Decodificação do relatório de 2018 por Alexei Lesovsky "Vamos desligar o vácuo?!"
Nota do editor: todas as recomendações para alterar parâmetros devem sempre ser comparadas em outros relatórios.
Essa chamada geralmente surge quando surgem problemas no PostgreSQL, e o principal suspeito é vacuum(daqui em diante simplesmente "vácuo"). Por experiência, muitos estão adotando esse rake, e meus colegas do Data Egret e eu frequentemente precisamos enfrentar as conseqüências, porque tudo fica pior. Mas se você prestar atenção ao próprio vácuo, talvez não exista essa pessoa que usaria o Postgres e, ao mesmo tempo, não sabia nada sobre ele. Afinal, a história do vácuo começa há relativamente tempo, e na Internet você pode encontrar muitas postagens antigas e novas sobre o vácuo, discussões volumosas nas listas de discussão. Apesar do tópico do vácuo ser descrito em detalhes na documentação oficial do PostgreSQL, novas postagens e novas discussões continuarão aparecendo. Talvez seja por isso que muitos mitos, histórias, histórias de horror e conceitos errôneos estejam associados ao vácuo. Enquanto isso, o vácuo é um dos componentes mais importantes do PostgreSQL,e seu trabalho afeta diretamente a produtividade. É impossível dizer absolutamente tudo sobre o vácuo em um relatório, mas eu gostaria de revelar pontos-chave relacionados ao vácuo, como sua estrutura interna, abordagens básicas de ajuste, monitoramento de desempenho, monitoramento e o que fazer quando o vácuo é a principal coisa suspeito de todos os problemas. Bem, e, é claro, quero dissipar mitos e conceitos errôneos comuns associados ao vácuo.Quero dissipar mitos e conceitos errôneos comuns associados ao vácuo.Quero dissipar mitos e conceitos errôneos comuns associados ao vácuo.

! . : , . , . , . , - , .

, , , . , . , , , .

, , ?

: « , . - . , ».
? , . , , , – 100 % ( ). , . - .

, . postgres’ . , . , . , . . - .

, . - , , , . . .
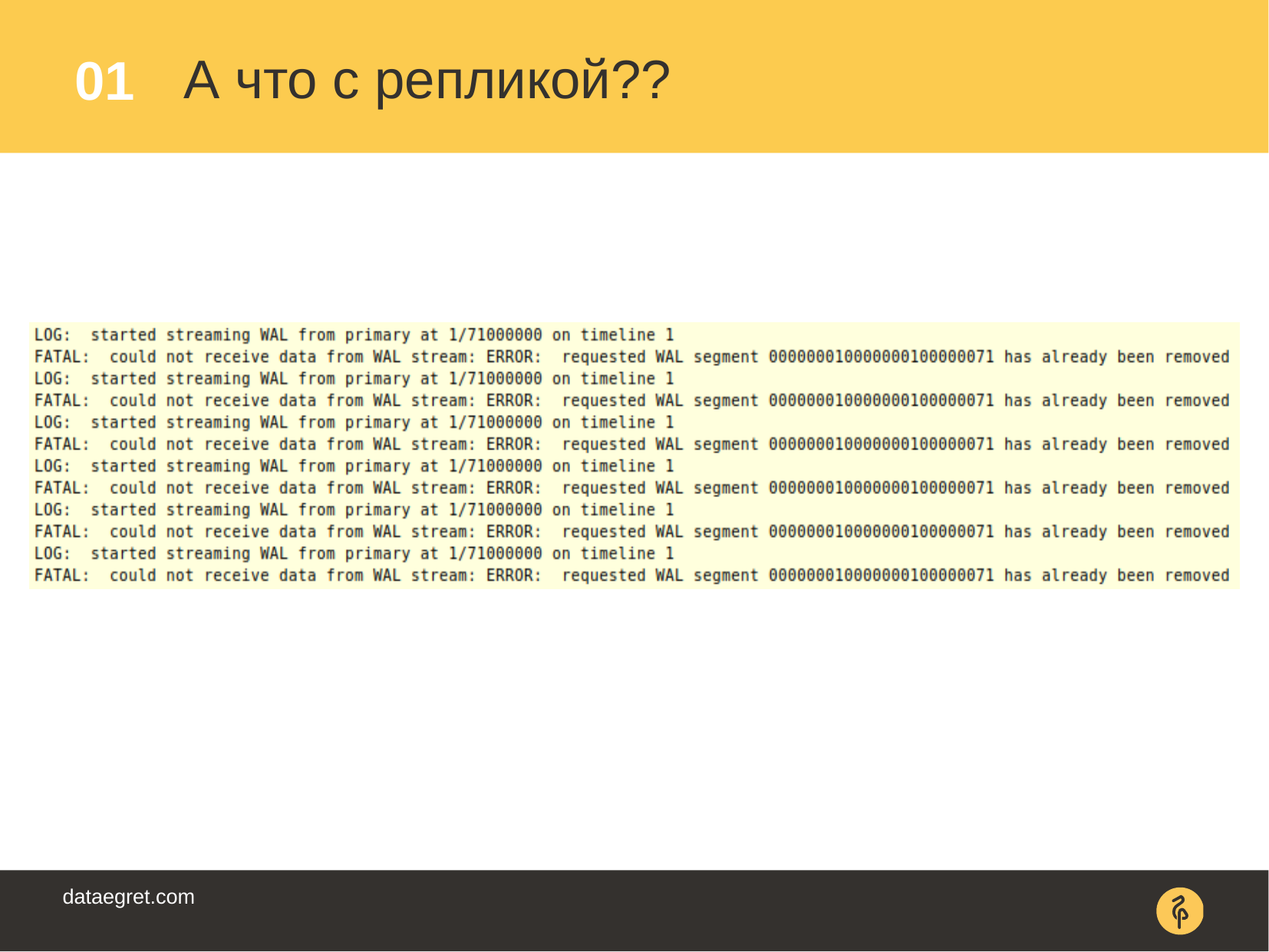
- / : « , ». , . - .
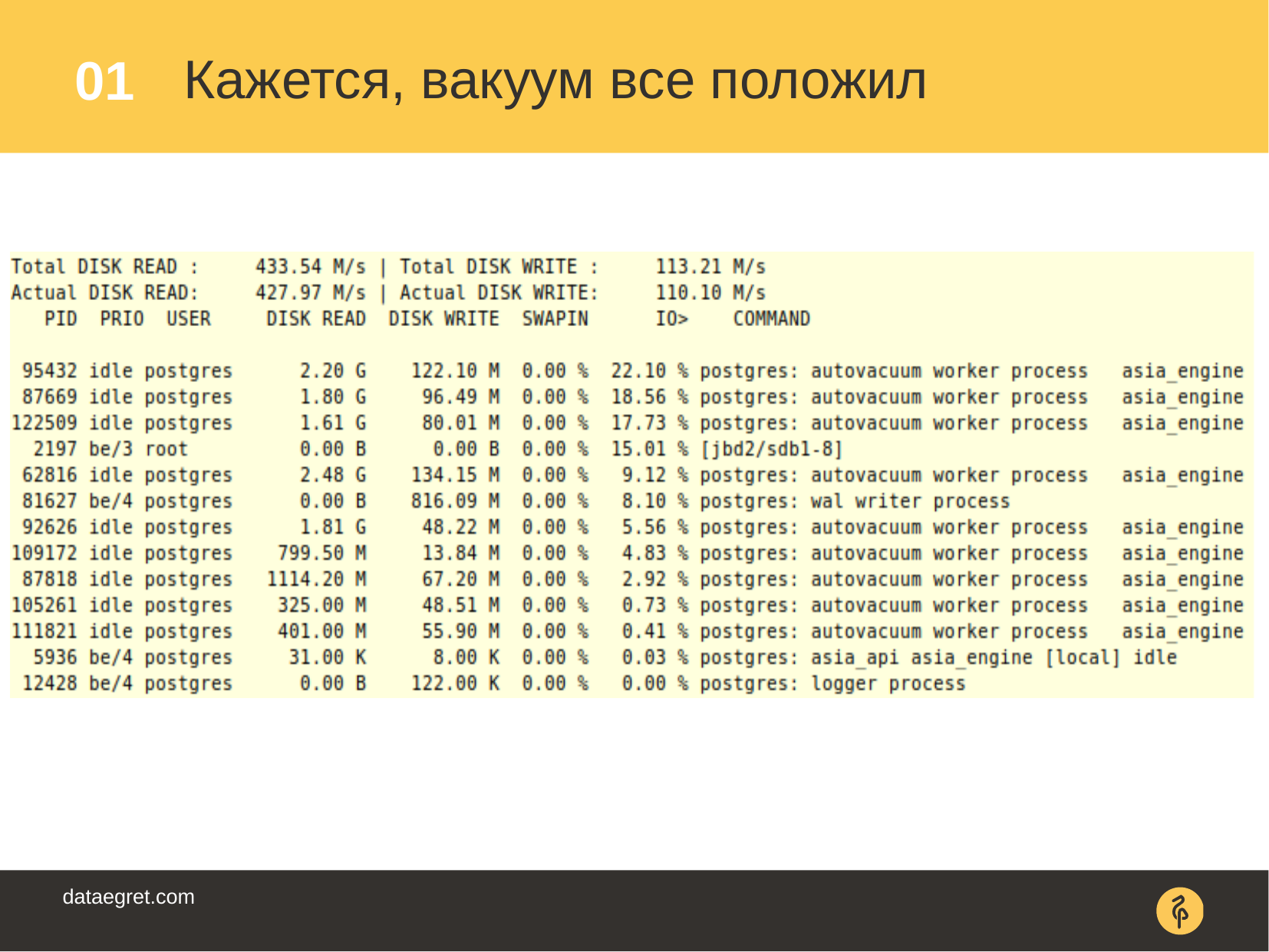
, , , iotop , . - . . .
. . , .

? , - . . . .

- - : « . – autovacuum. ».

, , , : , . . .
, .
- ( DBA) – , . , . , .
- , . . . .
- ,
shared buffers, ( , ), . . - , shared buffers. - . . – .

. . : https://github.com/lesovsky/ConferenceStuff/tree/master/2016.highload
? pgbench . pgbench . . , . . . , .

. , . , , , - . , Postgres, ( , ). , .

, MVCC.
MVCC (Multi-Version Concurrency Control) – "" , Postgres', . . .
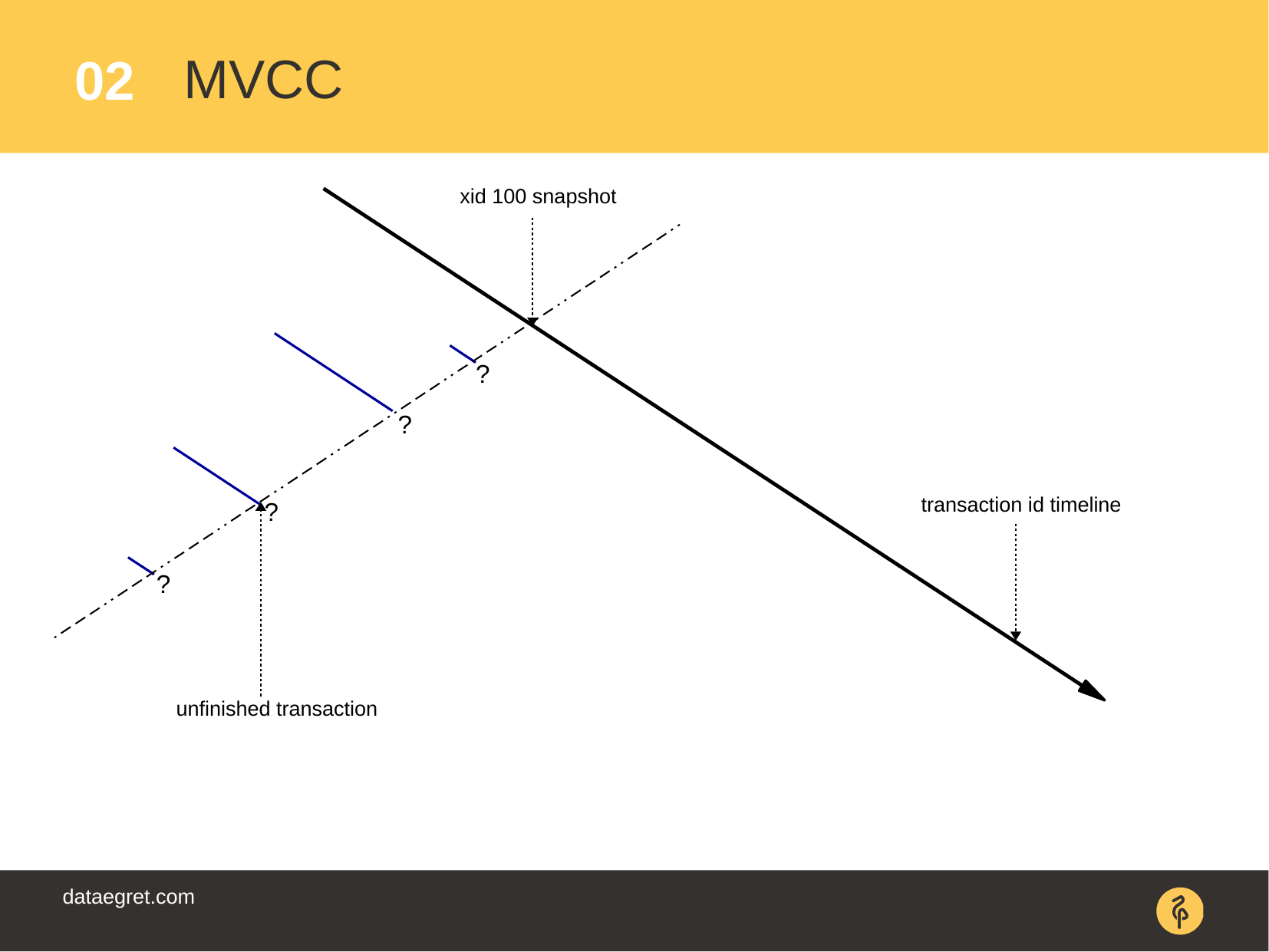
? . . (snapshot).
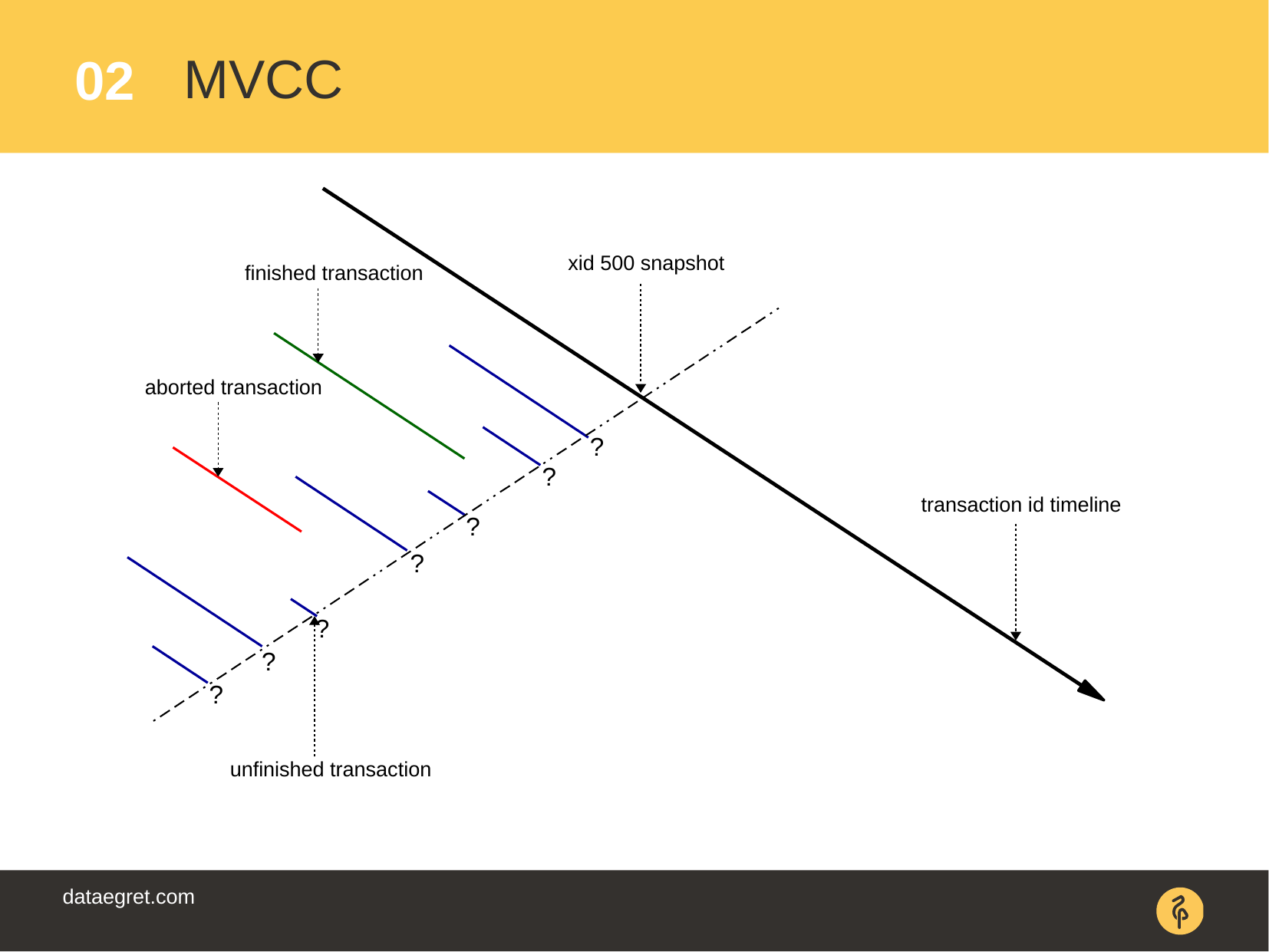
: , . , ( COMMIT ROLLBACK).
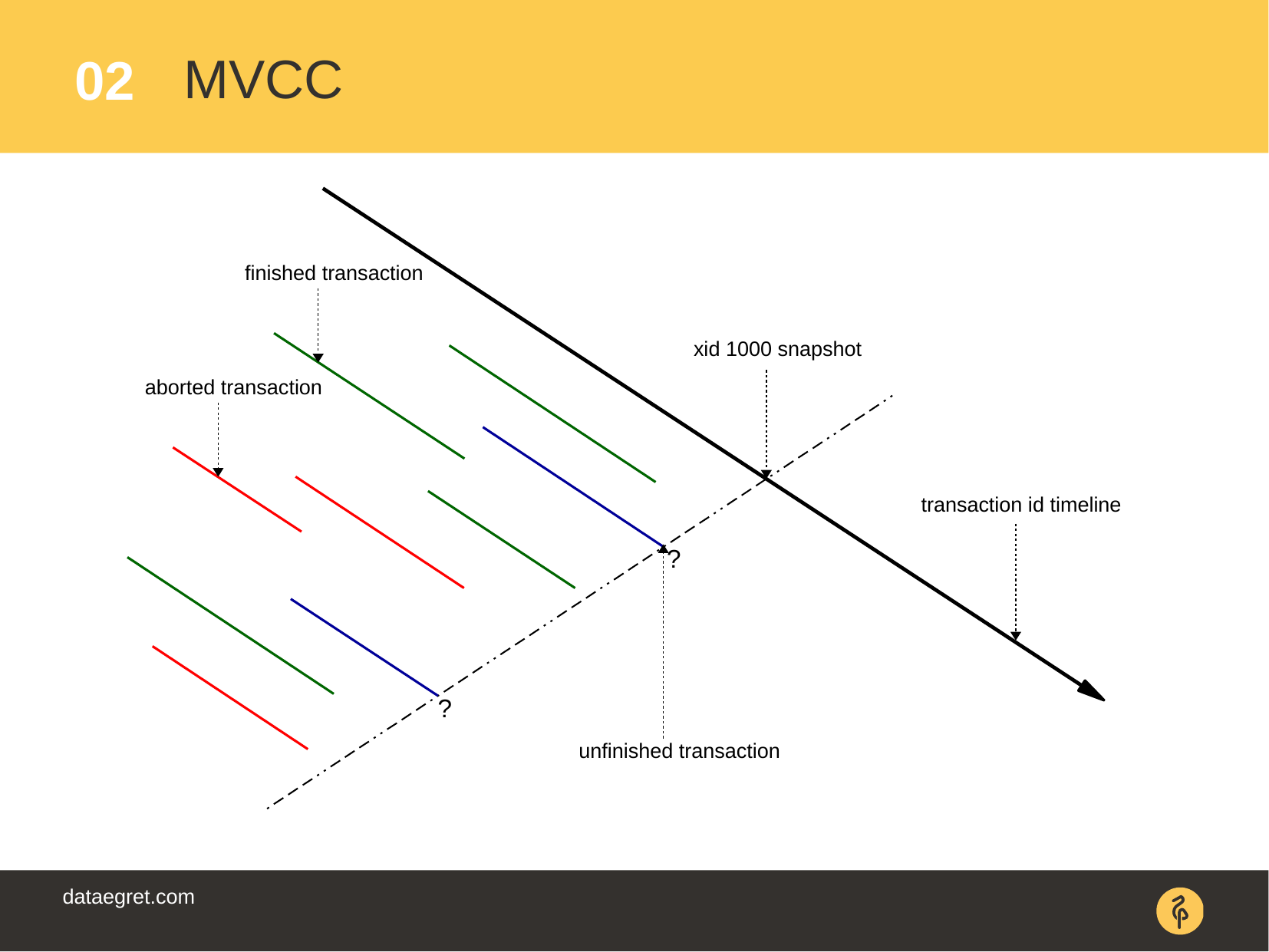
COMMIT, , . , " ". : PostgreSQL.
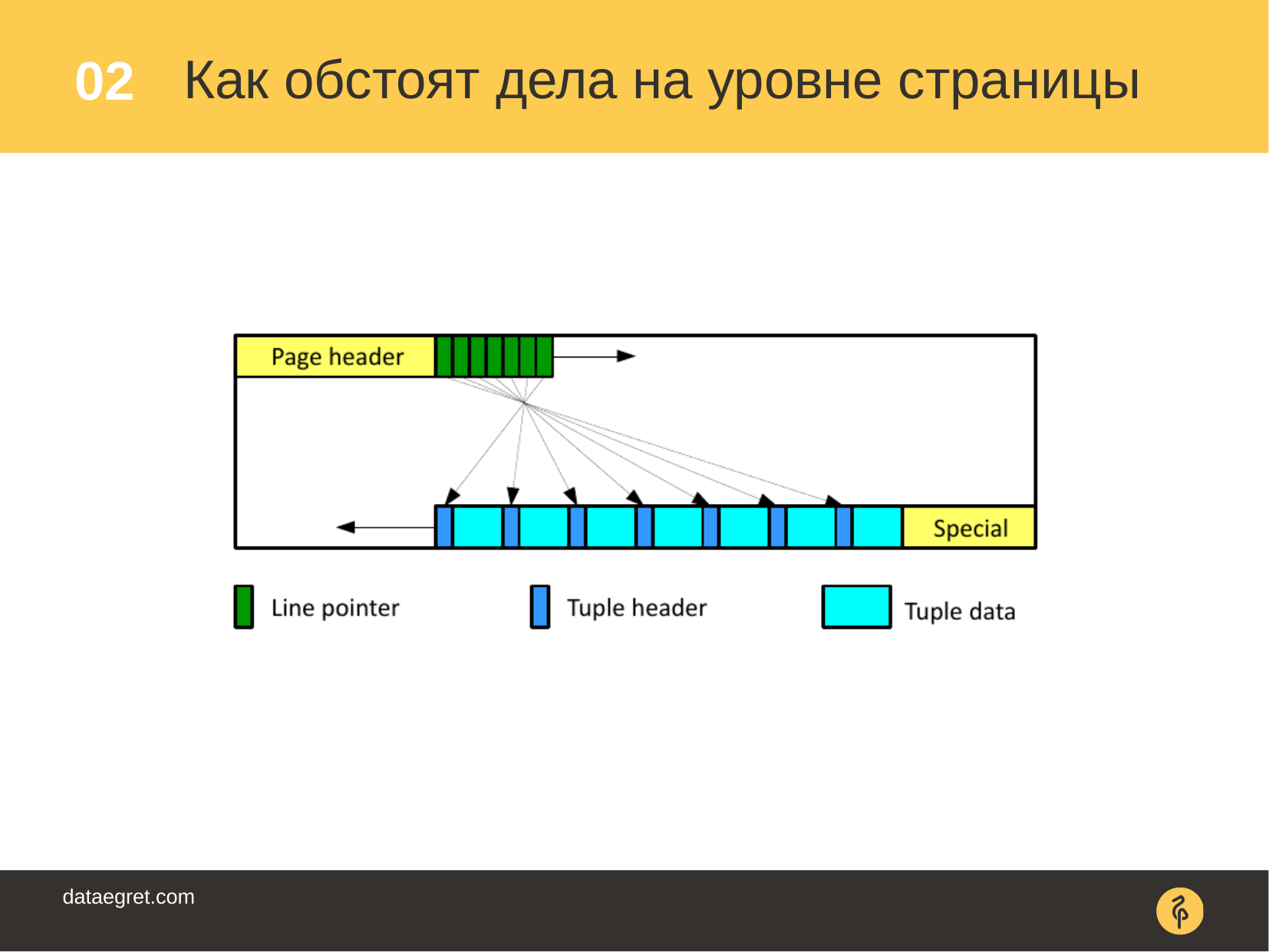
. , . - , «delete», «update». .. "" — dead tuples.

. – xmin. , . . . insert, xmin .
, . xmax , .
delete. . — xmax , .
, "" . , xmax . — , Postgres , . - - , .. , .
, ? , , , .
. , . .
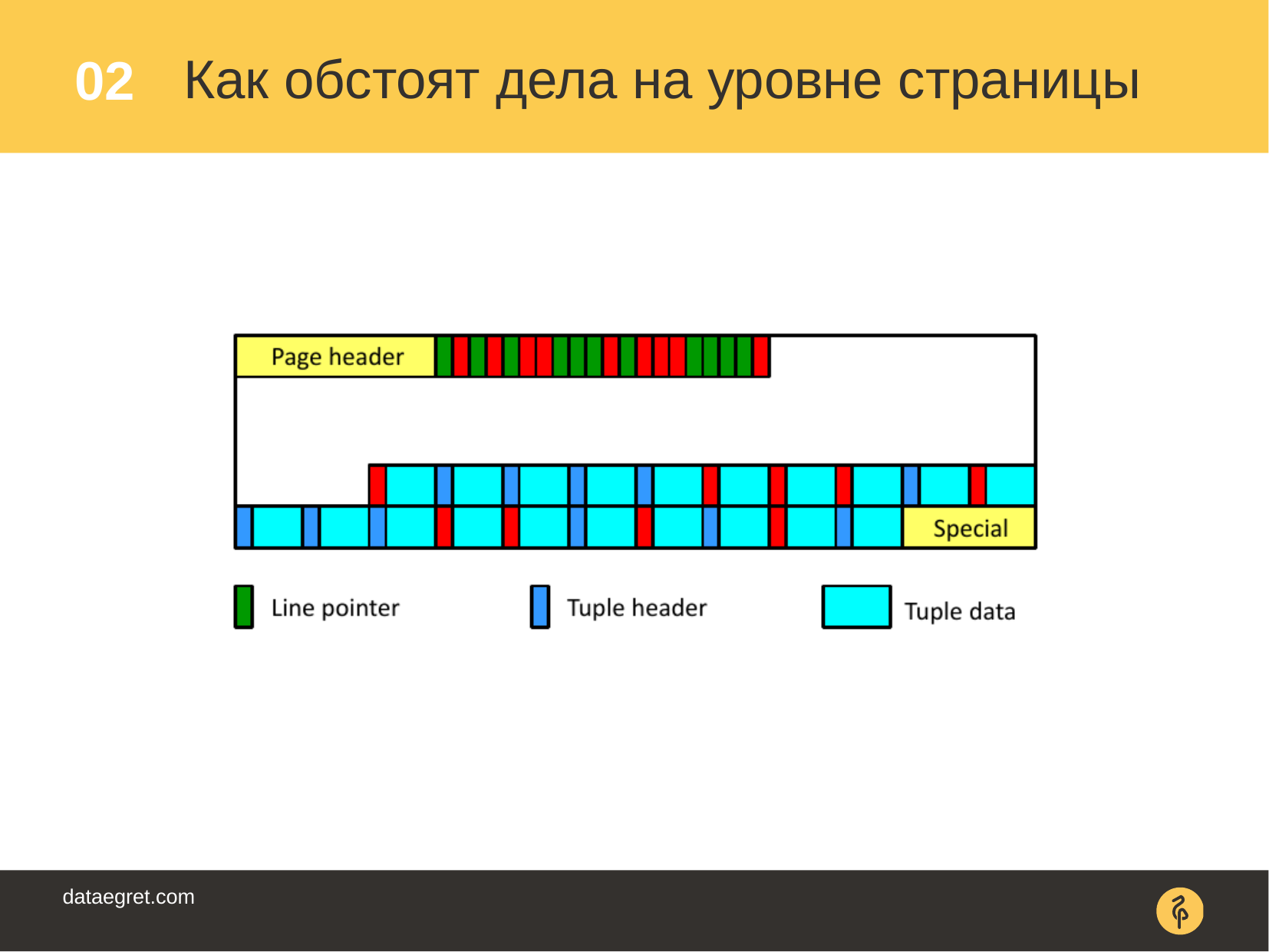
«delete», «update» , / . , , - .
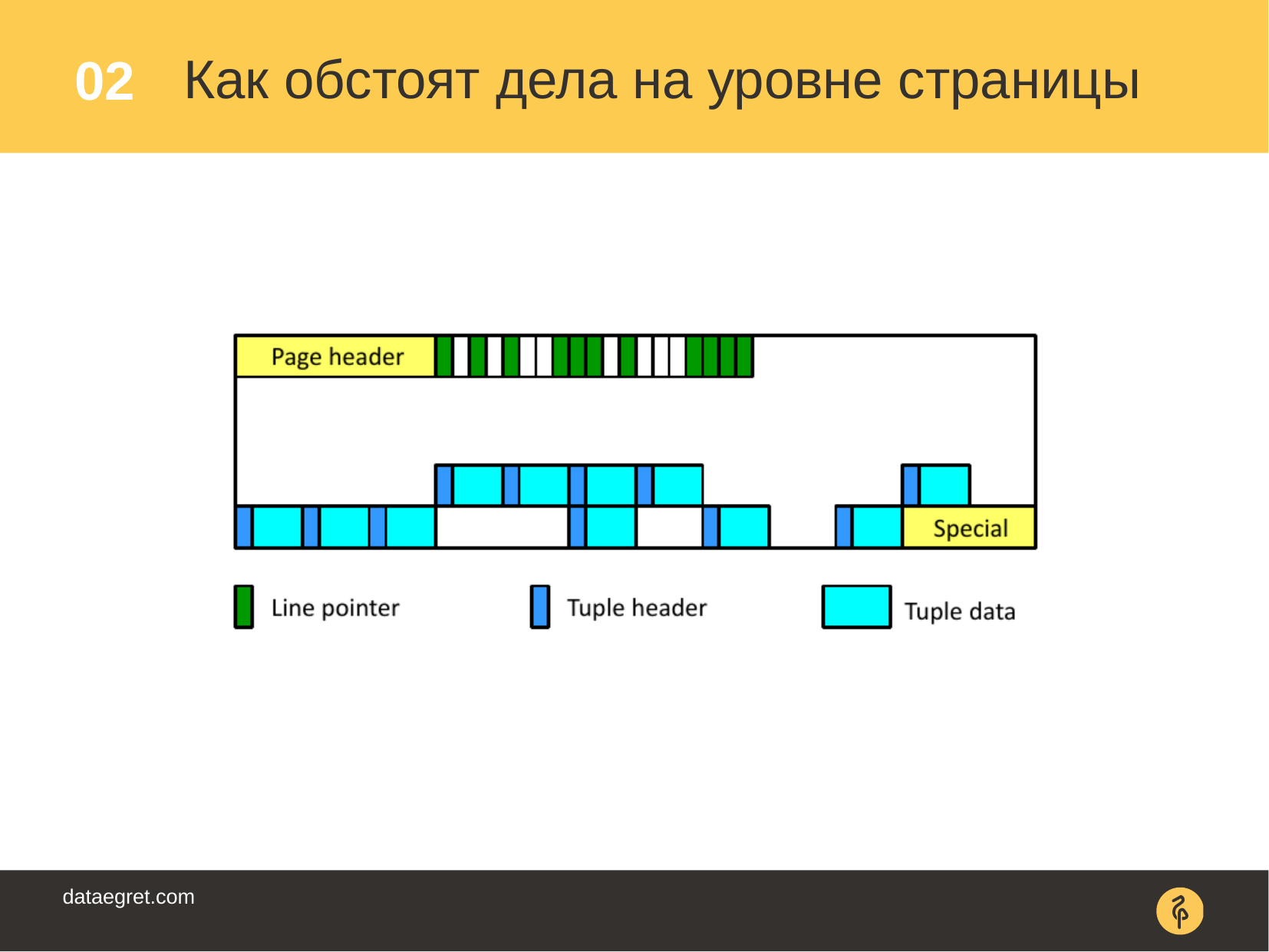
, . .
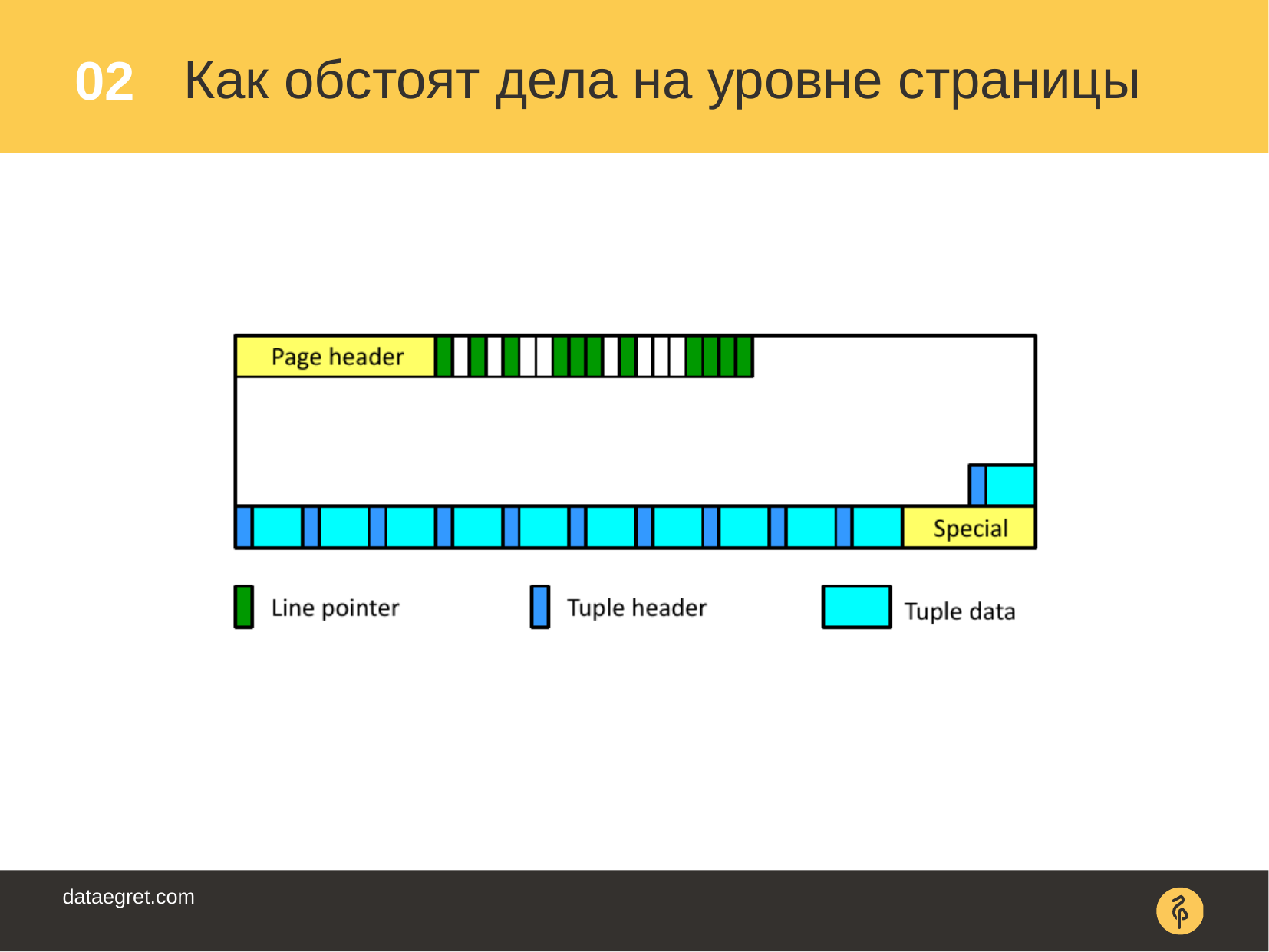
, , , . .

:
- , , , "", , .
- shared buffers .
bloat , .. — .

. ?
- -, .
- Postgres, . . . , , - , .
- . . .
- – . . . , .

- - . , Postgres . , . , .
- , .
- ,
to prevent wraparound vacuum, . wraparound vacuum — . - , , . - . . . , . , .

- . Postgres , Postgres , , Pentium, - , . - . , , , , - . . .
- Postgres . . 9.6. , 9.6 , 9.6. ( , Postgres 12)

- . .

-, , .. — cost-based vacuum. .
, : . , ( ) — . .
, . .
. vacuum_cost_page_hit, vacuum_cost_page_miss, vacuum_cost_page_dirty, hit, miss, dirty.
Hit – , , shared buffers, . . . , .
Miss – shared buffers . . , . , shared buffers, (page cache) - . , .
Dirty – , , . .
. vacuum_cost_limit. .
vacuum_cost_delay. , cost limit . cost delay .
, , , . . .

-, . - , , .
- , 32 , . , , autovacuum_max_workers 10-15 % .
- autovacuum_naptime. , . 60 . . , 1 . , . , – . . . . , .
- – , vacuum_cost_limit, , , . , vacuum_cost_limit .

-, , . , . – .
. autovacuum_vacuum_scale_factor. scale factor . - scale_factor 0.2, . . 20 %.
autovacuum_vacuum_threshold. - – 50 . , , .

, - 20 %. , autovacuum_vacuum_threshold , , 1-2-5 %.

, autovacuum_vacuum_scale_factor . . , 1 % — . autovacuum_vacuum_scale_factor 0. autovacuum_vacuum_threshold, . . , , . autovacuum_vacuum_scale_factor , autovacuum_vacuum_threshold.

, . 4-5 , HDD , . HDD . , , . , , , .
SSD . SSD . , .
SSD . , . , (, ), . – , .
NVMe , , . I/O . , . , - – - . , IO, , .

- . vacuum_cost_delay vacuum_cost_limit. . . . . . . – . .
, . , , .

vacuum_cost_delay = 0
vacuum_cost_page_hit = 0
vacuum_cost_page_miss = 5
vacuum_cost_page_dirty = 5
vacuum_cost_limit = 200
--
autovacuum_max_workers = 10
autovacuum_naptime = 1s
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.05
autovacuum_analyze_scale_factor = 0.05
autovacuum_vacuum_cost_delay = 5ms
autovacuum_vacuum_cost_limit = -1
SSD , . , , .
: SSD.

. - , - "" , .
, storage parameters. tablespaces, . , .

, — , , , Postgres. , , pgcompacttable pg_repack.
bloat .
, , . – , ( ). .

, . - .
Postgres , , .
pg_stat_activity. , (view) , , .
, , , . . . pg_stat_atctivity ().
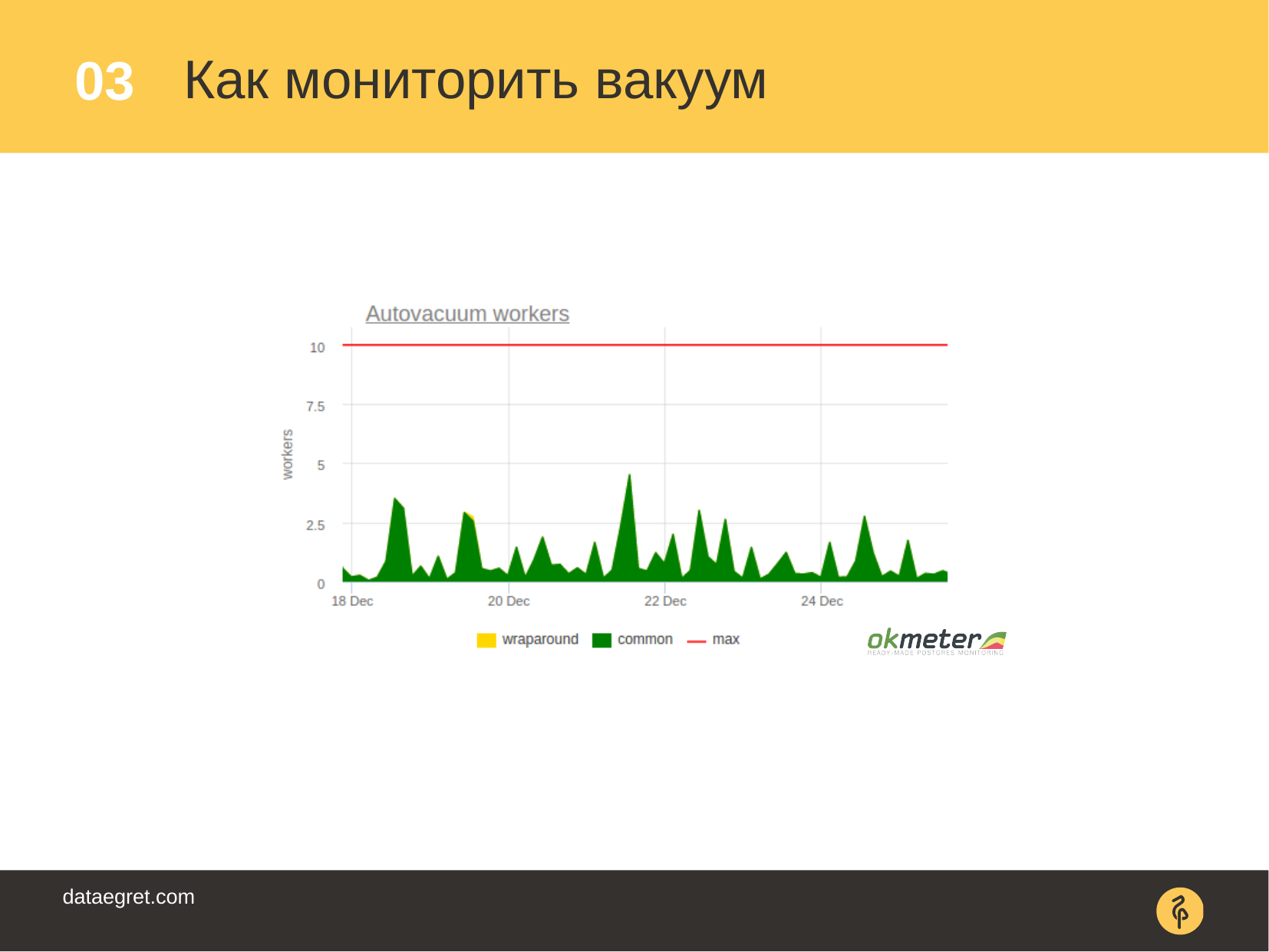
, , . , prevent wraparound . (autovacuum_max_workers)– .
– . , , , . — . .

, , pg_stat_progress_vacuum 9.6. .
, , . pg_stat_activity , , , , pg_stat_progress_vacuum .

https://github.com/lesovsky/uber-scripts/blob/master/postgresql/sql/vacuum_activity.sql
, , , . , 50 % . 3 , 3 .
— : , . , .

:
- . .
- . cost-based, cost-.
- – . , , .
! ! . 9.6 , . , , , . - ? , - ?
. 9.6 freeze-, . postgres’ , wraparound vacuum. , . , , . , , . , 9.5 . , . , .
, buffer cache, read?
, autovacuum worker , buffer-. 32 , -. , .
?
, , buffer cache, page cache, , . . , page cache, shared buffers .
, ! , . , . time . 5 1 , . . , 5 100 % CPU, storage. .
– . – . CPU, - . – ? Ubuntu. Ubuntu powersave. . ., , 3,4 GHz, – 1,2. . performance . . , , , , , , . , , .
. , , . . - , . - bloat - , . .
! , . : . - autovacuum_vacuum_scale_factor autovacuum_vacuum_threshold . , , , . , naptime , analyze. Postgres . pg_class reltuples
.
. .
.
dead tuples community , 2ndQuadrant. – . analyze reltuples .
, . – . . , «idle in transactions», , . - . , . . , .
, ?
, MVCC . - , .
reltuples?
. .
( ) . , . : update, insert . . : , . tuples. .
, . . , . . reltuples . , , , , . . . - – . .
, . - ?
Existem funções separadas no código do postgres que coletam estatísticas sobre a distribuição de dados nas tabelas. Este é um subsistema de autovacuum separado. Ele lê dados de amostra de tamanho limitado da tabela. E, com base nisso, constrói a distribuição de acordo com os dados. E ele salva essas informações no catálogo do sistema pg_statisticou na visualização do sistema pg_stats. E quando o planejador cria planos de consulta, ele lê as informações desse diretório. E em sua base faz planos. E então ele escolhe o melhor.