Olá Habr! Hoje falaremos detalhadamente sobre pontos não óbvios em uma operação aparentemente simples: corrigir distorções projetivas na imagem. Como costuma acontecer na vida, tivemos que escolher o que é mais importante: qualidade ou velocidade. E, para alcançar um certo equilíbrio, lembramos os algoritmos que estudamos ativamente nos anos 80-90 como parte da tarefa de renderizar estruturas e, desde então, raramente nos lembramos no contexto do processamento de imagens. Se estiver interessado, olhe embaixo do gato! O modelo de câmera pinhole, que, na prática, também torna muito boas as câmeras de telefones com foco curto, nos diz que, quando a câmera gira, as imagens de um objeto plano são interconectadas pela transformação projetiva. A visão geral da transformação projetiva é a seguinte:
O modelo de câmera pinhole, que, na prática, também torna muito boas as câmeras de telefones com foco curto, nos diz que, quando a câmera gira, as imagens de um objeto plano são interconectadas pela transformação projetiva. A visão geral da transformação projetiva é a seguinte:
Onde matriz de transformação projetiva, e coordenadas na fonte e nas imagens convertidas.Conversão de imagem geométrica
A transformação da imagem projetiva é uma das possíveis transformações geométricas das imagens (transformações nas quais os pontos da imagem original vão para os pontos da imagem final de acordo com uma determinada lei).Para entender como resolver o problema da transformação geométrica de uma imagem digital, é necessário considerar o modelo de sua formação a partir de uma imagem óptica na matriz da câmera. De acordo com G. Wahlberg [1], nosso algoritmo deve se aproximar do seguinte processo:- Recupere imagem óptica do digital.
- Transformação geométrica da imagem óptica.
- Amostragem da imagem convertida.
Uma imagem óptica é uma função de duas variáveis definidas em um conjunto contínuo de pontos. É difícil reproduzir esse processo diretamente, porque precisamos definir analiticamente o tipo de imagem óptica e processá-la. Para simplificar esse processo, o método de mapeamento reverso é geralmente usado:- No plano da imagem final, uma grade de amostragem é selecionada - os pontos pelos quais avaliaremos os valores de pixel da imagem final (esse pode ser o centro de cada pixel ou talvez alguns pontos por pixel).
- Usando a transformação geométrica inversa, essa grade é transferida para o espaço da imagem original.
- Para cada amostra de grade, seu valor é estimado. Como ele não aparece necessariamente em um ponto com coordenadas inteiras, precisamos de alguma interpolação do valor da imagem, por exemplo, interpolação por pixels vizinhos.
- De acordo com os relatórios da grade, estimamos os valores de pixel da imagem final.
Aqui, a etapa 3 corresponde à restauração da imagem óptica e as etapas 1 e 4 correspondem à amostragem.Interpolação
Aqui consideraremos apenas tipos simples de interpolação - aqueles que podem ser representados como uma convolução da imagem com o núcleo da interpolação. No contexto do processamento de imagens, algoritmos de interpolação adaptativos que preservam limites claros de objetos seriam melhores, mas sua complexidade computacional é muito maior e, portanto, não estamos interessados.Vamos considerar os seguintes métodos de interpolação:- pelo pixel mais próximo
- bilinear
- bicúbico
- b-spline cúbico
- spline hermitian cúbico, 36 pontos.
A interpolação também possui um parâmetro tão importante quanto a precisão. Se assumirmos que a imagem digital foi obtida a partir do método óptico por amostragem no centro do pixel e acreditarmos que a imagem original era contínua, o filtro passa-baixas com uma frequência de ½ será uma função de reconstrução ideal (consulte o teorema de Kotelnikov ).Portanto, comparamos os espectros de Fourier de nossos núcleos de interpolação com um filtro passa-baixo (nas figuras são apresentadas para o caso unidimensional).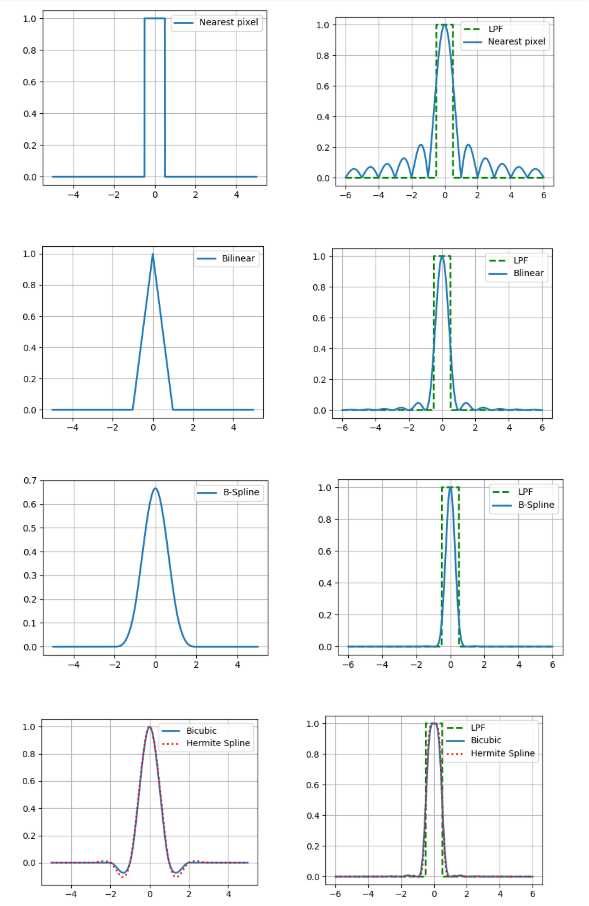 E você pode pegar um kernel com um espectro bastante bom e obter resultados relativamente precisos? Na verdade não, porque fizemos duas suposições acima: que existe um valor de pixel da imagem e a continuidade dessa imagem. Ao mesmo tempo, nem um nem o outro faz parte de um bom modelo de formação de imagem, porque os sensores na matriz da câmera não são pontuais e, na imagem, muitas informações carregam os limites dos objetos - lacunas. Portanto, deve-se entender que o resultado da interpolação será sempre diferente da imagem óptica original.Como você ainda precisa fazer alguma coisa, descreveremos brevemente as vantagens e desvantagens de cada um dos métodos considerados do ponto de vista prático. A maneira mais fácil de ver isso é quando você aumenta o zoom na imagem (neste exemplo, 10 vezes).
E você pode pegar um kernel com um espectro bastante bom e obter resultados relativamente precisos? Na verdade não, porque fizemos duas suposições acima: que existe um valor de pixel da imagem e a continuidade dessa imagem. Ao mesmo tempo, nem um nem o outro faz parte de um bom modelo de formação de imagem, porque os sensores na matriz da câmera não são pontuais e, na imagem, muitas informações carregam os limites dos objetos - lacunas. Portanto, deve-se entender que o resultado da interpolação será sempre diferente da imagem óptica original.Como você ainda precisa fazer alguma coisa, descreveremos brevemente as vantagens e desvantagens de cada um dos métodos considerados do ponto de vista prático. A maneira mais fácil de ver isso é quando você aumenta o zoom na imagem (neste exemplo, 10 vezes).Interpolação de pixels mais próxima
O mais simples e rápido, no entanto, leva a artefatos fortes.Interpolação bilinear
Melhor em qualidade, mas requer mais computação e além disso desfoca os limites dos objetos.Interpolação bicúbica
Ainda melhor em áreas contínuas, mas na borda há um efeito de halo (uma faixa mais escura ao longo da borda escura da borda e luz ao longo da luz). Para evitar esse efeito, você precisa usar um kernel de convolução não negativo, como um b-spline cúbico.Interpolação de spline B
O spline b possui um espectro muito estreito, o que significa uma imagem forte de "desfocagem" (mas também uma boa redução de ruído, que pode ser útil).Interpolação baseada em um spline cúbico de Hermite
Tal spline requer a estimativa de derivadas parciais em cada pixel da imagem. Se por aproximação escolhemos um esquema de diferença de 2 pontos, obtemos o núcleo da interpolação bicúbica, então aqui usamos 4 pontos.Também comparamos esses métodos em termos do número de acessos à memória (o número de pixels da imagem original para interpolação em um ponto) e o número de multiplicação por ponto.Pode-se observar que os três últimos métodos são significativamente mais caros em termos de computação que os dois primeiros.Amostragem
Este é o exato passo em que pouca atenção foi prestada sem merecido recentemente. A maneira mais fácil de executar a transformação da imagem projetada é avaliar o valor de cada pixel da imagem final pelo valor obtido invertendo seu centro no plano da imagem original (levando em consideração o método de interpolação selecionado). Chamamos essa abordagem de pixel por discretização de pixel . No entanto, em áreas onde a imagem é compactada, isso pode levar a artefatos significativos causados pelo problema de sobreposição de espectros a uma frequência de amostragem insuficiente.Demonstraremos claramente os artefatos de compressão na amostra do passaporte russo e em seu campo individual - local de nascimento (cidade de Arkhangelsk), compactada usando amostragem pixel por pixel ou o algoritmo FAST, que consideraremos abaixo.Pode-se ver que o texto na imagem esquerda ficou ilegível. Isso mesmo, porque consideramos apenas um ponto de toda a região da imagem de origem!Como não conseguimos estimar por um pixel, por que não escolher mais amostras por pixel e calcular a média dos valores obtidos? Essa abordagem é chamada de superamostragem . Realmente aumenta a qualidade, mas, ao mesmo tempo, a complexidade computacional aumenta na proporção do número de amostras por pixel.Métodos computacionalmente mais eficientes foram inventados no final do século passado, quando a computação gráfica resolveu o problema de renderizar texturas sobrepostas a objetos planos. Um desses métodos é a conversão usando o mip-mapestrutura. Mip-map é uma pirâmide de imagens que consiste na própria imagem original, bem como em suas cópias reduzidas em 2, 4, 8 e assim por diante. Para cada pixel, avaliamos o grau de compressão característico e, de acordo com esse grau, selecionamos o nível desejado da pirâmide, como a imagem de origem. Existem diferentes maneiras de avaliar o nível apropriado de mip-map (veja detalhes [2]). Aqui, usaremos o método baseado na estimativa de derivadas parciais em relação à bem conhecida matriz de transformação projetiva. No entanto, para evitar artefatos em áreas da imagem final onde um nível da estrutura do mapa mip vai para outro, geralmente é usada a interpolação linear entre dois níveis adjacentes da pirâmide (isso não aumenta muito a complexidade computacional, porque as coordenadas dos pontos nos níveis vizinhos são conectadas de maneira exclusiva).No entanto, o mapa mip não leva em consideração o fato de que a compactação da imagem pode ser anisotrópica (alongada em alguma direção). Esse problema pode ser parcialmente resolvido pelo rip-map . Uma estrutura na qual as imagens são compactadas tempos horizontalmente e vezes na vertical. Nesse caso, após determinar os coeficientes de compressão horizontal e vertical em um determinado ponto da imagem final, a interpolação é realizada entre os resultados de 4 cópias da imagem original compactada no número de vezes desejado. Mas esse método não é ideal, porque não leva em conta que a direção da anisotropia difere das direções paralelas aos limites da imagem original.Em parte, esse problema pode ser resolvido pelo algoritmo FAST (Texturas de amostras de área de pegada) [3]. Ele combina as idéias de mapa mip e supersampling. Estimamos o grau de compressão com base no eixo de menor anisotropia e selecionamos o número de amostras proporcionalmente à razão entre os comprimentos do menor eixo e o maior.Antes de comparar essas abordagens em termos de complexidade computacional, fazemos uma reserva de que, para acelerar o cálculo da transformação projetiva inversa, é racional fazer a seguinte alteração:Onde , É a matriz da transformação projetiva inversa. Como e funções de um argumento, podemos pré-calculá-las por um tempo proporcional ao tamanho linear da imagem. Então, para calcular as coordenadas da imagem inversa de um ponto da imagem final, são necessárias apenas 1 divisão e 2 multiplicações. Um truque semelhante pode ser realizado com derivadas parciais, que são usadas para determinar o nível na estrutura do mapa mip ou do mapa rip.Agora estamos prontos para comparar os resultados em termos de complexidade computacional.E compare visualmente (amostragem pixel por pixel da esquerda para a direita, 49 amostras de super amostragem, mapa mip, mapa rip, FAST).
Experimentar
Agora, vamos comparar nossos resultados experimentalmente. Compomos um algoritmo de transformação projetiva combinando cada um dos 5 métodos de interpolação e 5 métodos de discretização (25 opções no total). Pegue 20 imagens de documentos cortadas em 512x512 pixels, gere 10 conjuntos de 3 matrizes de transformação projetivas, de modo que cada conjunto seja geralmente equivalente à transformação de identidade e compararemos o PSNR entre a imagem original e a convertida. Lembre-se de que o PSNR éOnde este é o máximo na imagem original - o desvio padrão da final do original. Quanto mais PSNR, melhor. Também mediremos o tempo de operação da conversão projetiva no ODROID-XU4 com um processador ARM Cortex-A15 (2000 MHz e 2 GB de RAM).Mesa monstruosa com os resultados:Que conclusões podem ser tiradas?
- O uso da interpolação pelo pixel mais próximo ou pela amostragem pixel por pixel leva a baixa qualidade (era óbvio até pelos exemplos acima).
- 36 — .
- b- , , .
- Rip-map FAST , 9 ( , ?).
- mip-map b- PSNR , .
Se você deseja boa qualidade com velocidade não muito baixa, considere a interpolação bilinear em combinação com a discretização usando o mip-map ou o FAST. No entanto, se é certo que a distorção projetiva é muito fraca, para aumentar a velocidade, você pode usar a discretização pixel por pixel combinada com interpolação bilinear ou mesmo interpolação pelo pixel mais próximo. E se você precisar de um tempo de execução de alta qualidade e não muito limitado, poderá usar a interpolação bicúbica ou adaptativa emparelhada com supersampling moderado (por exemplo, também adaptável, dependendo da taxa de compactação local).PS A publicação é baseada no relatório: A. Trusov e E. Limonova, “A análise dos algoritmos de transformação projetiva para reconhecimento de imagem em dispositivos móveis”, ICMV 2019, 11433 ed., Wolfgang Osten, Dmitry Nikolaev, Jianhong Zhou, Ed., SPIE Jan. 2020, vol. 11433, ISSN 0277-786X, ISBN 978-15-10636-43-9, vol. 11433, 11433 0Y, pp. 1-8, 2020, DOI: 10.1117 / 12.2559732.Lista de fontes utilizadas- G. Wolberg, Digital image warping, vol. 10662, IEEE computer society press Los Alamitos, CA (1990).
- J. P. Ewins, M. D. Waller, M. White, and P. F. Lister, “Mip-map level selection for texture mapping,” IEEE Transactions on Visualization and Computer Graphics4(4), 317–329 (1998).
- B. Chen, F. Dachille, and A. E. Kaufman, “Footprint area sampled texturing,” IEEE Transactions on Visualizationand Computer Graphics10(2), 230–240 (2004).