionalboolean em nossa tabela , que nos dirá imediatamente se essa entrada específica em nossa árvore é um "nó" - ou seja , se pode ter algum filho.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
Bem! Acontece que apenas pouco mais de 30% de todos os elementos da árvore têm descendentes.Agora aplicaremos uma mecânica um pouco diferente - conectando-se à parte recursiva LATERAL, o que nos permitirá acessar imediatamente os campos da "tabela" recursiva e usar a função agregada com a condição de filtragem baseada no nó para reduzir o conjunto de chaves: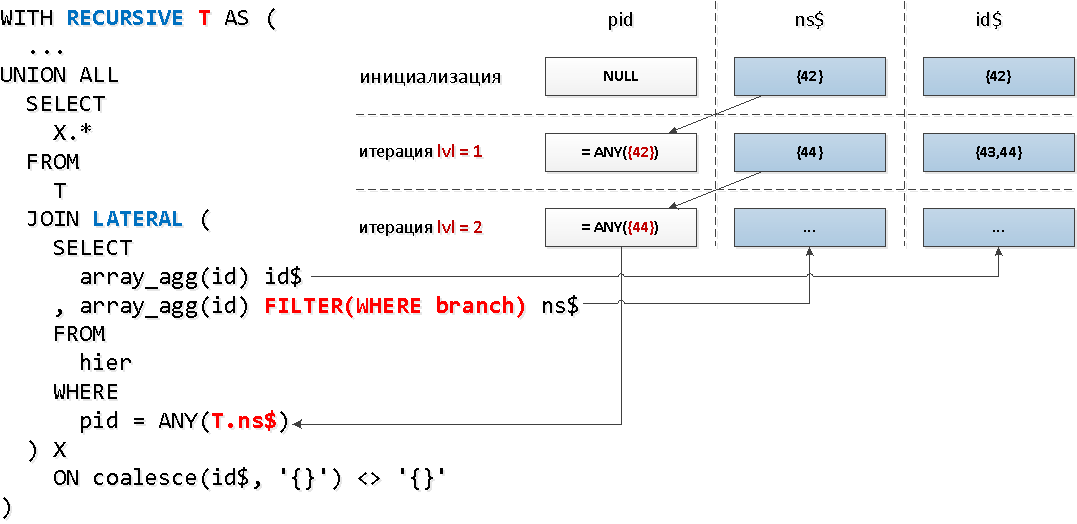
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [veja em explan.tensor.ru]Conseguimos reduzir outro apelo ao índice e vencemos mais de duas vezes em termos do valor deduzido.
[veja em explan.tensor.ru]Conseguimos reduzir outro apelo ao índice e vencemos mais de duas vezes em termos do valor deduzido.# 2 De volta às raízes
Esse algoritmo será útil se você precisar coletar registros para todos os elementos "na árvore", mantendo informações sobre qual planilha de origem (e com quais indicadores) fez com que ela caísse na amostra - por exemplo, para gerar um relatório de resumo com agregação aos nós.O adicional deve ser tomado exclusivamente como prova de conceito, uma vez que a solicitação é muito complicada. Mas se ele dominar seu banco de dados - vale a pena considerar o uso de tais técnicas.Vamos começar com algumas declarações simples:- É melhor ler o mesmo registro do banco de dados apenas uma vez .
- As entradas do banco de dados são lidas com mais eficiência em um "pacote" do que individualmente.
Agora vamos tentar projetar a consulta que precisamos.Passo 1
Obviamente, na inicialização da recursão (onde sem ela!) Teremos que subtrair os registros das próprias folhas do conjunto de identificadores de origem:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
Se pareceu estranho para alguém que o "conjunto" seja armazenado em uma string, não em uma matriz, então há uma explicação simples. Para seqüências de caracteres, existe uma função agregada de "colagem" incorporada string_agg, mas para matrizes, não. Embora não seja difícil implementá-lo você mesmo .Passo 2
Agora obteríamos um conjunto de IDs de seção que precisarão ser subtraídos ainda mais. Quase sempre, eles serão duplicados em diferentes registros do conjunto de fontes - para agrupá-los , mantendo as informações sobre as folhas de origem.Mas aqui três problemas nos esperam:- A parte "sub-recursiva" de uma consulta não pode conter funções agregadas c
GROUP BY. - Uma chamada para uma "tabela" recursiva não pode estar em uma subconsulta aninhada.
- Uma consulta na parte recursiva não pode conter um CTE.
Felizmente, todos esses problemas são facilmente contornados. Vamos começar do fim.CTE na parte recursiva
Não é assim que funciona:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
E assim funciona, os colchetes decidem!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
Consulta aninhada para "tabela" recursiva
Hmm ... Uma chamada para um CTE recursivo não pode estar em uma subconsulta. Mas pode estar dentro do CTE! Uma sub-solicitação já pode se referir a este CTE!GRUPO POR recursão interna
É desagradável, mas ... Também temos uma maneira simples de simular o GROUP BY usando as DISTINCT ONfunções da janela!SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
E assim funciona!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
Agora vemos por que o ID numérico se transformou em texto - para que possam ser colados com uma vírgula!etapa 3
Para o final, não temos mais nada:- lemos registros de "seções" em um conjunto de IDs agrupados
- combine as seções subtraídas com os "conjuntos" das folhas de origem
- “Expandir” a string definida usando
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
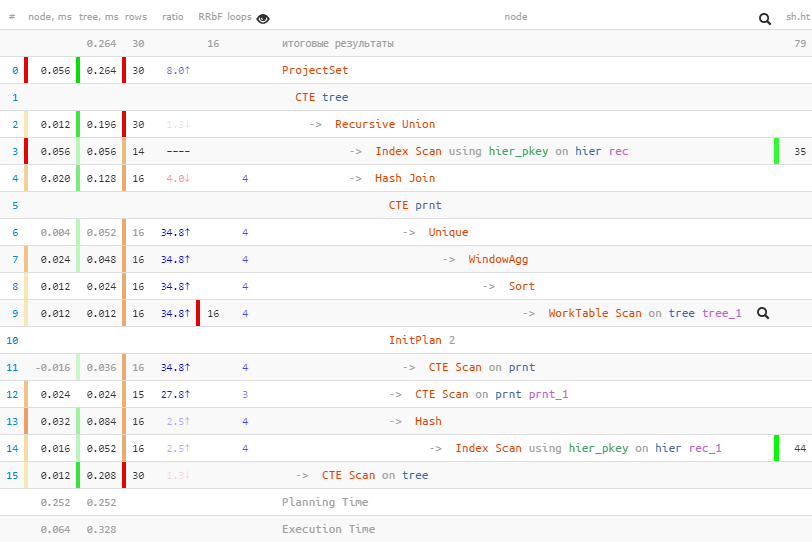 [ explain.tensor.ru]
[ explain.tensor.ru]