 Olá, habrozhiteli! Paul e Harvey Daytels oferecem uma nova visão do Python e usam uma abordagem única para resolver rapidamente os problemas que as pessoas de TI modernas enfrentam.À sua disposição, mais de quinhentas tarefas reais - de fragmentos a 40 grandes cenários e exemplos com implementação completa. O IPython com Jupyter Notebooks permite que você aprenda rapidamente os idiomas modernos de programação Python. Os capítulos 1–5 e fragmentos dos capítulos 6–7 farão exemplos claros da solução de problemas de inteligência artificial dos capítulos 11–16. Você aprenderá sobre processamento de linguagem natural, análise de emoções no Twitter, computação cognitiva IBM Watson, aprendizado de máquina com um professor em problemas de classificação e regressão, aprendizado de máquina sem um professor em cluster, reconhecimento de padrões com aprendizado profundo e redes neurais convolucionais, redes neurais recorrentes, grandes dados do Hadoop, Spark e NoSQL, IoT e muito mais. Você trabalhará (direta ou indiretamente) com serviços em nuvem, incluindo Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, etc.
Olá, habrozhiteli! Paul e Harvey Daytels oferecem uma nova visão do Python e usam uma abordagem única para resolver rapidamente os problemas que as pessoas de TI modernas enfrentam.À sua disposição, mais de quinhentas tarefas reais - de fragmentos a 40 grandes cenários e exemplos com implementação completa. O IPython com Jupyter Notebooks permite que você aprenda rapidamente os idiomas modernos de programação Python. Os capítulos 1–5 e fragmentos dos capítulos 6–7 farão exemplos claros da solução de problemas de inteligência artificial dos capítulos 11–16. Você aprenderá sobre processamento de linguagem natural, análise de emoções no Twitter, computação cognitiva IBM Watson, aprendizado de máquina com um professor em problemas de classificação e regressão, aprendizado de máquina sem um professor em cluster, reconhecimento de padrões com aprendizado profundo e redes neurais convolucionais, redes neurais recorrentes, grandes dados do Hadoop, Spark e NoSQL, IoT e muito mais. Você trabalhará (direta ou indiretamente) com serviços em nuvem, incluindo Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, etc.9.12.2 Lendo arquivos CSV na coleção DataFrame da biblioteca do pandas
As seções “Introdução à ciência de dados” dos dois capítulos anteriores apresentaram os conceitos básicos de trabalho com pandas. Agora, demonstraremos as ferramentas do pandas para baixar arquivos CSV e, em seguida, executaremos as operações básicas de análise de dados.Conjuntos de dados
Em exemplos práticos de ciência de dados, vários conjuntos de dados gratuitos e abertos serão usados para demonstrar os conceitos de aprendizado de máquina e processamento de linguagem natural. Uma enorme variedade de conjuntos de dados gratuitos estão disponíveis na Internet. O popular repositório Rdatasets contém links para mais de 1.100 conjuntos de dados CSV gratuitos. Esses kits foram originalmente fornecidos com a linguagem de programação R para simplificar o estudo e o desenvolvimento de programas estatísticos, no entanto, eles não estão relacionados à linguagem R. Agora, esses conjuntos de dados estão disponíveis no GitHub em:https://vincentarelbundock.imtqy.com/Rdatasets/ datasets.htmlEste repositório é tão popular que existe um módulo pydataset projetado especificamente para acessar o Rdatasets. Para obter instruções sobre como instalar pydataset e acessar conjuntos de dados, acesse:https://github.com/iamaziz/PyDataset
Outra excelente fonte de conjuntos de dados:https://github.com/awesomedata/awesome-public-datasetsUm conjunto de dados de aprendizado de máquina comumente usado para iniciantes é o conjunto de dados de acidentes do Titanic, que lista todos os passageiros e se eles sobreviveram quando o Titanic colidiu com um iceberg e afundou de 14 a 15 de abril de 1912. Usaremos esse conjunto para mostrar como carregar um conjunto de dados, visualizar seus dados e derivar estatísticas descritivas. Outros conjuntos de dados populares serão explorados nos capítulos de exemplos de ciência de dados mais adiante neste livro.Trabalhando com arquivos CSV locaisPara carregar um conjunto de dados CSV em um DataFrame, você pode usar a função read_csv da biblioteca do pandas. O seguinte snippet baixa e exibe o arquivo CSV accounts.csv criado anteriormente neste capítulo:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
O argumento names especifica os nomes das colunas do DataFrame. Sem esse argumento, o read_csv considera que a primeira linha do arquivo CSV contém uma lista de nomes de colunas separados por vírgula.Para salvar os dados do DataFrame em um arquivo CSV, chame o método to_csv da coleção DataFrame:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
O argumento-chave index = False significa que os nomes das linhas (0 a 4 no lado esquerdo da saída do DataFrame no fragmento [3]) não devem ser gravados no arquivo. A primeira linha do arquivo resultante contém os nomes das colunas:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3 Lendo o conjunto de dados do Titanic Disaster
O conjunto de dados de desastre do Titanic é um dos conjuntos de dados de aprendizado de máquina mais populares e está disponível em vários formatos, incluindo CSV.Faça o download do conjunto de dados do Titanic Disaster no URL
Se você tem um URL que representa um conjunto de dados no formato CSV, pode carregá-lo em um DataFrame com a função read_csv - digamos no GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
Visualizando algumas linhas do conjunto de dados de desastre do Titanic Oconjunto de dados contém mais de 1300 linhas, cada linha representa um passageiro. Segundo a Wikipedia, havia aproximadamente 1317 passageiros a bordo e 815 deles morreram1. Para conjuntos de dados grandes, apenas as 30 primeiras linhas são exibidas quando o DataFrame é produzido, as reticências "..." e as últimas 30 linhas são exibidas. Para economizar espaço, veremos as primeiras e as últimas cinco linhas usando os métodos de cabeçalho e cauda da coleção DataFrame. Ambos os métodos retornam cinco linhas por padrão, mas o número de linhas exibidas pode ser passado no argumento:Em [3]: pd.set_option ('precision', 2) # Formato para valores de ponto flutuanteObserve: o pandas ajusta a largura de cada coluna com base no valor mais amplo do nome da coluna ou da coluna (dependendo da maior largura); na coluna de idade da linha 1305 é NaN - um sinal de um valor ausente no conjunto de dados.Definindo nomes de colunasO nome da primeira coluna no conjunto de dados parece bastante estranho ('Sem nome: 0'). Esse problema pode ser resolvido personalizando os nomes das colunas. Substitua 'Unnamed: 0' por 'name' e reduza 'passengerClass' para 'class':

9.12.4 Análise simples de dados usando o conjunto de dados de desastre do Titanic como exemplo
Agora, usaremos os pandas para conduzir uma análise de dados simples, usando algumas características da estatística descritiva como exemplo. Quando você chama descrição para uma coleção DataFrame que contém colunas numéricas e não numéricas, a descrição calcula características estatísticas apenas para colunas numéricas - nesse caso, apenas para a coluna de idade: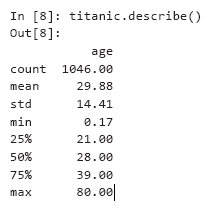 Observe as diferenças na contagem (1046) e o número de linhas de dados no conjunto de dados (1309 - ao chamar cauda, o índice da última linha era 1308). Apenas 1046 linhas de dados (valor da contagem) continham um valor de idade. O restante dos resultados estava ausente e foi marcado com NaN, como na linha 1305. Ao executar cálculos, a biblioteca do pandas ignora os dados ausentes (NaN) por padrão. Para 1046 passageiros com idade válida, a idade média (expectativa) foi de 29,88 anos. O passageiro mais jovem (min) tinha apenas dois meses (0,17 * 12 dá 2,04), e o mais velho (máximo) tinha 80 anos. A idade média foi de 28 anos (indicada por um quartil de 50%). O quartil de 25% descreve a idade média na primeira metade dos passageiros (classificada por idade),e o quartil de 75% é a mediana na segunda metade dos passageiros.Suponha que você queira calcular estatísticas sobre passageiros sobreviventes. Podemos comparar a coluna sobrevivente com o valor 'yes' para obter uma nova coleção de séries com valores True / False e, em seguida, usar a descrição para descrever os resultados:
Observe as diferenças na contagem (1046) e o número de linhas de dados no conjunto de dados (1309 - ao chamar cauda, o índice da última linha era 1308). Apenas 1046 linhas de dados (valor da contagem) continham um valor de idade. O restante dos resultados estava ausente e foi marcado com NaN, como na linha 1305. Ao executar cálculos, a biblioteca do pandas ignora os dados ausentes (NaN) por padrão. Para 1046 passageiros com idade válida, a idade média (expectativa) foi de 29,88 anos. O passageiro mais jovem (min) tinha apenas dois meses (0,17 * 12 dá 2,04), e o mais velho (máximo) tinha 80 anos. A idade média foi de 28 anos (indicada por um quartil de 50%). O quartil de 25% descreve a idade média na primeira metade dos passageiros (classificada por idade),e o quartil de 75% é a mediana na segunda metade dos passageiros.Suponha que você queira calcular estatísticas sobre passageiros sobreviventes. Podemos comparar a coluna sobrevivente com o valor 'yes' para obter uma nova coleção de séries com valores True / False e, em seguida, usar a descrição para descrever os resultados:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
Para dados não numéricos, o descrevem exibe várias características da estatística descritiva:- contagem - número total de elementos no resultado;
- exclusivo - o número de valores únicos (2) como resultado - Verdadeiro (o passageiro sobreviveu) ou Falso (o passageiro morreu);
- top - o valor mais frequentemente encontrado como resultado;
- freq - o número de ocorrências do valor superior.
9.12.5 Gráfico de barras das idades dos passageiros
A visualização é uma boa maneira de conhecer melhor os dados. O Pandas contém muitas ferramentas de visualização internas baseadas no Matplotlib. Para usá-los, primeiro ative o suporte ao Matplotlib no IPython:In [10]: %matplotlib
O histograma mostra claramente a distribuição dos dados numéricos em um intervalo de valores. O método hist da coleção DataFrame analisa automaticamente os dados de cada coluna numérica e cria o histograma correspondente. Para visualizar os histogramas para cada coluna numérica de dados, chame hist para sua coleção DataFrame:In [11]: histogram = titanic.hist()
O conjunto de dados de desastre do Titanic contém apenas uma coluna numérica de dados; portanto, o gráfico mostra um histograma para a distribuição etária. Para conjuntos de dados com várias colunas numéricas, o hist cria um histograma separado para cada coluna numérica.»Mais informações sobre o livro podem ser encontradas no site da editora» Conteúdo» Trecho docupom Khabrozhiteley de 25% de desconto no cupom - PythonApós o pagamento da versão em papel do livro (data de lançamento - 5 de junho ), um e-book é enviado.